
【大模型微调】LLaMA-Factory简介和基本使用流程
引言
本文开始,进入到大模型微调领域。
之前一直在做 RAG 的相关内容,RAG 能够直接通过预先解析好的知识库,增强模型回答的输出质量。
然而,当知识库较大时,RAG 会显著增加检索搜索的时间,导致回答反应迟钝;并且,RAG的方案并不适合在线大模型的调用,因为它会将相关内容一起作为模型的输入内容,会造成token成本上升。
模型微调则没有 RAG 的相关缺点,通过训练微调,可以直接将知识内容“注入”到模型的参数本身中,问答时无需再经历检索。
但是,模型微调不像 RAG 那样比较直观,需要微调数据集整理、高配置训练环境和丰富的炼丹技巧三个必要条件。
其实,模型微调和 RAG 本质上是不冲突的。对于多数不变的知识(如规章制度、历史材料等)完全可以通过微调直接喂给大模型;而对于变化的知识(如新闻等)来不及再去整理微调,则可以通过 RAG 的方式对模型知识进行有效补充,同时可以减少 RAG 知识库的容量,让检索压力更小。
作为系列开篇,本文先在 windows 操作系统上,跑通LLaMA-Factory的模型微调过程,为后续探索奠定基础。
LLaMA-Factory 简介
经调研,用于大模型微调的框架根据github上的关注度,主要有以下产品:LLaMA-Factory(52.4k)、unsloth(40.6k)、DeepSpeed(38.9k)、peft(18.8k)和axolotl(9.6k)。
其中,LLaMA-Factory不仅热度最高,而且还是国人维护,自然成为首选。

LLaMA-Factory支持直接通过命令行或 Web UI去微调模型,无需编写代码,其支持各种模型LLaMA、DeepSeek、Qwen等多种模型微调,集成了各种训练主流方法。
仓库地址:https://github.com/hiyouga/LLaMA-Factory
项目文档:https://llamafactory.readthedocs.io/zh-cn/latest/
安装
下面开始安装,下载项目
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
使用uv安装环境依赖
uv sync --extra torch --extra metrics --prerelease=allow
检测pytorch是否可用
python -c "import torch; print(torch.cuda.is_available())"
windows用户会输出False,需要卸载重新安装gpu版本。
uv pip uninstall torch torchvision
uv pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
再次检测,此时输出True,则表明安装成功。
LLaMA-Factory 版本校验:
llamafactory-cli version
输出以下内容,表明安装成功。
数据集准备
官方文档中介绍了指令监督微调、预训练、多模态等多种类型的数据集。
本文只关注第一种指令监督微调数据集,LLaMA Factory中支持Alpaca和ShareGPT。
1. Alpaca 数据集格式
Alpaca 格式的数据集结构示例如下:
{
"instruction": "计算这些物品的总费用。 ",
"input": "输入:汽车 - $3000,衣服 - $100,书 - $20。",
"output": "汽车、衣服和书的总费用为 $3000 + $100 + $20 = $3120。"
},
其中instruction对应人类指令,input对应人类输入,output对应模型回答。
在微调过程中,instruction和input会拼接起来输入到模型中。
Alpaca 格式可以进一步支持系统提示词system和对话历史history,完整的结构如下:
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]
2. ShareGPT 数据集格式
相比 alpaca 格式的数据集, sharegpt 格式支持 更多的角色种类,例如 human、gpt、observation、function 等等。它们构成一个对象列表呈现在 conversations 列中,示例如下:
{
"conversations": [
{
"from": "human",
"value": "你好,我出生于1990年5月15日。你能告诉我我今天几岁了吗?"
},
{
"from": "function_call",
"value": "{\"name\": \"calculate_age\", \"arguments\": {\"birthdate\": \"1990-05-15\"}}"
},
{
"from": "observation",
"value": "{\"age\": 31}"
},
{
"from": "gpt",
"value": "根据我的计算,你今天31岁了。"
}
],
"tools": "[{\"name\": \"calculate_age\", \"description\": \"根据出生日期计算年龄\", \"parameters\": {\"type\": \"object\", \"properties\": {\"birthdate\": {\"type\": \"string\", \"description\": \"出生日期以YYYY-MM-DD格式表示\"}}, \"required\": [\"birthdate\"]}}]"
}
该结构中,human 和 observation 必须出现在奇数位置,gpt 和 function 必须出现在偶数位置,完整结构格式如下:
[
{
"conversations": [
{
"from": "human",
"value": "人类指令"
},
{
"from": "function_call",
"value": "工具参数"
},
{
"from": "observation",
"value": "工具结果"
},
{
"from": "gpt",
"value": "模型回答"
}
],
"system": "系统提示词(选填)",
"tools": "工具描述(选填)"
}
]
具体使用方式
1. 启动应用
通过以下命令,启动webui界面:
llamafactory-cli webui
浏览器访问http://localhost:7860,进入到主界面。
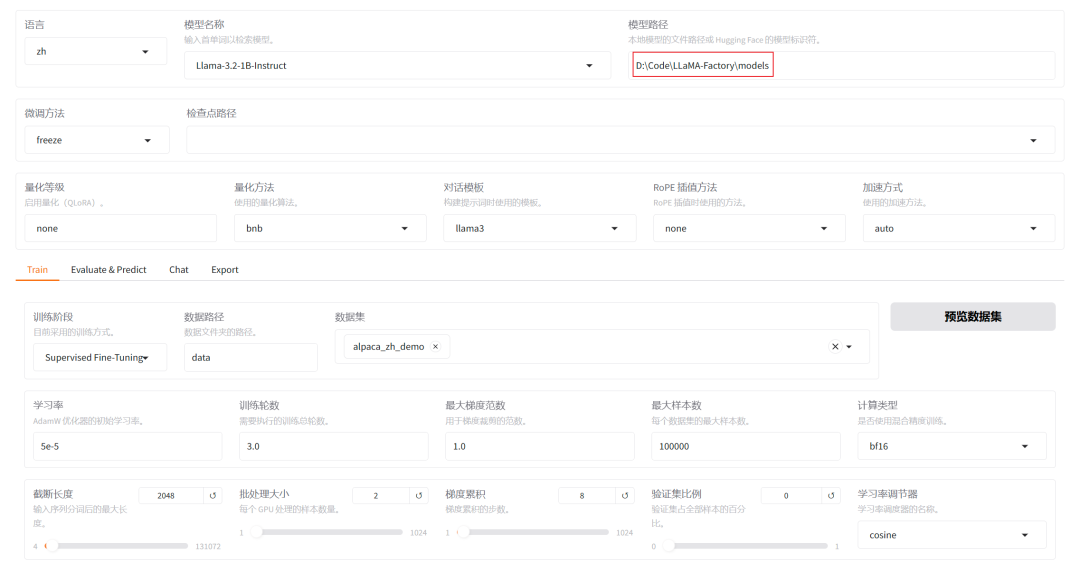
2. 下载模型
在主界面中,选择模型后,默认会从huggingface上去下载模型,在国内网络情况下,建议先从 modelscope 中下载好模型。
以下载Llama-3.2-1B-Instruct为例,先安装modelscope依赖:
uv pip install modelscope
下载模型,到本地目录models文件夹:
modelscope download --model LLM-Research/Llama-3.2-1B-Instruct --local_dir ./models
下载完后,就可以通过指定模型的绝对路径,去进行模型加载。
3. 数据集准备
在项目的data文件夹中,自带了不少数据集示例。
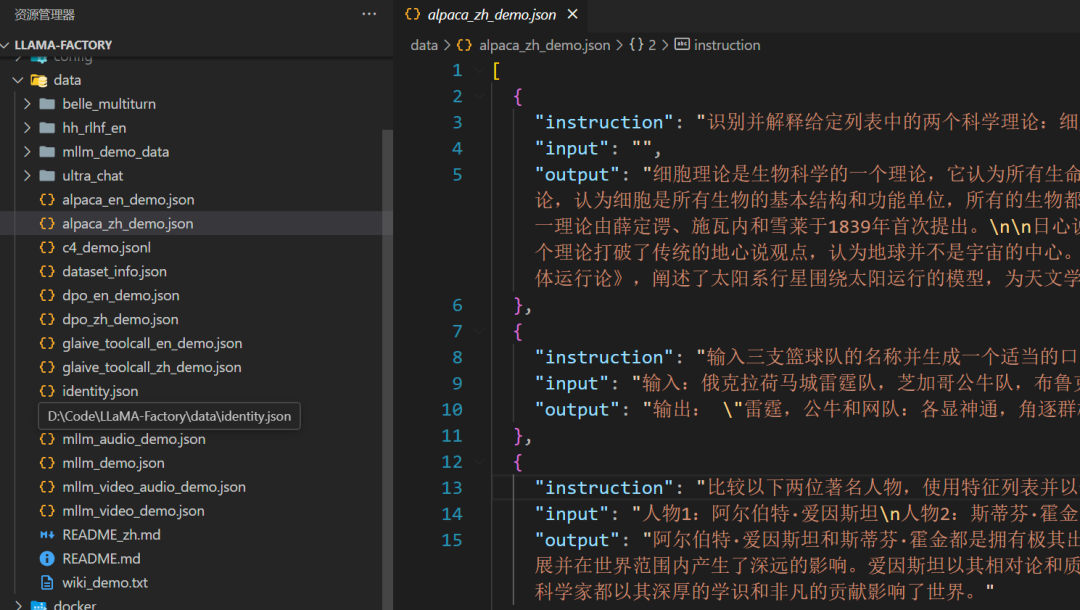
前端界面中,可选择加载自带的数据集示例,并进行显示查看。

4. 开始训练
选择完数据集后,就可以点击“开始”按钮,直接开始训练。
实测发现,Llama-3.2-1B模型全量训练,会报显存,因此,调整为Freeze模式,即冻结部分参数,默认只训练最后两层,具体可通过可训练层数进行控制。
训练时,下方会展示训练日志和进度。
损失曲线会实时更新,默认是训练三个epoch,损失不断降低,说明训练有效果。
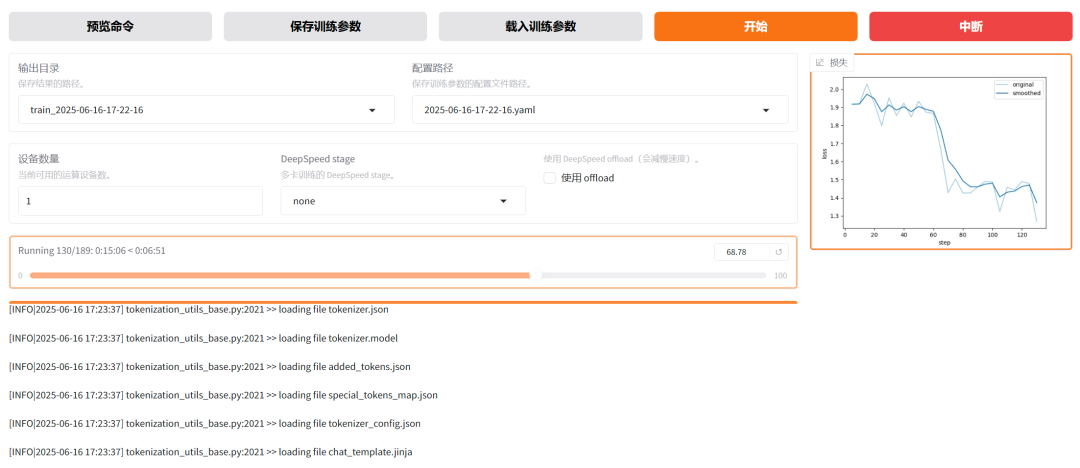
默认每100步会保存一个checkpoint,最终的结果会在saves文件夹中自动生成。
5. 模型测试
训练完之后,可以进行模型评估,不过在训练时,验证集比例默认为0,未划分验证集,评估就不会太有意义。
此外,可通过chat模块加载模型,进行问答测试。
下面测试了一下微调前后的模型回答效果(该问题在上面的数据集截图中有被训练):
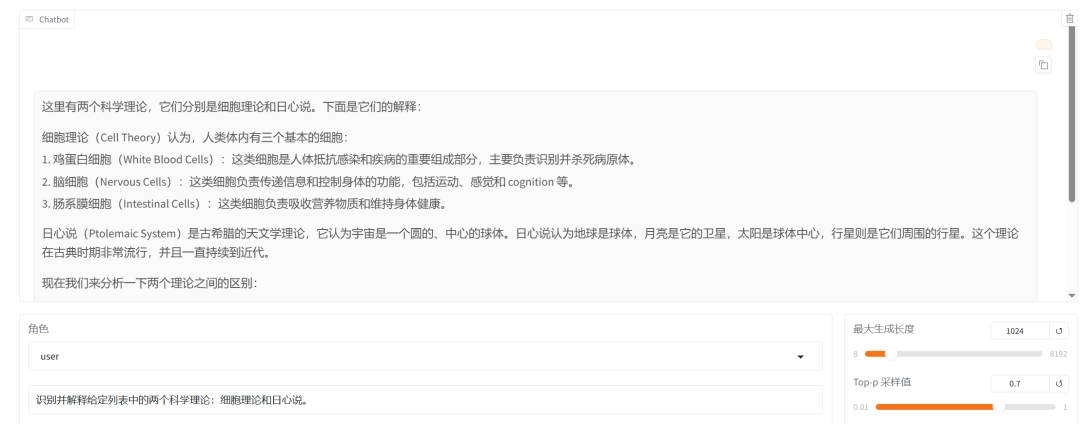
微调前

微调后
结果发现,微调后有一点优化后的感觉,但效果不是特别明显,可能和模型参数和训练轮次太少都有关系。之后将在服务器上训练更大的模型,并增加训练轮次,再测试效果。
总结
在初次体验模型微调的流程后,发现模型微调这一块的基础工具已经做的相当成熟,已经无需再编写代码去进行微调。
但是,LLaMA-Factory可选参数非常多,不同参数的选取对结果肯定会有很大影响,如何调参变成了代码之上更高一层的学问。初次踏入这个领域,让我想到了牛顿“沙滩上的孩童”比喻,里面有太多值得继续深挖探索的研究点,像是小孩看见玩具那样令人兴奋。
如何学习AI大模型 ?
“最先掌握AI的人,将会晚掌握AI的人有竞争优势,晚掌握AI的人比完全不会AI的人竞争优势更大”。 在这个技术日新月异的时代,不会新技能或者说落后就要挨打。
老蓝我作为一名在一线互联网企业(保密不方便透露)工作十余年,指导过不少同行后辈。帮助很多人得到了学习和成长。
我是非常希望可以把知识和技术分享给大家,但苦于传播途径有限,很多互联网行业的朋友无法获得正确的籽料得到学习的提升,所以也是整理了一份AI大模型籽料包括:AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、落地项目实战等 免费分享出来。
AI大模型学习路线图
100套AI大模型商业化落地方案
100集大模型视频教程
200本大模型PDF书籍
LLM面试题合集
AI产品经理资源合集

大模型学习路线
想要学习一门新技术,你最先应该开始看的就是学习路线图,而下方这张超详细的学习路线图,按照这个路线进行学习,学完成为一名大模型算法工程师,拿个20k、15薪那是轻轻松松!

视频教程
首先是建议零基础的小伙伴通过视频教程来学习,其中这里给大家分享一份与上面成长路线&学习计划相对应的视频教程。文末有整合包的领取方式

技术书籍籽料
当然,当你入门之后,仅仅是视频教程已经不能满足你的需求了,这里也分享一份我学习期间整理的大模型入门书籍籽料。文末有整合包的领取方式

大模型实际应用报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。文末有整合包的领取方式

大模型落地应用案例PPT
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。文末有整合包的领取方式

大模型面试题&答案
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。文末有整合包的领取方式

领取方式
这份完整版的 AI大模型学习籽料我已经上传CSDN,需要的同学可以微⭐扫描下方CSDN官方认证二维码免费领取!
。

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)