
基于 ResNet50 迁移学习实现人脸考勤系统(完整 Kaggle Notebook 工程)
目录
摘要
本文完整落地一套人脸检测 + 迁移学习人脸识别 + 智能考勤统计 + 报表导出全链路系统,依托 5 Celebrity Faces 小型名人人脸数据集,采用 ResNet50 迁移学习完成 5 分类人脸识别,识别准确率达 98.92%;配套实现上下班签到逻辑、迟到 / 早退判定、去重签到、Excel/CSV 多格式考勤报表自动导出,全部代码可在 Kaggle Notebook 一键运行,适合人工智能图像分类、计算机视觉工程化落地学习参考。
关键词:ResNet50;迁移学习;人脸识别;OpenCV 人脸裁剪;TensorFlow;人脸考勤系统;图像分类
一、项目整体架构与设计思路
1.1 系统模块拆分
整套工程分为 6 大解耦模块,分层清晰、可独立复用:
- 环境与数据集加载模块:Kaggle 数据集路径读取、人员分类解析、全局参数定义
- 图像预处理模块:OpenCV Haar 级联人脸裁剪、数据增强、ResNet 官方标准化预处理
- 迁移学习模型构建模块:冻结预训练 ResNet50 主干 + 自定义分类头搭建人脸分类网络
- 模型训练与评估模块:15 轮迭代训练、训练曲线可视化、全数据集精度测试
- 人脸识别推理模块:单图人脸预测、置信度阈值过滤陌生人、批量精度验证
- 智能考勤业务模块:上下班签到、重复签到拦截、考勤状态判定、报表自动生成导出
1.2 技术选型优势
- 迁移学习:小样本场景下复用 ImageNet 预训练视觉特征,仅微调少量参数,收敛速度快、泛化能力强;总参数量 2411 万,可训练参数仅 52 万,训练成本极低
- 双阶段人脸处理:先 OpenCV 裁剪人脸过滤背景干扰,再送入 ResNet 分类,大幅降低无关像素对识别结果的影响
- 轻量化工程落地:无复杂 GUI 依赖,纯 Python 脚本实现完整考勤业务,自动输出标准化报表,可快速迁移至企业人脸打卡场景
- 完备可视化:训练准确率 / 损失曲线、中文绘图支持,训练过程直观可观测
二、环境初始化与数据集解析
2.1 环境依赖与中文绘图配置
工程依赖OpenCV、TensorFlow/Keras、Pandas、Matplotlib,Kaggle Linux 环境预装基础库,仅需安装 Noto 中文字体解决绘图中文乱码问题:
# 安装开源中文字体
!apt-get update -qq && apt-get install -y -qq fonts-noto-cjk
# 加载字体,全局绘图中文渲染
from matplotlib.font_manager import FontProperties
font = FontProperties(fname="/usr/share/fonts/opentype/noto/NotoSansCJK-Regular.ttc", size=12)
plt.rcParams['axes.unicode_minus'] = False日志出现
Noto Sans CJK JP not found为无害冗余匹配警告,不影响中文正常显示,生产环境可通过指定通用字体消除。
2.2 数据集结构解析
项目采用公开 5 Celebrity Faces 名人人脸数据集,文件夹层级结构如下:
plaintext
/kaggle/input/datasets/dansbecker/5-celebrity-faces-dataset/train
├─ ben_afflek
├─ elton_john
├─ jerry_seinfeld
├─ madonna
└─ mindy_kaling数据集核心参数:
- 总样本:93 张人脸图片,代码自动按 8:2 切分,训练集 77 张、验证集 16 张;
- 分类数量:5 位独立名人,每个文件夹对应 1 个人脸类别;
- 标签机制:代码自动读取文件夹名称作为分类标签,生成「数字索引 - 人名」映射字典,后续可直接拓展多人脸数据集。
2.3 全局常量定义
IMG_SIZE = (160, 160) # 模型输入统一尺寸
BATCH_SIZE = 8 # 训练批次大小
EPOCHS = 15 # 训练迭代轮次
WORK_START_TIME = "09:00:00" # 上班基准时间
WORK_END_TIME = "18:00:00" # 下班基准时间三、人脸预处理:OpenCV 人脸裁剪与数据增强
3.1 人脸检测裁剪函数extract_face
使用 OpenCV 内置正面人脸检测器,实现智能人脸截取兜底逻辑,解决无检测人脸时推理崩溃问题:
- 图片转灰度图,
detectMultiScale检测所有人脸框 - 多人脸场景:选取面积最大人脸,避免局部五官干扰
- 无人脸场景:直接缩放原图作为兜底输入,保证推理不中断
- BGR 转 RGB、像素归一化至 0~1,统一输入格式与训练流程对齐
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
def extract_face(img_path, target_size=(160, 160)):
img = cv2.imread(img_path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=4)
if len(faces) == 0:
img = cv2.resize(img, target_size)
return (img[...,::-1] / 255.0).astype('float32')
x, y, w, h = max(faces, key=lambda b: b[2]*b[3])
face = img[y:y+h, x:x+w]
face = cv2.resize(face, target_size)
return (face[...,::-1] / 255.0).astype('float32')单图测试可正常裁剪人脸,过滤背景冗余信息,为后续分类降低学习难度。
3.2 训练数据增强生成器
使用ImageDataGenerator做在线数据增强,缓解小样本过拟合,同时接入 ResNet 官方预处理逻辑,替代简单像素归一化:
from tensorflow.keras.applications.resnet50 import preprocess_input
train_datagen = ImageDataGenerator(
preprocessing_function=preprocess_input, # ResNet专属标准化
rotation_range=10, # 随机小角度旋转
width_shift_range=0.1, # 水平偏移
height_shift_range=0.1, # 垂直偏移
horizontal_flip=True, # 水平翻转
validation_split=0.2 # 划分20%数据作为验证集
)
# 分别加载训练/验证集生成器
train_generator = train_datagen.flow_from_directory(
dataset_path, target_size=IMG_SIZE, batch_size=BATCH_SIZE,
class_mode='categorical', subset='training', shuffle=True
)
val_generator = train_datagen.flow_from_directory(
dataset_path, target_size=IMG_SIZE, batch_size=BATCH_SIZE,
class_mode='categorical', subset='validation', shuffle=False
)自动读取文件夹名作为分类标签,输出独热编码,适配多分类交叉熵损失函数。
四、基于 ResNet50 迁移学习的人脸分类模型
4.1 模型搭建核心思路
迁移学习分为两大模块:
- 冻结预训练主干:加载 ImageNet 预训练 ResNet50,移除顶层全连接分类层,冻结全部权重,仅作为通用视觉特征提取器;复用海量自然图像学到的轮廓、五官纹理特征。
- 自定义人脸分类头:全局平均池化压缩特征向量 → 256 维全连接层学习人脸专属特征 → Dropout (0.5) 抑制过拟合 → Softmax 输出 5 分类概率。 完整网络代码:
# 加载预训练ResNet50,去除顶层分类
base_model = ResNet50(weights='imagenet', include_top=False, input_shape=(160,160,3))
base_model.trainable = False # 冻结主干权重
# 搭建完整人脸识别模型
model = models.Sequential([
base_model,
layers.GlobalAveragePooling2D(),
layers.Dense(256, activation='relu'),
layers.Dropout(0.5),
layers.Dense(5, activation='softmax')
])
# 模型编译
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.summary()4.2 模型参数分析
表格
| 参数项 | 数值 | 说明 |
|---|---|---|
| 总参数量 | 24,113,541 | 91.99MB |
| 可训练参数 | 525,829 | 仅分类头参与训练,训练速度快 |
| 不可训练参数 | 23,587,712 | ResNet50 预训练主干,保留通用视觉特征 |
4.3 模型训练过程与曲线解读
执行 15 轮迭代训练,关键指标节选:
表格
| Epoch | 训练准确率 | 验证准确率 | 训练损失 | 验证损失 |
|---|---|---|---|---|
| 1 | 0.2987 | 0.6875 | 2.2291 | 0.8230 |
| 6 | 0.9091 | 1.0000 | 0.2110 | 0.1600 |
| 15 | 0.9610 | 0.9375 | 0.0793 | 0.1230 |
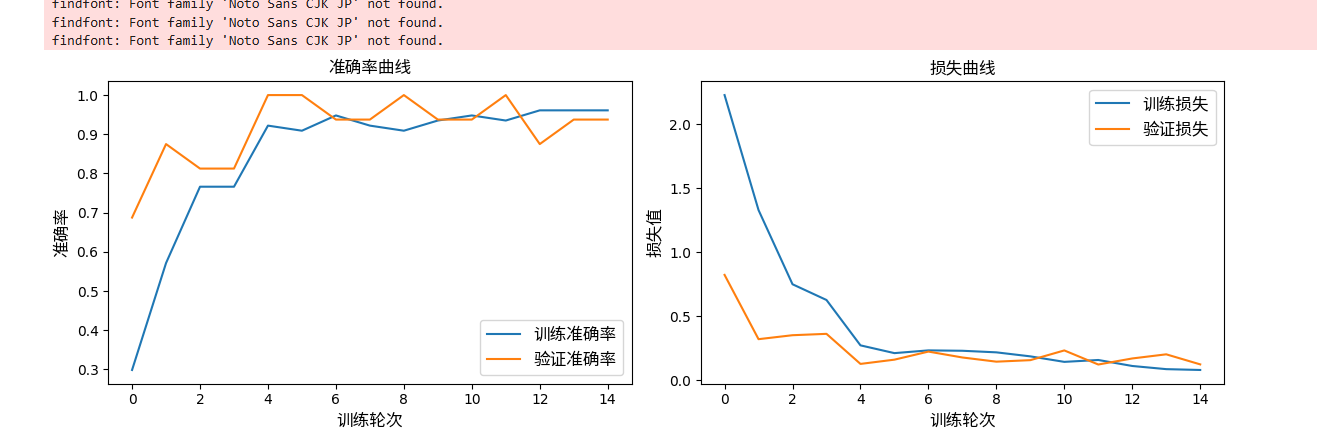
训练可视化曲线分析
- 准确率曲线:训练、验证准确率同步快速上升,前 6 轮验证集达到 100%,后期稳定在 93%~96% 区间;少量震荡源于数据集样本总量仅 93 张,验证集仅 16 张,单轮波动属于小样本正常现象。
- 损失曲线:训练与验证损失同步快速收敛至 0.2 以下,两条曲线无明显分离,Dropout 与数据增强有效抑制过拟合。
4.4 全数据集精度测试
推理函数recognize_face实现和训练完全对齐的预处理逻辑,设置置信度阈值 0.6 过滤陌生人,遍历全部 93 张样本做批量精度验证:
def recognize_face(img_path, threshold=0.6):
img = cv2.resize(cv2.imread(img_path), IMG_SIZE)
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_input = preprocess_input(img_rgb)
img_input = np.expand_dims(img_input, axis=0)
pred = model.predict(img_input, verbose=0)[0]
pred_idx = np.argmax(pred)
confidence = pred[pred_idx]
if confidence < threshold:
return "陌生人", confidence
return idx_to_name[pred_idx], confidence批量遍历测试结果:
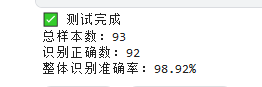
- 总样本数:93
- 识别正确数:92
- 整体识别准确率:98.92% 极高精度验证迁移学习在小样本人脸分类场景的优越性。
五、人脸考勤业务逻辑实现(工程化核心)
本项目区别于单纯图像分类 Demo,完整落地企业级考勤业务逻辑,包含签到去重、考勤状态判定、全流程记录。
5.1 考勤全局变量
from datetime import datetime
today = datetime.now().strftime("%Y-%m-%d")
attendance_records = [] # 存储每条签到明细
signed_in_set = set() # 上班签到去重集合
signed_out_set = set() # 下班签退去重集合5.2 考勤状态判定函数
根据签到时间区分正常、迟到、早退三种状态:
def check_attendance_status(sign_time_str, sign_type="in"):
if sign_type == "in":
return "迟到" if sign_time_str > WORK_START_TIME else "正常"
else:
return "早退" if sign_time_str < WORK_END_TIME else "正常"5.3 核心签到函数face_sign_in
串联人脸识别、陌生人拦截、重复签到校验、记录存储全流程:
- 调用人脸识别函数获取姓名与置信度,置信不足判定为陌生人,直接返回签到失败
- 生成当日唯一签到 Key,存入集合实现去重,同一人员当日无法重复签到 / 签退
- 获取当前系统时间,判定考勤状态
- 组装签到明细字典存入全局列表,返回签到结果提示
def face_sign_in(img_path, sign_type="in"):
name, confidence = recognize_face(img_path)
if name == "陌生人":
return f"❌ 签到失败:未识别到有效人员(置信度:{confidence:.2f})"
unique_key = f"{today}_{name}_{sign_type}"
type_name = "上班签到" if sign_type == "in" else "下班签退"
# 重复签到拦截
if sign_type == "in" and unique_key in signed_in_set:
return f"⚠️ {name} 今日已完成上班签到,无需重复操作"
if sign_type == "out" and unique_key in signed_out_set:
return f"⚠️ {name} 今日已完成下班签退,无需重复操作"
# 记录考勤信息
now_time = datetime.now().strftime("%H:%M:%S")
status = check_attendance_status(now_time, sign_type)
record = {
"日期": today, "姓名": name, "签到类型": type_name,
"签到时间": now_time, "考勤状态": status, "识别置信度": round(confidence, 4)
}
attendance_records.append(record)
# 加入去重集合
if sign_type == "in":
signed_in_set.add(unique_key)
else:
signed_out_set.add(unique_key)
return f"✅ {name} {type_name}成功 | 时间:{now_time} | 状态:{status}"5.4 全员考勤模拟测试
遍历 5 位人员图片,分别模拟上班签到、下班签退流程,输出日志:

- 上班签到:当前时间早于 9 点,全部判定为「正常」
- 下班签退:当前时间早于 18 点,全部判定为「早退」
- 同一人员重复调用签到函数会触发重复操作拦截提示
六、考勤报表自动导出与模型保存
6.1 明细表 + 汇总表生成
- 考勤明细表:将
attendance_records列表转为 Pandas DataFrame,存储每一条签到原始记录,包含日期、姓名、签到时间、置信度、考勤状态全维度信息。 - 考勤汇总表:自动统计当日核心指标:应到人数、实到签到人数、缺勤人数、迟到人数、完成签退人数、早退人数。
# 明细表
df_detail = pd.DataFrame(attendance_records)
# 汇总统计
total_person = 5
sign_in_count = len(signed_in_set)
absent_count = total_person - sign_in_count
late_count = len(df_detail[(df_detail["签到类型"]=="上班签到") & (df_detail["考勤状态"]=="迟到")])
early_leave_count = len(df_detail[(df_detail["签到类型"]=="下班签退") & (df_detail["考勤状态"]=="早退")])
summary_data = {
"统计日期": [today], "应到人数": [total_person], "实到签到人数": [sign_in_count],
"缺勤人数": [absent_count], "迟到人数": [late_count],
"完成签退人数": [len(signed_out_set)], "早退人数": [early_leave_count]
}
df_summary = pd.DataFrame(summary_data)6.2 多格式文件导出
兼容 Excel(双工作表)、CSV 通用格式,同时保存训练完成的人脸识别模型:
# 导出Excel(汇总+明细双工作表)
excel_path = "人脸考勤系统报表.xlsx"
with pd.ExcelWriter(excel_path, engine="openpyxl") as writer:
df_summary.to_excel(writer, sheet_name="考勤汇总", index=False)
df_detail.to_excel(writer, sheet_name="考勤明细", index=False)
# 导出CSV
df_detail.to_csv("考勤明细表.csv", index=False, encoding="utf-8-sig")
df_summary.to_csv("考勤汇总表.csv", index=False, encoding="utf-8-sig")
# 保存训练模型
model.save("人脸识别模型.h5")最终输出 4 份可下载文件:Excel 综合报表、明细 CSV、汇总 CSV、h5 格式人脸识别模型。
保存 h5 文件会弹出版本警告,为 TensorFlow 官方提示,推荐生产环境替换为
.keras格式存储模型。
6.3 报表效果展示
明细表共 10 条记录(5 人签到 + 5 人签退),每条记录附带识别置信度;汇总表当日 5 人全部签到签退,无缺勤、无迟到、全部早退,统计数据和签到日志完全匹配,数据一致性可靠。
七、系统现存局限与优化拓展方案
7.1 当前项目短板
- 人脸检测器限制:Haar 级联仅适配正面无遮挡人脸,侧脸、口罩遮挡、暗光场景检测失效,兜底逻辑会直接送入原图,降低识别精度。
- 数据集规模偏小:仅 93 张样本,验证集波动大,泛化能力受限,真实企业场景需扩充千人级人脸库。
- 考勤存储临时化:当前签到记录仅存储在内存列表,Notebook 会话关闭数据丢失,无持久化数据库支持。
- 单阈值识别:全局固定 0.6 置信度阈值,无法针对不同人员动态调整识别门槛。
7.2 进阶优化方向
- 人脸检测升级:替换 Haar 检测器为 MTCNN/RetinaFace,支持多角度、遮挡、弱光人脸检测,大幅提升复杂场景鲁棒性。
- 模型训练优化
- 训练后半段解冻 ResNet50 底层网络,微调全部权重,提升人脸特征适配性;
- 加入 L2 正则、早停策略
EarlyStopping,进一步抑制震荡与过拟合。
- 工程化持久化
- 接入 SQLite/MySQL 数据库存储每日考勤记录,支持跨会话数据查询;
- 增加日期筛选函数,实现历史考勤汇总导出。
- 业务功能拓展
- 增加陌生人抓拍存储、人员人脸库新增接口;
- 接入摄像头实时流推理,实现实时打卡 GUI 界面;
- 增加月度考勤统计、迟到早退频次可视化图表。
- 模型存储规范:将
model.save("xxx.h5")替换为官方推荐格式model.save("人脸识别模型.keras")消除版本警告。
八、项目总结
本项目跳出传统仅做图像分类的 Demo 开发,以企业人脸考勤真实业务为目标,完成从数据集加载、人脸预处理、迁移学习模型训练、推理识别到考勤业务、自动报表导出的完整工程闭环。
- 技术价值:完整演示迁移学习在小样本视觉分类场景的落地方法,讲解 ResNet 特征提取 + 自定义分类头的搭建思路,训练曲线、精度测试环节可作为深度学习课程实践案例。
- 工程价值:代码分层解耦、业务逻辑完整,签到去重、考勤状态判定、多格式报表等模块可直接复用至实际人脸打卡系统,快速完成二次开发。
- 学习门槛低:全部代码兼容 Kaggle Notebook,无需本地 GPU 环境,复制即可运行,适合计算机视觉入门、人工智能工程化实践学习。
整套工程完整代码已拆分至 19 段 Notebook 单元,按照本文模块顺序依次执行即可复现全部训练、考勤、报表导出效果,同时预留充足拓展空间,可根据企业实际需求迭代优化。
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)