
Ollama 安装与使用
·
Ollama 安装与使用
1. Ollama介绍
Ollama 是一个开源框架,专为在本地机器上便捷部署和运行大型语言模型(LLM)而设计。
以下是其主要特点和功能概述:
- 简化部署:Ollama 目标在于简化在 Docker 容器中部署大型语言模型的过程,使得非专业用户也能方便地管理和运行这些复杂的模型。
- 轻量级与可扩展:作为轻量级框架,Ollama 保持了较小的资源占用,同时具备良好的可扩展性,允许用户根据需要调整配置以适应不同规模的项目和硬件条件。
- API支持:提供了一个简洁的 API,使得开发者能够轻松创建、运行和管理大型语言模型实例,降低了与模型交互的技术门槛。
- 预构建模型库:包含一系列预先训练好的大型语言模型,用户可以直接选用这些模型应用于自己的应用程序,无需从头训练或自行寻找模型源。
- 模型导入与定制:从 GGUF 导入:支持从特定平台(如GGUF,假设这是一个模型托管平台)导入已有的大型语言模型。从 PyTorch 或 Safetensors 导入:兼容这两种深度学习框架,允许用户将基于这些框架训练的模型集成到 Ollama 中。自定义提示:允许用户为模型添加或修改提示(prompt engineering),以引导模型生成特定类型或风格的文本输出。
- 跨平台支持:提供针对 macOS、Windows(预览版)、Linux 以及 Docker 的安装指南,确保用户能在多种操作系统环境下顺利部署和使用 Ollama。
- 命令行工具与环境变量:命令行启动:通过命令 ollamaserve 或其别名 serve、start 可以启动 Ollama 服务。环境变量配置:如 OLLAMA_HOST,用于指定服务绑定的主机地址和端口,默认值为 127.0.0.1:11434,用户可以根据需要进行修改。
综上我们可以知道,Ollama 是一个专注于本地部署大型语言模型的工具,通过提供便捷的模型管理、丰富的预建模型库、跨平台支持以及灵活的自定义选项,使得开发者和研究人员能够在本地环境中高效利用大型语言模型进行各种自然语言处理任务,而无需依赖云服务或复杂的基础设施设置。
2. Ollama安装
2.1 Ollama安装
docker run --name ollama -p 11434:11434 -d -v /home/kent/Tools/ollama:/root/.ollama ollama/ollama
2.2 Ollama验证
浏览器打开 http://ip:11434
如果出现下面信息,证明安装运行成功
Ollama is running
2.3 Ollama基本命令
- 创建模型
ollama create modelxx
- 显示模型信息
ollama show
- 列出模型
ollama list
- 从注册表拉取模型
ollama pull deepseek:r1-8b
- 推送模型到注册表
ollama push deepseek:r1-8b
- 复制模型
ollama cp deepseek:r1-8b deepseek
- 删除模型
ollama rm deepseek:r1-8b
- 运行模型
ollama run deepseek:r1-8b
ollama run dengcao/Qwen3-Embedding-4B:Q8_0
3. 安装Open WebUI,实现图形界面交互
3.1 无GPU版
docker run -d -p 3000:8080 -v /opt/ollama/open-webui:/app/backend/data -e HF_ENDPOINT=https://hf-mirror.com -e OLLAMA_BASE_URL=http://ip:11434 -e DEFAULT_MODELS=llama3.2:1b --name open-webui --restart always ghcr.io/open-webui/open-webui:main
OLLAMA_BASE_URL 最好使用实际的ip地址,以防openwebui的docker识别不了ollama后端服务
3.1 界面操作
打开链接:http://ip:3000/ 即可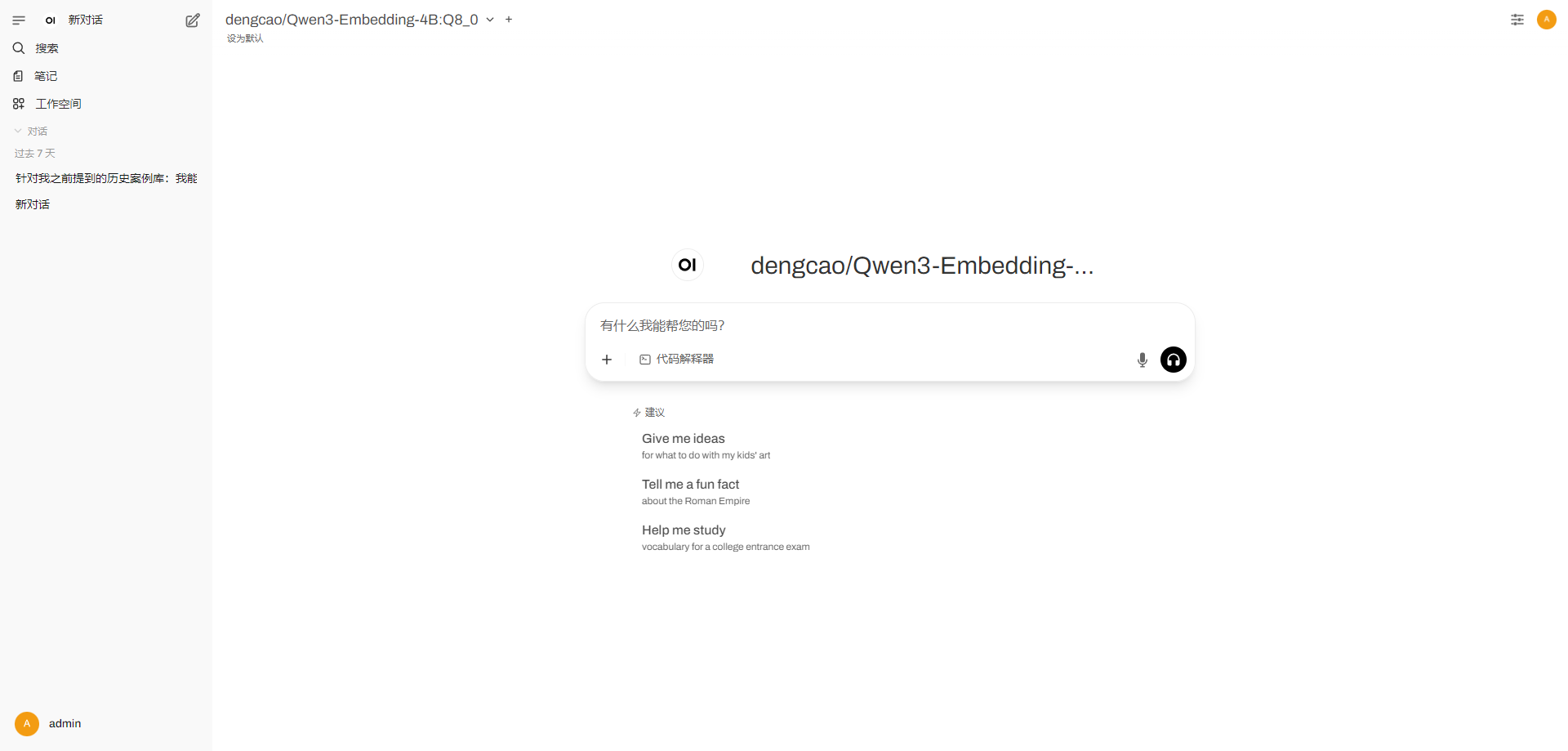

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐

 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)