
免费 GPU 算力动手系列之 LTX-Video 开源视频生成模型
1 获得算力时间
1.1 ROCm v.s. CUDA
英伟达在 AI 算力卡市场占据四分之三的市场份额,凭着 20 年的积累,CUDA 生态已经形成了一道很深的护城河。AMD 在最近十年也开始在这个市场布局,虽然市场份额比较少,但是主打一个性价比高。AMD 的 ROCm 目前已经基本上适配了 CUDA 的 API,在使用上也不需要再花费精力研究一套新的架构,只需将其当成 CUDA 用就可以了。可以这么说,同一套代码,只需做很少的修改,甚至不用修改就可以在基于 A 卡的 ROCm 环境上跑起来,适配和迁移的成本很低。
1.2 注册得免费算力
AMD 为了推广它的 GPU 算力卡,在中国地区推出了注册开发者用户就送 200 小时算力的活动。之前很多网友都成功注册了账号并兑换到了算力点,实际上,通过点击学习课程,还可以获得更多的积点,比如我就弄到了 300 积点,共换了 300 小时的算力。关于注册用户和兑换算力,如果你还没有试试,赶紧点这个链接薅羊毛:
拿到算力之后可以搞点什么事情呢?这次 AMD 提供的云 GPU 算力还是很强的,GPU 是 Radeon Pro W7900D(gfx1100),显存容量是 48G。就这个显存大小来说,不少百亿级别参数的开源模型都是可以拿来玩一下。这一次我们就用注册账号赠送的算力,结合开源的 LTX-Video 大模型,做了一次本地部署“文生视频”和“图像生成视频”的推理试验。
2 准备环境
2.1 创建和启动切片
拿到云 GPU 的算力时间后,首先要创建自己的 Template,可以理解这一步就是创建一个带 AMD GPU 的 Docker 切片。首先登录 Radeon Cloud(radeon.anruicloud.com),然后点右上角的用户图标,选择 Profile,进入开发人员的个人主页。在这个页面可以看到当前创建的切片模板和剩余的算力时间。在 My Templates 一栏点击“Add Template” 按钮创建切片,在弹出的窗口中除了 Title 和 Container Image 两项需要填写或选择,其他的都可以空着。Container Image 是容器映像,如下图所示,目前有三个可选的容器,我们选择第一个,这是最基础的容器,已经安装了大部分的组件,适合做一些基础的探索工作。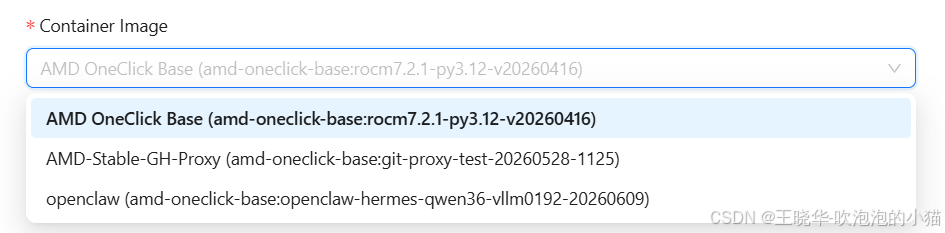
创建 Template 后,就可以在“My Templates” 看到这个切片:
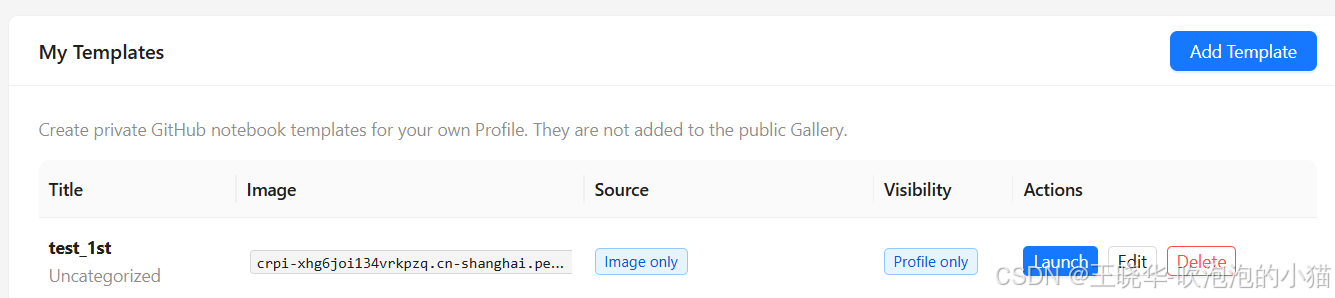
点击切片对应的 “Launch” 按钮启动切片,此时在页面右侧的“Active Instance”栏可以看到它的状态,比如运行时间和实际消耗的算力点数。点击“Open Notebook” 按钮就会启动一个新的“JupyterLab”页面,这就是我们能控制的切片的操作界面。
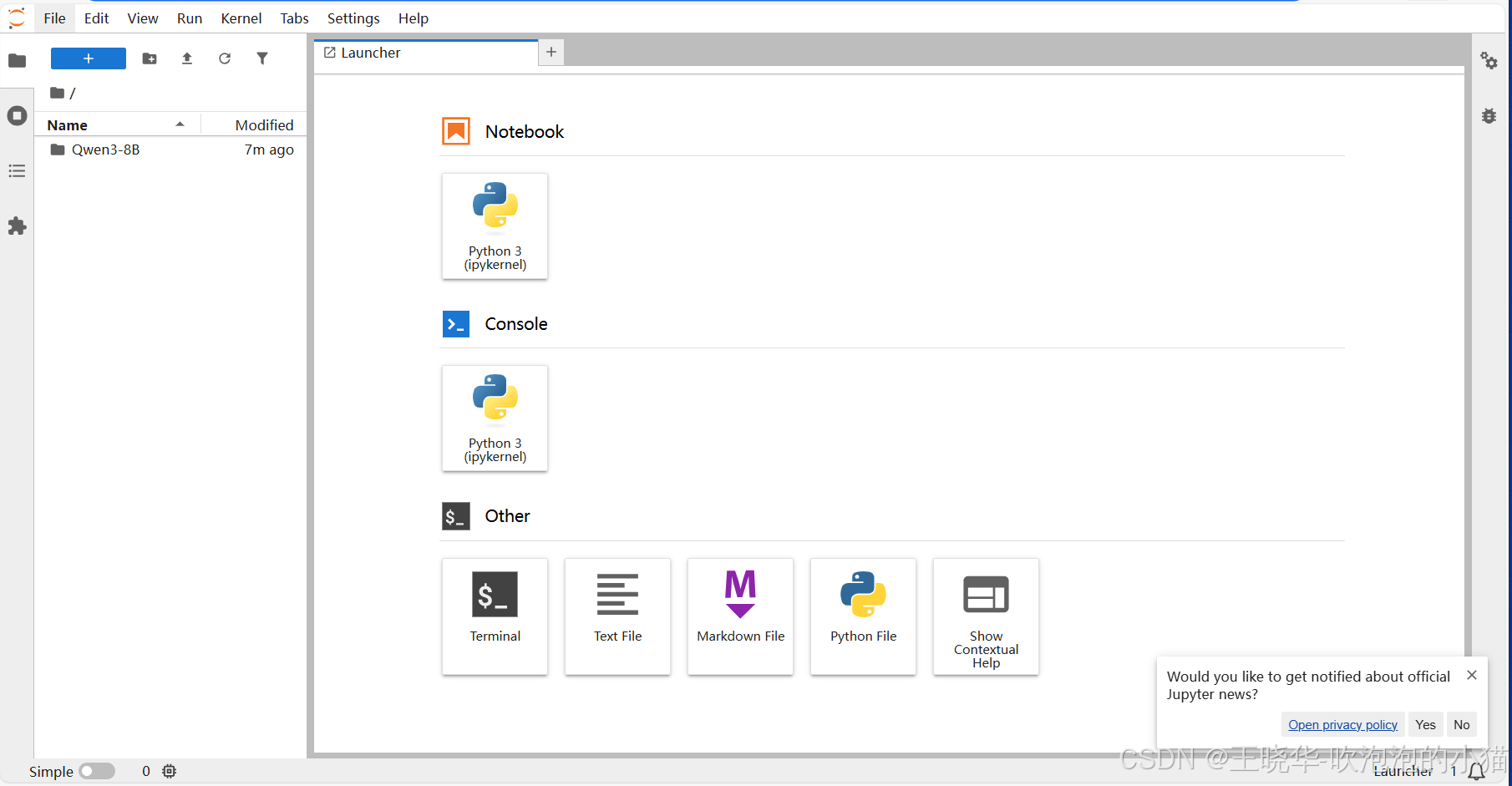
左侧是工作区文件,对应的是切片的 “/workspace” 目录,在这里可以新建目录、文件,还可以上传和下载文件。右侧可以选择工作区操作方式,可以打开一个 Jupyter 交互式笔记,也可以打开一个 python 终端,我选择更直接的方式,就是终端(Terminal)操作。在 Other 一栏点击 Terminal 启动一个 CLI 终端,用 uname 命令查了一下,系统是 Ubuntu:

2.2 准备环境
启动切片后就可以开始试验了。首先用 rocminfo 查看环境信息,可知系统中有一个 GPU,两个 CPU,GPU 的显示型号是 Radeon Pro W7900D 系列,其中架构代号是 gfx1100。
基于 ROCm 的大模型部署,从 PyTorch 代码的角度看,用起来的感觉是一样的。PyTorch 在检测到 ROCm 环境时自动链接 libtorch_hip.so 而非 libtorch_cuda.so,从而实现后端切换,但是前端 API 在命名上仍保留为 torch.cuda.*。这就是我们前面提到代码级的适配工作量很小的原因,同样的代码,在 ROCm 环境上调用的是 HIP 的封装层。
ROCm 生态对硬件架构非常敏感,即便都是 AMD 的 GPU,对应的 gfx 代号不一致,也会导致问题。为了解决 PyTorch 编译时指定的 GPU 架构代码与实际硬件不符的问题,需要通过 PYTORCH_ROCM_ARCH 环境变量明确指定当前硬件的架构。前面已经通过 rocminfo 命令查了当前的架构是 gfx1100,所以需要在终端上导出正确的环境变量。另外,HSA(Heterogeneous System Architecture)中 GPU 的版本号也要同步覆盖为 11.0.0:
export PYTORCH_ROCM_ARCH=gfx1100
export HSA_OVERRIDE_GFX_VERSION=11.0.0
这两个环境变量是在 ROCm 环境上跑通 PyTorch 的基石。
当然,还有一些与 ROCm 有关的环境变量也很重要,比如 HIP_VISIBLE_DEVICES,它类似于 N 卡环境上的 CUDA_VISIBLE_DEVICES。因为测试切片上的 GPU 只有一个,所以 HIP_VISIBLE_DEVICES=0 这一项不设置也可以,默认就是用第一个 GPU 设备。HIP_DEVICE=0 这个也是一样,默认值就可以了。
2.3 软件安装
首先使用 rocm-smi 命令查看 ROCm 环境的版本号:
rocm-smi --version
显示版本号是 7.8,然后就是安装然后安装 pytorch。与 CUDA 生态不同之处在于,使用 AMD 的 GPU 是安装基于 ROCm wheel 的 pytorch:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm7.8
结果是系统已经安装了相应的 pytorch,不需要重复安装, 你用的容器如果不一样,可以启动 python 验证一下:
>>> import torch
>>> print(torch.cuda.is_available())
True
>>> print(torch.cuda.get_device_name(0))
AMD Radeon Graphics
ROCm 将自己适配成 cuda 的 API,所以后续使用 GPU 的场合,直接指定 cuda 就可以了。如果上述命令正常,就可以继续安装 diffusers 模型支持组件(云切片中安装了 vllm 和 LLM 的支持组件,没有 diffusers 模型的组件):
pip install diffusers transformers accelerate safetensors sentencepiece
这些是不依赖 GPU 类型的,直接安装就可以了,另外,还要安装带 ffmpeg 支持的 imageio库:
pip install imageio imageio-ffmpeg
这个主要是用 imageio 输出视频文件的时候需要,我一开始用的是 imageio,不过后来改用 export_to_video,如果用 export_to_video 就不用安装 imageio-ffmpeg 了,因为 export_to_video 是 diffusers 的组件,上一步已经安装了。
3 部署 LTX-Video 大模型
3.1 模型下载
可以选择手工下载模型权重文件,也可以使用 LTXPipeline 组件在第一次使用模型时自动下载。如果你选择后者,可以跳过这一节的内容。手工下载可以选择从 huggingface 下载,也可以选择从 Modelscope 下载,从 huggingface 下载要先安装 huggingface_hub,然后使用以下命令下载整个 LTX-Video 库:
hf download Lightricks/LTX-Video --local-dir /workspace/models/ltx
从 Modelscope 下载需要安装 modelscope,然后用以下命令下载整个 LTX-Video 库:
modelscope download --model Lightricks/LTX-Video --local_dir /workspace/models/ltx
默认是下载完整的模型库,如果只想试试它的 13B 模型,没必要全部下载,可使用 exclude 参数排除掉一些不需要的权重文件。
3.2 部署与验证
模型权重文件下载后就可以开始测试,首先试试文生视频,在 JupyterLab 中选择 “New python file”,输入文件名 t2v.py,然后打开这个文件,输入代码:
mport torch
from diffusers import LTXPipeline
from diffusers.utils import export_to_video
pipe = LTXPipeline.from_pretrained("/workspace/models/ltx", torch_dtype=torch.bfloat16,)
pipe.to("cuda")
prompt = ("A spotted dog is running happily on the golden beach, with the sea and coconut trees in the distance, and a few crabs nearby")
# ~5 sec at 24 fps
output = pipe(
prompt=prompt,
negative_prompt="blurry, low quality, distorted",
num_frames=121,
width=768,
height=512,
num_inference_steps=30,
guidance_scale=7.5,
generator=torch.Generator("cuda").manual_seed(0),
)
frames = output.frames[0]
export_to_video(frames, "/workspace/output.mp4", fps=24)
在打开的终端中运行 python t2v.py,稍等一会儿就会在 workspace 目录生成 output.mp4。
如果想自动下载模型文件,只需要在调用 from_pretrained() 函数的时候将第一个参数换成 “Lightricks/LTX-Video” 就可以了。其他需要注意的是 num_frames 参数,按照官方文档的说法,这个参数的数值最好是以秒为单位的整数帧数+1,比如我们计划生成长度是 5 秒,每秒 24 帧的视频,则帧数就是 5 x 24 +1=121 帧。guidance_scale 参数也很重要,在 LTX-Video 开源大模型的讨论区,可以看到大家对这个模型的评价是参数很敏感,需要多次尝试确定最好的结果。我最初使用 guidance_scale=1.0,结果得到的视频惨不忍睹,截个图给大家看看:

这只狗有点潦草,要不是我真的见过斑点狗,我差点就信了。
其实,LTX-Video 开源模型最强的是根据图片生成视频,接下来就是试试它的图生视频功能。再创建一个 i2v.py 文件,输入以下根据图片生成视频的代码:
import torch
from PIL import Image
from diffusers import LTXImageToVideoPipeline
from diffusers.utils import export_to_video
pipe = LTXImageToVideoPipeline.from_pretrained(
"/workspace/models/ltx",
torch_dtype=torch.bfloat16,
)
pipe.to("cuda")
image = Image.open("/workspace/lake_s.jpg").resize((768, 512))
output = pipe(
prompt="镜头慢慢向右移动,水面上波纹荡漾",
negative_prompt="静态, 模糊",
image=image,
num_frames=121,
num_inference_steps=30,
guidance_scale=7.5,
)
frames = output.frames[0]
export_to_video(video_frames, "/workspace/output_2.mp4", fps=24)
在左侧工作区点击上传文件的图标,上传图片文件 lake_s.jpg 到 /workspace 目录,然后运行 i2v.py,这次等的时间要长一点,最终可生成视频文件 output_2.mp4。我上传的是一张岸边湖景,得到的结果确实比文生视频好,5 秒钟的视频画面没有瑕疵和穿帮,镜头移动平稳。
目前看,部署一个 diffusers 生图或生成视频的模型,然后在切片上做本地推理的流程是没有问题的,下一篇,我们就在这个基础上看看能不能玩点别的花样。
参考资料
User Guide for AMDGPU Backend — LLVM 23.0.0git documentation

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)