
vLLM:大模型推理的速度革命
摘要:在大模型落地的关键瓶颈中,推理性能始终是绕不开的挑战。vLLM 凭借其革命性的 PagedAttention 技术和 V1 Engine 架构,将 GPU 显存浪费率从传统的 60-80% 压缩至不足 4%,并通过连续批处理(Continuous Batching)和零开销前缀缓存(Prefix Caching)实现了数倍乃至数十倍的吞吐量提升。本文将从架构原理、快速上手、性能优化到生产部署,全方位解析这一开源推理引擎如何重塑 LLM 服务的基础设施。
引言:大模型时代的推理瓶颈
自 ChatGPT 引爆大模型浪潮以来,业界关注的焦点长期集中在训练环节——更大的模型、更长的上下文、更高效的分布式训练框架。然而,当企业真正尝试将大模型落地到客服、代码生成、内容创作等场景时,一个残酷的现实浮出水面:推理成本往往占据总成本的 70% 以上,而推理性能直接决定了用户体验和商业模式的可行性。
传统的 HuggingFace Transformers 推理 pipeline 采用静态批处理(Static Batching),即等待一组请求全部完成后才释放 GPU 资源。这种"短板效应"导致 GPU 利用率极低——一个生成 500 tokens 的请求会阻塞同批次所有其他请求,直到最慢的请求结束。在 100 个并发用户的场景下,未经优化的推理服务几乎瞬间饱和。
vLLM 的诞生正是为了解决这一痛点。作为由伯克利大学 Sky Computing Lab 发起并快速成长为社区驱动的开源项目,vLLM 通过操作系统级别的内存管理思想重构了 LLM 的 KV Cache 机制,配合 V1 Engine 的多进程架构革新,实现了生产级的吞吐量飞跃。截至 2026 年,vLLM 已支持从 NVIDIA H100 到 AMD MI300X、从 Google TPU 到 Intel Gaudi 的广泛硬件生态,并原生提供 OpenAI 兼容 API,成为大模型推理的事实标准。
第一部分:vLLM 核心概念与架构
1.1 什么是 vLLM?
vLLM 是一个专为高吞吐量、低延迟 LLM 推理设计的开源引擎。与传统的 HuggingFace Transformers 相比,其核心差异在于:
| 特性 | HuggingFace Transformers | vLLM |
|---|---|---|
| 批处理策略 | 静态批处理 | 连续批处理(Continuous Batching) |
| KV Cache 管理 | 预分配连续内存,碎片严重 | PagedAttention 分页管理,<4% 浪费 |
| 内存效率 | 60-80% 显存浪费 | <4% 显存浪费 |
| 并发能力 | 低,受限于最长请求 | 高,请求动态进出 |
| API 兼容性 | 需自行封装 | 原生 OpenAI 兼容 |
| 多 GPU 支持 | 需手动实现 | 内置 Tensor/Pipeline/Expert Parallelism |
vLLM 的定位并非替代 Transformers 的训练能力,而是专注于推理服务化——将实验室中的模型转化为可承载数千 QPS 的生产服务。
1.2 核心架构:从 PagedAttention 到 V1 Engine
PagedAttention:解决内存墙问题
Transformer 推理的核心开销在于 KV Cache(键值缓存)——存储每个 token 的注意力键和值以便后续复用。传统实现为每个请求预分配一段连续的 GPU 内存,这带来了两个致命问题:
- 内部碎片:请求实际生成长度不确定,预分配空间往往过剩;
- 外部碎片:不同长度的请求释放后,内存池出现不连续空洞,无法被大请求复用。
vLLM 的 PagedAttention 灵感直接来源于操作系统的虚拟内存分页机制:
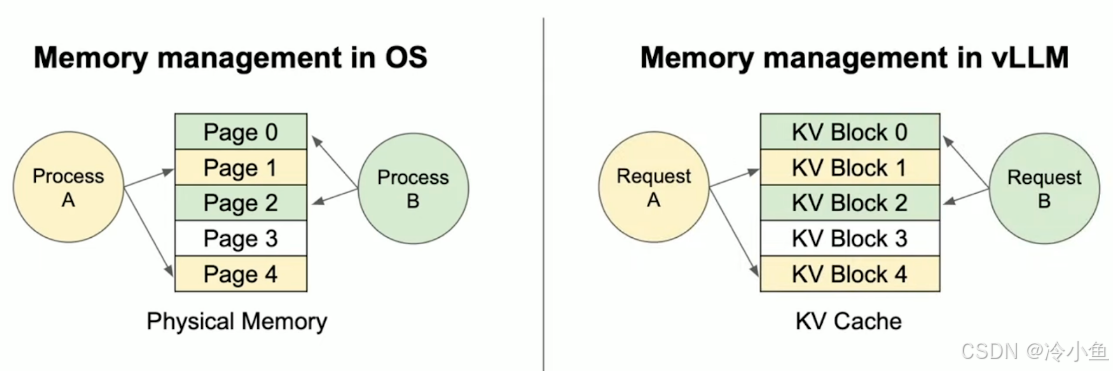
如图所示,vLLM 将 KV Cache 分割为固定大小的块(Block,通常为 16 个 token),通过块表(Block Table) 维护逻辑块到物理块的映射。这种设计的优势在于:
- 非连续存储:一个请求的逻辑块可以分散在物理内存的任意位置,彻底消除外部碎片;
- 动态增长:请求只需按需申请新块,无需预先分配最大可能长度;
- 共享复用:多个请求可以共享相同的物理块(如系统提示词、RAG 文档前缀),通过引用计数实现零拷贝共享。
实际效果惊人:在 vLLM 的基准测试中,GPU 显存浪费率从传统方案的 60-80% 降至不足 4%,这意味着在同等硬件上可服务的并发请求数量提升了一个数量级。
V1 Engine:架构的彻底重构
如果说 PagedAttention 解决了内存效率问题,那么 2025 年初发布的 V1 Engine(自 v0.8.0 起成为默认引擎)则解决了 CPU 开销瓶颈。随着 GPU 越来越快(如 H100 上单步推理仅需 ~5ms),Python 层面的调度、输入准备、反 tokenization 等 CPU 操作成为新的瓶颈。
V1 Engine 的核心架构采用多进程分离设计:
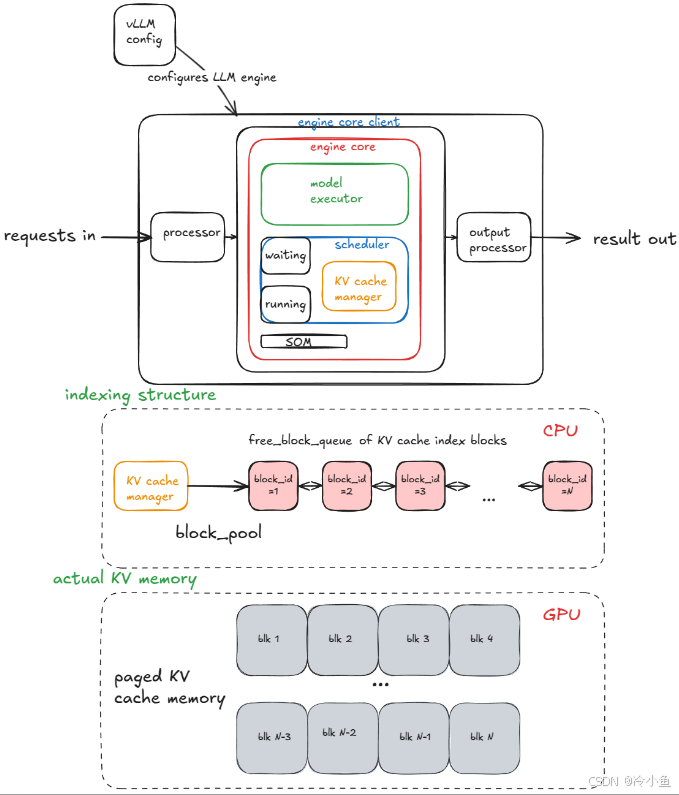
关键组件包括:
- API Server Process:处理 HTTP 请求、tokenization、多模态输入加载和流式输出。通过 ZMQ 与 Engine Core 通信,默认数量为 1(数据并行时自动扩展)。
- Engine Core Process:运行调度器、管理 KV Cache、协调 GPU Worker。采用 busy loop 持续调度请求,每数据并行 rank 一个进程。
- GPU Worker Processes:每个 GPU 一个独立进程,负责加载模型权重、执行前向传播和管理 GPU 内存。
- DP Coordinator Process(可选):数据并行时协调负载均衡和 MoE 模型的同步前向传播。
V1 Engine 的几项关键创新:
- 统一调度器:V0 区分 prefill(计算 prompt 的 KV Cache)和 decode(逐 token 生成)两个阶段,V1 将两者统一为
{request_id: num_tokens}的调度决策,天然支持 Chunked Prefill 和投机解码; - 零开销前缀缓存:通过优化数据结构和最小化 Python 对象创建,即使缓存命中率为 0%,吞吐量损失也小于 1%,因此 V1 默认启用前缀缓存;
- Persistent Batch:缓存 GPU 输入张量,每步仅传输增量更新(diffs),大幅减少 CPU-GPU 数据传输;
- 状态化 Worker:Worker 维护请求状态,调度器只需发送增量指令,而非完整的请求信息。
实测数据显示,V1 Engine 在 Llama 3.1 8B 和 70B 模型上实现了最高 1.7 倍的吞吐量提升,在视觉模型(如 Qwen2-VL)上增益更为显著。
连续批处理(Continuous Batching)
与静态批处理等待整批完成不同,vLLM 的连续批处理在**每个迭代步(iteration)**重新决定哪些请求参与下一次 GPU 调用:
迭代 1: Req A tok1 | Req B tok1 | Req C tok1 | Req D tok1
迭代 2: Req A tok2 | Req B tok2 | [EOS B] | Req D tok2
迭代 3: Req A tok3 | [Req E 入] | Req E tok1 | Req D tok3
迭代 4: [EOS A] | Req E tok2 | [Req F 入] | Req D tok4
一旦请求 B 在迭代 2 完成(遇到 EOS 或达到 max_tokens),其 GPU slot 立即被队列中的请求 E 取代,零空闲时间。这种迭代级调度是 vLLM 实现高 GPU 利用率的核心机制。
第二部分:vLLM 的安装与快速上手
2.1 环境准备
硬件要求:
- GPU:NVIDIA Ampere 架构及以上(A100/H100/H200/RTX 4090 等),支持 FP8 的 Hopper/Ada 架构可获得额外收益;
- 显存:7B 模型约需 14GB+(FP16),通过 FP8/AWQ 量化可降至 7GB+;
- CPU:建议多核处理器,V1 Engine 的分离架构对 CPU 资源有一定需求。
软件依赖:
- Python 3.9-3.12(v0.20+ 支持 Python 3.14)
- PyTorch 2.2+(CUDA 12.1/13.0)
- CUDA 11.8+(推荐 12.1 或 13.0)
2.2 安装指南
通过 pip 安装(推荐):
# 基础安装
pip install vllm
# 指定 CUDA 版本(如 CUDA 12.1)
pip install vllm --extra-index-url https://download.pytorch.org/whl/cu121
# 从源码编译(如需最新特性)
git clone https://github.com/vllm-project/vllm.git
cd vllm
pip install -e .
Docker 部署:
docker run --runtime nvidia --gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-p 8000:8000 \
vllm/vllm-openai:latest \
--model meta-llama/Llama-3.1-8B-Instruct
2.3 第一个 vLLM 程序
离线推理(Python API):
from vllm import LLM, SamplingParams
# 加载模型(自动从 HuggingFace 下载)
llm = LLM(model="Qwen/Qwen2.5-7B-Instruct")
# 配置采样参数
params = SamplingParams(
temperature=0.7,
top_p=0.9,
max_tokens=512,
stop=["</s>"]
)
prompts = [
"解释什么是 PagedAttention",
"vLLM 的核心优势是什么?",
]
outputs = llm.generate(prompts, params)
for output in outputs:
print(f"生成 {len(output.outputs[0].token_ids)} tokens: {output.outputs[0].text}")
启动 OpenAI 兼容服务:
vllm serve Qwen/Qwen2.5-7B-Instruct \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.90 \
--max-model-len 8192 \
--port 8000
关键参数解读:
--tensor-parallel-size:张量并行度,多 GPU 时设置为 GPU 数量;--gpu-memory-utilization:GPU 显存使用比例,建议生产环境 0.90-0.95,保留余量防止 OOM;--max-model-len:最大序列长度,直接影响 KV Cache 预分配量;--dtype:数据类型,可选 auto/fp16/bf16/fp8,H100 推荐 fp8。
客户端调用:
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="dummy")
response = client.chat.completions.create(
model="Qwen/Qwen2.5-7B-Instruct",
messages=[{"role": "user", "content": "Hello!"}]
)
print(response.choices[0].message.content)
第三部分:vLLM 进阶技巧与性能优化
3.1 模型加载与配置
支持的模型格式:
- HuggingFace 原生:直接通过
model_id加载; - 量化模型:GPTQ、AWQ、FP8、GGUF 等,vLLM 自动识别量化配置;
- 多模态:支持 Qwen-VL、LLaVA 等视觉语言模型。
多 GPU 部署:
# 张量并行(TP):适合 NVLink 互联 GPU
vllm serve meta-llama/Meta-Llama-3.1-70B-Instruct \
--tensor-parallel-size 2 \
--dtype bfloat16
# 数据并行(DP):多副本独立服务
vllm serve Qwen/Qwen2.5-7B-Instruct \
--data-parallel-size 4
# 混合并行(TP + DP)
vllm serve deepseek-ai/DeepSeek-V3 \
--tensor-parallel-size 4 \
--data-parallel-size 2
3.2 性能调优
关键参数策略:
| 参数 | 作用 | 调优建议 |
|---|---|---|
--max-num-batched-tokens |
每批最大 token 数 | 根据 GPU 显存和模型大小调整,增大可提升吞吐量 |
--max-num-seqs |
最大并发序列数 | 高并发场景适当增大,需配合显存监控 |
--gpu-memory-utilization |
GPU 显存使用比例 | 生产建议 0.90-0.95,留 5-10% 余量 |
--enable-prefix-caching |
前缀缓存(V1 默认开启) | RAG/多轮对话场景必开,命中率高时数倍提升 |
--num-scheduler-steps |
调度器前瞻步数 | 增大可减少调度开销,但增加延迟 |
量化策略:
- FP8:H100/H200 原生支持,显存减半,精度损失 <1%,无需预量化模型;
- AWQ 4-bit:显存减少 ~75%,适合 70B+ 大模型在消费级 GPU 部署;
- GPTQ:成熟稳定的 4-bit 方案,社区支持广泛。
结构化输出(JSON 模式):
from pydantic import BaseModel
from vllm.sampling_params import GuidedDecodingParams
class Product(BaseModel):
name: str
price: float
category: str
params = SamplingParams(
temperature=0.0,
guided_decoding=GuidedDecodingParams(json=Product.model_json_schema())
)
# 输出严格符合 JSON Schema,无需后处理
3.3 与生态框架集成
LangChain:
from langchain_community.llms import VLLMOpenAI
llm = VLLMOpenAI(
openai_api_key="dummy",
openai_api_base="http://localhost:8000/v1",
model_name="Qwen/Qwen2.5-7B-Instruct"
)
LlamaIndex:
from llama_index.llms.vllm import Vllm
llm = Vllm(
model="Qwen/Qwen2.5-7B-Instruct",
api_url="http://localhost:8000/v1",
max_new_tokens=512
)
第四部分:vLLM 在实际生产中的应用
4.1 适用场景
- 高并发 API 服务:客服机器人、代码补全、实时翻译等需要毫秒级响应的场景;
- 大规模批处理:数据集生成、离线评估、A/B 测试等吞吐量优先任务;
- 多租户 SaaS 平台:通过 Multi-LoRA 在单一 GPU 上服务数十个微调模型;
- Agent 与工具调用:结构化输出保证工具参数格式正确,降低重试率。
4.2 部署方案
生产级 systemd 服务:
# /etc/systemd/system/vllm.service
[Unit]
Description=vLLM Inference Service
After=network.target
[Service]
Type=notify
User=vllm
Group=vllm
Environment=HF_TOKEN=your_token
Environment=VLLM_API_KEY=your_secret
ExecStart=/usr/local/bin/vllm serve meta-llama/Llama-3.3-70B-Instruct \
--dtype fp8 \
--max-model-len 16384 \
--gpu-memory-utilization 0.90 \
--max-num-seqs 256 \
--host 127.0.0.1 \
--port 8000
Restart=on-failure
[Install]
WantedBy=multi-user.target
Kubernetes 部署要点:
- 使用 NVIDIA Device Plugin 暴露 GPU 资源;
- 配置 startup/readiness/liveness probes;
- 通过 KEDA 基于队列深度自动扩缩容;
- 监控 TTFT p99、KV Cache 利用率、请求队列深度等关键指标。
安全加固:
- 使用
VLLM_API_KEY环境变量启用 Bearer Token 认证; - 通过 Nginx 反向代理处理 TLS 和速率限制;
- 避免在命令行直接传递
--api-key(会被其他用户通过/proc/<PID>/cmdline看到)。
4.3 案例分享
- DeepSeek V4 大规模服务:通过 vLLM 的 Wide-EP(弹性专家并行)和 MTP(多 token 预测),在 H200 集群上实现 2.2k tokens/s 的吞吐量;
- Amazon SageMaker 多 LoRA 服务:单 GPU 实例同时服务数十个微调适配器,显著降低多租户成本;
- Mooncake 分离式部署:通过 Prefill-Decode 分离架构,将长上下文 prefill 和短延迟 decode 分布在不同节点,优化资源配比。
第五部分:vLLM 的未来发展与社区
5.1 最新动态与发展方向(2026)
截至 2026 年中,vLLM 的最新版本已演进至 v0.20.x/v0.21.x,核心发展方向包括:
- 推理与训练一体化:原生 RL API 支持,与 TorchTitan 配合实现 bitwise 一致的在线强化学习,消除训练-推理不一致性;
- 多模态原生支持:vLLM-Omni 支持扩散模型和全模态模型服务,Encoder 分离架构优化多模态推理;
- 投机解码(Speculative Decoding):EAGLE 3.1、P-EAGLE 等并行投机解码方案,最高 2.8x 加速;
- 量化前沿:AutoRound、TurboQuant、MXFP4 等低比特量化方案持续集成,平衡精度与效率;
- 硬件生态扩展:AMD ROCm、Intel Gaudi、Google TPU、华为 Ascend 等后端持续优化,实现真正的硬件无关部署。
5.2 社区与贡献
vLLM 采用开放的 Apache 2.0 许可证,拥有活跃的开源社区:
- GitHub:https://github.com/vllm-project/vllm
- 官方文档:https://docs.vllm.ai
- 博客与案例:https://vllm.ai/blog
贡献途径:
- 代码贡献:从 good first issue 入手,涵盖内核优化、新模型支持、硬件后端等;
- 文档改进:完善中文文档、教程和最佳实践;
- 性能基准:提交不同硬件和模型组合的 benchmark 数据;
- 插件开发:利用 vLLM 的插件系统扩展自定义功能。
结论
vLLM 通过 PagedAttention 的内存管理革命和 V1 Engine 的架构重构,将大模型推理从"实验室玩具"转变为"生产级基础设施"。它将 GPU 显存浪费率压缩至不足 4%,通过连续批处理和零开销前缀缓存实现了数量级的吞吐量提升,并以原生 OpenAI 兼容 API 降低了迁移成本。
无论你是希望在单张 RTX 4090 上部署 7B 模型,还是在 H100 集群上服务千亿参数 MoE 模型,vLLM 都提供了成熟的解决方案。随着 2026 年推理-训练一体化、多模态原生支持和更广泛的硬件生态的持续演进,vLLM 正在重新定义 LLM 推理的性价比边界。
现在就开始你的 vLLM 之旅:
pip install vllm
vllm serve Qwen/Qwen2.5-7B-Instruct
附录
常见问题解答(FAQ)
Q: vLLM 与 Ollama 如何选择?
A: Ollama 面向本地开发和个人使用,一键安装、管理方便;vLLM 面向生产级多用户服务,支持连续批处理、量化、多 GPU 和 OpenAI 兼容 API。100+ 并发用户场景请选择 vLLM。
Q: 前缀缓存何时生效?
A: 适用于共享系统提示、RAG 文档前缀、少样本模板等场景。V1 Engine 默认开启,即使 0% 命中率也仅有 <1% 开销。
Q: 如何降低显存占用?
A: 三大利器:(1) FP8 量化(~50% 显存节省,H100 原生支持);(2) AWQ 4-bit(~75% 节省);(3) 张量并行(多 GPU 分担)。
性能基准参考
| 模型 | 硬件 | 配置 | 吞吐量 |
|---|---|---|---|
| Llama 3.1 8B | H100 | FP16, TP=1 | ~5,000 tokens/s |
| Llama 3.1 70B | 2×H100 | FP8, TP=2 | ~2,000 tokens/s |
| DeepSeek V4 | 8×H200 | FP8, Wide-EP | ~2,200 tokens/s |
参考资料
- vLLM 官方文档:https://docs.vllm.ai
- V1 Engine 架构详解:https://vllm.ai/blog/2025-01-27-v1-alpha-release
- PagedAttention 论文:https://arxiv.org/abs/2309.06180
- GitHub 仓库:https://github.com/vllm-project/vllm

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)