
VLLM历次会议(2024.6)
·
VLLM功能矩阵
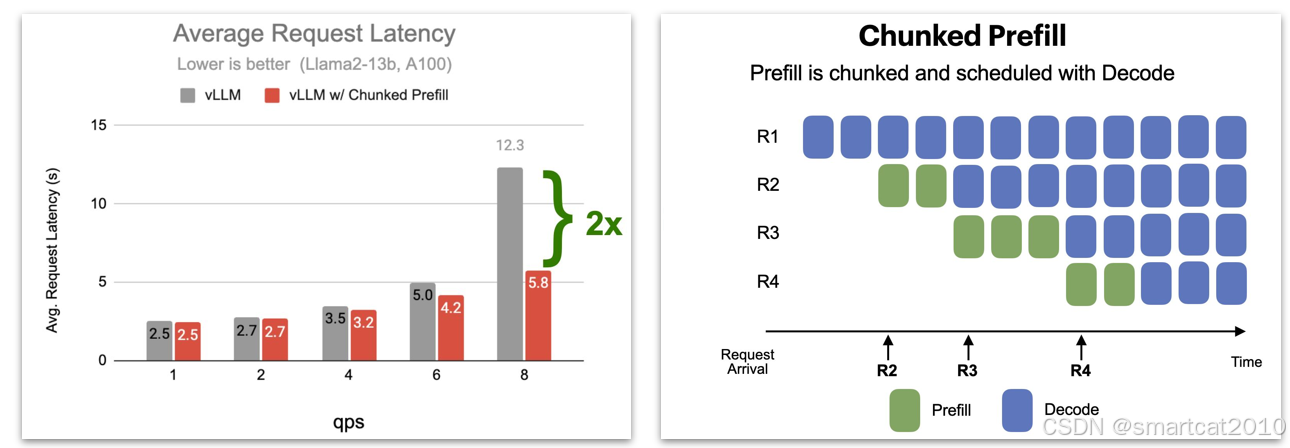
chunked prefill
qps上来以后,延迟能有明显的优化。
原理就是新到request的prefill,不阻塞正在decode的request。
FP8量化的支持

动态量化,即激活是在推理阶段进行量化,不需要提前calibration:

FlashInfer
NCCL和custom allreduce(应该就是指one-shot和two-shot以及half-bufferfly那些,小数据量通信情况下,降低延迟用的)
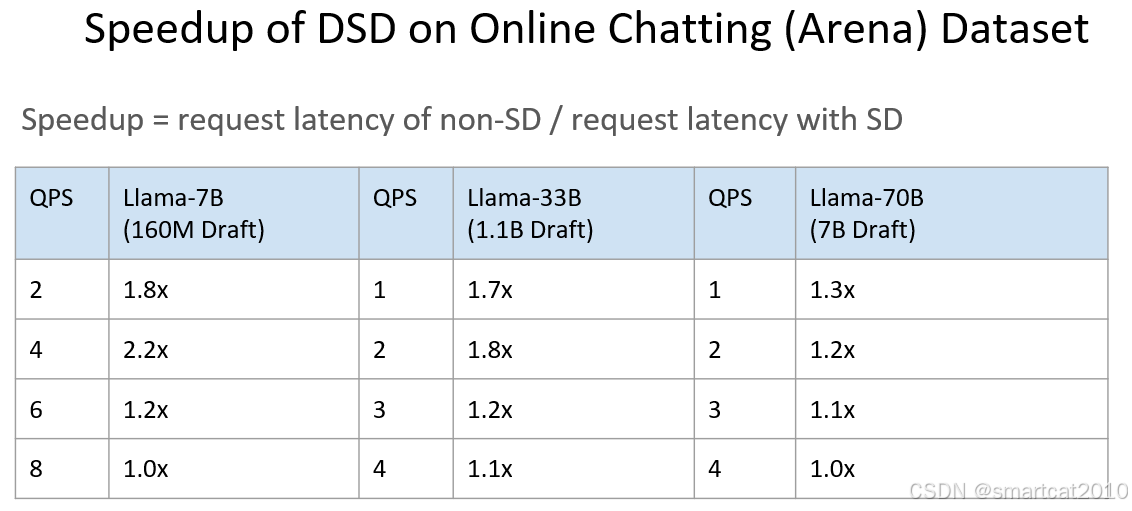
Speculative Decoding
和continous batching一起使用时,为什么加速比和qps有关?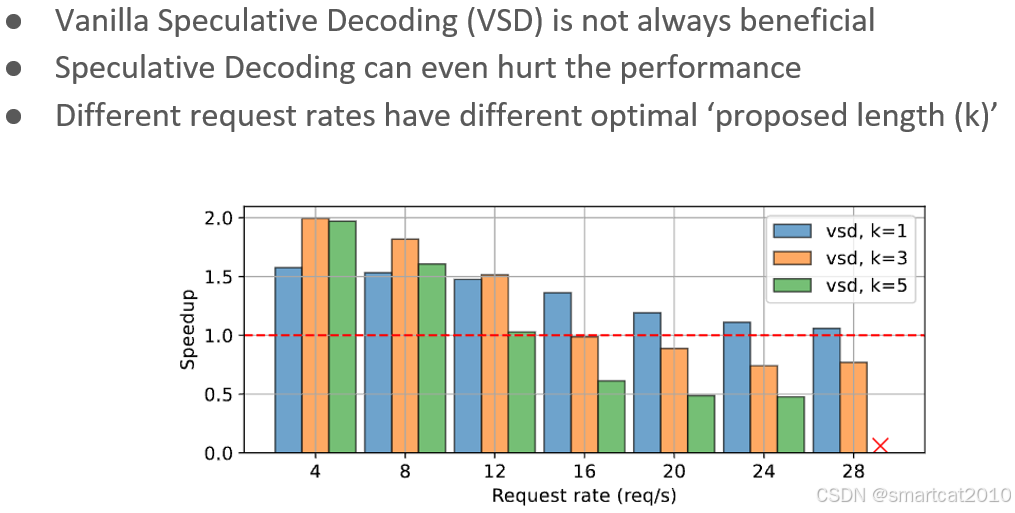
不同种类:


免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐

 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)