
ROCm Reduce算子(Warp Shuffle/SMEM规约)
·
Reduce
规约操作,实际上就是把一个张量的所有元素,汇总到一个值。汇总可以是求和,求max。这里以求和为例。
本文研究一下ROCm版Reduce的两种写法,以及分析线程束分化对性能的影响。
写法1:块内同步
每个线程块负责一个区域,整个线程块内的所有线程一起写作,由于执行基本单位是线程束不是线程块,块内的不同线程束之间是异步的,需要加上强制同步屏障。
extern __shared__ float sdata[];动态共享内存,编译时不确定,通过kernel launch时的参数,运行时确定。int global = blockIdx.x * blockDim.x * 2 + tid;计算当前线程的全局编号if (global < n) sum += in[global];用全局编号,去全局内存中的初始数据读取if (global + blockDim.x < n) sum += in[global + blockDim.x];经典跨步读取,一个线程会读取多个位置,提高计算密度。这里相当于每个线程块,会负责blockDim.x * 2长度的一个区间。sdata[tid] = sum;读到的数据存入共享内存,等待后续规约__syncthreads();块内所有线程都读完才能继续,但是块内不同线程束是不同步的,需要强制同步for (int stride = blockDim.x / 2; stride > 0; stride >>= 1)经典规约算法,类似于log x次操作求出x位整形的1个数奇偶,每次都把有效范围内后一半元素折叠到前一半。比如64个元素的话,开始把[32,63]折叠到[0,31],有效范围变为[0,31],然后下一步把[16,31]折叠到[0,15],以此类推直到有效元素只剩一个。if (tid < stride)为了保证每次都折叠到前一半,需要if else判断线程是否位于前一半,这就引入了线程束分化__syncthreads();同样吗,每一轮折叠必须所有线程都完成了才能进入下一轮,但不同线程束是异步的,需要强制同步if (tid == 0) out[blockIdx.x] = sdata[0];我们最后把每个线程块的元素规约成了一个值,根据线程块编号写入答案数组。这里并没有一步到位把整个数组规约成一个元素,而是类似于一个递归,每次都把问题规模缩小,然后多次调用这个内核实现规约到只剩一个元素
这个内核比较简单,但是有明显的性能问题,一是线程束分化if (tid < stride),造成分化的线程束并行度降低,退化成串行。而是频繁的__syncthreads();使得很多已经完成工作的线程处于阻塞,必须等待少数几个未完成的线程。如何避免这两点?我们来看下一个内核。
// 版本1:分支+同步的传统 reduction
__global__ void reduce_branchy(const float* __restrict__ in,
float* __restrict__ out,
int n) {
extern __shared__ float sdata[];
int tid = threadIdx.x;
int global = blockIdx.x * blockDim.x * 2 + tid;
float sum = 0.0f;
if (global < n) sum += in[global];
if (global + blockDim.x < n) sum += in[global + blockDim.x];
sdata[tid] = sum;
__syncthreads();
for (int stride = blockDim.x / 2; stride > 0; stride >>= 1) {
if (tid < stride) {
sdata[tid] += sdata[tid + stride];
}
__syncthreads();
}
if (tid == 0) out[blockIdx.x] = sdata[0];
}
写法2:Warp级规约
每个block不同步,但是每个线程束是同步的。那么能不能考虑把规约的基本单位设为一个线程束。每个线程束各自规约,把结果写到一个临时数组,最后再启动一个线程束把临时数组规约,得到整个块的结果
wf_reduce_sum先实现一个线程束规约的函数for (int offset = WARP_SIZE / 2; offset > 0; offset >>= 1)内部折叠思路和线程块折叠类似,只是把范围改成从线程束大小开始,而不是块大小开始__shfl_down(v, offset, WARP_SIZE);规约操作和整块规约完全不同。同一线程束,有内置函数,不用访问共享内存。这个函数的意思是读取当前线程编号增加offset后的另一个线程的v变量,如果增加offset后超出warp_size则结果为0。这是利用了同一warp的线程之间,存在直接的数据通路,不用借助共享内存进行通信。int lane = tid % WARP_SIZE;当前线程在线程束内的编号。我们默认全局的所有线程,就是没warp_sizeg个划分成一个warpint wid = tid / WARP_SIZE;当前线程所在的线程束编号。float wf_sum = wf_reduce_sum(v);每个线程都一起执行线程束规约函数,由于线程束内是同步的,不需要同步屏障了if (lane == 0) wf_sums[wid] = wf_sum;线程束规约结束了,线程束内第一个线程负责把结果写入临时数组__syncthreads();这里由于不同线程束之间还是不同步的,需要一个同步屏障if (wid == 0)每个线程束的结果都写入数组了,让第一个线程束来对临时数组再次进行线程束规约,得到整个线程块的答案int num_waves = (blockDim.x + WARP_SIZE - 1) / WARP_SIZE;首先计算当前线程块内线程束个数float x = (lane < num_waves) ? wf_sums[lane] : 0.0f;如果线程束个数小于线程束内线程个数,多出来的线程也要参与计算,只是把初始数据赋值为0。由于是线程束内规约,不读SMEM,直接把数据放到一个寄存器变量里- 再次执行线程束规约得到整块结果
float block_sum = wf_reduce_sum(x); if (lane == 0) out[blockIdx.x] = block_sum;当前线程数的第一个线程写入全局答案数组
这个版本有几个有点:
- 一是整个warp内都是同步的,不需要额外的同步操作,
- 二是warp内操作都相同,没有线程束发散,
- 三是不用走SMEM,数据搬运更快。
// wavefront shuffle sum
__device__ __forceinline__ float wf_reduce_sum(float v) {
for (int offset = WARP_SIZE / 2; offset > 0; offset >>= 1) {
v += __shfl_down(v, offset, WARP_SIZE);
}
return v;
}
__global__ void reduce_shuffle(const float* __restrict__ in,
float* __restrict__ out,
int n) {
extern __shared__ float wf_sums[];
int tid = threadIdx.x;
int idx = blockIdx.x * blockDim.x * 2 + tid;
float v = 0.0f;
if (idx < n) v += in[idx];
if (idx + blockDim.x < n) v += in[idx + blockDim.x];
float wf_sum = wf_reduce_sum(v);
int lane = tid % WARP_SIZE;
int wid = tid / WARP_SIZE;
if (lane == 0) wf_sums[wid] = wf_sum;
__syncthreads();
if (wid == 0) {
int num_waves = (blockDim.x + WARP_SIZE - 1) / WARP_SIZE;
float x = (lane < num_waves) ? wf_sums[lane] : 0.0f;
float block_sum = wf_reduce_sum(x);
if (lane == 0) out[blockIdx.x] = block_sum;
}
}
多次调用
前面说过,这内核只是把每个block都规约成一个数,每做一次数组长度/block_size,想要实现规约到一个元素,需要对内核进行封装,循环调用,代码如下
int max_blocks = (n + (threads * 2 - 1)) / (threads * 2);首先计算第一轮的block数,用来申请缓冲区,每个线程负责两个元素,所以块长是block线程数的两倍float* d_buf1 = nullptr;float* d_buf2 = nullptr;定义两个缓冲区,因为reduce的输入输出必须是两个数组,多次调用reduce至少需要两个缓冲区,来回倒着用。auto launch_once = [&](int cur_n, const float* cur_in, float* cur_out)一个lambda表达式,传入输入,输出缓冲区,以及当前的有效元素个数,执行一轮规约int blocks = (cur_n + (threads * 2 - 1)) / (threads * 2);计算当前的block数if (use_shuffle)判断使用哪个内核smem = num_waves * sizeof(float);根据每个block启动的warp数,确定每个block所需的共享内存大小,前面我们声明的extern SMEM会被初始化为这个大小int next_n = launch_once(cur_n, cur_in, cur_out);启动一次的函数,返回值是这次规约后的有效元素个数,将这个作为下一轮的规约长度cur_in = cur_out;这一轮的规约结果,作为下一轮的规约输入cur_out = (cur_out == d_buf1) ? d_buf2 : d_buf1;下一轮使用和这一轮不一样的数组作为输出缓冲区,类似于滚动数组优化的思路while (cur_n > 1)重复规约直到有效元素只剩一个
// Host:多轮 reduction 直到剩一个数
float run_reduce(const float* d_in, int n,
bool use_shuffle,
int threads, int iterations) {
hipEvent_t start, stop;
HIP_CHECK(hipEventCreate(&start));
HIP_CHECK(hipEventCreate(&stop));
int max_blocks = (n + (threads * 2 - 1)) / (threads * 2);
float* d_buf1 = nullptr;
float* d_buf2 = nullptr;
HIP_CHECK(hipMalloc(&d_buf1, max_blocks * sizeof(float)));
HIP_CHECK(hipMalloc(&d_buf2, max_blocks * sizeof(float)));
auto launch_once = [&](int cur_n, const float* cur_in, float* cur_out) {
int blocks = (cur_n + (threads * 2 - 1)) / (threads * 2);
size_t smem = 0;
if (use_shuffle) {
int num_waves = (threads + WARP_SIZE - 1) / WARP_SIZE;
smem = num_waves * sizeof(float);
hipLaunchKernelGGL(reduce_shuffle, dim3(blocks), dim3(threads),
smem, 0, cur_in, cur_out, cur_n);
} else {
smem = threads * sizeof(float);
hipLaunchKernelGGL(reduce_branchy, dim3(blocks), dim3(threads),
smem, 0, cur_in, cur_out, cur_n);
}
return blocks;
};
// warmup
{
int cur_n = n;
const float* cur_in = d_in;
float* cur_out = d_buf1;
while (cur_n > 1) {
int next_n = launch_once(cur_n, cur_in, cur_out);
cur_n = next_n;
cur_in = cur_out;
cur_out = (cur_out == d_buf1) ? d_buf2 : d_buf1;
}
HIP_CHECK(hipDeviceSynchronize());
}
HIP_CHECK(hipEventRecord(start));
for (int it = 0; it < iterations; ++it) {
int cur_n = n;
const float* cur_in = d_in;
float* cur_out = d_buf1;
while (cur_n > 1) {
int next_n = launch_once(cur_n, cur_in, cur_out);
cur_n = next_n;
cur_in = cur_out;
cur_out = (cur_out == d_buf1) ? d_buf2 : d_buf1;
}
}
HIP_CHECK(hipEventRecord(stop));
HIP_CHECK(hipEventSynchronize(stop));
float ms = 0.0f;
HIP_CHECK(hipEventElapsedTime(&ms, start, stop));
HIP_CHECK(hipFree(d_buf1));
HIP_CHECK(hipFree(d_buf2));
HIP_CHECK(hipEventDestroy(start));
HIP_CHECK(hipEventDestroy(stop));
return ms;
}
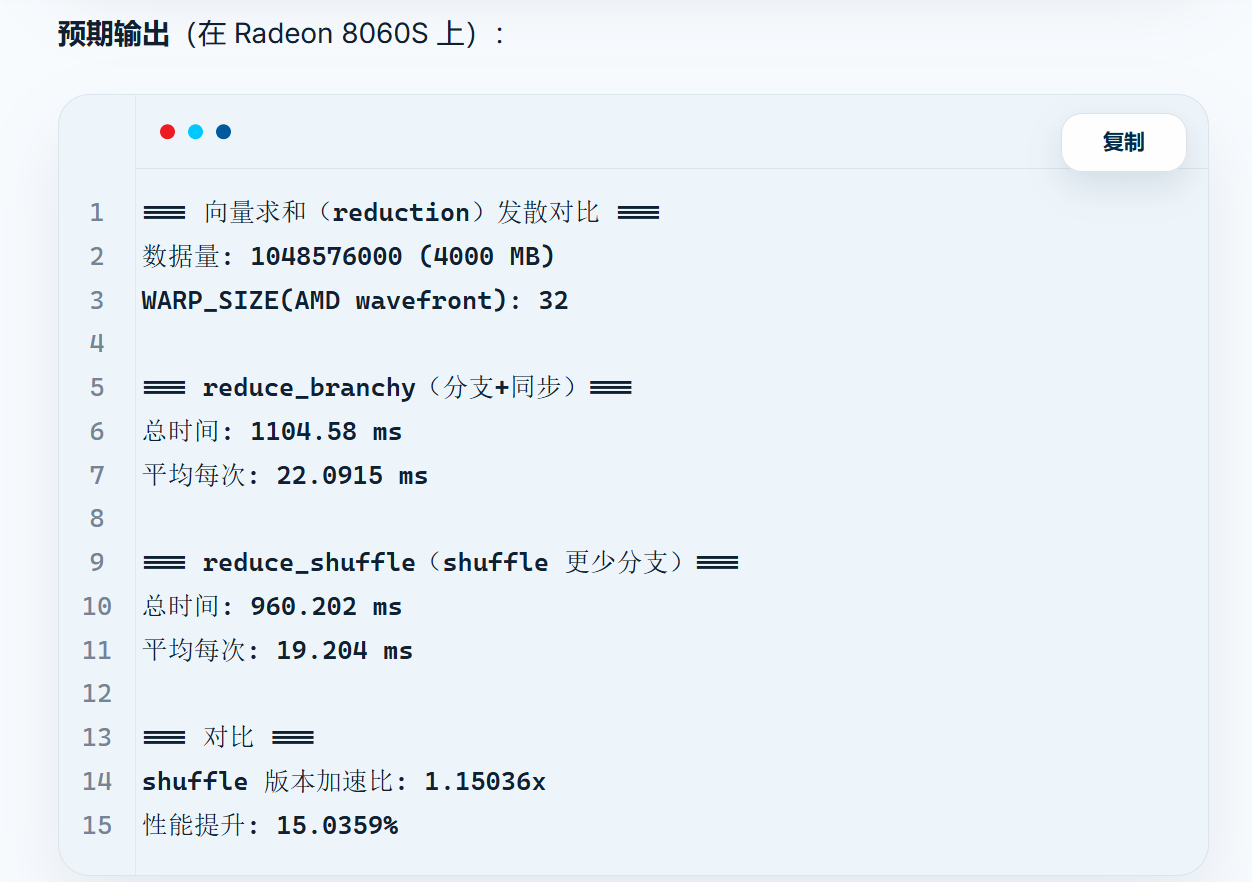
性能分析

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 9
9 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)