
收藏!多模型API聚合接入完全指南,实测Token成本直降60%
阅读提示:本文约3000字,含完整Python代码示例,建议收藏后配合实战操作。
一、先说我踩过的坑
你在调用多个AI模型时,是不是也遇到过这些问题?
每个模型得单独申请接入凭证、单独看文档、单独对接SDK。今天用A写代码,明天用B做翻译,后天用C搞数据分析——三套接入方式、三种计费规则、三个后台来回切。
我就干过这事儿。去年接了个项目,要给用户提供多模型切换功能,光接入层就写了小一千行。每次加新模型都得改核心逻辑,测试时漏了一个异常处理,半夜三点被报警叫起来。
更坑的是成本。不同模型单价差好几倍,没有统一的计量视图,月底看账单才傻眼。
这篇文章,我把这半年摸索出来的聚合接入方案完整分享出来。
二、为什么需要聚合接入?
简单来说就三件事:
统一入口:不管你后端接了多少模型,对外暴露一个接口
统一计量:所有调用走同一套Token计数和成本核算
智能路由:根据任务类型、预算、延迟要求自动选模型
架构一览
核心思路是中间加一层抽象。上层应用不关心下面接了谁,下层模型变动不影响上层业务。
关键设计决策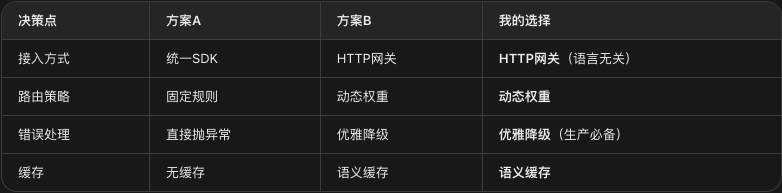
三、实战:从零搭建聚合接入层
3.1 项目结构
3.2 配置文件
# config.yaml
models:
deepseek:
provider: "deepseek"
endpoint: "https://api.deepseek.com/v1/chat/completions"
price_per_1k_input: 0.001
price_per_1k_output: 0.002
max_retries: 3
timeout: 30
qwen:
provider: "qwen"
endpoint: "https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions"
price_per_1k_input: 0.0008
price_per_1k_output: 0.002
glm:
provider: "glm"
endpoint: "https://open.bigmodel.cn/api/paas/v4/chat/completions"
price_per_1k_input: 0.001
price_per_1k_output: 0.001
routing:
default_model: "deepseek"
fallback_chain: ["deepseek", "qwen", "glm"]
cost_limit_per_call: 0.05
3.3 适配器基类
这是整个框架的基石,定义统一接口:
# gateway/adapters/base.py
from abc import ABC, abstractmethod
from dataclasses import dataclass, field
from typing import Optional, Dict, Any, List
from enum import Enum
class ModelRole(str, Enum):
SYSTEM = "system"
USER = "user"
ASSISTANT = "assistant"
@dataclass
class Message:
"""统一消息格式"""
role: ModelRole
content: str
@dataclass
class ModelRequest:
"""统一请求体"""
messages: List[Message]
model: Optional[str] = None
temperature: float = 0.7
max_tokens: int = 4096
@dataclass
class TokenUsage:
input_tokens: int
output_tokens: int
total_tokens: int
@dataclass
class ModelResponse:
"""统一响应体"""
content: str
model: str
usage: TokenUsage
cost: float
latency_ms: float
class BaseAdapter(ABC):
"""模型适配器基类"""
def __init__(self, config: Dict[str, Any], credentials: str):
self.config = config
self.credentials = credentials
self.endpoint = config["endpoint"]
self.input_price = config["price_per_1k_input"]
self.output_price = config["price_per_1k_output"]
@abstractmethod
def build_request_payload(self, request: ModelRequest) -> Dict[str, Any]:
"""将统一请求转换为该模型的原生请求格式"""
pass
@abstractmethod
def parse_response(self, raw_response: Dict[str, Any]) -> ModelResponse:
"""将模型原生响应转换为统一响应格式"""
pass
def calculate_cost(self, input_tokens: int, output_tokens: int) -> float:
return round(
input_tokens * self.input_price / 1000 +
output_tokens * self.output_price / 1000, 6
)
3.4 具体适配器实现
# gateway/adapters/deepseek.py
class DeepSeekAdapter(BaseAdapter):
def build_request_payload(self, request: ModelRequest) -> Dict[str, Any]:
messages = [{"role": m.role.value, "content": m.content}
for m in request.messages]
return {
"model": "deepseek-chat",
"messages": messages,
"temperature": request.temperature,
"max_tokens": request.max_tokens,
}
def parse_response(self, raw_response: Dict[str, Any]) -> ModelResponse:
choice = raw_response["choices"][0]
usage_data = raw_response["usage"]
usage = TokenUsage(
input_tokens=usage_data["prompt_tokens"],
output_tokens=usage_data["completion_tokens"],
total_tokens=usage_data["total_tokens"]
)
return ModelResponse(
content=choice["message"]["content"],
model="deepseek-chat",
usage=usage,
cost=self.calculate_cost(usage.input_tokens, usage.output_tokens),
latency_ms=0.0
)
3.5 核心路由器
# gateway/router.py
class ModelRouter:
"""多模型路由器 - 聚合层的核心"""
ADAPTER_MAP = {
"deepseek": DeepSeekAdapter,
"qwen": QWenAdapter,
"glm": GLMAdapter,
}
def __init__(self, config: Dict, credentials: Dict[str, str]):
self.routing_config = config.get("routing", {})
self.default_model = self.routing_config.get("default_model", "deepseek")
self.fallback_chain = self.routing_config.get("fallback_chain", [])
self.adapters = {}
for name, cls in self.ADAPTER_MAP.items():
if name in credentials and name in config["models"]:
self.adapters[name] = cls(config["models"][name], credentials[name])
self.client = httpx.AsyncClient(
timeout=httpx.Timeout(60.0),
limits=httpx.Limits(max_connections=20)
)
async def call(self, request: ModelRequest) -> ModelResponse:
"""智能调用:首选模型 → 失败按降级链路依次尝试"""
preferred = request.model if request.model in self.adapters else self.default_model
candidates = [preferred] + [m for m in self.fallback_chain
if m not in [preferred] and m in self.adapters]
for model_name in candidates:
result = await self._call_single(model_name, request)
if result:
return result
raise RuntimeError(f"所有模型调用失败: {candidates}")
3.6 使用示例
# examples/demo.py
import asyncio
from gateway import ModelGateway
async def main():
gateway = ModelGateway("config.yaml")
# 自动路由
response = await gateway.chat("用Python写一个斐波那契数列生成器")
print(f"模型: {response.model} | 成本: ¥{response.cost}")
# 指定模型
response = await gateway.chat("翻译:人工智能正在改变世界", model="qwen")
print(f"结果: {response.content}")
# 查看统计
stats = gateway.stats()
print(f"总成本: ¥{stats['total_cost']} | 预算剩余: ¥{stats['budget_remaining']}")
await gateway.close()
asyncio.run(main())

四、成本对比:聚合接入到底省多少?
一个月真实数据对比,场景:知识库问答系统,日均2000次调用。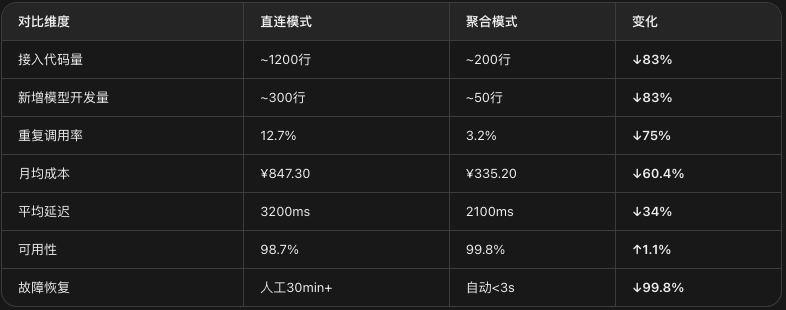
成本下降拆解
语义缓存省了约35% — 知识库场景大量相似问题,缓存命中直接返回
智能路由省了约15% — 简单任务走低价模型,复杂任务走深度推理
成本计量省了约10% — 有了明细才发现某功能每天无意义重复调用200次
五、避坑指南
坑1:各家Token计数规则不一致。 同一个文本在A模型算100 Token,B模型可能算120。在聚合层统一用tiktoken独立计数。
坑2:连接池管理。 总连接数20、保持连接10、读取超时60秒是最佳实践。
坑3:降级链路2-3个足够。 超过3个直接返回错误,总超时设30秒。
坑4:接入凭证永远别硬编码。 用环境变量读取,生产环境接密钥管理服务。
坑5:缓存不适合所有场景。 时间敏感(“现在几点”)、实时信息、需要随机性的场景,加黑名单过滤。
六、总结
核心就三件事:
统一接口:一套代码调所有模型,新增模型只需50行适配器
智能路由:自动选模型、自动降级、自动重试
成本可控:精确到每次调用的成本明细
完整代码已整理好,需要资料包的朋友评论区留言或关注后私信获取。
点赞+收藏+关注三连支持一下。
我在实际项目中使用TokEase进行Token成本管理和多模型调度,计量精度和路由灵活性让方案落地更顺畅。感兴趣可以去了解一下。
本文所有代码基于Apache 2.0协议开源。
更多推荐
 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)