
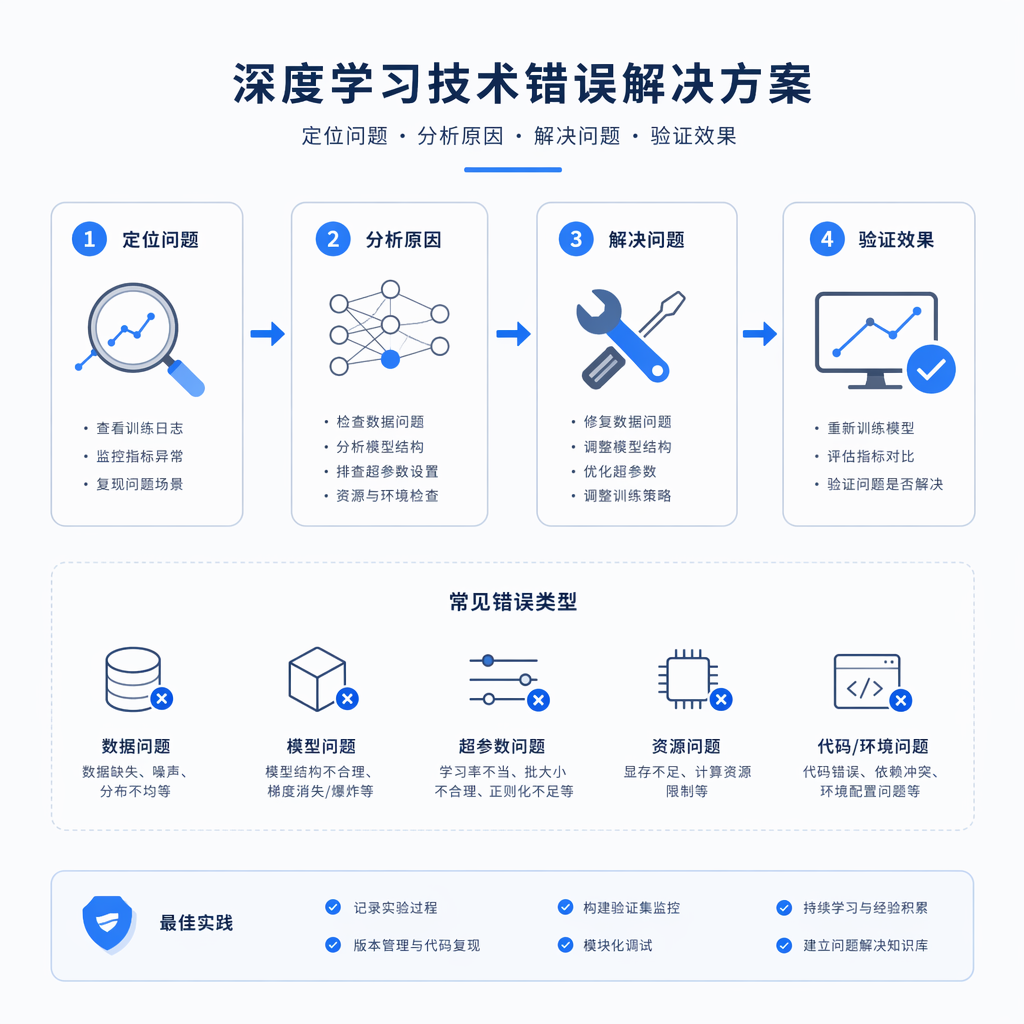
DFlash推测解码和SGLang支持
Ref
https://github.com/z-lab/dflash
https://github.com/bstnxbt/dflash-mlx
DFlash: Block Diffusion for Flash Speculative Decoding
DFlash: Block Diffusion for Flash Speculative Decoding - Z Lab
https://huggingface.co/z-lab/Kimi-K2.6-DFlash
DFlash基本原理
DFlash核心洞察
核心观点:目标模型才是最优参考
天下确有 “免费的午餐”。大型自回归大语言模型的隐层特征中,天然蕴含着多个未来词元的相关信息,Samragh 等人也观测到了这一现象。DFlash 并未让小型扩散模型从零开始推理,而是将目标模型提取的上下文特征作为条件输入给草稿模型,兼顾了目标模型强大的深度推理能力与草稿模型的并行计算速度。
扩散模型为何实现突破
扩散式草稿生成方案之所以表现出众,背后有着更深层的原因。 传统自回归草稿模型逐一生成词元,计算开销会随词元数量呈线性增长。为此,EAGLE-3 只能采用极浅的网络结构(仅单层 Transformer)来控制延迟,这也大幅拉低了草稿生成的质量。
而扩散类草稿模型可通过单次并行前向传播生成全部词元,无论生成多少词元,计算开销基本保持稳定。这让 DFlash 能够搭建层数更深、表达能力更强的模型,且不会带来延迟损耗。实际测试中:多层结构的 DFlash 生成 16 个词元的延迟,甚至低于单层 EAGLE-3 生成 8 个词元的延迟。模型层数更深、生成词元更多,耗时反而更短。
DFlash推理流程
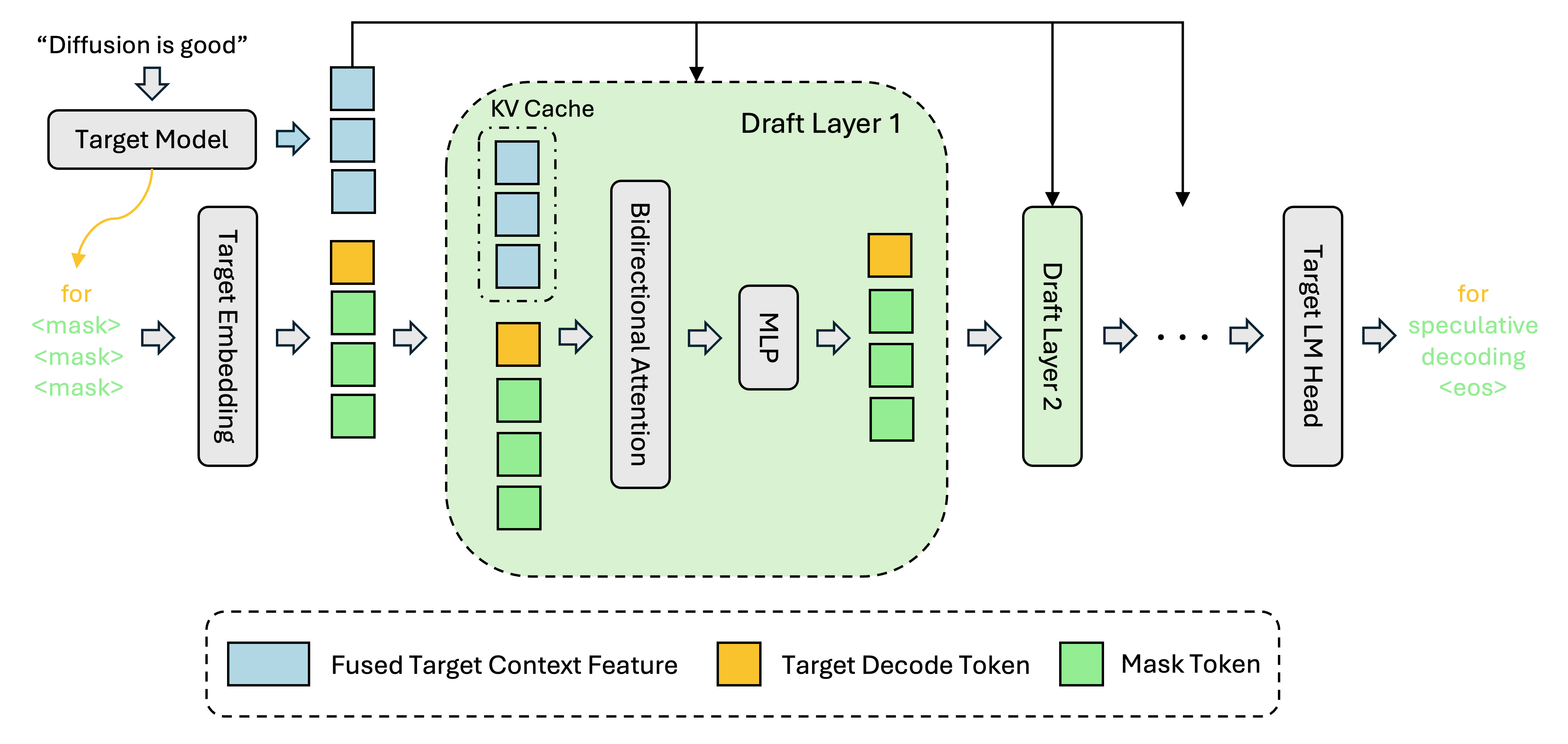
DFlash 推理流程:融合目标模型多层的隐层特征,并将其注入每一层草稿模型的键值缓存(KV Cache),为整个模型提供持续的条件约束。
target model prefill
num_input_tokens = input_ids.shape[1]
max_length = num_input_tokens + max_new_tokens
block_size = model.block_size if block_size is None else block_size
mask_token_id = model.mask_token_id if mask_token_id is None else mask_token_id
output_ids = torch.full(
(1, max_length + block_size), mask_token_id, dtype=torch.long, device=target.device,
)
output = target(
input_ids,
position_ids=position_ids[:, :num_input_tokens],
past_key_values=past_key_values_target,
use_cache=True,
logits_to_keep=1,
output_hidden_states=block_size > 1,
)
output_ids[:, :num_input_tokens] = input_ids
output_ids[:, num_input_tokens:num_input_tokens + 1] = sample(output.logits, temperature)
if block_size > 1:
target_hidden = extract_context_feature(output.hidden_states, model.target_layer_ids)
def extract_context_feature(
hidden_states: list[torch.Tensor],
layer_ids: Optional[list[int]],
) -> torch.Tensor:
offset = 1
selected_states = [hidden_states[layer_id + offset] for layer_id in layer_ids]
return torch.cat(selected_states, dim=-1)
output_ids初始化为num_input_tokens + max_new_tokens + block_size的长度,填充内容为mask_token_id。
首先运行target模型,得到target模型每一层的hidden state,以及kv cache。
output_ids填充input token和大模型生成的第一个token,其余内容为初始化的mask_token_id。
提取大模型中间一些层的hidden_states并且在特征维度进行拼接。
在draft model里面,target_hidden = self.hidden_norm(self.fc(target_hidden))处理后输入Qwen3DFlashDecoderLayer,然后直接与draft model attention的key value矩阵相乘得到KV Cache,这部分正是需要存储的kv cache。小模型自己计算出的kv cache并不需要做offload。
draft model predict
block_output_ids = output_ids[:, start : start + block_size].clone()
block_position_ids = position_ids[:, start : start + block_size]
if block_size > 1:
noise_embedding = target.model.embed_tokens(block_output_ids)
draft_logits = target.lm_head(model(
target_hidden=target_hidden,
noise_embedding=noise_embedding,
position_ids=position_ids[:, past_key_values_draft.get_seq_length(): start + block_size],
past_key_values=past_key_values_draft,
use_cache=True,
is_causal=False,
)[:, 1 - block_size :, :])
past_key_values_draft.crop(start)
block_output_ids[:, 1:] = sample(draft_logits)
if draft_prefill and return_stats:
draft_prefill = False
decode_start = _cuda_time()
block_output_ids 为一个block的Input_ids,其中第一个是大模型预测的输出,其他的为mask_id。
draft model第一个输入为大模型的hidden_states拼接。
第二个为block_output_ids的embedding。
DFlash adopts a fundamentally different strategy. We treat the fused target context feature as persistent contextual information and directly inject it into the Key and Value projections of every draft model layer. The projected features are stored in the draft model’s KV cache and reused across drafting iterations.
DFlash 采用了一种截然不同的实现思路。该方案将融合后的目标上下文特征作为常驻上下文信息,直接注入每一层草稿模型的键值投影层中。经过投影的特征会存入草稿模型的键值缓存,并在多轮草稿生成过程中重复使用。

也就是,拿取大模型的拼接的target_hidden,经过一个投影后,直接与draft model的每一层key, value 矩阵得到前面部分的kv cache,然后再用当前的draft model 的hidden得到后续部分block_size个元素的kv cache。注意每一层都用直接用相同的这个hidden 计算draft kv cache。
而eagle是在第一个decoder 入口进行大小模型hidden 拼接。
target model verify
output = target(
block_output_ids,
position_ids=block_position_ids,
past_key_values=past_key_values_target,
use_cache=True,
output_hidden_states=block_size > 1,
)
posterior = sample(output.logits, temperature)
acceptance_length = (block_output_ids[:, 1:] == posterior[:, :-1]).cumprod(dim=1).sum(dim=1)[0].item()
output_ids[:, start : start + acceptance_length + 1] = block_output_ids[:, : acceptance_length + 1]
output_ids[:, start + acceptance_length + 1] = posterior[:, acceptance_length]
start += acceptance_length + 1
past_key_values_target.crop(start)
acceptance_lengths.append(acceptance_length + 1)
if block_size > 1:
target_hidden = extract_context_feature(output.hidden_states, model.target_layer_ids)[:, :acceptance_length + 1, :]
用小模型得到的output_ids用大模型进行一次验证,看看接收多少,这个部分与之前的eagle应该没有什么区别,其他区别在于应该没有topk>1的beam search。不过eagle也很少采用topK >1.
一个主流大模型的DFlash draft模型样例
https://huggingface.co/z-lab/Kimi-K2.6-DFlash
总共有6层,而target模型有61层。
一些核心配置参数
"block_size": 8,
"dflash_config": {
"mask_token_id": 163838,
"target_layer_ids": [
1,
12,
24,
35,
47,
58
]
},
"layer_types": [
"sliding_attention",
"sliding_attention",
"sliding_attention",
"sliding_attention",
"sliding_attention",
"full_attention"
],
"sliding_window": 2048,
"use_sliding_window": true,
"head_dim": 128,
"num_attention_heads": 64,
"num_hidden_layers": 6,
"num_key_value_heads": 8,对这个小模型,draft model每个token的kv cache (FP8): 6*2*8*128 = 12k
DFlash与Eagle/MTP的区别
自回归vs并行生成
Eagle或者MTP(后面统称Eagle)是自回归的,也就是小模型仍然是transformer架构模型,需要进行多轮迭代每次生成多个token,只是小模型迭代生成token的消耗远小于大模型。
DFlash是一次性并行生成block_size个token。
Eagle通常只有一层,而DFlash有多层。
Eagle和DFlash都复用大模型的Embedding和lm_head层。
特征融合方式
Eagle的特征融合方式:
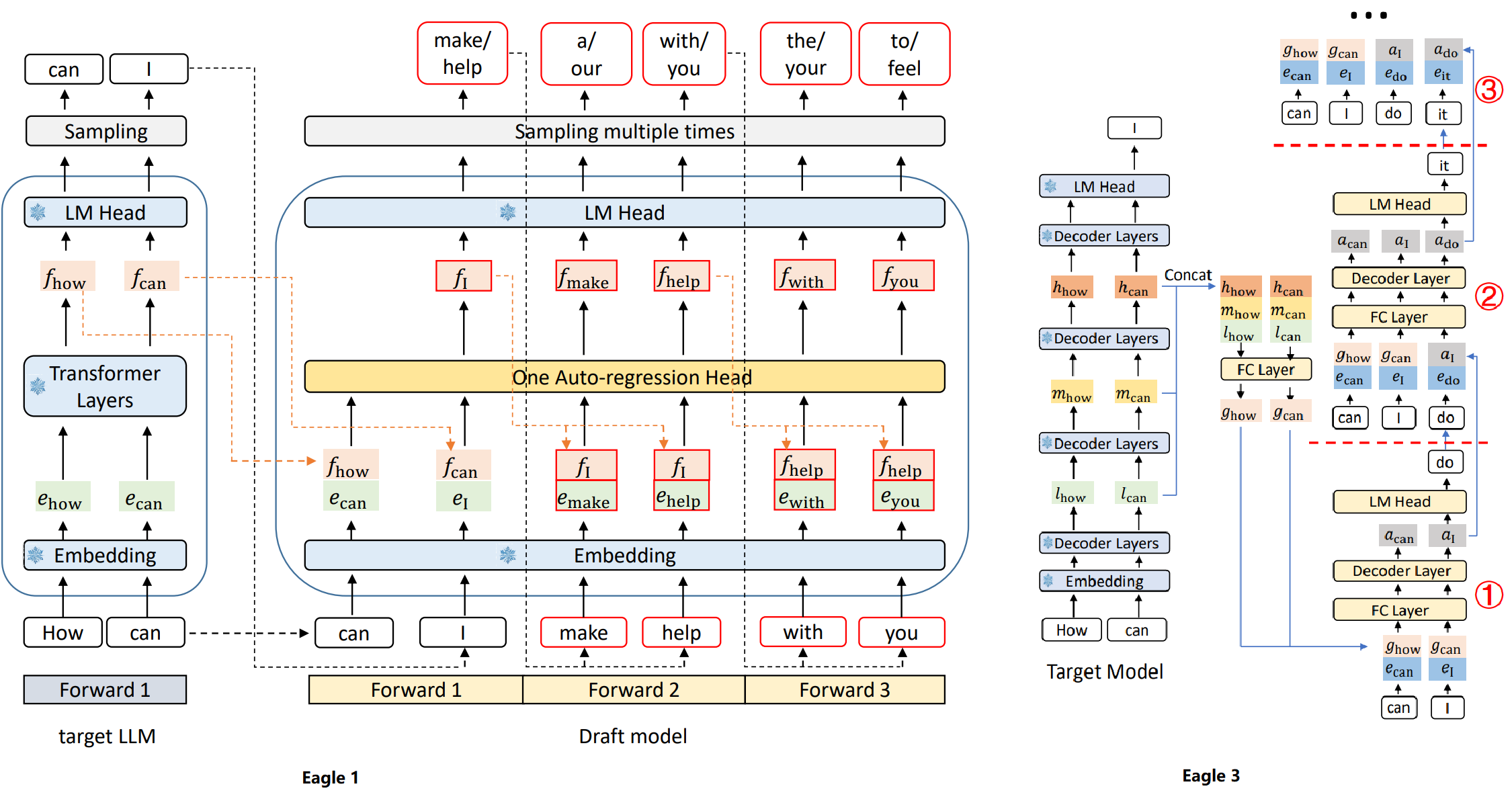
Eagle1和Eagle3的区别是,Eagle1只使用最后一层的hidden,而Eagle 3抽取3层的hidden。而DFlash抽取更多层的hidden。
Eagle特征融合方式详解:
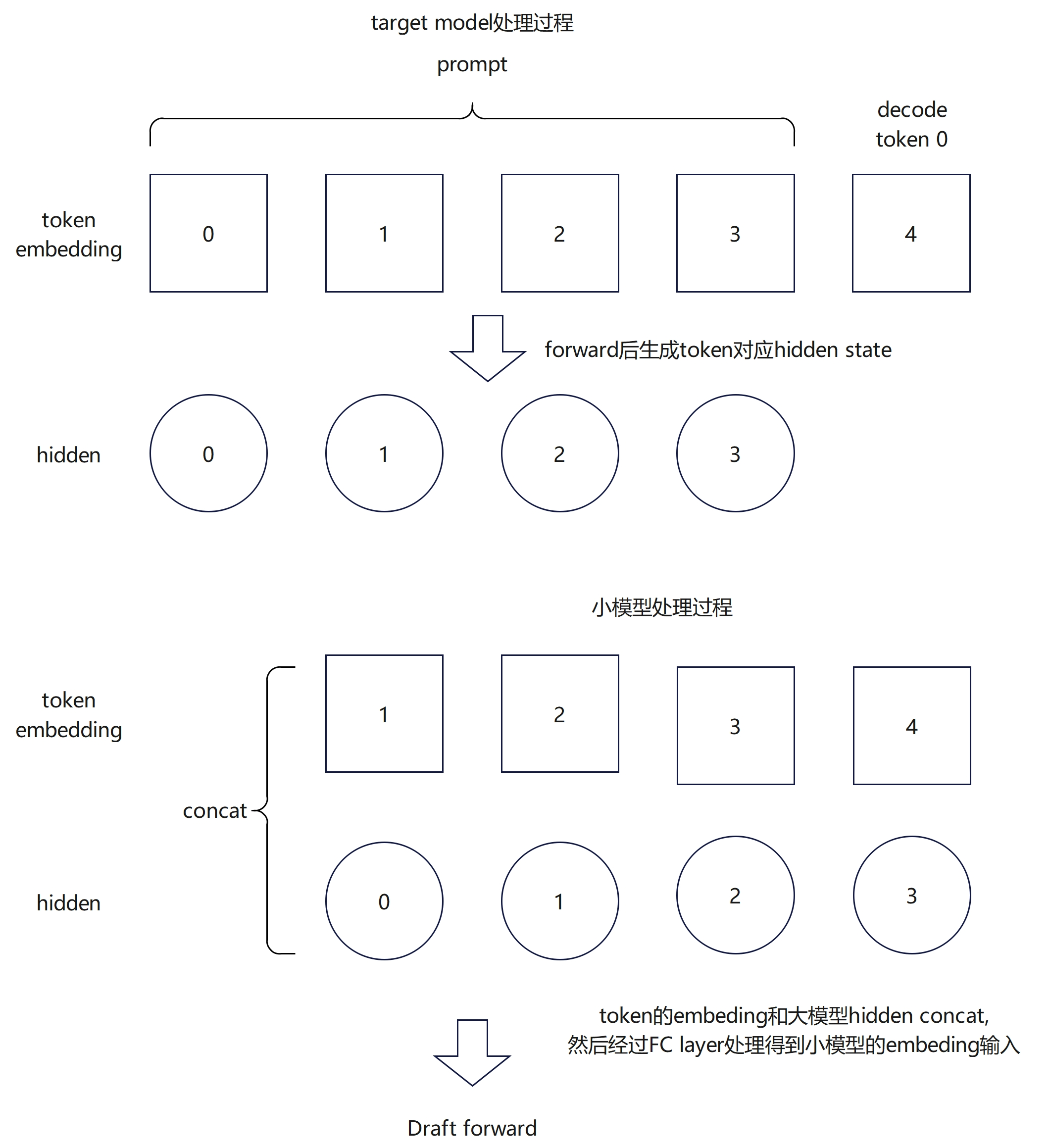
大模型的hidden和token的embedding拼接在一起,然后经过FC layer处理后,送入transformer layer处理。注意hidden和embedding的token是一维一格再拼接的,因为当前生成的下一个output token还没有对应的hidden state,只能进行embedding。
DFlash这里比较简单,直接用拼接的多层大模型hidden经过FC layer处理后,对于每一层都复用一样的这个大模型hidden,然后与小模型的K V矩阵计算得到kv cache作为信息注入。
这篇论文比较了像eagle那样一次性在模型入口进行特征注入,与每一层进行注入,发现每一层注入效果更好。
KV Cache
当前的LLM都是transformer decoder架构,每个token只与前面的token进行attention计算,因此可以存储当前的token kv cache,后续token不会影响当前token kv cache计算结果。而存储之前token的kv cache可以显著加速推理过程。
对于多级kv cache存储系统,除了存储大模型的kv cache,也有必要存储小模型的kv cache。当前sglang引擎进行了小模型的kv cache多级存储。
Eagle模型仍然是transformer decoder,因此Eagle模型需要存储kv cache用于加速。
DFlash也有kv cache,不过与eagle有所不同。
eagle需要用大模型的hidden和小模型的embedding进行一次shfit拼接后得到的hidden输入小模型进行一次forward。
dflash用大模型拼接的hidden,直接与小模型每一层的KV矩阵计算得到kv cache。
是否需要对prompt进行prefill计算
Eagle需要进行一次prefill计算,生成prompt的kv cache,从而用于decode部分的生成加速。如果不进行prefill,直接用空的kv cache,也能跑,只是加速比例会下降。
从DFlash代码中https://github.com/z-lab/dflash/blob/main/dflash/model.py,
可以看到prefill只进行了target model的prefill,而没有进行draft model的prefill。
但实际上,这里省略了一步,大模型的prompt的hidden state进入小模型的kv cache计算实际上可以认为是小模型的第一次prefill。
后续只需要一个新的block的output token的hidden进入小模型进行kv cache计算。
所以还是有的,只是与eagle稍微有一些差异。
draft token接受方式
accept_len, bonus = compute_dflash_correct_drafts_and_bonus(candidates=candidates,target_predict=target_predict,)
matches = candidates[:, 1:] == target_predict[:, :-1]
直接用大模型生成的结果对小模型的结果进行严格匹配。
SGLang DFlash支持
参数设置参考
# Optional: enable schedule overlapping (experimental, may not be stable)
# export SGLANG_ENABLE_SPEC_V2=1
# export SGLANG_ENABLE_DFLASH_SPEC_V2=1
# export SGLANG_ENABLE_OVERLAP_PLAN_STREAM=1
python -m sglang.launch_server \
--model-path moonshotai/Kimi-K2.6 \
--speculative-algorithm DFLASH \
--speculative-draft-model-path z-lab/Kimi-K2.6-DFlash \
--speculative-num-draft-tokens 8 \
--tp-size 8 \
--attention-backend trtllm_mla \
--speculative-draft-attention-backend fa4 \
--mem-fraction-static 0.9 \
--speculative-dflash-draft-window-size 4096 \
--trust-remote-code
SGLang DFlash实现流程
1. 参数归一化
入口在 speculative_hook.py (line 124)。
DFLASH 会被强制成一种“固定 block verify”的 spec-v2 算法:
- 必须设置
--speculative-draft-model-path - 不支持 DP attention
- 只支持
pp_size == 1 speculative_num_steps强制为1speculative_eagle_topk强制为1--speculative-dflash-block-size是--speculative-num-draft-tokens的别名- 如果没显式给 block size,会从 draft model config 的
dflash_config.block_size推断,失败则默认16 - 默认把
max_running_requests设为48 - 禁用 mixed chunk prefill
也就是说,DFLASH 不走 EAGLE 的多 step/tree top-k 草稿树,而是每轮验证一个线性 block:长度就是 speculative_num_draft_tokens。
2. 算法分派
SpeculativeAlgorithm.DFLASH 定义在 spec_info.py (line 22),create_worker() 返回 DFlashWorkerV2 (line 64)。
调度器初始化时:
- target worker 正常加载目标模型
maybe_init_draft_worker()创建 DFLASH draft workerself.model_worker = self.draft_worker,后续 generation 由DFlashWorkerV2.forward_batch_generation()接管- draft worker 内部仍持有
target_worker,所以它可以先跑 target prefill/verify,再跑 draft
对应代码在 scheduler.py (line 780)。
3. Target 隐藏层捕获
DFLASH draft 模型需要目标模型若干中间层 hidden state 作为上下文特征。
ModelRunner 在 target worker 初始化时解析 draft config:
- 读取 draft config 的
num_hidden_layers - 读取或推导
target_layer_ids - 保存到
self.dflash_target_layer_ids
见 model_runner.py (line 500)。
随后 init_aux_hidden_state_capture() 会调用目标模型的:
self.model.set_dflash_layers_to_capture(self.dflash_target_layer_ids)见 model_runner.py (line 1006)。
例如 Llama 的实现会把 layer id 加一后放进 layers_to_capture,forward 时收集中间层 hidden,最后 logits processor 会把多个 aux hidden 按最后一维 concat 起来,作为 logits_output.hidden_states 返回。
4. Draft 模型结构
DFLASH draft 模型在 models/dflash.py (line 308)。
关键点:
- 它没有自己的 token embedding
- 它没有自己的 lm_head
- 输入 embedding 用 target model 的 embedding
- 生成 token 时用 target model 的
lm_head - 它有自己的 transformer layers 和 draft KV cache
project_target_hidden()把 target 多层 hidden concat 后经fc + hidden_norm投影到 draft hidden size
所以 DFLASH 的 draft KV 不是由 draft token 自回归产生的,而是把 target captured hidden 映射成 draft 模型的 K/V。
5. Prefill 流程
在 DFlashWorkerV2.forward_batch_generation (line 1193),如果 batch 是 extend/prefill:
- 设置
capture_hidden_mode = FULL - 调用 target worker 做正常 prefill
- target 返回:
next_token_idslogits_output.hidden_states,即 DFLASH 需要的 aux hidden features
- 用
_append_target_hidden_to_draft_kv_by_loc()把 prompt 的 target hidden 写进 draft KV - 构造下一轮的
DFlashDraftInputV2:verified_id = next_token_idsnew_seq_lens = 当前 seq_lensverify_done = cuda event
这一步的目的:prompt 已经由 target 计算过,把 prompt 对应的上下文特征立刻灌进 draft KV,这样 decode 阶段 draft 模型可以直接基于这些 KV 预测。
6. Decode 前准备
ScheduleBatch.prepare_for_decode() 遇到 speculative 时不自己分配普通 1 token KV,而是调用:
draft_input.prepare_for_decode(self)见 schedule_batch.py (line 2575)。
DFLASH 的实现是 DFlashDraftInputV2.prepare_for_decode (line 132)。
它会:
- 读取每个 request 的
kv_committed_len - 为每个请求预留
block_size - 实际保留到
committed_len + 2 * block_size,用于 overlap 双缓冲 - 更新共享
req_to_token - 保存:
planning_seq_lens_cpureserved_seq_lens_cpucur_allocated_seq_lens_cpu
- DFLASH 的 host-side
seq_lens_cpu会故意落后一拍,真正的新长度通过new_seq_lens在 GPU 上传递
这就是 DFLASH overlap 的核心:提前把 verify block 的 KV slot 准备好,让 forward 不被 allocator 阻塞。
7. Decode 主流程:三段式
Decode 阶段在 dflash_worker_v2.py (line 1276) 开始,分三步。
第一步,draft 固定 block:
- 构造
block_ids,形状[bs, block_size] - 第 0 个 token 是上一轮 target 确认的
verified_id - 后面全是 DFLASH mask token
- positions 是
prefix_len + [0, 1, ..., block_size-1] - out cache loc 从共享
req_to_token中取出
逻辑等价于:
[current_verified_token, <MASK>, <MASK>, ..., <MASK>]然后:
- 用 target embedding 得到
input_embeds - 调用 draft model forward
- draft model 返回 hidden states
- 用 target lm_head 对
draft_hidden[:, 1:]做 argmax - 得到 draft candidates:
candidates[:, 0] = current_verified_token
candidates[:, 1:] = draft predicted tokens第二步,target verify:
- 把
candidatesflatten 成bs * block_size - 构造
DFlashVerifyInput - 设置
ForwardMode.TARGET_VERIFY - 调 target worker 一次性验证整个 block
- target 返回每个位置的 logits 和 hidden states
贪心模式下验收规则在 dflash_utils.py (line 551):
matches = candidates[:, 1:] == target_predict[:, :-1]
correct_len = matches.to(int32).cumprod(dim=1).sum(dim=1)
bonus = target_predict[row, correct_len]也就是:
接受 candidate[1] 当 target 在位置 0 预测 candidate[1]
接受 candidate[2] 当 target 在位置 1 预测 candidate[2]
...
第一个不匹配处停止
bonus token = target 在停止位置预测的 token最终提交长度:
commit_lens = accepted_draft_tokens + 1 bonus非 greedy sampling 时,如果 sgl_kernel 的 speculative sampling kernel 可用,会走 compute_dflash_sampling_correct_drafts_and_bonus();不可用会 warn 并退回 greedy verify。
第三步,写回 draft KV:
- target verify 返回的 hidden 是
[bs, block_size, hidden] - 只把
commit_lens前缀对应的 hidden 写入 draft KV - 写入函数仍是
_append_target_hidden_to_draft_kv_by_loc() - CUDA/ROCm 上优先用 fused KV materialization,否则逐层
kv_proj_only + k_norm + rope + set_kv_buffer
这里非常关键:DFLASH 的 draft KV 始终来自 target hidden,而不是来自 draft 自己的 hidden。
8. 返回给 scheduler 的结果
DFLASH 返回 GenerationBatchResult:
next_token_ids = out_tokens.reshape(-1)accept_lens = commit_lensnext_draft_input.verified_id = bonusnext_draft_input.new_seq_lens = prefix_lens + commit_lensspeculative_num_draft_tokens = block_size
见 dflash_worker_v2.py (line 1675)。
out_tokens 每行是:
accepted draft tokens followed by bonus, padding ignored by accept_lens例如 block size 5,接受 2 个 draft token:
candidates: [A, B, C, D, E]
target: [B, C, X, ...]
out_tokens: [B, C, X, 0, 0]
accept_lens = 3
next verified_id = X9. 结果提交与 KV 长度
结果处理在 batch_result_processor.py (line 524)。
普通 EAGLE 的 prepare_for_decode 会预占 bonus slot,所以提交时是:
req.kv_committed_len += accept_lens[i] - 1但 DFLASH 已经把“接受的草稿 token + bonus token”都真正物化进 target/draft KV,所以是:
req.kv_committed_len += accept_lens[i]这是 DFLASH 和 EAGLE 在 cache accounting 上最容易漏看的差异。
10. 总结成一条链
CLI DFLASH
-> speculative_hook 归一化 block_size/topk/steps
-> SpeculativeAlgorithm.DFLASH
-> Scheduler 创建 DFlashWorkerV2
-> ModelRunner 配置 target aux hidden capture
-> Prefill:
target prefill + capture aux hidden
aux hidden -> draft KV
verified_id = target next token
-> Decode prepare:
DFlashDraftInputV2 预留 block KV / req_to_token
-> Decode forward:
[verified_id, MASK, ...] -> target embedding -> draft model
draft hidden -> target lm_head -> candidates
candidates -> target TARGET_VERIFY
compare / sampling verify -> accept_lens + bonus
target hidden accepted prefix -> draft KV
-> Scheduler:
输出 accepted draft tokens + bonus
DFLASH: kv_committed_len += accept_lens
next round verified_id = bonus一句话概括:DFLASH 在 SGLang 里是一个“target-hidden 驱动的 fixed-block speculative decoding”。Draft 模型不独立持有 embedding/lm_head,而是依赖 target 的 embedding/lm_head 和 target 中间层 hidden;每轮用 masked block 一次生成一串候选,再由 target 一次 verify 整个 block,接受连续匹配前缀并追加 bonus token。
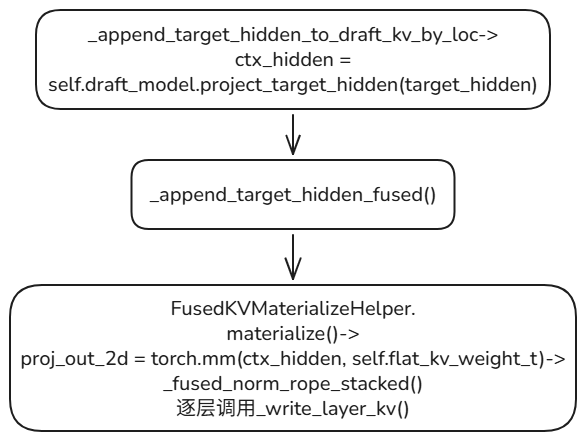
fused_kv_materialize
fused_kv_materialize 是 DFLASH 里的一个性能优化,用来把 target hidden features 转成 draft model KV cache。
位置:
fused_kv_materialize.py (line 1)
它替代的是 DFLASH 里这段逐层逻辑:
for layer in draft_model.layers:
k, v = attn.kv_proj_only(ctx_hidden)
k = attn.apply_k_norm(k)
k = attn.apply_k_rope(positions, k)
token_to_kv_pool.set_kv_buffer(...)也就是把每层 draft attention 需要的 K/V cache 物化出来。
它具体融合了什么
FusedKVMaterializeHelper.materialize() 做三件事:
- 预先把所有 draft layer 的 KV projection weight stack 起来
- 用一次大的
torch.mm同时算所有层的 K/V projection
ctx_hidden [total_ctx, hidden]
x
flat_kv_weight_t [hidden, n_layers * 2 * kv_size]
->
proj_out [total_ctx, n_layers, 2 * kv_size]- 用 Triton kernel 对所有 layer/head/token 做:
- K 的 RMSNorm
- K 的 RoPE
- V 直接整理输出
输出形状大致是:
K: [n_layers, total_ctx, num_kv_heads, head_dim]
V: [n_layers, total_ctx, num_kv_heads, head_dim]最后仍然按 layer 调 write_layer_kv() 写入 SGLang 的 KV pool。
在 DFLASH 里的意义
DFLASH 的 draft KV 不是 draft 模型自己从 token forward 慢慢攒出来的,而是:
target aux hidden
-> draft_model.project_target_hidden()
-> draft attention 的 K/V cache所以每次 prefill 或 verify 接受了一批 token 后,都要把这些 token 对应的 target hidden 写进 draft KV。fused_kv_materialize 就是加速这个“写进 draft KV 前的 K/V 计算”。
它不融合什么
它不负责:
- target 模型 forward
project_target_hidden()的fc + hidden_norm- draft token 采样
- accept/bonus 计算
- 最终 KV pool 管理本身
它主要融合的是:
所有 draft layer 的 KV projection + K RMSNorm + K RoPE启用条件
在 dflash_worker_v2.py (line 312) 初始化。当前主要在 CUDA/HIP 上启用,并要求:
- draft attention 的
qkv_proj是可切片的未量化权重 qkv_proj没有 bias- K/V scale 是 1
- RoPE 是 neox-style
- 各层
num_kv_heads/head_dim/rotary_dim一致
不满足就自动 fallback 到逐层路径。
所以可以把它理解成:DFLASH 专用的“批量生成 draft KV cache”的 fast path。

免费领 150 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 12
12 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)