
Elasticsearch与kibana
前言
Java中比较流行的搜索引擎是Elasticsearch,传统的数据库搜索,使用like’关键字%’,当内容过多时性能会大大降低,所以Elasticsearch就出现了。
Elasticsearch核心概念
Elasticsearch 是面向文档的分布式搜索引擎,所有数据以 JSON 格式存储和返回,无需预先定义严格的表结构,具备高度的灵活性和扩展性。
数据层级关系
ES 的数据组织层级可以类比为关系型数据库,但两者并不完全等价:
| Elasticsearch | 关系型数据库(类比) | 说明 |
|---|---|---|
| 集群(Cluster) | 数据库实例 | 由一个或多个节点组成,统一对外提供服务 |
| 节点(Node) | 数据库服务器 | 集群中的每一台服务器,存储数据并参与索引和搜索 |
| 索引(Index) | 表(Table) | 具有相同结构的文档集合,是数据存储和搜索的逻辑单元 |
| 文档(Document) | 行(Row) | 一条完整的数据记录,以 JSON 格式存储 |
| 字段(Field) | 列(Column) | 文档中的具体属性,如 title、price、createTime |
倒排索引
倒排索引中有两个非常重要的概念:
- 文档(
Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息 - 词条(
Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条
创建倒排索引是对正向索引的一种特殊处理,流程如下:
- 将每一个文档的数据利用算法分词,得到一个个词条
- 创建表,每行数据包括词条、词条所在文档id、位置等信息
- 因为词条唯一性,可以给词条创建索引,例如hash表结构索引
Kibana
Kibana 是一款免费且开放的前端应用程序,其基础是 Elastic Stack,可以为 Elasticsearch 中索引的数据提供搜索和数据可视化功能。
用途:
搜索、查看并可视化 Elasticsearch 中所索引的数据,并通过创建柱状图、饼状图、表格、直方图和地图对数据进行分析。仪表板视图能将这些可视化元素集中到一起,然后通过浏览器加以分享,以提供有关海量数据的实时分析视图,为下列用例提供支持:
1.日志处理和分析
2.基础设施指标和容器监测
3.应用程序性能监测 (APM)
4.地理空间数据分析和可视化
5.安全分析
6.业务分析
es和kibana的安装
可以参考Linux环境下安装Elasticsearch,史上最详细的教程来啦~_linux elasticsearch-CSDN博客
以及kibana的安装Linux下安装Kibana环境_kibana 端口 15601-CSDN博客
es的操作(通过kibana可视化工具操作)
基本操作
索引创建:PUT /index_name
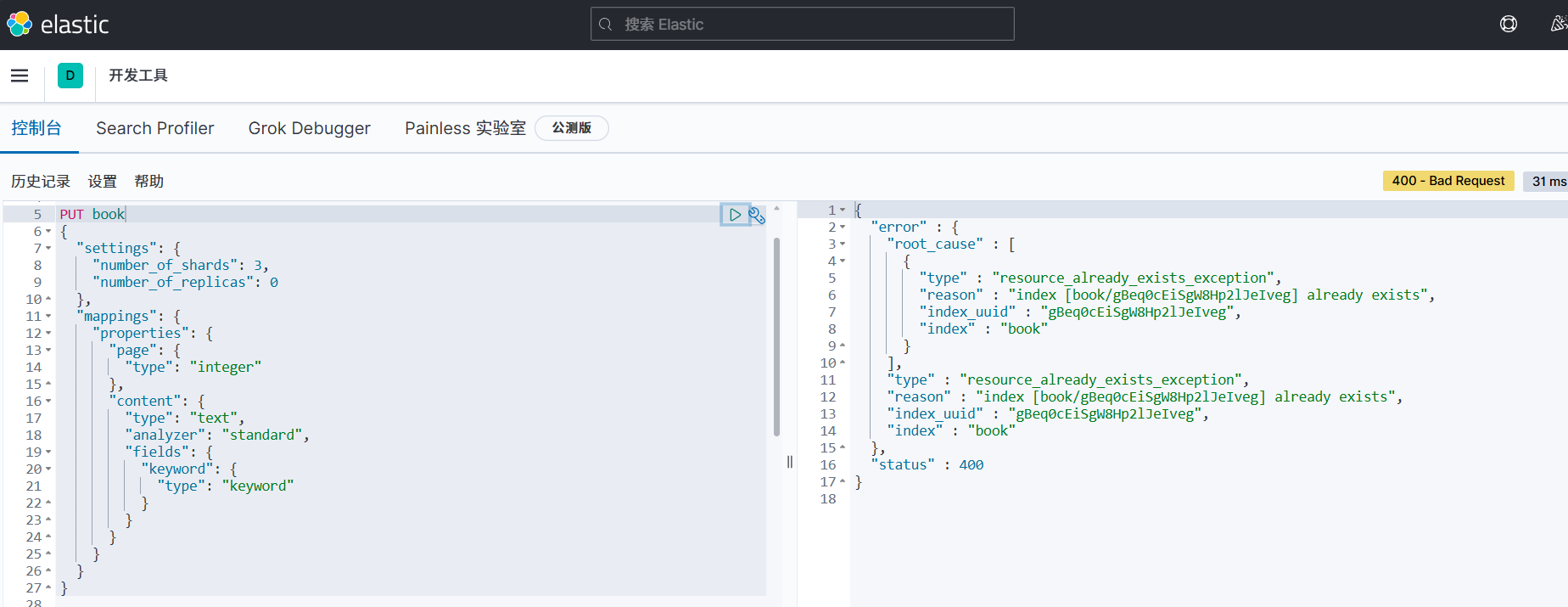
因为我是单机环境下搭建的,只有 1 个节点,ES 无法将副本分片分配到其他节点,所以将副本数设置为0
文档添加:POST /index_name/_doc {JSON数据}
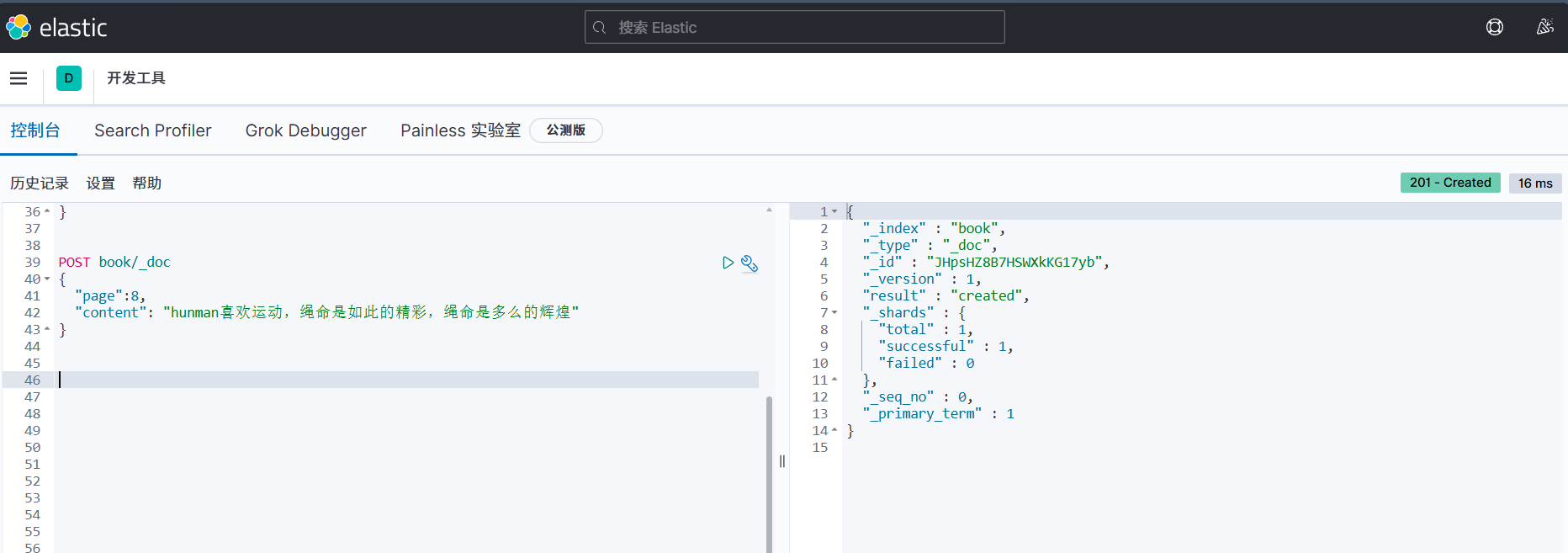
添加方式有两种:post 和 put 区别是post可以不用指定文档ID(自动生成),put需要指定
文档查询:GET /index_name/_doc/id
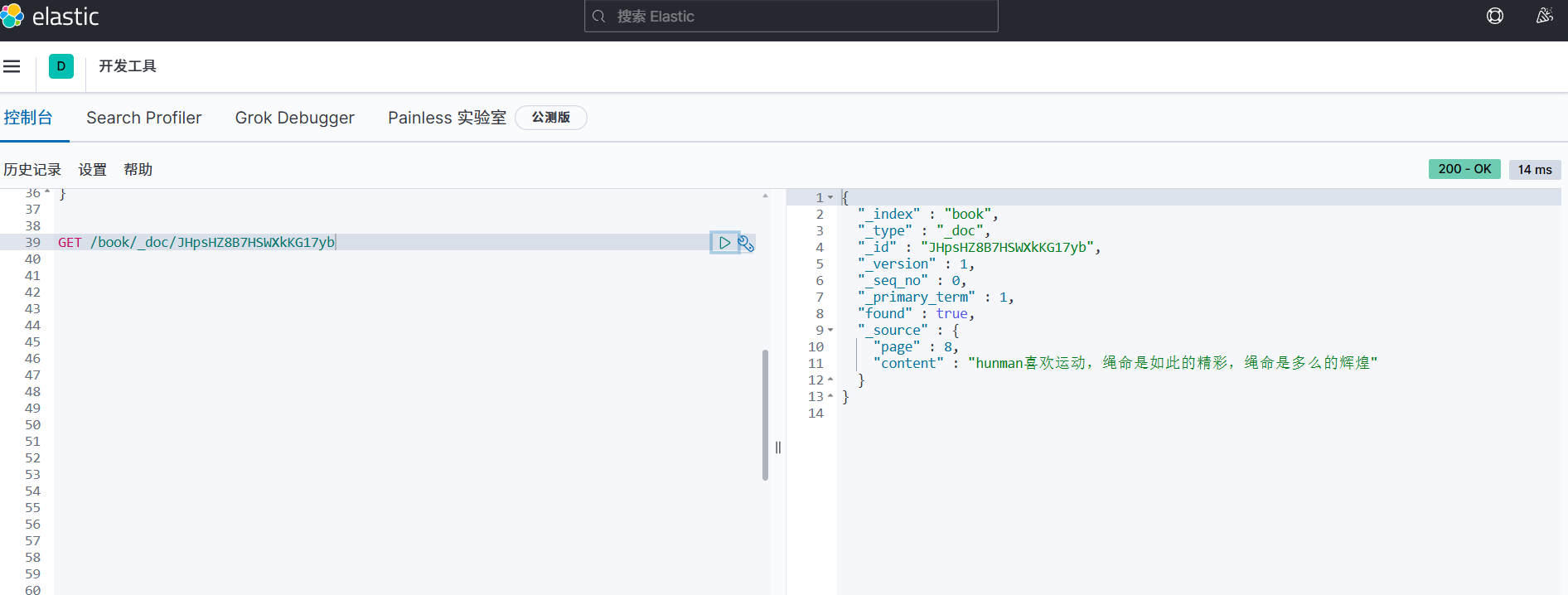
索引删除:DELETE /index_name
高级功能
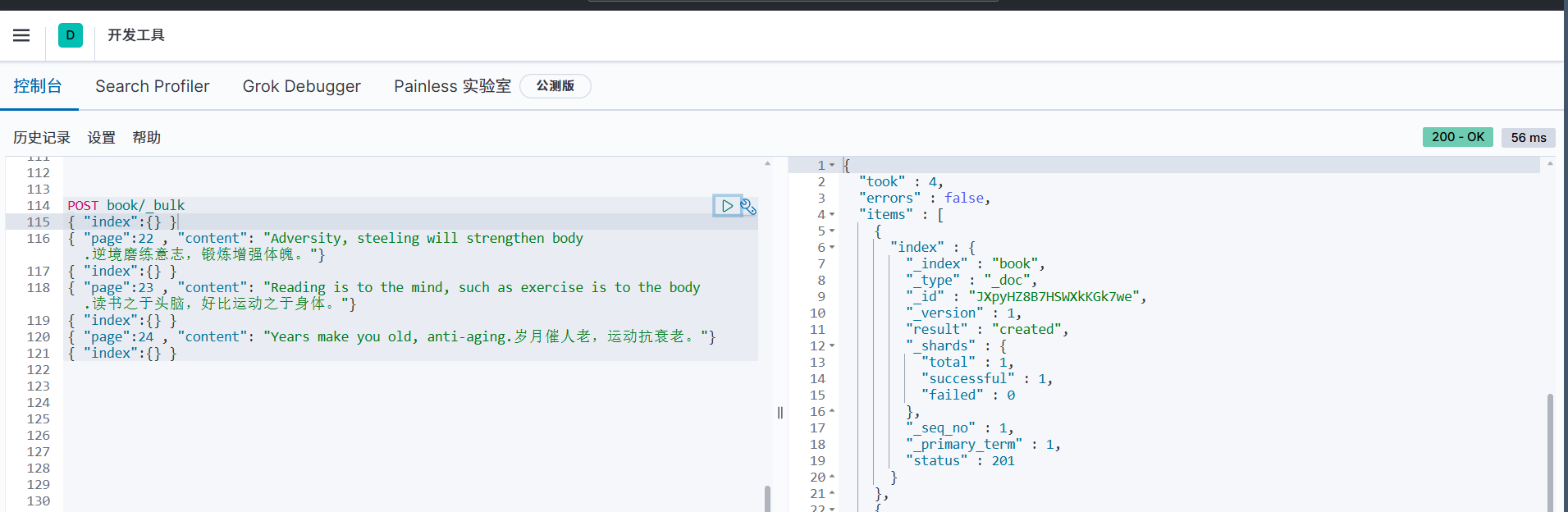
批量操作:使用_bulkAPI执行多个操作
搜索查询:通过_searchAPI实现复杂检索
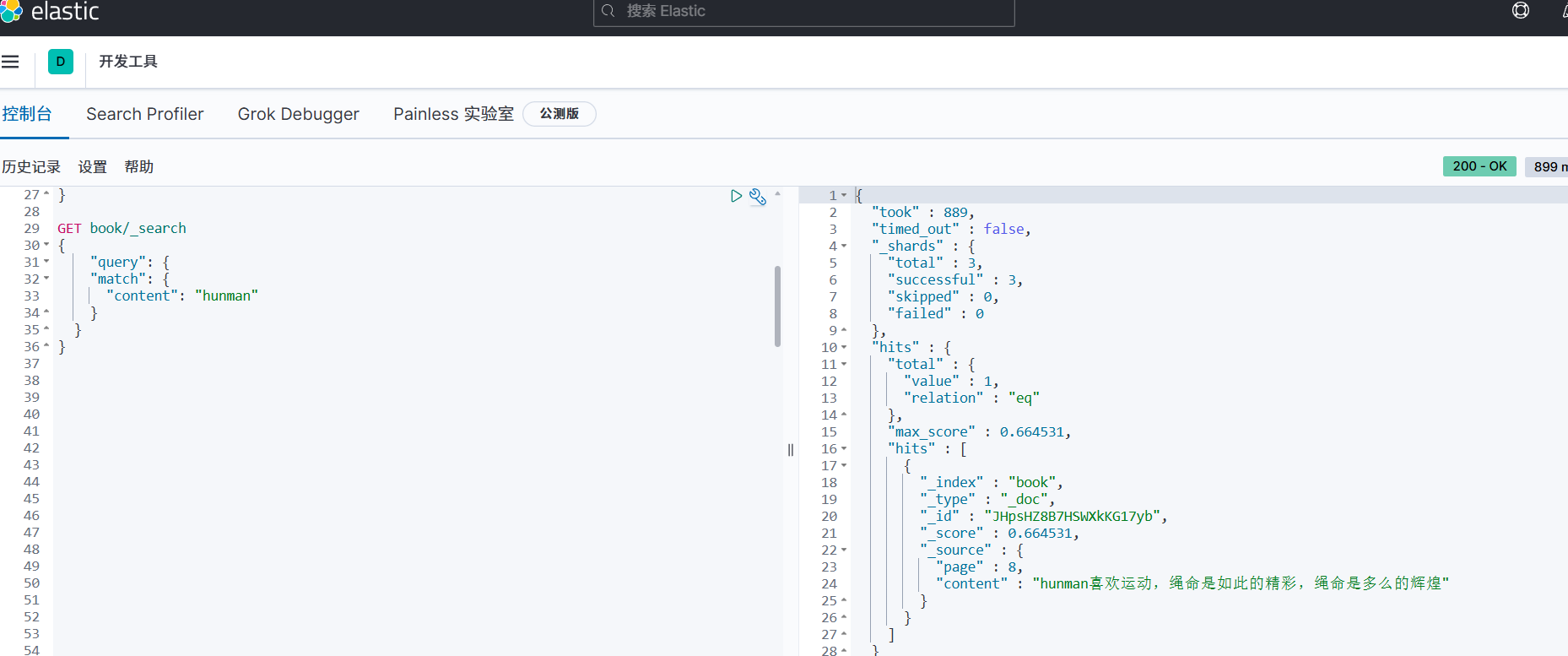
通过content关键字匹配查询 ,也可以通过其他字段match
聚合分析:利用聚合功能进行数据统计分析
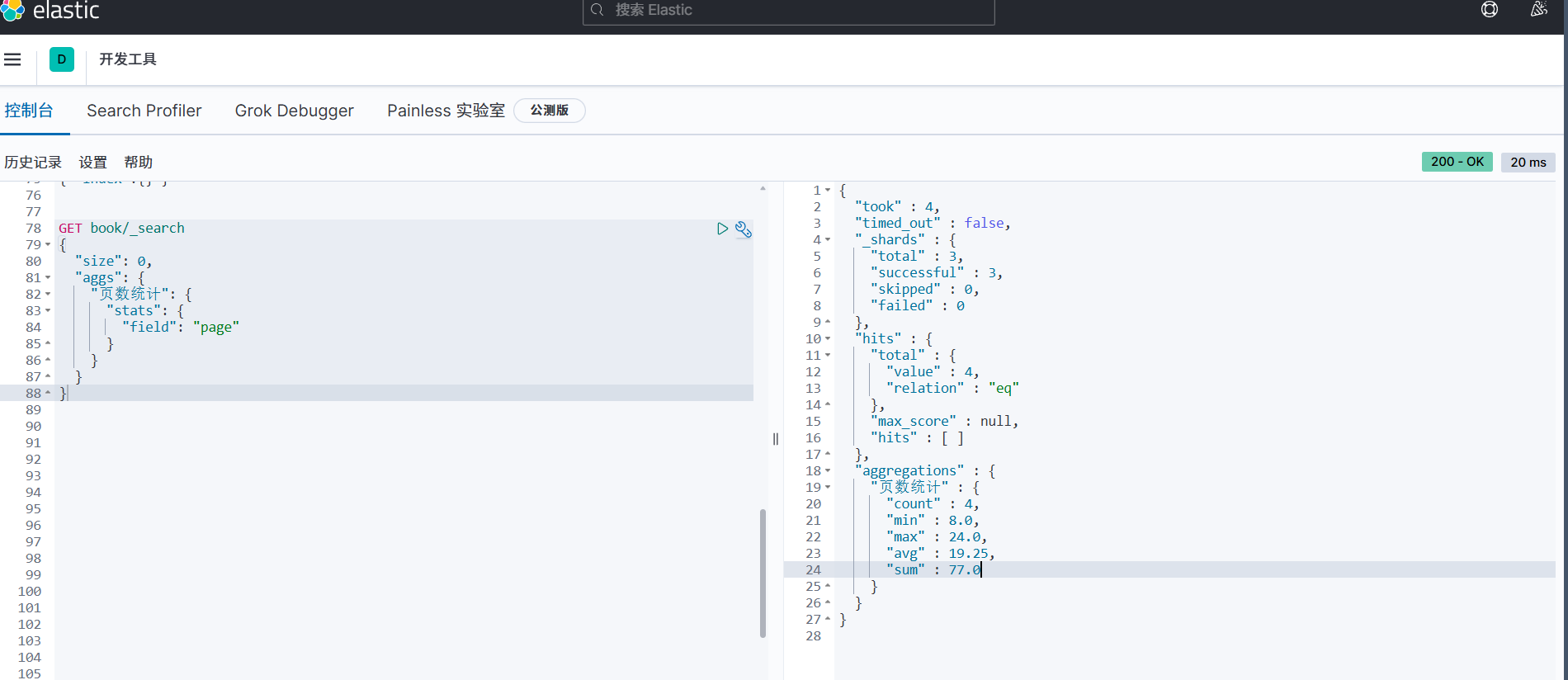
我这里使用的是aggs,可以分别统计 条数、最小值、最大值、平均值、总和
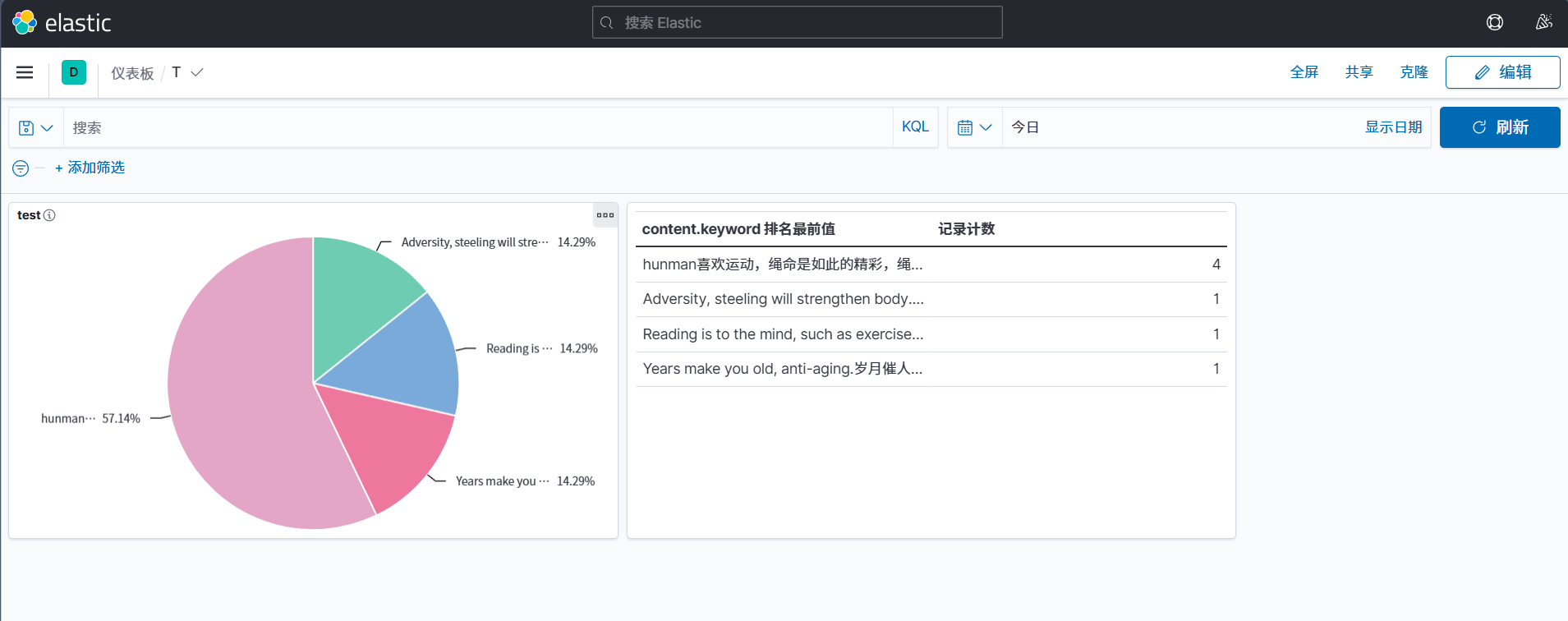
可视化展示
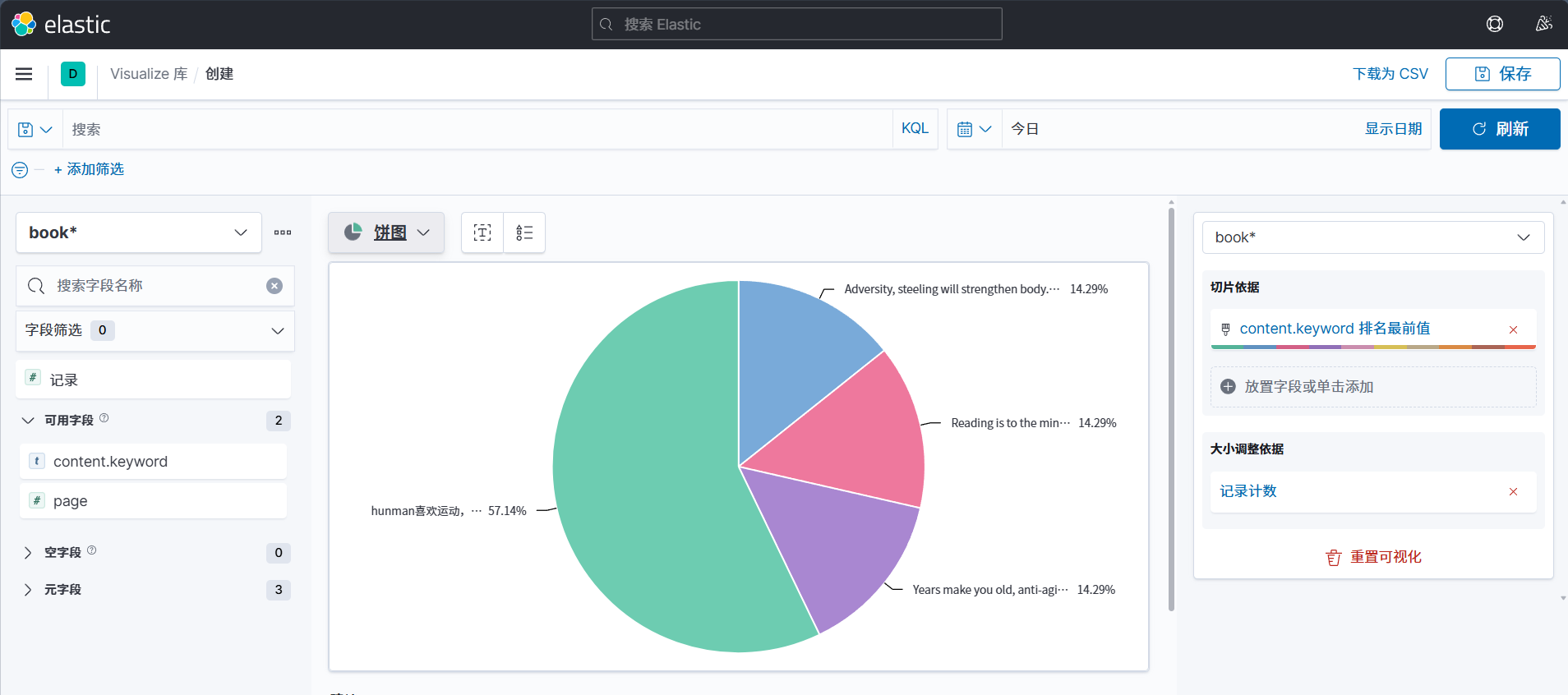
和其他可视化工具一样,可以创建数据图并且可以放在可视化大屏展示
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)