
15分钟部署&运行 Gemma4 大模型 #Datawhale#AMDev
#Datawhale#AMDev
一、部署&运行 Gemma4 大模型
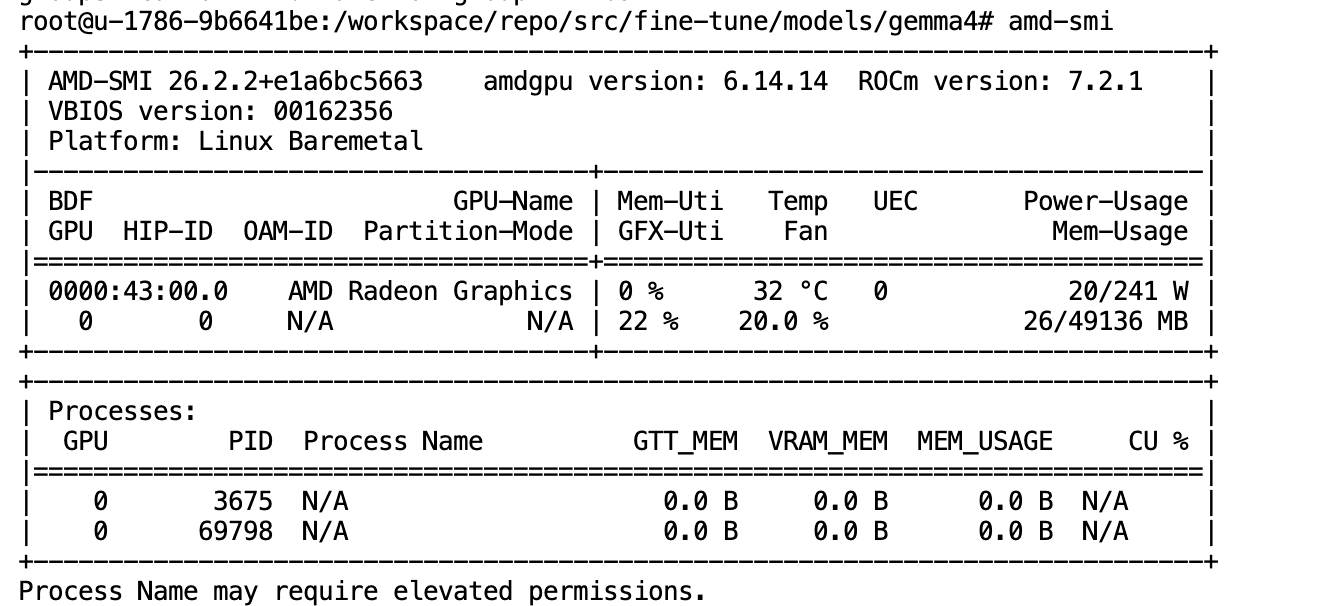
- 检查当前 GPU 是否可用
amd-smi
2. 确认 PyTorch 能识别 AMD GPU
python -c "import torch; print('PyTorch:', torch.__version__); print('ROCm available:', torch.cuda.is_available()); print('Device:', torch.cuda.get_device_name(0) if torch.cuda.is_available() else 'N/A')"

- 下载 Gemma4 模型
Gemma 4 是Google推出的一款大语言模型
为了提升国内环境下的依赖下载速度,先把 pip 源切换到腾讯云镜像
pip config set global.index-url https://mirrors.cloud.tencent.com/pypi/simple/

- 安装 魔搭 ModelScope
什么是 ModelScope? 它是由阿里达摩院主导的国内开源模型社区,是国内的“AI 模型应用商店”。而其服务器在国内,因此能帮我们高速、稳定地把大模型拉到本地。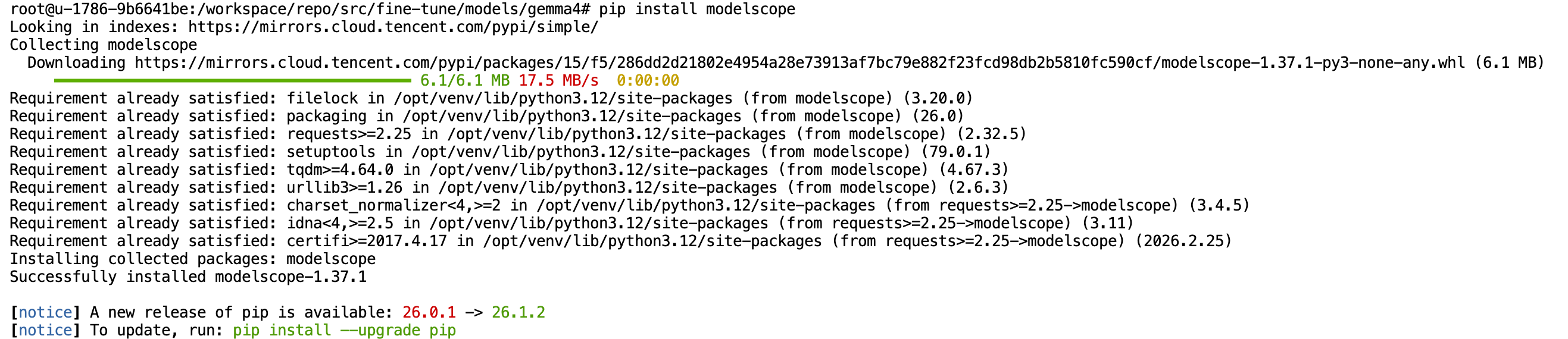
- 下载 Gemma4 模型到当前目录
modelscope download --model google/gemma-4-E4B-it --cache_dir "./models"

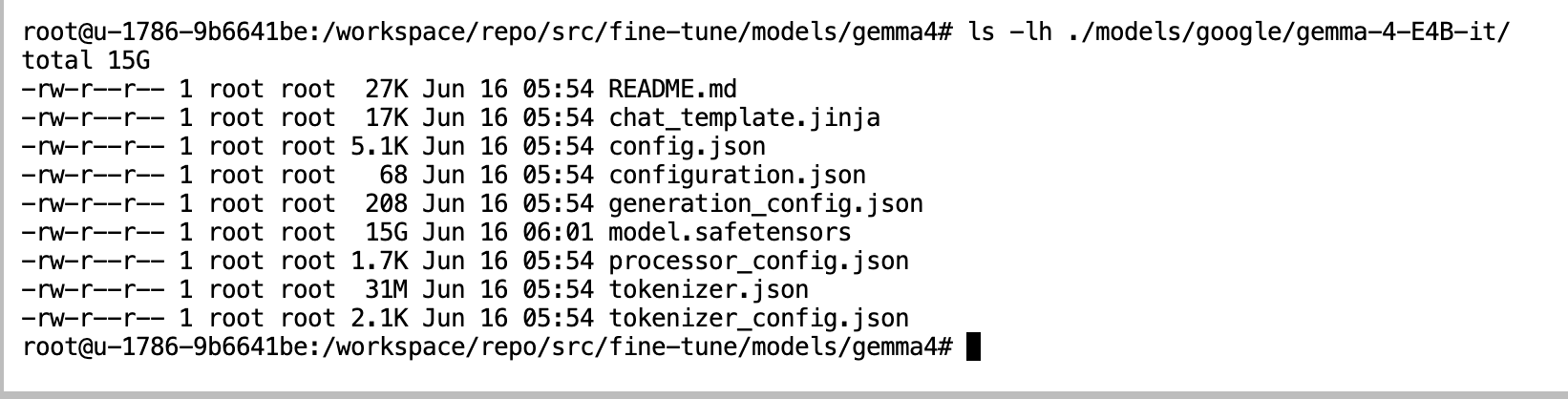
- 确认 Gemma4 模型模型文件完整下载成功
其中15G大的 model.safetensors 是模型权重
ls -lh ./models/google/gemma-4-E4B-it/
7. 启动 vLLM 服务
vLLM 是一个本地高效推理大模型的项目,这里我们使用vLLM来测试刚才下载的模型能否正常使用。
在使用 vLLM 前,需更新云环境中的 vLLM 版本才能运行 Gemma4 模型。
uv pip uninstall torchvision torchaudio # 经测试,在该云环境中,需卸载重新安装这个库才能正常使用
uv pip install 'vllm==0.23.0+rocm723' torchvision torchaudio 'fastapi[standard]==0.136.0' \
--no-cache \
--index-url https://mirrors.aliyun.com/pypi/simple/ \
--extra-index-url https://wheels.vllm.ai/rocm/ \
-U
vllm serve ./models/google/gemma-4-E4B-it/ --served-model-name gemma-4-E4B-it
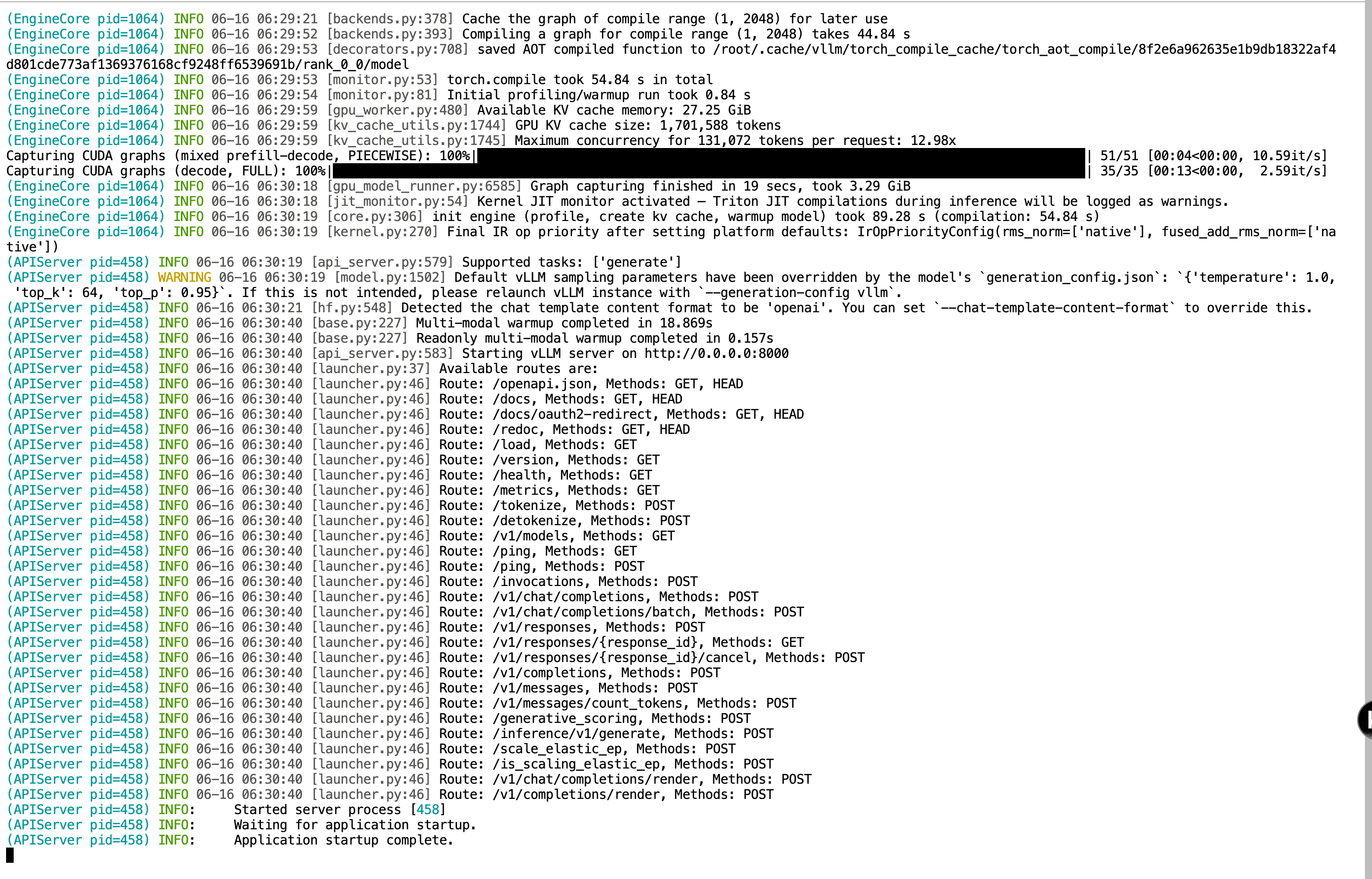
注意:运行这个命令后,这个终端窗口就会 被大模型服务“死死占满” 。请 保持运行,绝对不要关闭它 ,也不要按 Ctrl+C ,否则大模型服务就会立刻停止。
8. 打开新终端进行对话测试
💡 为什么要打开一个“新终端”?
第一个终端正在跑模型服务,像后台厨师在做饭,被占住了不能再输命令。所以要再开一个新终端当"前台",专门用来给模型发命令、跟它对话。
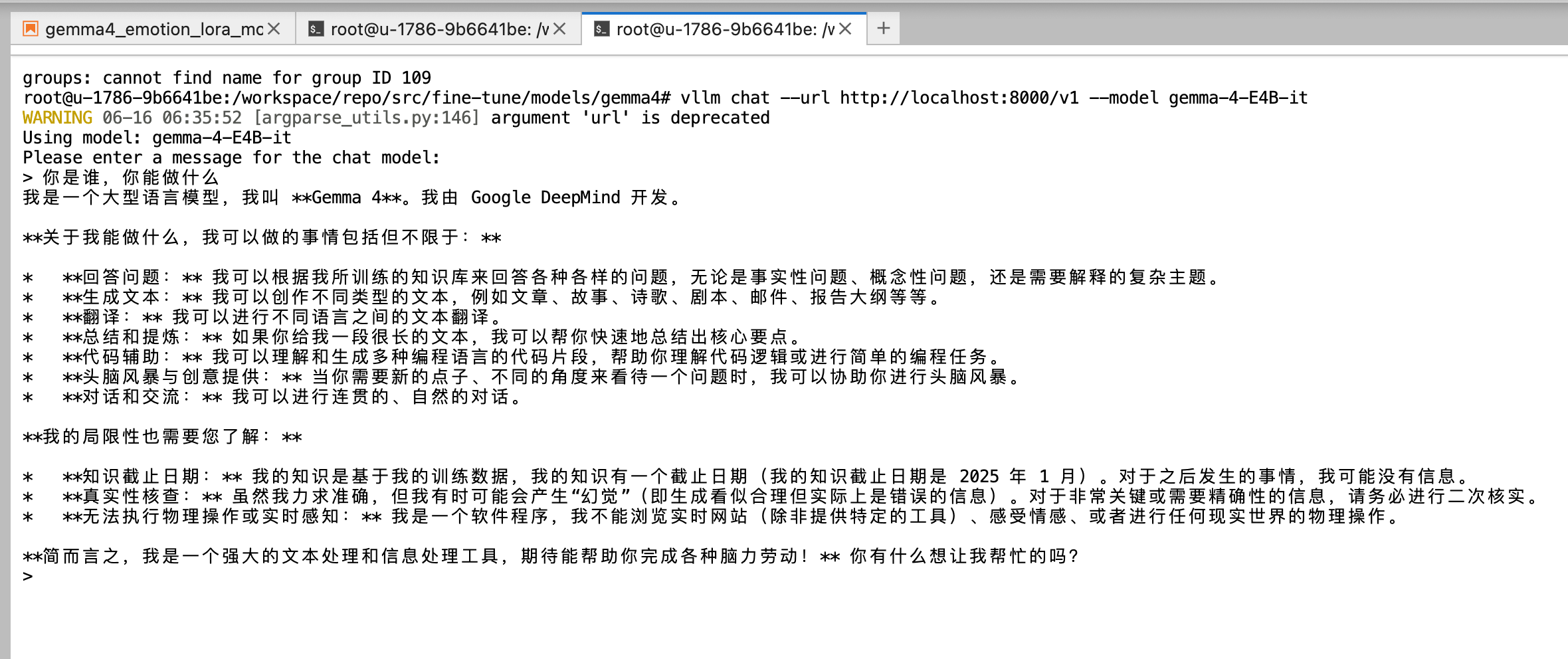
新建 一个 终端 , 在新终端里输入测试命令,发送消息给后台的 Gemma 4 模型,测试它的推理服务是否正常
输入 文本进行测试 :复制如下命令,粘贴命令运行
终端返回模型回答的内容,说明Gemma4已经在 AMD ROCm 云环境中正常运行!
vllm chat --url http://localhost:8000/v1 --model gemma-4-E4B-it
9. 关闭 vLLM 服务
因为我们后续还要对 Gemma4 模型进行微调,因此需关闭这个 vLLM 来为微调任务腾出计算资源
(1)新终端: ( Mac电脑: 按 Control+C ;Windows电脑: 按 Ctrl +C )退出聊天
(2)上一个终端: 回到第一个终端( Mac电脑: 按 Control+C ;Windows电脑: 按 Ctrl +C ),结束 vLLM 服务
二、常见问题排查
- vllm serve 启动很慢怎么办?
第一次启动需要加载模型和编译内核,等待几分钟是正常现象。只要日志还在输出,通常不需要中断。
2.提示显存不足怎么办?
可以降低最大上下文长度后再启动:
vllm serve ./models/google/gemma-4-E4B-it/ --served-model-name gemma-4-E4B-it --max-model-len 8192
如果仍然显存不足,可以继续降低到 4096 。
- modelscope download 命令找不到怎么办?
先确认 ModelScope 是否安装成功:
pip show modelscope
如果没有安装成功,重新执行:
pip install -U modelscope
也可以直接使用本文提供的 Python 下载命令。
4.聊天命令连接失败怎么办?
先确认第一个终端中的 vLLM 服务仍在运行,并且已经出现 Application startup complete. 。如果服务没有启动完成,等待启动完成后再运行 vllm chat 。
【科普卡片】一文读懂大模型核心概念
- 大模型是什么?
先说它和普通软件的区别,这是理解一切的起点。
普通软件,是程序员把规则一条一条写死的。比如一个计算器,程序员写明"看到加号就做加法",它才会做加法。程序员没想到的情况,它就不会处理。
大模型不一样:没有人给它写规则。它是从海量文字里,自己总结出语言规律的。
那它具体在做什么?它的核心工作其实只有一件事:
看着前面的文字,预测下一个词最可能是什么。
听起来太简单了,但请先记住这件事,因为它就是大模型的全部底层逻辑。展开来看,模型每生成一个词,内部都走了这么五步:
一个词一个词地往下接,接成句子、接成段落,就是我们看到的"会聊天、会写作"的样子。
为什么这样就显得聪明? 因为要把"下一个词"猜得准,模型在学习时必须暗暗掌握很多东西:语法、常识、事实、甚至简单的推理。举例:要正确续写"中国的首都是____",它就必须"知道"答案是北京。它不是被人手把手教的,而是在海量文字里反复见到这个搭配,自己总结出来的规律。
- Gemma 4 是什么?
Gemma 4 是 Google(旗下 DeepMind 团队)在 2026 年推出的一个 开源大模型家族 。它和 Google 那款闭源、收费的 Gemini 3 用的是同一套底层技术,所以你可以把它看成 Gemini 3 的"开源师弟"——区别在于,Gemma 把模型权重公开放了出来,而且用的是商业友好的 Apache 2.0 许可 ,意味着 不光能免费下载,还能免费商用 。
"开源"这一点对本次教程特别关键 :任何人都能免费下载模型文件、装到自己环境里运行、甚至拿自己的数据去改造它 (也就是任务四要做的微调)。而闭源模型(比如 GPT、Gemini),你只能隔着网络调用,看不到也改不动里面的东西。顺带一提,Gemma 系列至今 已被下载超过 4 亿次、衍生出 10 万多个模型 , 是开源圈里用得最广的家族之一 。
Gemma 4 有好几种大小,从能塞进手机、树莓派的,到要用服务器才跑得动的都有,一共四款:E2B、E4B、26B 和 31B。本次教程用的是其中较小的 E4B :体积小到 单张显卡就能跑,又足够聪明,正好适合上手学习 。(型号里的"E"是"有效参数"的意思,E4B 大致是 40 亿参数这个量级。)
别看个头小,Gemma 4 这一代主打的就是" 单位参数下的高智能 "——按 Google 官方说法,它家最大的 31B 模型在权威的开放模型排行榜上能排进全球前三,甚至打赢比它大 20 倍的对手。能力上,它会做多步推理、能写代码、能看图、能听音频、一次能读进很长的内容,还支持 140 多种语言。
本次教程为什么选它? 开源 (能下能改、还能免费商用)、 够小 (单卡跑得动)、 够强 。
更多信息详见谷歌官方对Gemma 4 的介绍: https://mp.weixin.qq.com/s/9ocQ4g2v8zmKuIMcle3sDA
- 顺便搞懂几个高频词!
这几个词在任务三里会反复出现,搞懂了,后面就不犯迷糊。
1️⃣ 参数 / 权重 / “多少 B”
参数(Parameter) :模型内部的数字,就像模型的大脑神经元的“记忆”。每个参数都是一个固定的数,模型就是靠这些数进行运算,算出答案。
权重(Weight) :参数的另一种叫法,完全等价。
“多少 B” :B = 10 亿。模型名字里的 4B、15B,就是模型里参数的数量。例如,4B 模型有 40 亿个参数。
模型文件 :你下载的 model.safetensors 文件里存的就是这些参数。文件大(比如 15G)是正常的,因为存储结构和精度决定了文件大小。
💡一句话理解: 参数 = 模型的“本体”,模型会不会聊天、聪不聪明,全在这堆数字里。
2️⃣ 推理(Inference)与部署(Deploy)
推理 :用训练好的模型做实际工作(跟模型对话、生成内容)。
部署 :把模型放到服务器上,让别人可以访问、请求模型生成结果。
关系 :
训练 = 教模型
推理 = 用模型干活部署 = 把模型放到服务器上,别人也能用
3️⃣ 魔搭 ModelScope
一个国内的开源模型社区,相当于"国内的模型下载站"。 用它可以下载模型,速度快、稳定,不容易卡。任务三第二步,你就是用它把 Gemma 4 下载下来的。因为它的服务器在国内,下载又快又稳、不容易卡——这也是教程让你先把下载源切到国内镜像的原因。
4️⃣ vLLM
刚下载的模型文件,只是一堆"静止"的参数,没法直接聊天 。vLLM 就是负责把模型"装载起来、发动跑起来"的推理框架 ,而且它优化过运算流程, 同一个模型用它跑会更快 。
📌总结一句话:
模型 = 一堆参数(权重)
推理 = 模型开始用参数算东西
部署 = 模型可以被别人访问
ModelScope = 国内模型下载渠道
vLLM = 推理框架,让模型跑得快
- 读懂本节任务:这一连串操作到底在干嘛
本节任务命令看着多,其实是一条很清晰的链路。一句话概括目标: 把一个"挂在网上的模型文件",变成"一个能跟你对话的服务" 。理解了这条链路,你敲命令时就不是在盲抄,而是知道每一步在干嘛。
第一步,先检查显卡能不能用。 为什么放最前面?因为后面下载、运行、对话全靠显卡。先花几秒确认地基没问题,免得忙活半天才发现显卡用不了——相当于开工前先看看工具齐不齐。
第二步,把模型下载到本地。 模型得先待在你这台服务器上,才能被运行。先切换国内镜像、用魔搭来下载,都是为了又快又稳;下完确认那个 15G 的权重文件在,"原料"就到位了。
第三步,用 vLLM 把模型启动成一个服务。 有了模型文件(原料),还需要一个引擎(vLLM)把它点着:它会把模型加载进显存,然后开一个"窗口"停在那儿等人提问。注意启动后这个终端会被一直占住——因为服务得持续运行,不能关。
第四步,另开一个终端连上去对话。 这里藏着一个很真实的概念:大模型实际运行时,往往是" 服务端 + 客户端 "的模式。第三步启动的是服务端(像后厨,一直运转);你要跟它说话,得另开一个终端当客户端(像前台,负责传话)。所以让你"开新终端"不是麻烦,这套结构本来就这么设计的——你以后调用大模型 API,本质也是这个样子。
对话测试通过,本次学习任务就达成了:你已经独立把一个开源大模型部署起来、并验证它能正常工作。最后让你关掉服务,是因为下一步微调要用显存,得先把这个"后厨"腾出来。

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)