
NVIDIA H200/H20 DeepSeek-V4-Pro 部署指南、压测性能与稳定性调优建议
GPUStack 安装与集群初始化
GPUStack 是一个开源 GPU 集群管理与 AI 模型服务平台,旨在高效部署 AI 模型。它可以配置并编排多种推理引擎——如 vLLM、SGLang、TensorRT-LLM,甚至自定义引擎——以在 GPU 集群上实现最佳性能。核心功能包括多异构 GPU 集群池化调度、可插拔推理引擎架构、Day 0 模型支持、性能优化配置(低延迟/高吞吐)、以及企业级运维能力,如故障恢复、负载均衡、监控与权限管理。
GPUStack 可以帮助我们高效地管理 vLLM、SGLang 等推理引擎,并推动模型从部署走向企业生产落地运营。在开始部署 DeepSeek V4 之前,首先完成 GPUStack 控制面的安装,并将 NVIDIA GPU 节点纳入管理。
准备容器环境
GPUStack 以容器方式运行,因此需要提前准备好容器运行环境(如 Docker、Podman 或 Kubernetes)。本文以 Docker 为例进行说明。
在各节点上安装 Docker,确保服务已正常启动:
docker info
启动 GPUStack Server
GPUStack Server 无需依赖 GPU,可运行在普通 CPU 节点上,也可运行在 GPU 节点。本文以八卡 NVIDIA H200 141GB 为实验环境,在该节点上启动 GPUStack Server 容器:
sudo docker run -d --name gpustack \
--restart unless-stopped \
-p 80:80 \
--volume gpustack-data:/var/lib/gpustack \
swr.cn-south-1.myhuaweicloud.com/gpustack/gpustack:v2.1.2 \
--debug --bootstrap-password GPUStack@123
关键参数说明:
- -p 80:80:用于对外暴露 Web 控制台端口;如需修改为其他端口(例如 9999),可调整为 -p 9999:80。
- --volume:持久化平台数据(包括模型服务、计量数据、API Key 等)
- --bootstrap-password:初始化 admin 用户密码
- --debug:开启调试日志,便于排查问题
容器启动后,可以通过日志确认服务是否正常运行:
docker logs -f gpustack
访问控制台并初始化
打开浏览器访问:http://<Server 主机 IP>:80
使用默认账号登录:
- 用户名:admin
- 密码:GPUStack@123
登录后,首先创建一个 Docker 类型的集群,用于统一管理后续接入的 GPU 节点。
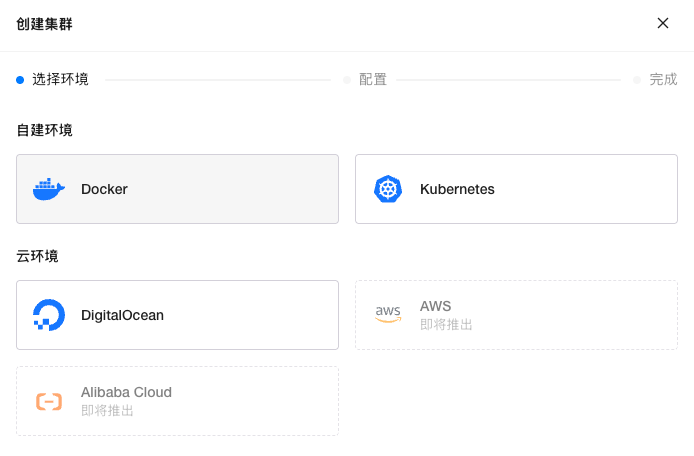
添加 NVIDIA GPU Worker 节点
在集群创建完成后,可以接入 NVIDIA GPU 节点。
在添加节点之前,先完成基础环境检查。
(1)驱动版本检查
在目标节点上执行以下命令:
nvidia-smi
该命令会显示当前安装的 NVIDIA 驱动版本。请确认驱动版本 ≥ 580,以保证对 DeepSeek V4 模型的兼容性和稳定性。
(2)Nvidia Container Toolkit 检查
执行以下命令检查 Docker 是否正确配置了 Nvidia Container Toolkit:
sudo docker info 2>/dev/null | grep -q "Runtime.*nvidia" && echo "Nvidia Container Toolkit OK" || (echo "Nvidia Container Toolkit not configured"; exit 1)
- 该命令会从
docker info输出中查找是否存在nvidia运行时配置。 - 如果输出 "Nvidia Container Toolkit OK",说明 Docker 已正确配置,可在容器中访问 GPU。
- 如果输出 "Nvidia Container Toolkit not configured",则说明未正确配置,需要安装并启用 Nvidia Container Toolkit,否则推理容器无法使用 GPU 资源。
(3)接入 Worker 节点
在 GPUStack 控制台中,选择添加节点(Worker),并复制系统生成的接入命令,在目标节点执行。
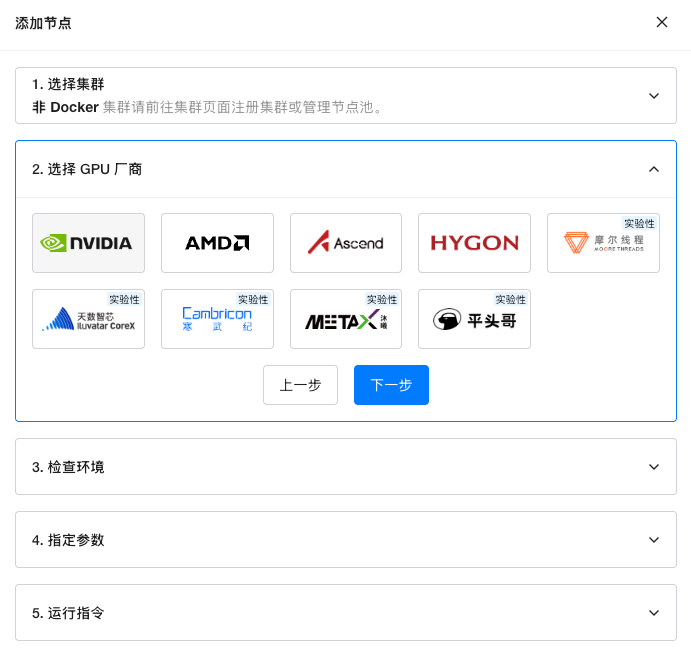
该命令本质上会启动一个 Worker 容器,并自动注册到 Server。
(4)验证 Worker 状态
节点接入后,可以在节点上查看容器日志:
docker logs -f gpustack-worker
同时,在 GPUStack 控制台中也可以看到节点状态是否为 Ready。
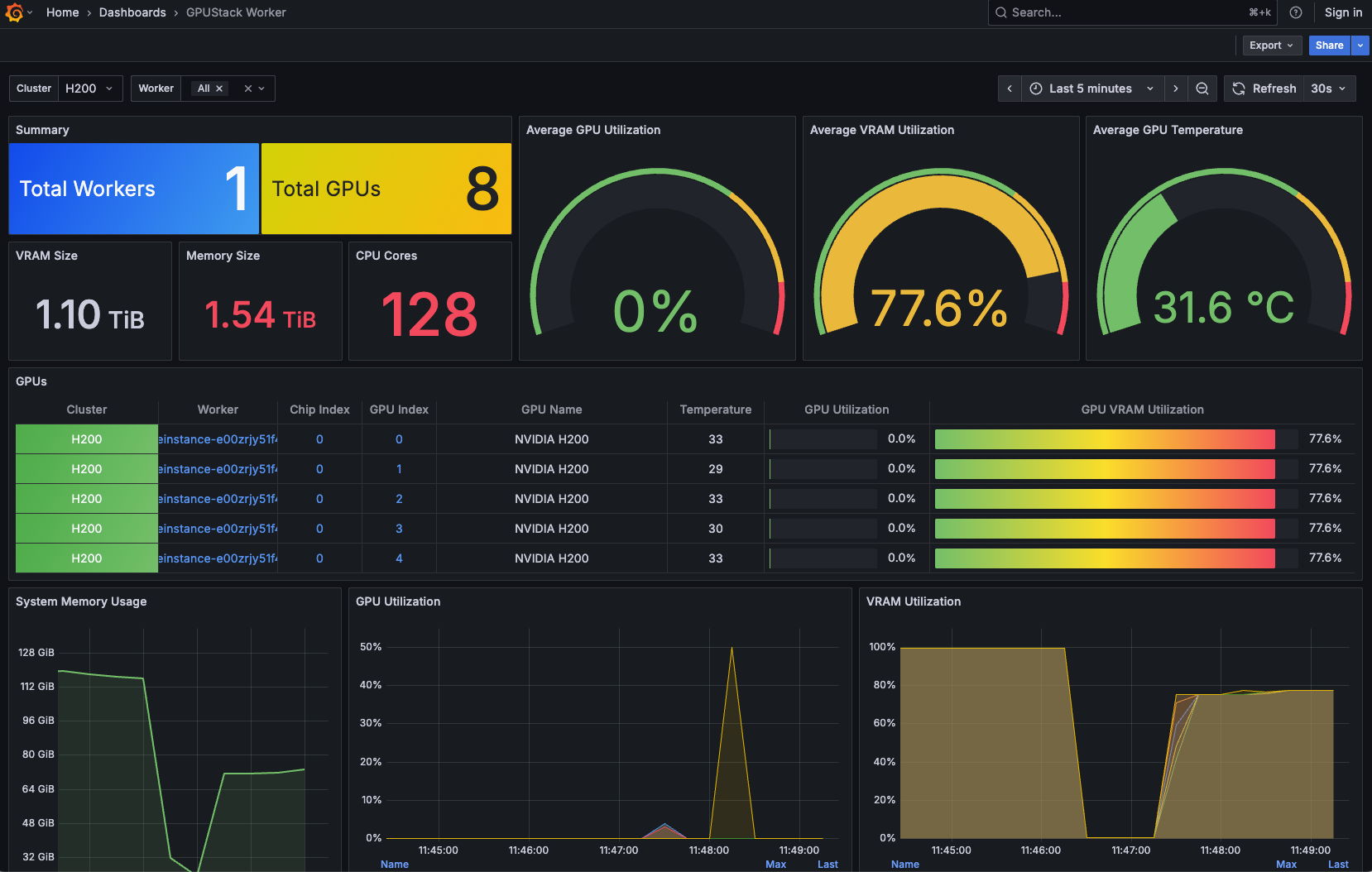
至此,GPUStack 的控制面已成功部署,NVIDIA GPU 节点也顺利接入集群,并能够正常采集设备名称、索引、厂商信息、温度、利用率及显存使用等指标。接下来即可在该环境中部署具体的推理服务。
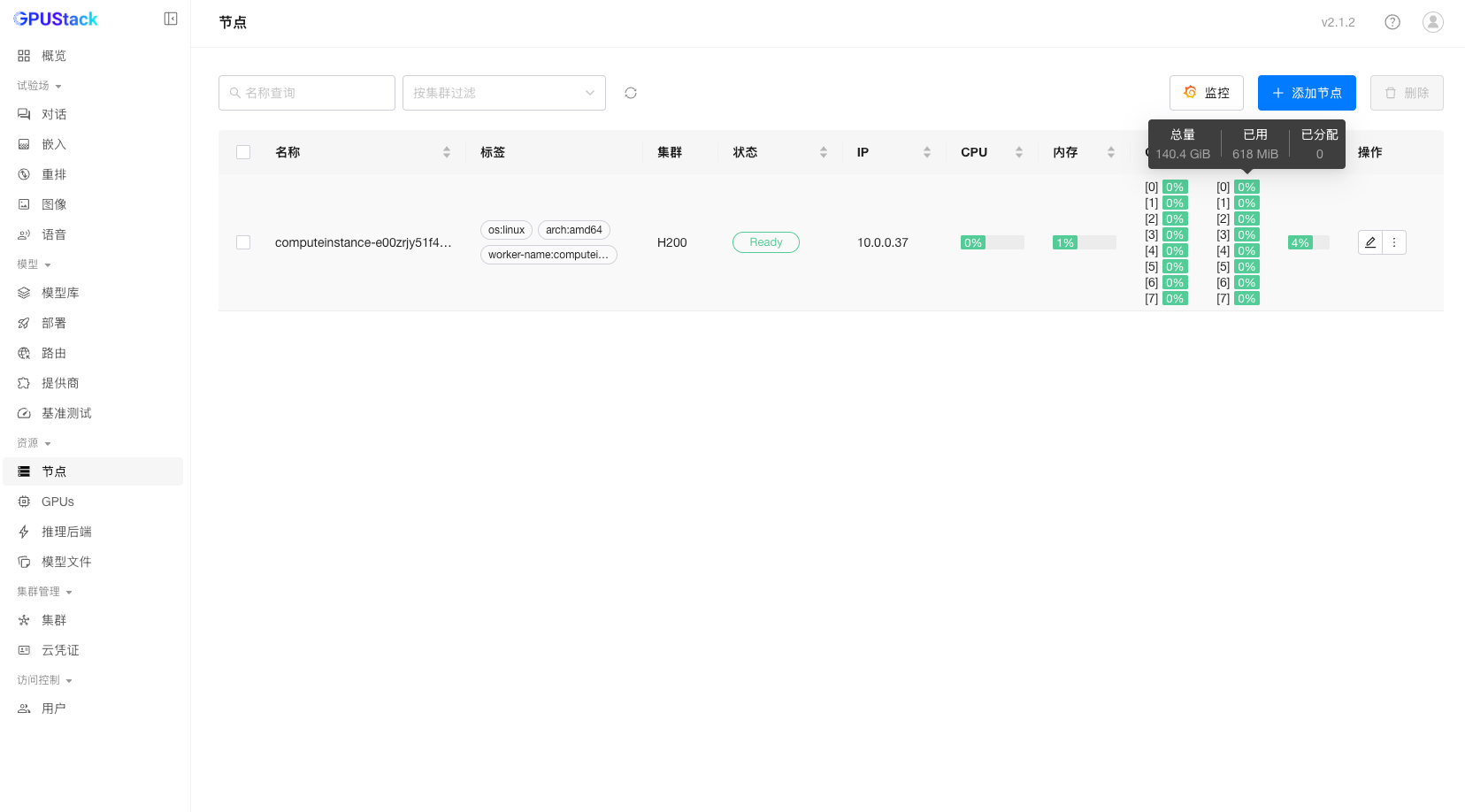
GPU 资源监控数据
添加自定义 vLLM 版本
GPUStack 支持可插拔的推理引擎架构,允许自定义推理后端及其版本,用于引入 GPUStack 未内置的 vLLM / SGLang / MindIE 版本,或接入其他自定义推理引擎镜像。
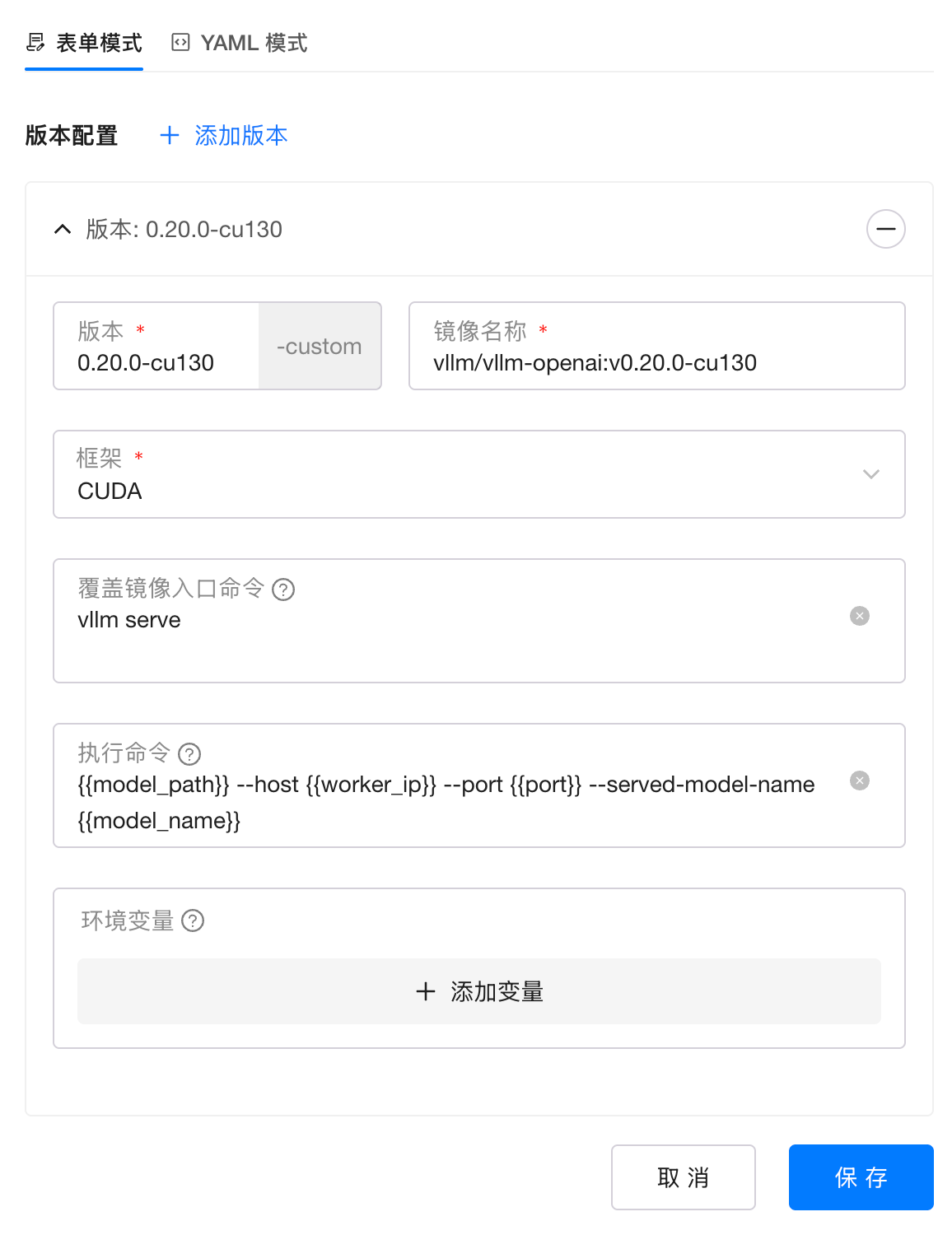
为了部署 DeepSeek V4 模型,需要添加 vLLM 最新发布的支持 DeepSeek V4 构建的 vllm/vllm-openai:v0.20.0-cu130 版本。
vLLM
在推理后端菜单,编辑 vLLM,在版本配置中选择添加版本,添加一个新的 vLLM 版本,指向 vLLM 官方镜像:
| 配置 | 值 |
|---|---|
| 版本 | 0.20.0-cu130 |
| 镜像名称 | vllm/vllm-openai:v0.20.0-cu130 |
| 框架 | CUDA |
| 覆盖镜像入口命令(ENTRYPOINT) | vllm serve |
| 执行命令 | {{model_path}} --host {{worker_ip}} --port {{port}} --served-model-name {{model_name}} |
自定义添加 vLLM 0.20.0-cu130 镜像配置如图所示:
注意:
- GPUStack 会自动调用主机容器运行时拉取容器镜像,需要确保 Worker 节点可访问 Docker Hub,或者提前拉取好并重新 tag,并按需修改 UI 配置中的镜像地址;
- 保持执行命令中的 {{}} 变量内容不变,此为模板化配置。
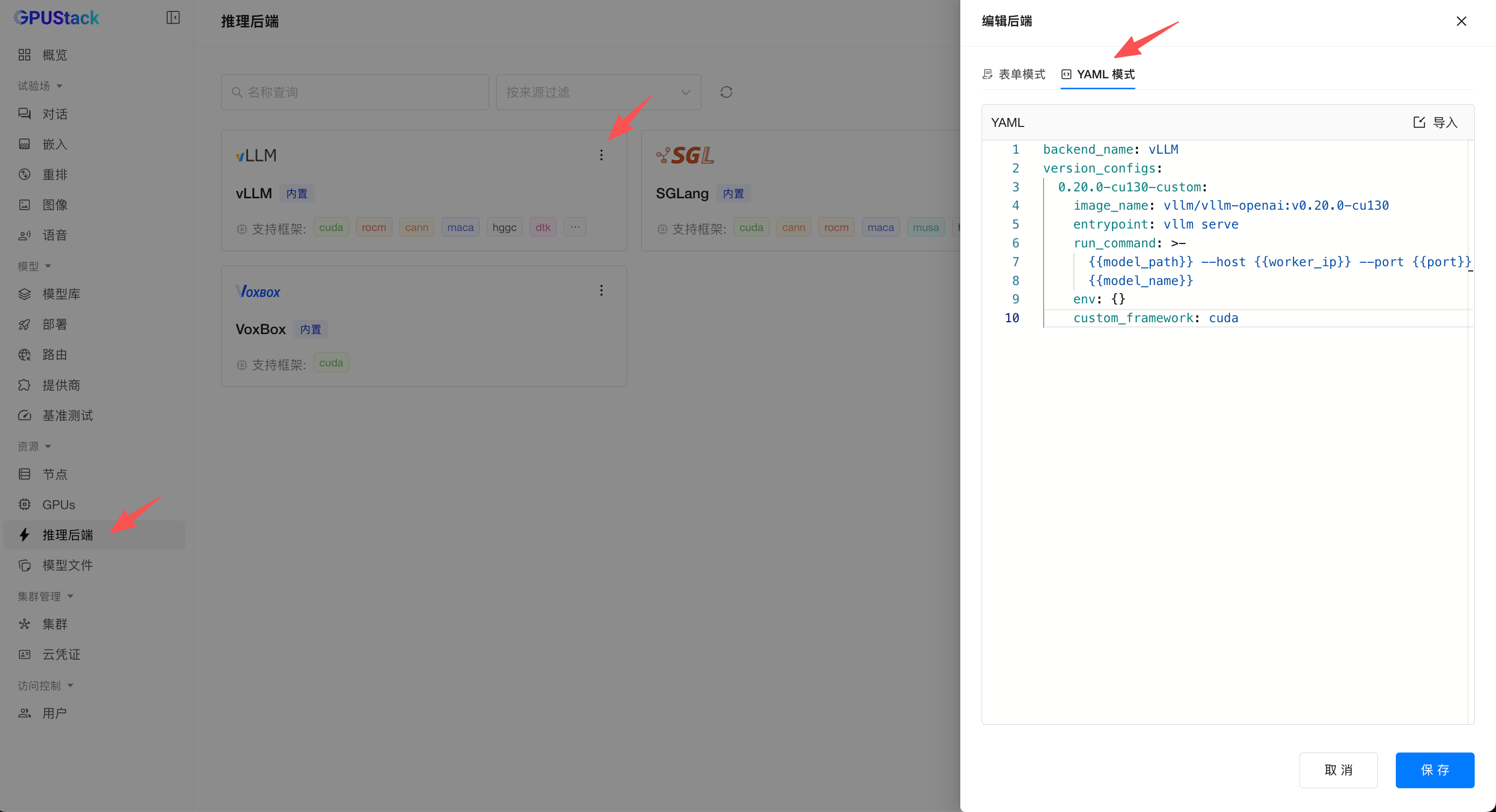
也可以切换到 YAML 模式,直接使用以下的 YAML 导入(公众号复制可能存在特殊格式,可以发送给 AI 重新整理 YAML 格式):
backend_name: vLLM
version_configs:
0.20.0-cu130-custom:
image_name: vllm/vllm-openai:v0.20.0-cu130
entrypoint: vllm serve
run_command: >-
{{model_path}} --host {{worker_ip}} --port {{port}} --served-model-name
{{model_name}}
env: {}
custom_framework: cuda
注意:如果当前已经有其它自定义版本,需要将其它自定义版本一同添加在 version_configs 中一起导入。
部署 DeepSeek V4 模型
vLLM 已提供关于 DeepSeek V4 模型的部署与使用教程,详情可参考:
deepseek-ai/DeepSeek-V4-Pro | vLLM Recipes
以下将介绍在 GPUStack 上部署 DeepSeek V4 Pro 模型的配置流程。
-
在在线环境下,可直接通过 HuggingFace 或 ModelScope 搜索
deepseek-ai/DeepSeek-V4-Pro模型并进行部署,具体步骤参考下方。 -
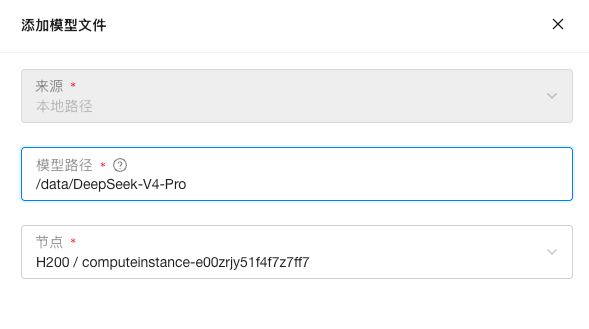
在离线环境中,需要提前下载好模型权重,并将其分发到 Worker 节点,同时挂载到对应的 Worker 容器中。随后,在 GPUStack 控制台 - 模型文件菜单中,选择添加模型文件 - 本地路径,填写对应的模型权重路径。需要注意,这里填写的应为容器内路径,例如:
联网环境:在 GPUStack 控制台 - 部署菜单下,选择 部署模型 → ModelScope,直接搜索 deepseek-ai/DeepSeek-V4-Pro 模型进行部署。
离线环境:可从 GPUStack 控制台 - 模型文件菜单中,选择已添加的 DeepSeek-V4-Pro 模型进行部署。
vLLM
-
后端:选择
vLLM -
版本:选择前面自定义添加的
0.20.0-cu130-custom -
GPU:8 块 H200/H20 141GB GPU
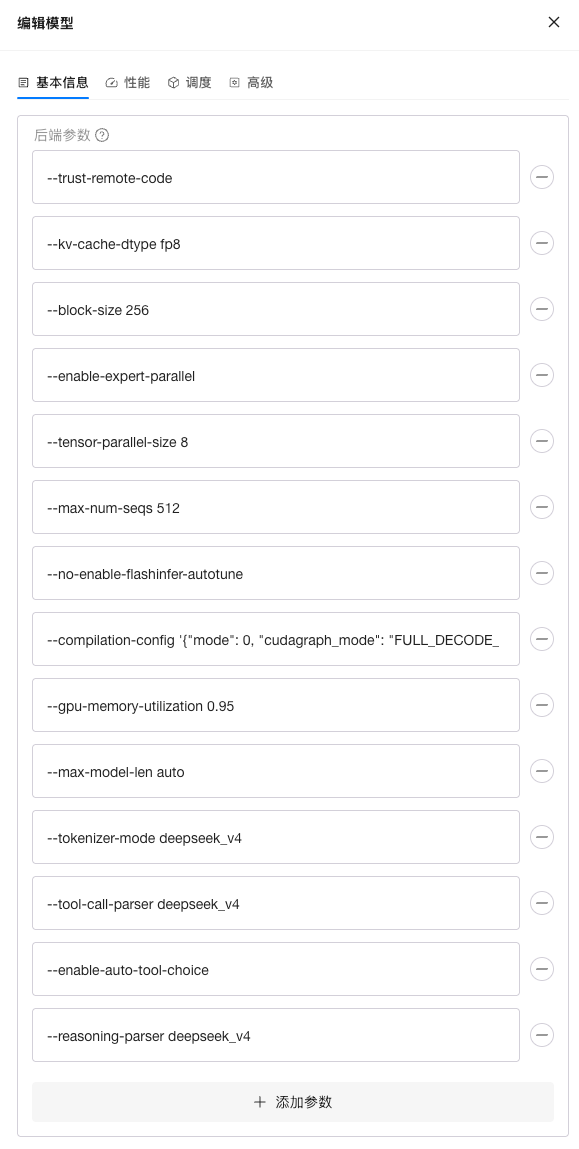
使用以下后端参数和环境变量启动,后端参数支持单行或多行形式(注意已设置 TP 8 DP 1,请确保有八块 GPU 可分配;其它环境请根据实际情况调整并行策略):
# 后端参数
--trust-remote-code
--kv-cache-dtype fp8
--block-size 256
--enable-expert-parallel
# 可选 --data-parallel-size 8
# TP 模式单请求速度高,DP 模式总吞吐量更高,详见下文测试数据
--tensor-parallel-size 8
--max-num-seqs 512
# 默认 8192,会有更佳的性能表现,但在显存资源不足时易发生 OOM
# 512 更稳定,但吞吐性能相对较差,详见下文测试数据
--max-num-batched-tokens 512
--no-enable-flashinfer-autotune
--compilation-config '{"mode": 0, "cudagraph_mode": "FULL_DECODE_ONLY"}'
--gpu-memory-utilization 0.95
# auto 表示自动根据模型最大上下文设置上下文大小
# 注意 H200/H20 141G 设置 1M 上下文时,可用 KV cache 空间难以支撑高并发
# 期望服务更稳定,可以考虑设置上下文到:131072/262144/524288
# 或者考虑双机推理,或者开启扩展 KV 缓存(LMCache/HiCache)
--max-model-len auto
--tokenizer-mode deepseek_v4
--tool-call-parser deepseek_v4
--enable-auto-tool-choice
--reasoning-parser deepseek_v4
# 注意目前 H200/H20 开启 MTP 推测解码存在 Bug,无法启动则需要暂时移除该参数
# 04.27 更新:该参数需要设置为 1
# 04.28 更新:最新的 0.20.0 版本已支持解码 token > 2
--speculative_config '{"method":"mtp","num_speculative_tokens":1}'
# 环境变量
VLLM_ENGINE_READY_TIMEOUT_S=3600
等待模型启动时,可以在操作中点击查看日志,实时观察启动过程:

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)