
机器学习笔记之马尔可夫链蒙特卡洛方法(四)吉布斯采样
上一节介绍了将马尔可夫链与蒙特卡洛方法相结合的算法——MH采样算法(Metropolis Hastings),本节将介绍吉布斯采样算法(Gibbs Sampling)。
机器学习笔记之马尔可夫链蒙特卡洛方法——吉布斯采样
引言
上一节介绍了将马尔可夫链与蒙特卡洛方法相结合的算法——MH采样算法(Metropolis Hastings),本节将介绍吉布斯采样算法(Gibbs Sampling)。
回顾:MH采样算法
基于马尔可夫链的采样方式
首先,MH算法是基于马尔可夫链的采样方式:
- 通过构建合适的状态转移矩阵
A
∗
\mathcal A^*
A∗,使得连续状态下的随机变量
X
t
,
X
t
+
1
\mathcal X_t,\mathcal X_{t+1}
Xt,Xt+1对应的概率分布满足细致平衡原则(Detail Balance):
π ( X t = x i ) ⋅ P ( X t + 1 = x j ∣ X t = x i ) = π ( X t = x j ) ⋅ P ( X t + 1 = x i ∣ X t = x j ) \pi(\mathcal X_{t} =x_i) \cdot P(\mathcal X_{t+1} =x_j \mid \mathcal X_t = x_i) = \pi(\mathcal X_{t} = x_j) \cdot P(\mathcal X_{t+1} =x_i \mid \mathcal X_t =x_j) π(Xt=xi)⋅P(Xt+1=xj∣Xt=xi)=π(Xt=xj)⋅P(Xt+1=xi∣Xt=xj)
其中, π ( X t ) , π ( X t + 1 ) \pi(\mathcal X_t),\pi(\mathcal X_{t+1}) π(Xt),π(Xt+1)表示不同时刻对应随机变量 X t , X t + 1 \mathcal X_t,\mathcal X_{t+1} Xt,Xt+1的概率分布; P ( X t + 1 ∣ X t ) P(\mathcal X_{t+1} \mid \mathcal X_t) P(Xt+1∣Xt)表示 t t t时刻到 t + 1 t+1 t+1时刻的状态转移概率。 - 这种状态转移矩阵 A ∗ \mathcal A^* A∗的构建方式,使得马尔可夫链 { X T } \{\mathcal X_{T}\} {XT}共用同一个概率分布,即平稳分布;
- 已知上一状态随机变量
X
k
−
1
\mathcal X_{k-1}
Xk−1选择具体离散结果
x
k
−
1
x_{k-1}
xk−1的条件下,当前状态随机变量
X
k
\mathcal X_{k}
Xk的采样结果可表示如下:
x k ∼ P ( X k ∣ X k − 1 = x k − 1 ) x_k \sim P(\mathcal X_{k} \mid \mathcal X_{k-1} = x_{k-1}) xk∼P(Xk∣Xk−1=xk−1) - 由于平稳分布的原因,使得 各时间状态产生的样本点
{
x
0
,
x
1
,
⋯
,
x
k
−
1
,
x
k
,
⋯
}
\{x_0,x_1,\cdots,x_{k-1},x_{k},\cdots \}
{x0,x1,⋯,xk−1,xk,⋯}均属于平稳分布的样本点,从而使用蒙特卡洛方法来求解该平稳分布的期望信息:
N N N表示采集样本点数量。
E X [ f ( X ) ] = 1 N ∑ i = 1 N f ( x i ) \mathbb E_{\mathcal X} [f(\mathcal X)] = \frac{1}{N} \sum_{i=1}^N f(x_i) EX[f(X)]=N1i=1∑Nf(xi)
细致平衡原则与接收率
在马尔可夫链与平稳分布中介绍过,由于马尔可夫链自身的 齐次马尔可夫假设 的性质,使得状态转移矩阵
A
\mathcal A
A必然是一个双随机矩阵;
由于双随机矩阵的自身性质,使得只要状态转移过程足够多,各状态随机变量的概率分布必然逼近于平稳分布:
m
m
m表示执行了足够多次状态转移过程后达到平稳分布的状态结果;
X
e
n
d
\mathcal X_{end}
Xend表示转移过程的终结状态。
π
(
X
m
+
1
)
=
π
(
X
m
+
2
)
=
⋯
=
π
(
X
e
n
d
)
\pi(\mathcal X_{m+1}) = \pi(\mathcal X_{m+2}) = \cdots = \pi(\mathcal X_{end})
π(Xm+1)=π(Xm+2)=⋯=π(Xend)
但是,我们并不清楚:到底状态转移至什么状态,就可以得到平稳分布了?
或者可理解为:虽然平稳分布在马尔可夫链中必然存在,但是要一直等下去,等到转移次数足够多了,就大致认为其是平稳分布。
这种做法明显是不精确的。我们需要有一种方式,来判断当前时刻随机变量的概率分布是否为平稳分布?
细致平衡原则很好地满足了这样的条件,准确来说:细致平衡原则是判断当前状态随机变量
X
t
\mathcal X_t
Xt是平稳分布的充分不必要条件。
π
(
X
t
=
x
i
)
⋅
P
(
X
t
+
1
=
x
j
∣
X
t
=
x
i
)
=
?
π
(
X
t
=
x
j
)
⋅
P
(
X
t
+
1
=
x
i
∣
X
t
=
x
j
)
\pi(\mathcal X_{t} =x_i) \cdot P(\mathcal X_{t+1} =x_j \mid \mathcal X_t = x_i) \overset{\text{?}}{=} \pi(\mathcal X_{t} = x_j) \cdot P(\mathcal X_{t+1} =x_i \mid \mathcal X_t =x_j)
π(Xt=xi)⋅P(Xt+1=xj∣Xt=xi)=?π(Xt=xj)⋅P(Xt+1=xi∣Xt=xj)
如果式子两端相等,就可以判定
t
t
t时刻随机变量的概率分布
π
(
X
t
)
\pi(\mathcal X_t)
π(Xt)是平稳分布,反之同理。
即便我们已经得到了平稳分布的判定条件,但是平稳分布只是一个无限逼近的过程,仅凭判定条件,我们可能依然很难得到那个达到平稳分布的状态 m m m。
而MH采样算法构建一种方式,通过细致平衡原则将逼近过程映射成概率形式。并基于该概率拒绝或者接受样本。从而在马尔可夫链的任意状态下,均可采集样本。
MH采样算法的接受率
α
(
x
i
,
x
j
)
(
i
,
j
∈
{
1
,
2
,
⋯
,
K
}
)
\alpha(x_i,x_j)(i,j \in \{1,2,\cdots,\mathcal K\})
α(xi,xj)(i,j∈{1,2,⋯,K})表示如下:
α
(
x
i
,
x
j
)
=
min
[
1
,
π
(
x
j
)
P
(
X
=
x
i
∣
X
=
x
j
)
π
(
x
i
)
P
(
X
=
x
j
∣
X
=
x
i
)
]
\alpha(x_i,x_j) = \min \left[1, \frac{\pi(x_j)P(\mathcal X = x_i \mid \mathcal X = x_j)}{\pi(x_i)P(\mathcal X = x_j \mid \mathcal X = x_i)}\right]
α(xi,xj)=min[1,π(xi)P(X=xj∣X=xi)π(xj)P(X=xi∣X=xj)]
在细致平衡中添加接收率,可以使当前状态与下一时刻状态强行细致平衡,从而将细致平衡的可能性转化为
α
(
x
i
,
x
j
)
\alpha(x_i,x_j)
α(xi,xj)的接受概率:
π
(
X
t
=
x
i
)
⋅
P
(
X
t
+
1
=
x
j
∣
X
t
=
x
i
)
⋅
α
(
x
i
,
x
j
)
=
π
(
X
t
=
x
j
)
⋅
P
(
X
t
+
1
=
x
i
∣
X
t
=
x
j
)
⋅
α
(
x
j
,
x
i
)
\pi(\mathcal X_{t} =x_i) \cdot P(\mathcal X_{t+1} =x_j \mid \mathcal X_t = x_i)\cdot \alpha(x_i,x_j) = \pi(\mathcal X_{t} = x_j) \cdot P(\mathcal X_{t+1} =x_i \mid \mathcal X_t =x_j) \cdot \alpha(x_j,x_i)
π(Xt=xi)⋅P(Xt+1=xj∣Xt=xi)⋅α(xi,xj)=π(Xt=xj)⋅P(Xt+1=xi∣Xt=xj)⋅α(xj,xi)
就以
α
(
x
i
,
x
j
)
\alpha(x_i,x_j)
α(xi,xj)的概率采集
x
j
x_j
xj样本,在
α
(
x
i
,
x
j
)
\alpha(x_i,x_j)
α(xi,xj)概率结果之外,自然只能拒绝该样本,并将
x
i
x_i
xi再一次加入样本集合中。
MH采样算法的弊端
基于上述流程,我们发现:
-
添加接受率这种操作确实能够使当前状态与下一时刻状态之间强行细致平衡,但是这种细致平衡同样是基于概率的。
如果状态转移矩阵 A \mathcal A A的选择不当,导致每次状态转移后指向的样本对应的接收率都不高,此时,这个样本即便指向了它,但也大概率会被拒绝。
即出现‘下一状态对于各个结果的状态转移概率都很平均,都不太高,以至于没有明显区分’; -
随机变量 X \mathcal X X可能是一个高维度的随机变量,那么 π ( X ) \pi(\mathcal X) π(X)可视作随机变量 X \mathcal X X各维度分量的联合概率分布。即:
X = ( x 1 , x 2 , ⋯ , x p ) T π ( X ) = π ( x 1 , x 2 , ⋯ , x p ) \begin{aligned}\mathcal X = (x_1,x_2,\cdots,x_p)^{T} \\ \pi(\mathcal X) = \pi(x_1,x_2,\cdots,x_p) \end{aligned} X=(x1,x2,⋯,xp)Tπ(X)=π(x1,x2,⋯,xp)
实际上,基于高维样本的马尔可夫链的采样过程很困难,加上第一条问题,采出来的样本不仅量少,而且样本的有效性也很差。
这里的‘有效性差’指采出来的样本‘无法近似表示’平稳分布。
吉布斯采样方法
吉布斯采样的采样过程
吉布斯采样方法的核心思想:坐标上升法。
相比于MH算法将整个样本(所有维度)一次性采集完成,吉布斯采样使用 针对某一维度进行采样,并将除采样维度外的其他维度信息进行固定;下一状态采样其他维度过程中,将上一状态采样的维度加入本次采样中进行更新,直至所有维度均采样一遍为止。
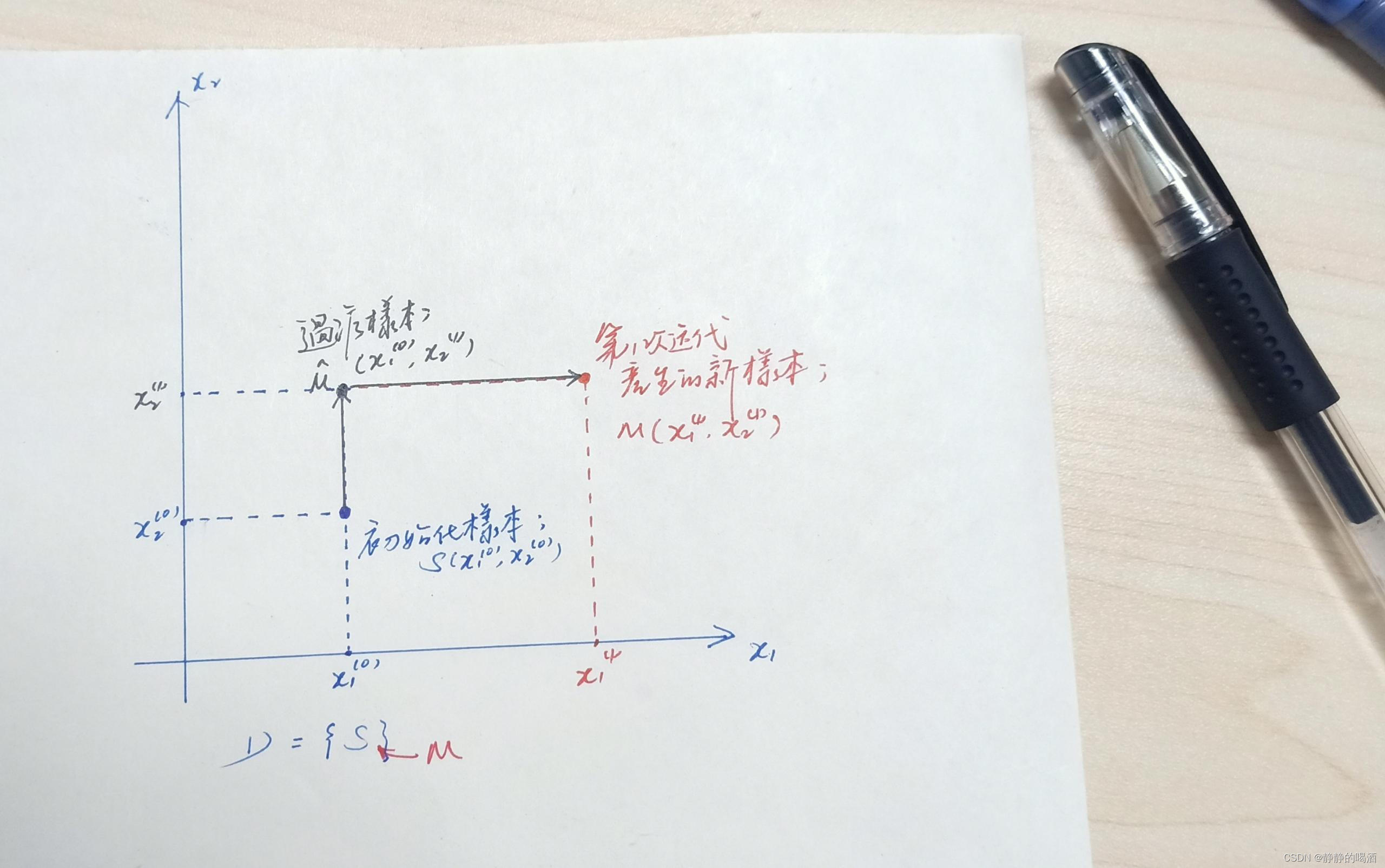
以一个基于二维信息的联合概率分布 π ( x 1 , x 2 ) \pi(x_1,x_2) π(x1,x2)为例:
- 已知一个初始化样本点
S
=
(
x
1
(
0
)
,
x
2
(
0
)
)
\mathcal S = (x_1^{(0)},x_2^{(0)})
S=(x1(0),x2(0));
一个初始化集合 D = { S } \mathcal D = \{\mathcal S\} D={S}; - 固定
x
1
x_1
x1维度:
- 固定
x
1
x_1
x1维度的样本信息
x
1
(
0
)
x_1^{(0)}
x1(0),从 后验概率
P
(
x
2
∣
x
1
(
0
)
)
P(x_2 \mid x_1^{(0)})
P(x2∣x1(0))中采样
x
2
x_2
x2维度的维度样本:
x 2 ( 1 ) ∼ P ( x 2 ∣ x 1 ( 0 ) ) x_2^{(1)} \sim P(x_2 \mid x_1^{(0)}) x2(1)∼P(x2∣x1(0)) - 此时
x
2
(
1
)
x_2^{(1)}
x2(1)满足 细致平衡原则:
此时,我们可以将x 2 ( 0 ) , x 2 ( 1 ) x_2^{(0)},x_2^{(1)} x2(0),x2(1)均视为‘后验概率’P ( x 2 ∣ x 1 ( 0 ) ) P(x_2 \mid x_1^{(0)}) P(x2∣x1(0))中随机产生的样本点~
x 2 ( 0 ) → x 2 ( 1 ) : π ( x 1 ( 0 ) , x 2 ( 0 ) ) ⋅ P ( x 2 ( 1 ) ∣ x 1 ( 0 ) ) x 2 ( 1 ) → x 2 ( 0 ) : π ( x 1 ( 0 ) , x 2 ( 1 ) ) ⋅ P ( x 2 ( 0 ) ∣ x 1 ( 0 ) ) π ( x 1 ( 0 ) , x 2 ( 0 ) ) ⋅ P ( x 2 ( 1 ) ∣ x 1 ( 0 ) ) = π ( x 1 ( 0 ) , x 2 ( 1 ) ) ⋅ P ( x 2 ( 0 ) ∣ x 1 ( 0 ) ) x_2^{(0)} \to x_2^{(1)} : \quad\pi(x_1^{(0)},x_2^{(0)}) \cdot P(x_2^{(1)} \mid x_1^{(0)}) \\ x_2^{(1)} \to x_2^{(0)} : \quad \pi(x_1^{(0)},x_2^{(1)}) \cdot P(x_2^{(0)} \mid x_1^{(0)}) \\ \pi(x_1^{(0)},x_2^{(0)}) \cdot P(x_2^{(1)} \mid x_1^{(0)}) = \pi(x_1^{(0)},x_2^{(1)}) \cdot P(x_2^{(0)} \mid x_1^{(0)}) x2(0)→x2(1):π(x1(0),x2(0))⋅P(x2(1)∣x1(0))x2(1)→x2(0):π(x1(0),x2(1))⋅P(x2(0)∣x1(0))π(x1(0),x2(0))⋅P(x2(1)∣x1(0))=π(x1(0),x2(1))⋅P(x2(0)∣x1(0)) - 至此,得到一个中间的过渡样本: M ^ = ( x 1 ( 0 ) , x 2 ( 1 ) ) \hat {\mathcal M} = (x_1^{(0)},x_2^{(1)}) M^=(x1(0),x2(1))。
- 固定
x
1
x_1
x1维度的样本信息
x
1
(
0
)
x_1^{(0)}
x1(0),从 后验概率
P
(
x
2
∣
x
1
(
0
)
)
P(x_2 \mid x_1^{(0)})
P(x2∣x1(0))中采样
x
2
x_2
x2维度的维度样本:
- 固定
x
2
x_2
x2维度:
- 借助样本点
M
^
\hat {\mathcal M}
M^,固定
x
2
x_2
x2维度的样本信息
x
2
(
1
)
x_2^{(1)}
x2(1),从 后验概率
P
(
x
1
∣
x
2
(
1
)
)
P(x_1 \mid x_2^{(1)})
P(x1∣x2(1))中采样
x
1
x_1
x1维度的维度样本:
x 1 ( 1 ) ∼ P ( x 1 ∣ x 2 ( 1 ) ) x_1^{(1)} \sim P(x_1 \mid x_2^{(1)}) x1(1)∼P(x1∣x2(1)) - 此时
x
1
(
1
)
x_1^{(1)}
x1(1)满足 细致平衡原则:
同理,此时我们可以将x 1 ( 0 ) , x 1 ( 1 ) x_1^{(0)},x_1^{(1)} x1(0),x1(1)均视为‘后验概率’P ( x 1 ∣ x 2 ( 1 ) ) P(x_1 \mid x_2^{(1)}) P(x1∣x2(1))中随机产生的样本点~
π ( x 1 ( 0 ) , x 2 ( 1 ) ) ⋅ P ( x 1 ( 1 ) ∣ x 2 ( 1 ) ) = π ( x 1 ( 1 ) , x 2 ( 1 ) ) ⋅ P ( x 1 ( 0 ) ∣ x 2 ( 1 ) ) \pi(x_1^{(0)},x_2^{(1)}) \cdot P(x_1^{(1)} \mid x_2^{(1)}) = \pi(x_1^{(1)},x_2^{(1)}) \cdot P(x_1^{(0)} \mid x_2^{(1)}) π(x1(0),x2(1))⋅P(x1(1)∣x2(1))=π(x1(1),x2(1))⋅P(x1(0)∣x2(1)) - 至此,再次得到一个样本: M = ( x 1 ( 1 ) , x 2 ( 1 ) ) \mathcal M = (x_1^{(1)},x_2^{(1)}) M=(x1(1),x2(1))。
- 借助样本点
M
^
\hat {\mathcal M}
M^,固定
x
2
x_2
x2维度的样本信息
x
2
(
1
)
x_2^{(1)}
x2(1),从 后验概率
P
(
x
1
∣
x
2
(
1
)
)
P(x_1 \mid x_2^{(1)})
P(x1∣x2(1))中采样
x
1
x_1
x1维度的维度样本:
- 注意,至此我们将所有维度全部固定一次(
x
1
,
x
2
x_1,x_2
x1,x2)。并得到一个新的样本点
M
=
(
x
1
(
1
)
,
x
2
(
1
)
)
\mathcal M = (x_1^{(1)},x_2^{(1)})
M=(x1(1),x2(1))。将该样本点添加到样本集合
D
\mathcal D
D中:
D = { S , M } \mathcal D = \{\mathcal S,\mathcal M\} D={S,M} - 后续步骤将以
M
\mathcal M
M点为基准点,重复执行上述操作,采样出新的样本点,直至样本集合
D
\mathcal D
D足够大,最终进行蒙特卡洛方法求解。
图形描述表示如下:
吉布斯采样的推导过程
为什么可以使用这种迭代方式进行采样?这种采样方式本质上是MH算法中的一种特殊情况:接受率为1的MH采样方法。
为什么这种采样方式得到的样本都可以完整接受它?
构建如下场景:
假设要采样的隐变量
Z
\mathcal Z
Z是一个
p
p
p维的随机变量:
Z
=
(
z
1
,
z
2
,
⋯
,
z
p
)
T
\mathcal Z = (z_1,z_2,\cdots,z_p)^{T}
Z=(z1,z2,⋯,zp)T
该随机变量
Z
\mathcal Z
Z对应在各时间状态中的概率分布
π
(
Z
)
\pi(\mathcal Z)
π(Z)可看作是关于
Z
\mathcal Z
Z的联合概率分布:
π
(
Z
)
=
π
(
z
1
,
z
2
,
⋯
,
z
p
)
\pi(\mathcal Z) = \pi(z_1,z_2,\cdots,z_p)
π(Z)=π(z1,z2,⋯,zp)
针对上述吉布斯采样的采样过程,任意维度的样本
z
i
∗
(
i
=
1
,
2
,
⋯
,
p
)
z_i^*(i=1,2,\cdots,p)
zi∗(i=1,2,⋯,p)可视作从状态转移矩阵
P
(
z
i
∣
z
1
,
⋯
,
z
i
−
1
,
z
i
+
1
,
⋯
,
z
p
)
P(z_i \mid z_1,\cdots,z_{i-1},z_{i+1},\cdots,z_p)
P(zi∣z1,⋯,zi−1,zi+1,⋯,zp)中生成的一个样本:
z
i
∗
∼
P
(
z
i
∣
z
1
,
⋯
,
z
i
−
1
,
z
i
+
1
,
⋯
,
z
p
)
z_i^* \sim P(z_i \mid z_1,\cdots,z_{i-1},z_{i+1},\cdots,z_p)
zi∗∼P(zi∣z1,⋯,zi−1,zi+1,⋯,zp)
同理,在生成其他维度样本过程中,如
z
j
∗
(
j
≠
i
)
z_j^*(j \neq i)
zj∗(j=i),需要将前面步骤采集的
z
i
∗
z_i^*
zi∗样本加入到后验概率分布中:
z
j
∗
∼
P
(
z
j
∣
z
1
,
⋯
,
z
i
∗
,
⋯
,
z
j
−
1
,
z
j
+
1
,
⋯
,
z
p
)
z_j^* \sim P(z_j \mid z_1,\cdots,z_i^*,\cdots,z_{j-1},z_{j+1},\cdots,z_p)
zj∗∼P(zj∣z1,⋯,zi∗,⋯,zj−1,zj+1,⋯,zp)
其他维度样本均同理。直至所有维度样本均采样一次后,得到的结果是一个新的样本点。
上述过程中,吉布斯采样存在一个特殊现象:对于一个完整样本的 p p p次迭代中,每一次迭代转移概率都是固定的。因此即便存在维度替换的情况,但并不影响当前步骤的后验概率结果。
示例:
从如下两个样本中采样维度
j
j
j的样本
z
j
z_j
zj:
z
j
∼
P
(
z
j
∣
z
1
,
⋯
,
z
i
∗
,
⋯
,
z
j
−
1
,
z
j
+
1
,
⋯
,
z
p
)
z
j
∼
P
(
z
j
∣
z
1
,
⋯
,
z
i
,
⋯
,
z
j
−
1
,
z
j
+
1
,
⋯
,
z
p
)
z_j \sim P(z_j \mid z_1,\cdots,z_i^*,\cdots,z_{j-1},z_{j+1},\cdots,z_p) \\ z_j \sim P(z_j \mid z_1,\cdots,z_i,\cdots,z_{j-1},z_{j+1},\cdots,z_p)
zj∼P(zj∣z1,⋯,zi∗,⋯,zj−1,zj+1,⋯,zp)zj∼P(zj∣z1,⋯,zi,⋯,zj−1,zj+1,⋯,zp)
这两个分布的唯一区别在于:第 i i i维度是否被替换过。但不需要担心这种情况。因为上述两次采样绝不会出现在同一个样本的迭代过程中。
观察接受率中的分数项,并表示为吉布斯采样的概率形式:
注意,此时的
Z
\mathcal Z
Z已经是一个高维向量;
z
−
i
z_{-i}
z−i表示除去
z
i
z_i
zi分量后的剩余分量。
P
(
Z
∗
∣
X
)
⋅
Q
(
Z
∣
Z
∗
)
P
(
Z
∣
X
)
⋅
Q
(
Z
∗
∣
Z
)
=
π
(
z
i
∗
∣
z
−
i
∗
)
⋅
π
(
z
−
i
∗
)
⋅
p
(
z
i
∣
z
−
i
∗
)
π
(
z
i
∣
z
−
i
)
⋅
π
(
z
−
i
∗
)
⋅
p
(
z
i
∗
∣
z
−
i
)
=
1
\begin{aligned} & \frac{P(\mathcal Z^* \mid \mathcal X) \cdot \mathcal Q(\mathcal Z \mid \mathcal Z^*)}{P(\mathcal Z \mid \mathcal X) \cdot \mathcal Q(\mathcal Z ^* \mid \mathcal Z)} \\ & = \frac{\pi(z_i^* \mid z_{-i}^*) \cdot \pi(z_{-i}^*)\cdot p(z_i \mid z_{-i}^*)}{\pi(z_i \mid z_{-i}) \cdot \pi(z_{-i}^*) \cdot p(z_i^* \mid z_{-i})} \\ & = 1 \end{aligned}
P(Z∣X)⋅Q(Z∗∣Z)P(Z∗∣X)⋅Q(Z∣Z∗)=π(zi∣z−i)⋅π(z−i∗)⋅p(zi∗∣z−i)π(zi∗∣z−i∗)⋅π(z−i∗)⋅p(zi∣z−i∗)=1
吉布斯采样的代码实现
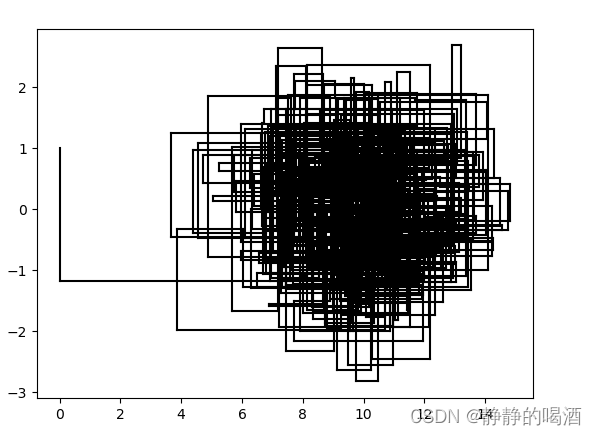
基于上述的吉布斯采样过程,我们通过采样的方式近似一个给定的2维高斯分布:
首先,这个近似操作只是一个简化了的工作:
- 二维高斯分布它的各维度也是高斯分布;
- 各维度之间相互独立,因此,状态转移概率(条件概率)就是边缘概率分布本身;
说白了,就是从两个独立的高斯分布中进行采样。但是吉布斯采样的过程还是要保留的。
代码表示如下:
这里关于概率的表示有错误,这里使用概率密度函数结果直接表示了概率,但真实情况是‘概率密度结果的积分’才是概率结果。后续有机会改。
import math
import matplotlib.pyplot as plt
import random
def one_dim_pdf(x,mu,sigma):
return (1 / (math.sqrt(2 * math.pi) * sigma)) * math.exp(-1 * (((x - mu) ** 2)/ (2 * (sigma ** 2))))
def get_sample(mu,sigma):
while True:
random_value = random.uniform(-5, 15)
u = random.uniform(0, 1)
prob = one_dim_pdf(random_value, mu, sigma)
if u < prob:
break
return random_value
def gibbs(start_point,mu_1,mu_2,sigma_1,sigma_2,loop_num):
assert len(start_point) == 2
start = start_point
for i in range(loop_num):
start_x, start_y = start[0], start[1]
randomv = get_sample(mu_1,sigma_1)
plt.scatter([start_x,start_x],[start_y,randomv],c="k",s=2)
randomq = get_sample(mu_2,sigma_2)
plt.scatter([start_x,randomq],[randomv,randomv],c="k",s=2)
start = [randomq,randomv]
plt.show()
if __name__ == '__main__':
mu_1 = 0
sigma_1 = 1
mu_2 = 10
sigma_2 = 2
start_point = [0,1]
gibbs(start_point,mu_1,mu_2,sigma_1,sigma_2,loop_num=500)
对应图像表示如下:
下一节将介绍马尔可夫链蒙特卡洛方法面对的挑战
相关参考:
机器学习-白板推导系列-蒙特卡洛方法4(Monte Carlo Method)-吉布斯采样(Gibbs)
更多推荐

 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)