
sglang radix tree KV cache管理
Ref
https://zhuanlan.zhihu.com/p/31160183506
VLLM KV cache管理参考:
KV cache内存分配
KV cache在sglang.srt.model_executor.model_runner.ModelRunner中的init_memory_pool中分配。
首先根据当前剩余内存除以每个token的kv大小,得到支持的最大token数量max_total_num_tokens:
self.max_total_num_tokens = self.profile_max_num_token(total_gpu_memory)
self.max_total_num_tokens = self.max_total_num_tokens // self.server_args.page_size * self.server_args.page_size
page_size也就是VLLM的KV cache block size,每个cache block连续存储的token数量。
分配kv cache内存分为了3个数据结构:MHATokenToKVPool,TokenToKVPoolAllocator,ReqToTokenPool,在ModelRunner创建,它们的关系:
首先根据GPU的容量,可以得到可以分配的kv cache的max_total_tokens个数,然后使用MHATokenToKVPool分配max_total_tokens个kv cache内存。
TokenToKVPoolAllocator则是为请求分配block id,也就是分配kv cache内存的索引位置,然后把这个索引位置存储在ReqToTokenPool里面。
此外,kv cache的分配和释放还需要RadixCache的参与,这个数据结构以树形结构来进行TokenToKVPoolAllocator分配的prefix cache的存储,以及evict过程中调用TokenToKVPoolAllocator进行释放kv cache id。
ReqToTokenPool
class ModelRunner:
def init_memory_pool()
if self.server_args.disaggregation_mode == "decode":
from sglang.srt.disaggregation.decode import DecodeReqToTokenPool
# subscribe memory for pre-allocated requests
# if max_num_reqs <= 32, we pre-allocate 2x requests
pre_alloc_size = max_num_reqs * 2 if max_num_reqs <= 32 else 0
self.req_to_token_pool = DecodeReqToTokenPool(
size=max_num_reqs, max_context_len=self.model_config.context_len + 4,
device=self.device, enable_memory_saver=self.server_args.enable_memory_saver,
pre_alloc_size=pre_alloc_size,)
else:
self.req_to_token_pool = ReqToTokenPool(
size=max_num_reqs, max_context_len=self.model_config.context_len + 4,
device=self.device, enable_memory_saver=self.server_args.enable_memory_saver,)
class ReqToTokenPool:
"""A memory pool that maps a request to its token locations."""
def __init__(self, size: int, max_context_len: int, device: str, enable_memory_saver: bool,):
memory_saver_adapter = TorchMemorySaverAdapter.create(enable=enable_memory_saver)
self.size = size
self.max_context_len = max_context_len
self.device = device
with memory_saver_adapter.region():
self.req_to_token = torch.zeros((size, max_context_len), dtype=torch.int32, device=device)
self.free_slots = list(range(size))
def alloc(self, need_size: int) -> List[int]:
select_index = self.free_slots[:need_size]
self.free_slots = self.free_slots[need_size:]
return select_index
def free(self, free_index: Union[int, List[int]]):
if isinstance(free_index, (int,)):
self.free_slots.append(free_index)
else:
self.free_slots.extend(free_index)
def write(self, indices, values):
self.req_to_token[indices] = values
ReqToTokenPool内部req_to_token存储的二维张量,对应每个请求id和这个请求的token的kv cache张量在kv cache pool的索引index,类似VLLM 的slot_mapping。
alloc和free分别从free_slots拿走和extend一些slot的index。
write方法把请求的kv cache 索引写入到它对应索引位置中。
例如write((1, slice(0, 8, None)), tensor([8, 9, 10, 11, 12, 13, 14, 15])),这实现了在index=1的请求0:8的token写入8个kv cache index。
TokenToKVPool
if self.use_mla_backend:
self.token_to_kv_pool = MLATokenToKVPool(
self.max_total_num_tokens,
page_size=self.page_size,
dtype=self.kv_cache_dtype,
kv_lora_rank=self.model_config.kv_lora_rank,
qk_rope_head_dim=self.model_config.qk_rope_head_dim,
layer_num=self.model_config.num_hidden_layers,
device=self.device,
enable_memory_saver=self.server_args.enable_memory_saver,
)
else:
self.token_to_kv_pool = MHATokenToKVPool(
self.max_total_num_tokens,
page_size=self.page_size,
dtype=self.kv_cache_dtype,
head_num=self.model_config.get_num_kv_heads(get_attention_tp_size()),
head_dim=self.model_config.head_dim,
layer_num=self.model_config.num_hidden_layers,
device=self.device,
enable_memory_saver=self.server_args.enable_memory_saver,
)MHATokenToKVPool,MLATokenToKVPool,DoubleSparseTokenToKVPool继承自KVCache类,负责分配和管理KV cache的物理存储。提供了get_contiguous_buf_infos用于获取kv cache地址、内存大小等信息。
根据ReqToTokenPool中保存的kv index来访问TokenToKVPool对应的KV cache数据。
MHATokenToKVPool独立分配了key和value cache张量:
class MHATokenToKVPool(KVCache):
def _create_buffers(self):
with self.memory_saver_adapter.region():
# [size, head_num, head_dim] for each layer
# The padded slot 0 is used for writing dummy outputs from padded tokens.
self.k_buffer = [
torch.zeros(
(self.size + self.page_size, self.head_num, self.head_dim),
dtype=self.store_dtype,
device=self.device,
)
for _ in range(self.layer_num)
]
self.v_buffer = [
torch.zeros(
(self.size + self.page_size, self.head_num, self.head_dim),
dtype=self.store_dtype,
device=self.device,
)
for _ in range(self.layer_num)
]
跟VLLM的一些区别:
对于MHA,sglang对key和value独立创建了张量,但是VLLM的key, value合并在一起分配一个张量, 但其实是相当于这两个key, value concat在一起。
VLLM的MHA KV cache format是block_size独占一个维度:[2, block_num, block_size, head_num, head_dim],每个layer独立创建。而sglang的format两者是合并的:[max_token_num, head_num, head_dim]。这是sglang需要针对page_size等于1和不等于1分别开发TokenToKVPoolAllocator和PagedTokenToKVPoolAllocator的原因吗?这个也使得sglang的kv index分配相比VLLM不够优雅。
MLATokenToKVPool因为key,value cache是在一个hidden张量里面,因此分配一个KV cache张量:
class MLATokenToKVPool(KVCache):
with memory_saver_adapter.region():
# The padded slot 0 is used for writing dummy outputs from padded tokens.
self.kv_buffer = [
torch.zeros(
(size + page_size, 1, kv_lora_rank + qk_rope_head_dim),
dtype=self.store_dtype,
device=device,
)
for _ in range(layer_num)
]
针对MLA,sglang的kv cache format是(token_num, 1, kv_lora_rank + qk_rope_head_dim) ,每个layer独立创建。VLLM的format是是(num_gpu_blocks, block_size, hidden_size),例如(8556, 64, 576)。对于MLA两者都是每层创建一个张量,但是foamt解释不一样,VLLM的格式相对更加优雅一些。
TokenToKVPool还提供了get_kv_buffer和set_kv_buffer,为何需要这两个方法?
TokenToKVPoolAllocator
负责分配token的kv cache index(out_cache_loc).
根据page_size是否为1创建了2种对象。为何PagedTokenToKVPoolAllocator不能对page_size==1替换TokenToKVPoolAllocator?
if self.page_size == 1:
self.token_to_kv_pool_allocator = TokenToKVPoolAllocator(
self.max_total_num_tokens,
dtype=self.kv_cache_dtype,
device=self.device,
kvcache=self.token_to_kv_pool,
)
else:
self.token_to_kv_pool_allocator = PagedTokenToKVPoolAllocator(
self.max_total_num_tokens,
page_size=self.page_size,
dtype=self.kv_cache_dtype,
device=self.device,
kvcache=self.token_to_kv_pool,
)TokenToKVPoolAllocator的原理比较简单,提供了两个核心的方法alloc和free:
class TokenToKVPoolAllocator:
"""An allocator managing the indices to kv cache data."""
def alloc(self, need_size: int):
select_index = self.free_slots[:need_size]
self.free_slots = self.free_slots[need_size:]
return select_index
def free(self, free_index: torch.Tensor):
if self.is_not_in_free_group:
self.free_slots = torch.cat((self.free_slots, free_index))
else:
self.free_group.append(free_index)
def free_group_begin(self):
self.is_not_in_free_group = False
self.free_group = []
def free_group_end(self):
self.is_not_in_free_group = True
if self.free_group:
self.free(torch.cat(self.free_group))
def clear(self):
# The padded slot 0 is used for writing dummy outputs from padded tokens.
self.free_slots = torch.arange(1, self.size + 1, dtype=torch.int64, device=self.device)
self.is_not_in_free_group = True
self.free_group = []
alloc从free_slot前面拿取index,然后free添加到free_slots后面。在in_free_group的情况下,free时先放到free_group中,最后一次性释放到free_slots中。
srt/managers/scheduler.py中process_batch_result->process_batch_result_decode中调用了free_group_begin和free_group_end。目的是什么?
PagedTokenToKVPoolAllocator的alloc和free与TokenToKVPoolAllocator基本一样,只是free_slots变成free_pages,一个page是page_size个连续的token。
此外,PagedTokenToKVPoolAllocator还提供了两个独立的方法:alloc_extend和alloc_decode,还写了triton kernel使用GPU对batch的输入情况进行加速。example:
# PagedTokenToKVPoolAllocator log, page_size=16
# first round
alloc_extend prefix_lens=tensor([0], device='cuda:0'), seq_lens=tensor([42], device='cuda:0'), last_loc=tensor([-1], device='cuda:0'), extend_num_tokens=42, len 1
alloc_extend result: out_indices=tensor([16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33,
34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51,
52, 53, 54, 55, 56, 57], device='cuda:0')
alloc_extend alloc num_new_pages: 3
alloc_decode seq_lens=tensor([43], device='cuda:0'), last_loc=tensor([57], device='cuda:0', dtype=torch.int32), len 1
alloc_decode result: out_indices=tensor([58], device='cuda:0')
# second round
alloc_extend prefix_lens=tensor([32], device='cuda:0'), seq_lens=tensor([42], device='cuda:0'), last_loc=tensor([47], device='cuda:0'), extend_num_tokens=10, len 1
alloc_extend result: out_indices=tensor([48, 49, 50, 51, 52, 53, 54, 55, 56, 57], device='cuda:0')
alloc_extend alloc num_new_pages: 1 # 2 pages in kv cache
alloc_decode seq_lens=tensor([43], device='cuda:0'), last_loc=tensor([57], device='cuda:0', dtype=torch.int32), len 1
alloc_decode result: out_indices=tensor([58], device='cuda:0')
alloc_extend调用位置:srt/managers/scheduler.py get_next_batch_to_run() -> get_new_batch_prefill() -> new_batch.prepare_for_extend() ->
srt/managers/schedule_batch.py alloc_paged_token_slots_extend()
alloc_decode调用位置:srt/managers/scheduler.py get_next_batch_to_run() -> update_running_batch(self.running_batch) -> prepare_for_decode -> srt/managers/schedule_batch.py alloc_paged_token_slots_decode()
Tree cache
Scheduler里面调用init_memory_pool_and_cache创建tree_cache,有三种不同的cache方法:
ChunkCache,HiRadixCache,RadixCache。
这个主要用于构建一个prefix cache的存储信息。
if server_args.chunked_prefill_size is not None and server_args.disable_radix_cache:
self.tree_cache = ChunkCache(
req_to_token_pool=self.req_to_token_pool,
token_to_kv_pool_allocator=self.token_to_kv_pool_allocator,
page_size=self.page_size,)
else:
if self.enable_hierarchical_cache:
self.tree_cache = HiRadixCache(
req_to_token_pool=self.req_to_token_pool,
token_to_kv_pool_allocator=self.token_to_kv_pool_allocator,
tp_cache_group=self.tp_cpu_group,
page_size=self.page_size,
hicache_ratio=server_args.hicache_ratio,
hicache_size=server_args.hicache_size,
hicache_write_policy=server_args.hicache_write_policy,)
else:
self.tree_cache = RadixCache(
req_to_token_pool=self.req_to_token_pool,
token_to_kv_pool_allocator=self.token_to_kv_pool_allocator,
page_size=self.page_size,
disable=server_args.disable_radix_cache,)ChunkCache
针对关闭radix cache的场景(disable_radix_cache=True)
match_prefix直接返回空。
cache_finished_req直接释放相关资源
class ChunkCache(BasePrefixCache):
def match_prefix(self, **unused_kwargs) -> Tuple[List[int], int]:
return [], None
def cache_finished_req(self, req: Req):
kv_indices = self.req_to_token_pool.req_to_token[req.req_pool_idx,
# For decode server: if req.output_ids is empty, we want to free all req.origin_input_ids
: len(req.origin_input_ids) + max(len(req.output_ids) - 1, 0),
]
self.req_to_token_pool.free(req.req_pool_idx)
self.token_to_kv_pool_allocator.free(kv_indices)
def cache_unfinished_req(self, req: Req):
kv_indices = self.req_to_token_pool.req_to_token[req.req_pool_idx, : len(req.fill_ids)]
# `req.prefix_indices` will be used in `PrefillAdder::add_chunked_req` later
req.prefix_indices = kv_indices
HiRadixCache
具备CPU的offload能力。
RadixCache
sglang\srt\managers\schedule_batch.Req给请求保存的kv cache相关信息:
class Req:
"""The input and output status of a request."""
self.origin_input_ids = origin_input_ids
# Each decode stage's output ids
self.output_ids = []
# fill_ids = origin_input_ids + output_ids. Updated if chunked.
self.fill_ids = None
# Memory pool info
self.req_pool_idx: Optional[int] = None
# Prefix info
# The indices to kv cache for the shared prefix.
self.prefix_indices = []
# Number of tokens to run prefill.
self.extend_input_len = 0 # extend_input_len = len(self.fill_ids) - len(self.prefix_indices)
# last node in radix tree
self.last_node: Any = None
self.last_host_node: Any = None
self.host_hit_length = 0
cache_unfinished_req
def cache_unfinished_req(self, req: Req):
"""Cache request when it is unfinished."""
if self.disable:
return
token_ids = req.fill_ids
kv_indices = self.req_to_token_pool.req_to_token[
req.req_pool_idx, : len(token_ids)
]
if self.page_size != 1:
page_aligned_len = len(kv_indices) // self.page_size * self.page_size
page_aligned_kv_indices = kv_indices[:page_aligned_len].clone()
else:
page_aligned_len = len(kv_indices)
page_aligned_kv_indices = kv_indices.clone()
page_aligned_token_ids = token_ids[:page_aligned_len]
# Radix Cache takes one ref in memory pool
new_prefix_len = self.insert(page_aligned_token_ids, page_aligned_kv_indices)
# len(req.prefix_indices) 是过去prefix cache的长度,new_prefix_len是新的长度
# 针对同一个batch里面相同prefix cache但是分配不同的kv block id的情况
self.token_to_kv_pool_allocator.free(
kv_indices[len(req.prefix_indices) : new_prefix_len]
)
# The prefix indices could be updated, reuse it
new_indices, new_last_node = self.match_prefix(page_aligned_token_ids)
self.req_to_token_pool.write(
(req.req_pool_idx, slice(len(req.prefix_indices), len(new_indices))),
new_indices[len(req.prefix_indices) :],
)
# 应该是做一个保护作用,避免evit
self.dec_lock_ref(req.last_node)
self.inc_lock_ref(new_last_node)
# `req.prefix_indices` will be used in `PrefillAdder::add_chunked_req` later
if self.page_size != 1:
req.prefix_indices = torch.cat(
[new_indices, kv_indices[len(new_indices) :]]
)
else:
req.prefix_indices = new_indices
req.last_node = new_last_node
通过离线推理的脚本Offline Engine API — SGLang,
sglang对于同一个batch内的多个请求没有命中prefix cache,但是相同前缀部分分配了不同的kv cache idx,而不是相同的。
所以这个cache_unfinished_req出现了
self.token_to_kv_pool_allocator.free(kv_indices[len(req.prefix_indices) : new_prefix_len])然后req_to_token_pool.write()这样的调用。
这个free就是释放同一个batch里面后面request相同分配的那一部分,然后使用前面的请求相同prefix的部分进行替换。
len(req.prefix_indices)是推理前命中的prefix cache长度。而new_prefix_len是推理后命中的prefix cache的长度。如果同一个batch前面的请求有相同的部分,就导致radix tree匹配到的new_prefix_len大于了推理前匹配的长度。因此释放掉重复释放的,用radix tree匹配到的进行替换更新。
cache_finished_req
process_batch_result_prefill, process_batch_result_decode中进行了调用。
在请求完成或者失败后调用,unlock the tree。
RadixCache节点管理
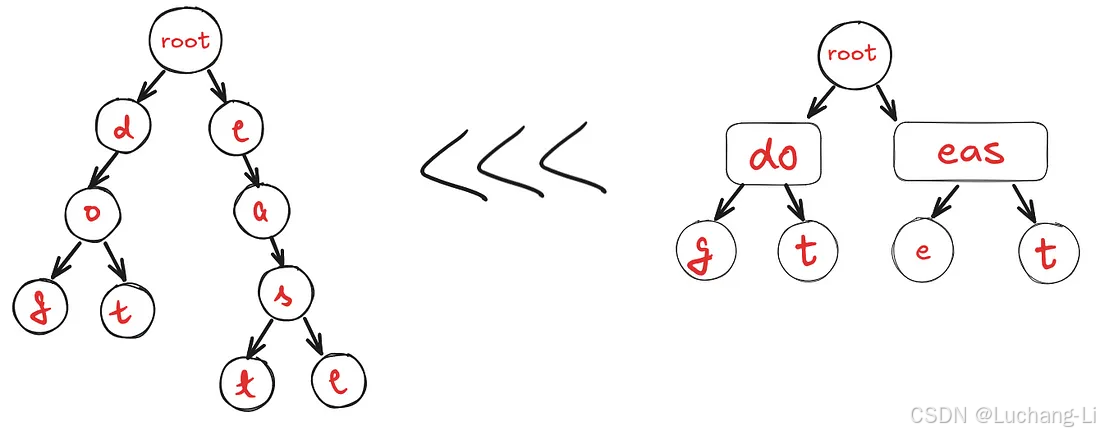
Radix Tree, or compact prefix tree, is an optimization of the Trie that combines nodes with single children to reduce space complexity. It retains the same hierarchical structure but eliminates unnecessary nodes, making it more memory-efficient.
Performance:
- Space Efficiency:By merging nodes with single children, Radix Trees can significantly reduce memory usage compared to standard Tries.
- Search Complexity:The search operation remainsO(m) on average, similar to Tries, but with reduced overhead due to fewer nodes.
sglang的radix tree用于保存token id和kv cache index的映射关系,以及查找不同token序列的公共前缀。
每个节点的key和value是page_size整数倍个token对应的token id和kv cache index。
每个node索引children的key只是首个page size长度的token id,但children里面key和value是更长的token序列。
TreeNode
class TreeNode:
counter = 0
def __init__(self, id: Optional[int] = None):
self.children = defaultdict(TreeNode) # Tuple(int) of token : TreeNode
self.parent = None # TreeNode
self.key = None # token ids
self.value = None # kv index
self.lock_ref = 0
self.last_access_time = time.time()
self.hit_count = 0
# indicating the node is loading KV cache from host
self.loading = False
# store the host indices of KV cache
self.host_value = None
self.id = TreeNode.counter if id is None else id
TreeNode.counter += 1
@property
def evicted(self):
return self.value is None
@property
def backuped(self):
return self.host_value is not None
def __lt__(self, other: "TreeNode"):
return self.last_access_time < other.last_access_time
match_prefix
返回匹配到的prefix kv cache index和最后的叶子节点。
insert
输入key和value分别是token id和每个token的kv cache index,例如
key = [151644, 8948, 198, 2610]
value = tensor([16, 17, 18, 19])insert被调用位置:
process_batch_result -> process_batch_result_prefill -> tree_cache.cache_unfinished_req
process_batch_result -> process_batch_result_decode -> tree_cache.cache_finished_req
insert调用_insert_helper,首先找到现有节点上公共前缀的部分,对于公共前缀没有匹配的剩余部分,先进行split,然后创建一个新子节点,子节点被父节点检索的child_key是未匹配部分key的第一个page_size部分。
返回匹配到的前缀部分长度。
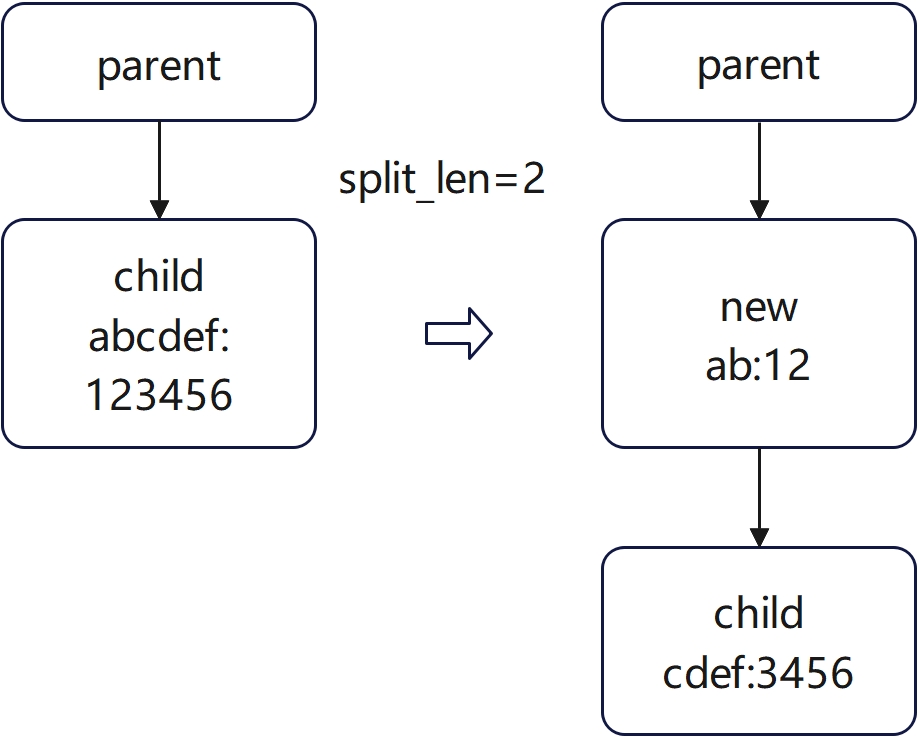
split_node
def _split_node(self, key, child: TreeNode, split_len: int):
# new_node -> child
new_node = TreeNode()
new_node.children = {self.get_child_key_fn(key[split_len:]): child}
new_node.parent = child.parent
new_node.lock_ref = child.lock_ref
new_node.key = child.key[:split_len]
new_node.value = child.value[:split_len]
child.parent = new_node
child.key = child.key[split_len:]
child.value = child.value[split_len:]
new_node.parent.children[self.get_child_key_fn(key)] = new_node
return new_node
split示意图:
inc_lock_ref
从当前叶子节点到根节点的lock_ref加1,这些lock_ref非0的节点不会被驱逐。同时更新evictable_size_和protected_size_。
dec_lock_ref
从当前叶子节点到根节点的lock_ref减1,lock_ref为0的节点可以被驱逐。同时更新evictable_size_和protected_size_。
evict
获得所有叶子节点,然后heapq.heapify(leaves)使得x = heapq.heappop(leaves)优先出栈访问时间最早的节点(TreeNode记录了访问时间并且有一个比较大小的方法)。
对于驱逐的节点,删除这个节点,并且token_to_kv_pool_allocator释放对应的kv cache index。
sglang的radix tree cache设计不足
作者的一些观点:
1,每个radix tree的节点的key应该存储类似VLLM的hash值,而不是token id进行匹配。当前的方法匹配速度比较慢。而且hash对多模态更容易兼容。
2,每个节点的token数量是不固定的,但是是block size的整数倍。我认为每一个节点应该是存一个block/page就可以了,而且key存hash值。这样检索速度更快,避免了split和merge操作。
3,内存格式上,针对MHA,VLLM的page size和page num是独立的维度:[2, block_num, block_size, head_num, head_dim],但是sglang是合并的:[max_token_num, head_num, head_dim],这一点,VLLM在page管理更加方便和简洁。而sglang却针对page size是否为1做额外处理,以及token id到page id都更加复杂。
radix tree相比VLLM的hashmap方式,匹配速度会慢一些,但是优势在于能够保存不同hash block之间的关系,这个对于evit来说更加方便,可以做更多策略的evit。例如evit可以精确的驱逐叶子节点,但是VLLM的hash map做不到这一点。hash map LRU驱逐方法可能驱逐了一个token序列中间的部分,而有一些叶子部分即使没有被驱逐也无法产生prefix cache效果。

免费领 150 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 7
7 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)