
大模型系列:LLaMA-Factory大模型微调

引言
开源大模型如LLaMA,Qwen,Baichuan等主要都是使用通用数据进行训练而来,其对于不同下游的使用场景和垂直领域的效果有待进一步提升,衍生出了微调训练相关的需求,包含预训练(pt),指令微调(sft),基于人工反馈的对齐(rlhf)等,以提高其在特定领域的性能。
但大模型训练对于显存和算力的要求较高,同时也需要下游开发者对大模型本身的技术有一定了解,具有一定的门槛。
LLaMA-Factory 作为一个高效、易用的微调工具,为广大开发者提供了极大的便利。适配市场主流开源模型,形成一个功能丰富,适配性好的训练框架。项目提供了多个高层次抽象的调用接口,包含多阶段训练,推理测试,benchmark评测,API Server等,使开发者开箱即用。
本次将详细介绍如何使用LLaMA-Factory从零开始微调大模型,帮助大家快速掌握这一技能。
什么是模型微调?
在深度学习领域,模型微调通常指的是在预训练模型的基础上进行的进一步训练。
预训练模型(基座模型)是在大量数据上训练得到的,它已经学习到了语言的基本规律和丰富的特征表示。然而,这些模型可能并不直接适用于特定的任务或领域,因为它们可能缺乏对特定领域知识的理解和适应性。
模型微调通过在特定任务的数据集上继续对预训练模型(基座模型)进行训练,使得模型能够学习到与任务相关的特定特征和知识。这个过程通常涉及到模型权重的微幅调整,而不是从头开始训练一个全新的模型。
微调的过程
微调过程主要包括以下几个步骤:
-
数据准备:收集和准备特定任务的数据集。
-
模型选择:选择一个预训练模型作为基座模型。
-
迁移学习:在新数据集上继续训练模型,同时保留预训练模型的知识。
-
参数调整:根据需要调整模型的参数,如学习率、批大小等。
-
模型评估:在验证集上评估模型的性能,并根据反馈进行调整;
微调的优势
微调技术带来了多方面的优势:
资源效率:相比于从头开始训练模型,微调可以显著减少所需的数据量和计算资源。
快速部署:微调可以快速适应新任务,加速模型的部署过程。
性能提升:针对特定任务的微调可以提高模型的准确性和鲁棒性。
领域适应性:可以使得预训练模型在这些任务上取得更好的性能,更好地满足实际应用的需求。
LLamA-Factory
GitHub项目地址:
LLaMA-Factory/data/dpo_en_demo.json at main · hiyouga/LLaMA-Factory · GitHub
项目特色
-
多种模型:LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、Qwen2-VL、DeepSeek、Yi、Gemma、ChatGLM、Phi 等等。
-
集成方法:(增量)预训练、(多模态)指令监督微调、奖励模型训练、PPO 训练、DPO 训练、KTO 训练、ORPO 训练等等。
-
多种精度:16 比特全参数微调、冻结微调、LoRA 微调和基于 AQLM/AWQ/GPTQ/LLM.int8/HQQ/EETQ 的 2/3/4/5/6/8 比特 QLoRA 微调。
-
先进算法:GaLore、BAdam、APOLLO、Adam-mini、Muon、DoRA、LongLoRA、LLaMA Pro、Mixture-of-Depths、LoRA+、LoftQ 和 PiSSA。
-
实用技巧:FlashAttention-2、Unsloth、Liger Kernel、RoPE scaling、NEFTune 和 rsLoRA。
-
广泛任务:多轮对话、工具调用、图像理解、视觉定位、视频识别和语音理解等等。
-
实验监控:LlamaBoard、TensorBoard、Wandb、MLflow、SwanLab 等等。
-
极速推理:基于 vLLM 或 SGLang 的 OpenAI 风格 API、浏览器界面和命令行接口。
支持模型
|
模型名 |
参数量 |
Template |
|
Baichuan 2 |
7B/13B |
baichuan2 |
|
BLOOM/BLOOMZ |
560M/1.1B/1.7B/3B/7.1B/176B |
- |
|
ChatGLM3 |
6B |
chatglm3 |
|
Command R |
35B/104B |
cohere |
|
DeepSeek (Code/MoE) |
7B/16B/67B/236B |
deepseek |
|
DeepSeek 2.5/3 |
236B/671B |
deepseek3 |
|
DeepSeek R1 (Distill) |
1.5B/7B/8B/14B/32B/70B/671B |
deepseekr1 |
|
Falcon |
7B/11B/40B/180B |
falcon |
|
Gemma/Gemma 2/CodeGemma |
2B/7B/9B/27B |
gemma |
|
Gemma 3 |
1B/4B/12B/27B |
gemma3/gemma (1B) |
|
GLM-4/GLM-4-0414/GLM-Z1 |
9B/32B |
glm4/glmz1 |
|
GPT-2 |
0.1B/0.4B/0.8B/1.5B |
- |
|
Granite 3.0-3.3 |
1B/2B/3B/8B |
granite3 |
|
Hunyuan |
7B |
hunyuan |
|
Index |
1.9B |
index |
|
InternLM 2-3 |
7B/8B/20B |
intern2 |
|
InternVL 2.5-3* |
1B/2B/8B/14B/38B/78B |
intern_vl |
|
Kimi-VL |
16B |
kimi_vl |
|
Llama |
7B/13B/33B/65B |
- |
|
Llama 2 |
7B/13B/70B |
llama2 |
|
Llama 3-3.3 |
1B/3B/8B/70B |
llama3 |
|
Llama 4 |
109B/402B |
llama4 |
|
Llama 3.2 Vision |
11B/90B |
mllama |
|
LLaVA-1.5 |
7B/13B |
llava |
|
LLaVA-NeXT |
7B/8B/13B/34B/72B/110B |
llava_next |
|
LLaVA-NeXT-Video |
7B/34B |
llava_next_video |
|
MiMo |
7B |
mimo |
|
MiniCPM |
1B/2B/4B |
cpm/cpm3 |
|
MiniCPM-o-2.6/MiniCPM-V-2.6 |
8B |
minicpm_o/minicpm_v |
|
Ministral/Mistral-Nemo |
8B/12B |
ministral |
|
Mistral/Mixtral |
7B/8x7B/8x22B |
mistral |
|
Mistral Small |
24B |
mistral_small |
|
OLMo |
1B/7B |
- |
|
PaliGemma/PaliGemma2 |
3B/10B/28B |
paligemma |
|
Phi-1.5/Phi-2 |
1.3B/2.7B |
- |
|
Phi-3/Phi-3.5 |
4B/14B |
phi |
|
Phi-3-small |
7B |
phi_small |
|
Phi-4 |
14B |
phi4 |
|
Pixtral |
12B |
pixtral |
|
Qwen (1-2.5) (Code/Math/MoE/QwQ) |
0.5B/1.5B/3B/7B/14B/32B/72B/110B |
qwen |
|
Qwen3 (MoE) |
0.6B/1.7B/4B/8B/14B/32B/235B |
qwen3 |
|
Qwen2-Audio |
7B |
qwen2_audio |
|
Qwen2.5-Omni** |
3B/7B |
qwen2_omni |
|
Qwen2-VL/Qwen2.5-VL/QVQ |
2B/3B/7B/32B/72B |
qwen2_vl |
|
Skywork o1 |
8B |
skywork_o1 |
|
StarCoder 2 |
3B/7B/15B |
- |
|
TeleChat2 |
3B/7B/35B/115B |
telechat2 |
|
XVERSE |
7B/13B/65B |
xverse |
|
Yi/Yi-1.5 (Code) |
1.5B/6B/9B/34B |
yi |
|
Yi-VL |
6B/34B |
yi_vl |
|
Yuan 2 |
2B/51B/102B |
yuan |
安装&数据准备
参考下一篇文章:LLaMA Factory 安装 & 数据准备
微调实践
启动web UI
export USE_MODELSCOPE_HUB=1 && llamafactory-cli webui启动一个本地Web服务器,可以通过访问http://0.0.0.0.0.0.09:7860 来使用WebUI。
如果配置了:USE_MODELSCOPE_HUB=1, 默认从modelscope上去下载模型,不写的话就是从hugging face下载;
选择模型
deepseek-ai/DeepSeek-R1-Distill-Qwen-7B · Hugging Face
下载模型方法
-
使用Web UI 默认下载
直接选择模型,不修改模型路径,点击加载模型
ll ~/.cache/huggingface/hubdrwxr-xr-x 6 root root 4.0K May 14 11:58 models--deepseek-ai--DeepSeek-R1-Distill-Qwen-7B-rw-r--r-- 1 root root 1 Feb 14 15:49 version_diffusers_cache.txt-rw-r--r-- 1 root root 1 Feb 14 12:05 version.txt
默认路径 ~/.cache/huggingface/hub
进入chat 验证一下
-
使用 Hugging Face CLI 下载模型到指定路径
huggingface-cli download model_name --cache-dir /path/to/your/directoryhuggingface-cli download --resume-download deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --cache-dir /home/maoyaozong/LLaMA-Factory-Model
deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B · Hugging Face


自定义数据集
(base) root@dev:/home/maoyaozong/LLaMA-Factory/data(main○) # lltotal 7.8M-rw-r--r-- 1 root root 841K May 12 13:09 alpaca_en_demo.json-rw-r--r-- 1 root root 622K May 12 13:09 alpaca_zh_demo.jsondrwxr-xr-x 2 root root 4.0K May 12 13:09 belle_multiturn-rw-r--r-- 1 root root 730K May 12 13:09 c4_demo.jsonl-rw-r--r-- 1 root root 17K May 12 13:09 dataset_info.json-rw-r--r-- 1 root root 1.6M May 12 13:09 dpo_en_demo.json-rw-r--r-- 1 root root 834K May 12 13:09 dpo_zh_demo.json-rw-r--r-- 1 root root 722K May 12 13:09 glaive_toolcall_en_demo.json-rw-r--r-- 1 root root 665K May 12 13:09 glaive_toolcall_zh_demo.jsondrwxr-xr-x 2 root root 4.0K May 12 13:09 hh_rlhf_en-rw-r--r-- 1 root root 20K May 12 13:09 identity.json-rw-r--r-- 1 root root 893K May 12 13:09 kto_en_demo.json-rw-r--r-- 1 root root 877 May 12 13:09 mllm_audio_demo.jsondrwxr-xr-x 2 root root 4.0K May 12 13:09 mllm_demo_data-rw-r--r-- 1 root root 3.3K May 12 13:09 mllm_demo.json-rw-r--r-- 1 root root 1.1K May 12 13:09 mllm_video_audio_demo.json-rw-r--r-- 1 root root 828 May 12 13:09 mllm_video_demo.json-rw-r--r-- 1 root root 13K May 12 13:09 README.md-rw-r--r-- 1 root root 12K May 12 13:09 README_zh.mddrwxr-xr-x 2 root root 4.0K May 12 13:09 ultra_chat-rw-r--r-- 1 root root 1005K May 12 13:09 wiki_demo.txt
-
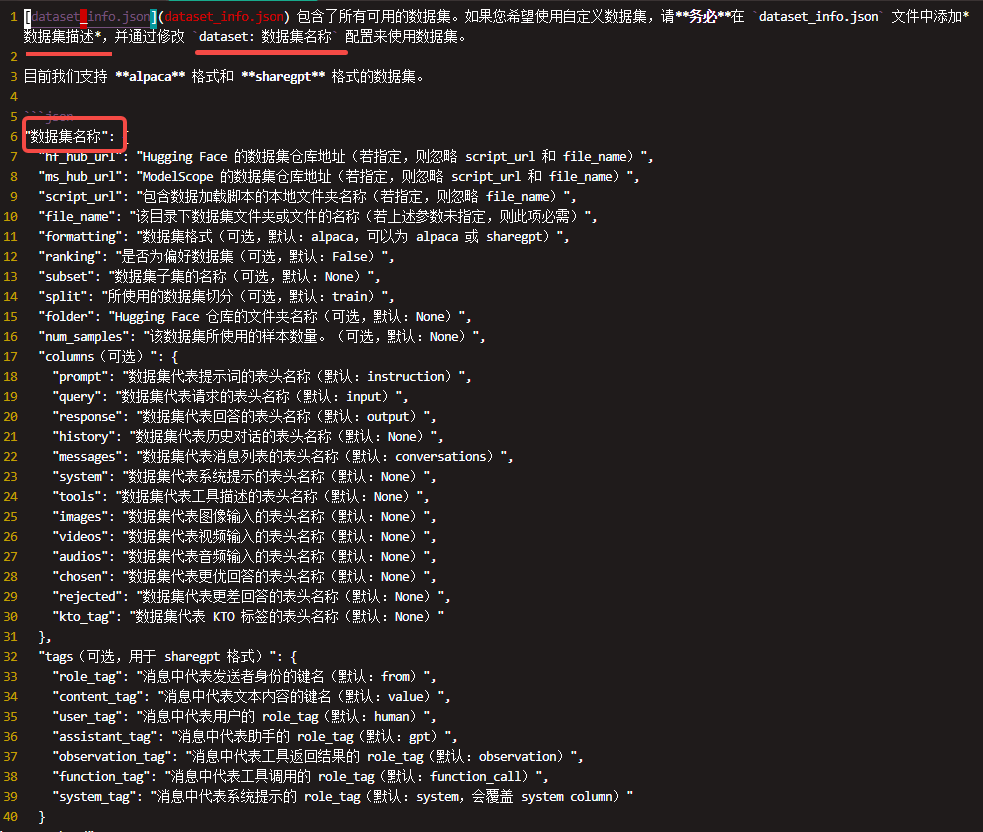
dataset_info.json
|
dataset_info.json |
README_zh.md |
|
|
|
|
|
mllm_demo.json
|
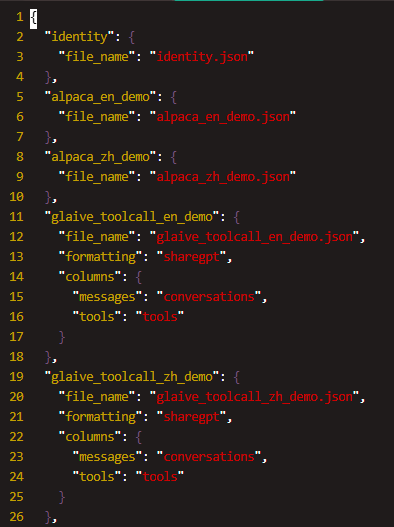
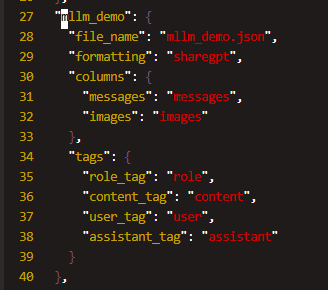
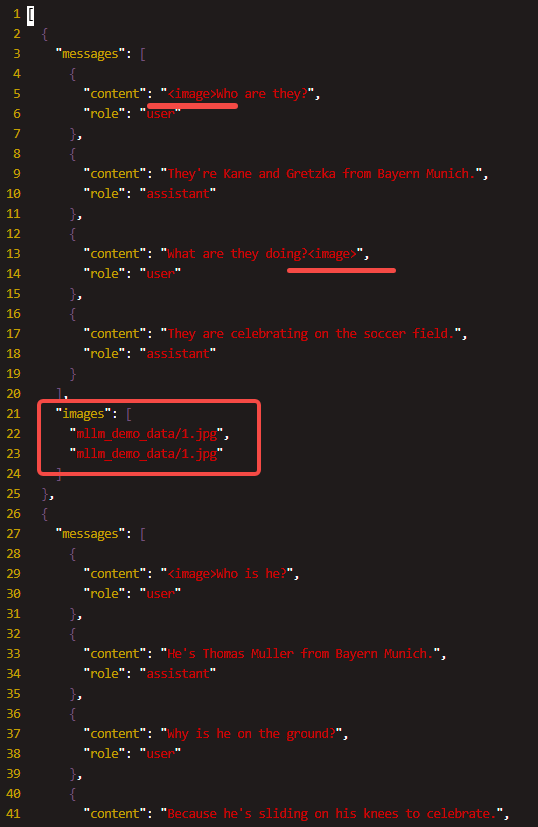
使用 alpaca_zh_demo.json, 一共1000条进行微调

模型训练

-
训练
-
评估、预测
-
对话
-
导出
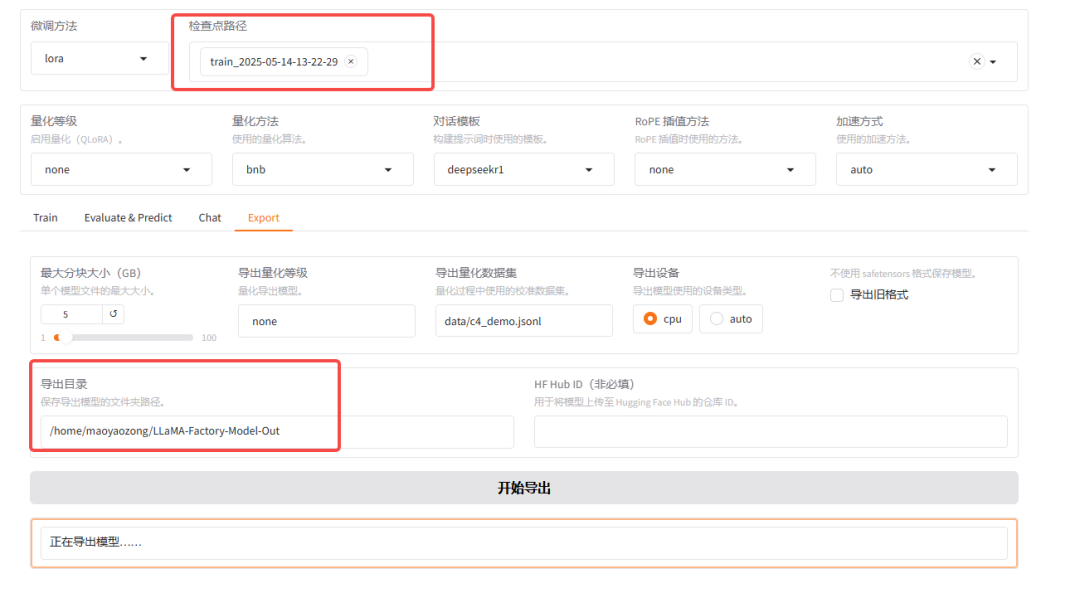
我们在deepseek-r1模型上训练完之后会得到一个lora模型, 和原有基座模型进行合并,最后导出微调后的模型
-
在开始训练模型之前,需要指定的参数有:
-
模型名称及路径

-
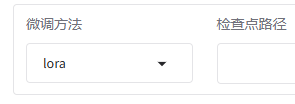
微调方法
-
训练阶段
-
训练数据集
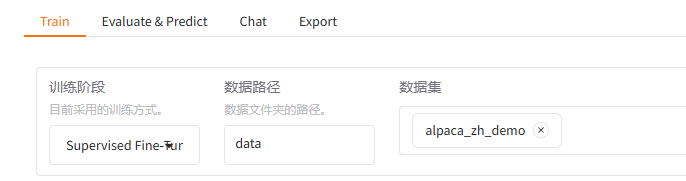
-
学习率、训练轮数等训练参数
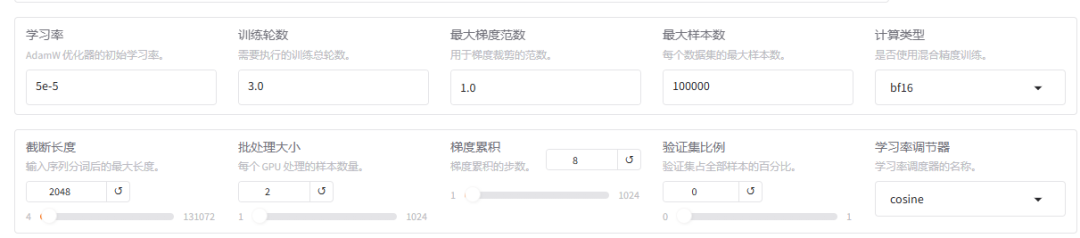
-
训练轮数, 越多越好, 一般的业务训练要几十到100轮,根据业务和效果的需求;
-
微调参数等其他参数
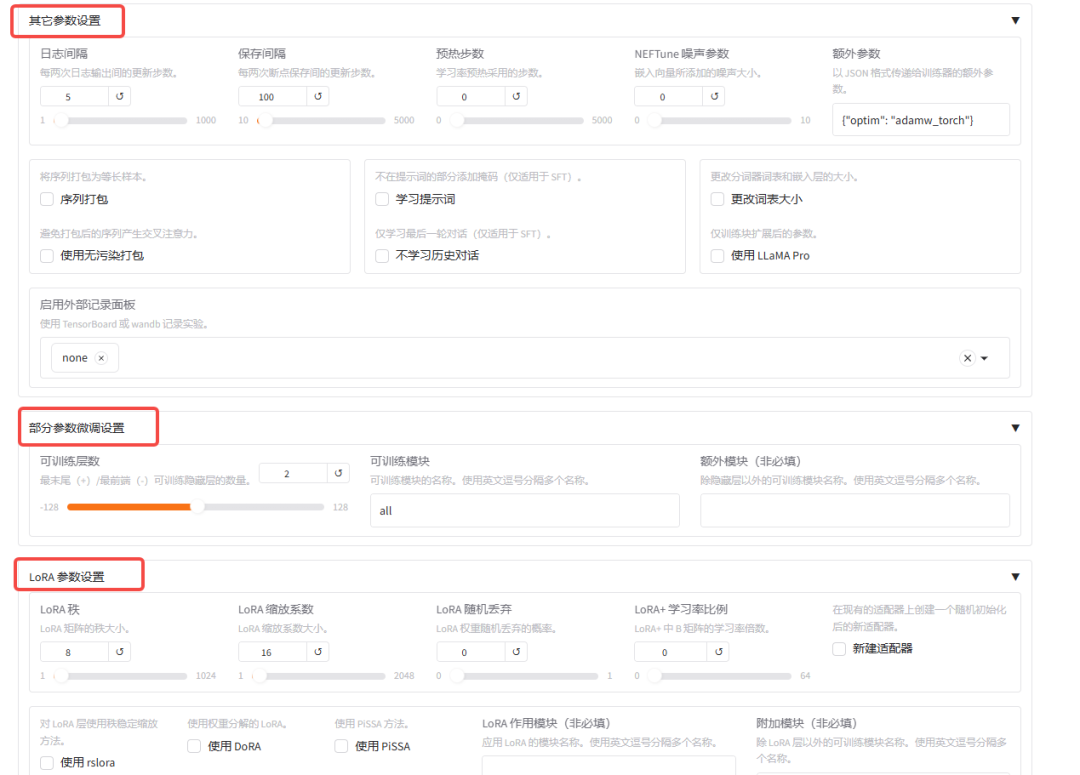
-
输出目录及配置路径
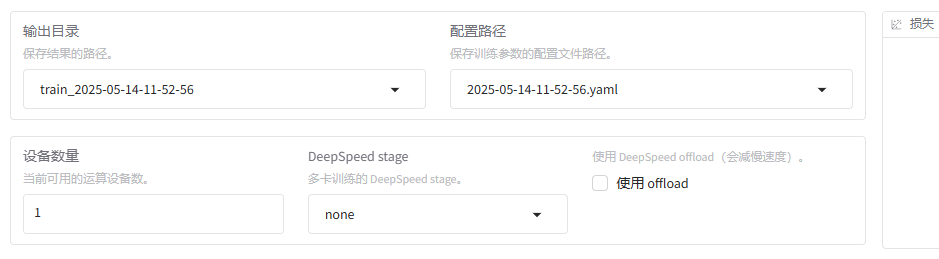
-
点击【预览命令】,可以看到生成好的参数命令, 这里和使用命令行去调用效果是一样的

llamafactory-cli train \--stage sft \--do_train True \--model_name_or_path /home/maoyaozong/LLaMA-Factory-Model/models--deepseek-ai--DeepSeek-R1-Distill-Qwen-1.5B \--preprocessing_num_workers 16 \--finetuning_type lora \--template deepseekr1 \--flash_attn auto \--dataset_dir data \--dataset alpaca_zh_demo \--cutoff_len 2048 \--learning_rate 5e-05 \--num_train_epochs 3.0 \--max_samples 100000 \--per_device_train_batch_size 2 \--gradient_accumulation_steps 8 \--lr_scheduler_type cosine \--max_grad_norm 1.0 \--logging_steps 5 \--save_steps 100 \--warmup_steps 0 \--packing False \--report_to none \--output_dir saves/DeepSeek-R1-1.5B-Distill/lora/train_2025-05-14-11-52-56 \--bf16 True \--plot_loss True \--trust_remote_code True \--ddp_timeout 180000000 \--include_num_input_tokens_seen True \--optim adamw_torch \--lora_rank 8 \--lora_alpha 16 \--lora_dropout 0 \--lora_target all
-
模型训练过程
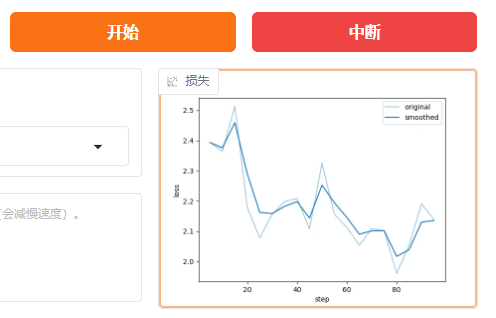
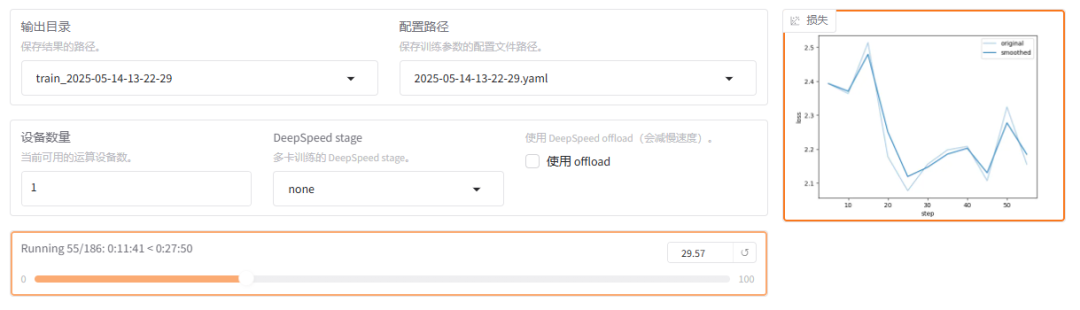
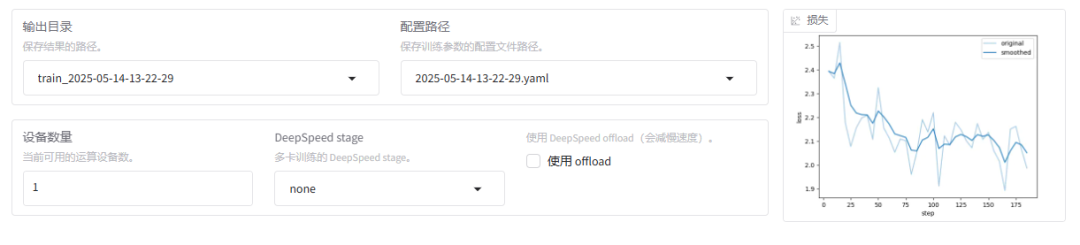
loss(损失)
含义:损失值是一个衡量模型预测与实际标签之间差异的指标。损失值越小,表示模型的预测结果越接近真实值。
例子:假设我们在训练一个猫狗分类器,损失值为0.7493表示模型在当当前训练状态下,预测结果与实际标签之间的差异程度。损失值越小,说明模型的预测越准确。
-
在web UI 上可以看到训练的日志

-
在代码 saves 目录下也可以看到训练的日志
-
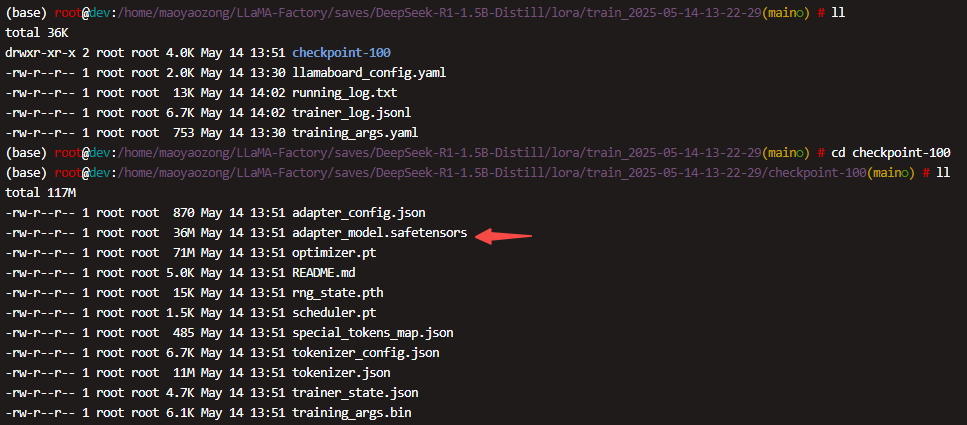
训练完成后,在checkpoint目录下面, 有一个adapter_model.safetensors 这个就是lora 模型
-
可找到该模型历史上使用webui训练的LoRA模型文件,后续再训练或者执行chat的时候,即会将此LoRA一起加载。

-
将模型导出到 LLaMA-Factory-Model-Out
部署微调模型
-
部署到Ollama 对外提供服务
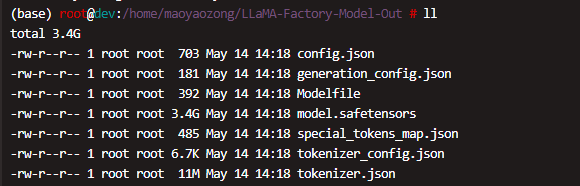
导出了以下文件:
-
config.json -
generation_config.json -
Modelfile -
model.safetensors -
special_tokens_map.json -
tokenizer_config.json -
tokenizer.json
这些文件是部署到 Ollama 所需的全部文件
LLaMA-Factory 导出的模型已经包含了 Modelfile 文件,这个文件是 Ollama 用来识别模型结构的配置文件
-
目前ollama下的服务:

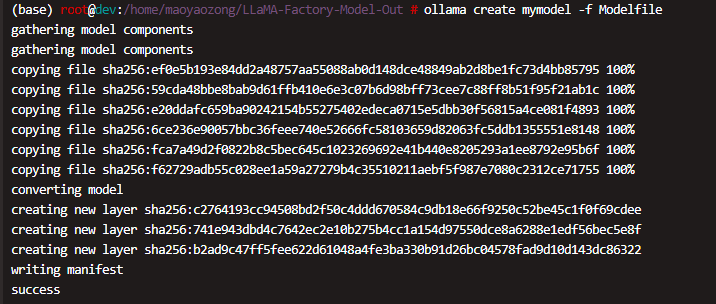
导入模型到 Ollama
在模型文件所在目录运行以下命令,将模型导入到 Ollama
ollama create mymodel -f Modelfile其中 mymodel 是你为模型指定的名称
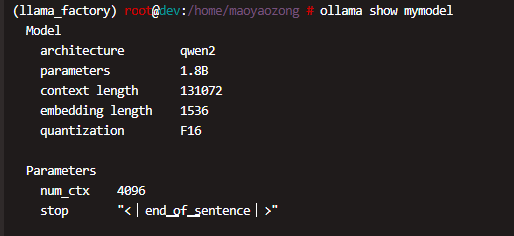
验证模型导入
导入完成后,可以通过以下命令查看模型信息:
ollama show mymodel这将显示模型的详细信息,确保模型已正确导入
运行模型
启动模型并进行推理:
ollama run mymodel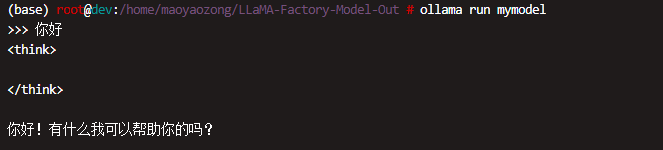
如果使用的是旧版本 Ollama,可能需要将 .safetensors 文件转换为 .gguf 格式
-
最终ollama对外提供的服务
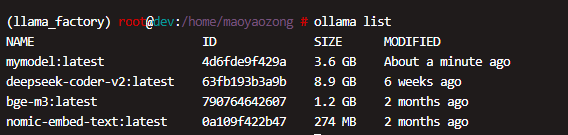
流式请求
curl -X POST http://localhost:11434/api/generate \-H "Content-Type: application/json" \-d '{"model": "mymodel:latest","prompt": "Hello, how are you?","max_tokens": 100}'
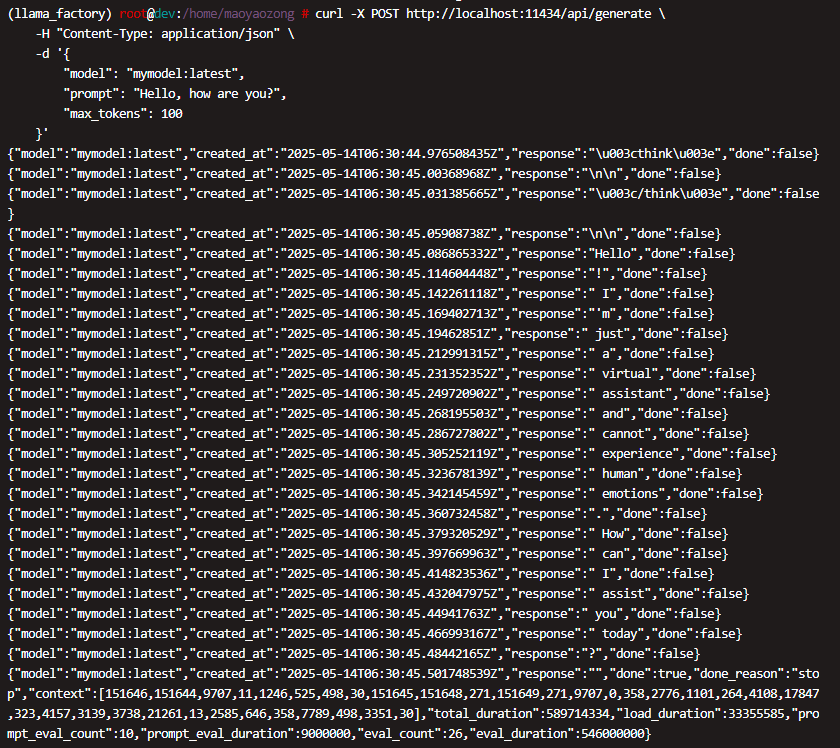
非流式请求
curl -X POST http://localhost:11434/api/generate \-H "Content-Type: application/json" \-d '{"model": "mymodel:latest","prompt": "Hello, how are you?","max_tokens": 100,"stream": false}'
我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
第一不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来: 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 21
21 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)