
机器学习——多项式曲线拟合及Python代码实现
线性回归是回归问题,此方法对训练数据类型没有要求,可以是离散特征,也可以是连续特征;此方法会出现过拟合问题,在处理过拟合手段就是降低模型难度,减少特征个数,或者采用正则化方法,就是在损失函数后面加上正则项(l1、l2正则项)。此方法也会出现欠拟合问题。处理手工增加新的特征变量,也可以增加多项式特征,使模型更加complex,实现非线性回归。
·
一、回归模型评价指标说明
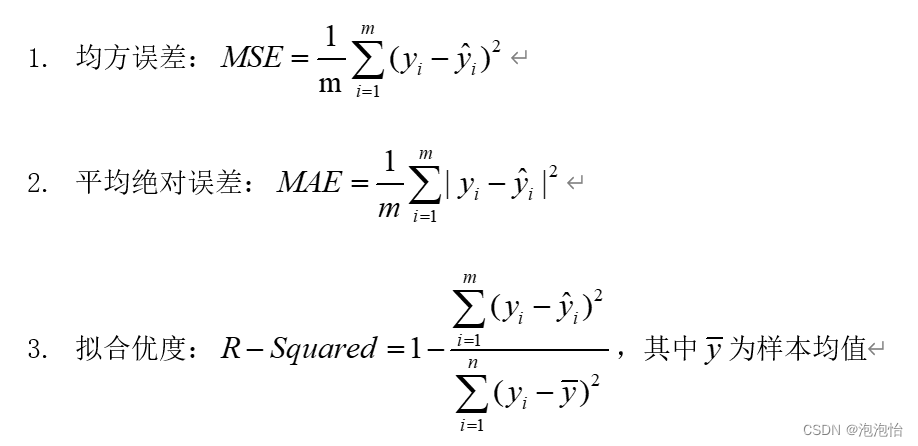
二、线性回归
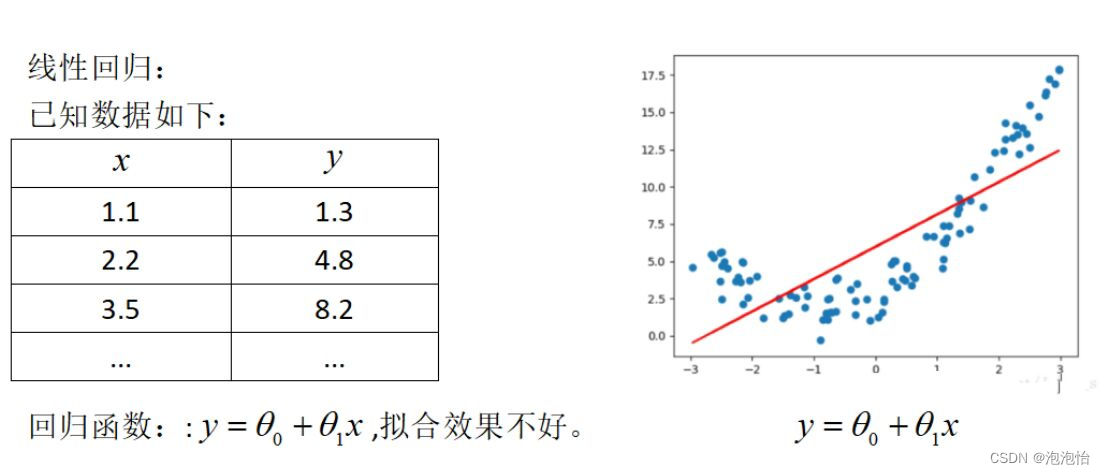
线性回归是回归问题,此方法对训练数据类型没有要求,可以是离散特征,也可以是连续特征;此方法会出现过拟合问题,在处理过拟合手段就是降低模型难度,减少特征个数,或者采用正则化方法,就是在损失函数后面加上正则项(l1、l2正则项)。此方法也会出现欠拟合问题。处理手工增加新的特征变量,也可以增加多项式特征,使模型更加complex,实现非线性回归。比如:
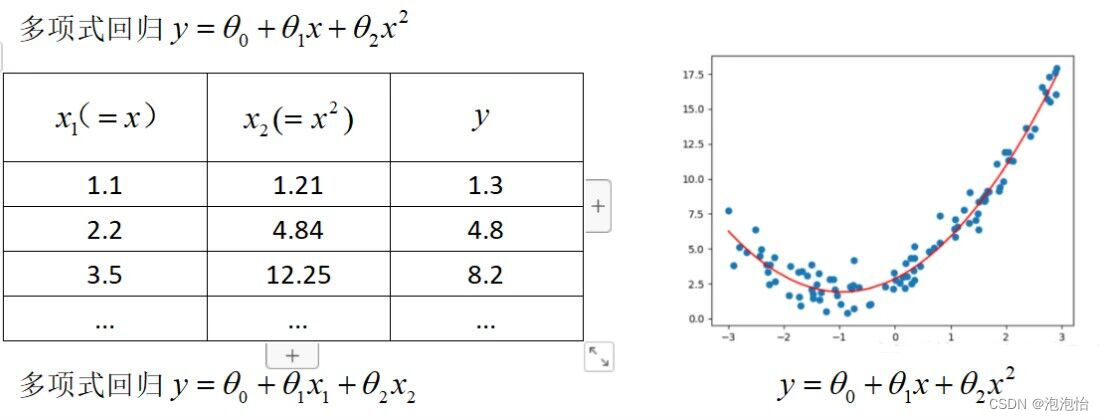
三、Python代码实现
(1)导包
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_boston
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report
from sklearn.metrics import r2_score,mean_squared_error,mean_absolute_error(2)下载数据集(从sklearnz中下载)
boston=load_boston()
X=boston.data
y=boston.targetX:代表所有特征;y:代表所有label
(3)划分数据集(test_size=0.2:将数据的80%划分为训练集,20%划分为测试集)
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=3)(4)数据标准化(归一化,去除量纲)
ss=StandardScaler()
X_train=ss.fit_transform(X_train)
X_test=ss.transform(X_test)(5)训练模型(导入线性训练器)
from sklearn.linear_model import LinearRegression
model=LinearRegression()
model.fit(X_train,y_train)(6)模型评估
train_score=model.score(X_train,y_train)#训练集得分
test_score=model.score(X_test,y_test)#测试集得分
print('train_score:',train_score)
print('test_score:',test_score)结果:

我们会发现训练结果欠拟合。
我们还可以看一下MAE、MSE
mse=mean_squared_error(y_test,y_test_predict)
print('The value of mse:',mse)
mae=mean_absolute_error(y_test,y_test_predict)
print('The value of mae:',mae)结果:

(7)模型优化
1.导入多项式包
from sklearn.preprocessing import PolynomialFeatures2.传入degree的数值,比如等于2,则代表2次多项式
polynomial_features=PolynomialFeatures(degree=2)
X_train1=polynomial_features.fit_transform(X_train)
X_test1=polynomial_features.fit_transform(X_test)3.模型训练
model=LinearRegression()
model.fit(X_train1,y_train)4.模型评估
train_score = model.score(X_train1, y_train)
test_score = model.score(X_test1, y_test)
print('train_score:','R2=',train_score)
print('test_score=:','R2=',test_score)结果:
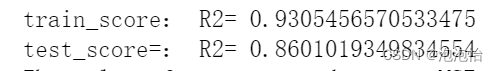
(8)权重系数
model.coef_
更多推荐

 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)