
Ollama:一行命令,本地跑起大模型
Ollama:一行命令,本地跑起大模型
ollama 在 GitHub 上已经拿到 171K Star 了。
把 Llama、Gemma、Mistral 这些开源模型跑在本机上,以前要折腾驱动、编译 llama.cpp、调 CUDA 环境。Ollama 把这个过程压缩成了一行命令。
1、这是干嘛的
把大模型装进个人电脑。
Ollama 把 llama.cpp 的推理能力包了一层壳,用命令行就能下载模型、启动服务、调用 API。背后是 C++ 推理引擎,面前是 ollama run gemma3 这样一句话。不用配环境变量,不用管 GPU 驱动版本,装好就能跑。
支持的模型列表在官网的 library 页面,从 Gemma 到 Llama 4,全在一个 ollama pull 里。
2、为什么要用它
本地跑模型的三个核心问题,Ollama 给了直接答案。
第一个是环境。新手想跑一个本地模型,装 CUDA、配 cuDNN、挑对 Python 版本就能卡半天。Ollama 把推理环境整体打包,安装一行命令,macOS、Windows、Linux 全平台覆盖。
第二个是模型管理。ollama list 看本机有哪些模型,ollama pull 拉新模型,ollama rm 删掉不用的。不占多余磁盘空间,不残留配置。
第三个是开发生态接入。Ollama 在 11434 端口暴露了 REST API,格式跟 OpenAI 的 Chat Completions 对齐。已有代码换个 base_url 就能切到本地模型,Python 和 JavaScript 都有官方 SDK。
除了这三个点,还有一个很多人关心的好处:数据完全不离开本机。所有推理在本地跑,模型文件、对话记录、API 请求都不经过任何外部服务器。对于处理内部文档、客户数据、医疗记录这类场景,这一点比性能指标更重要。
实用功能方面,Ollama 可以直接接入 Claude Code 和 GitHub Copilot 这些 AI 编程工具。ollama launch claude,一条命令把本地模型接进编程工作流。
3、怎么用
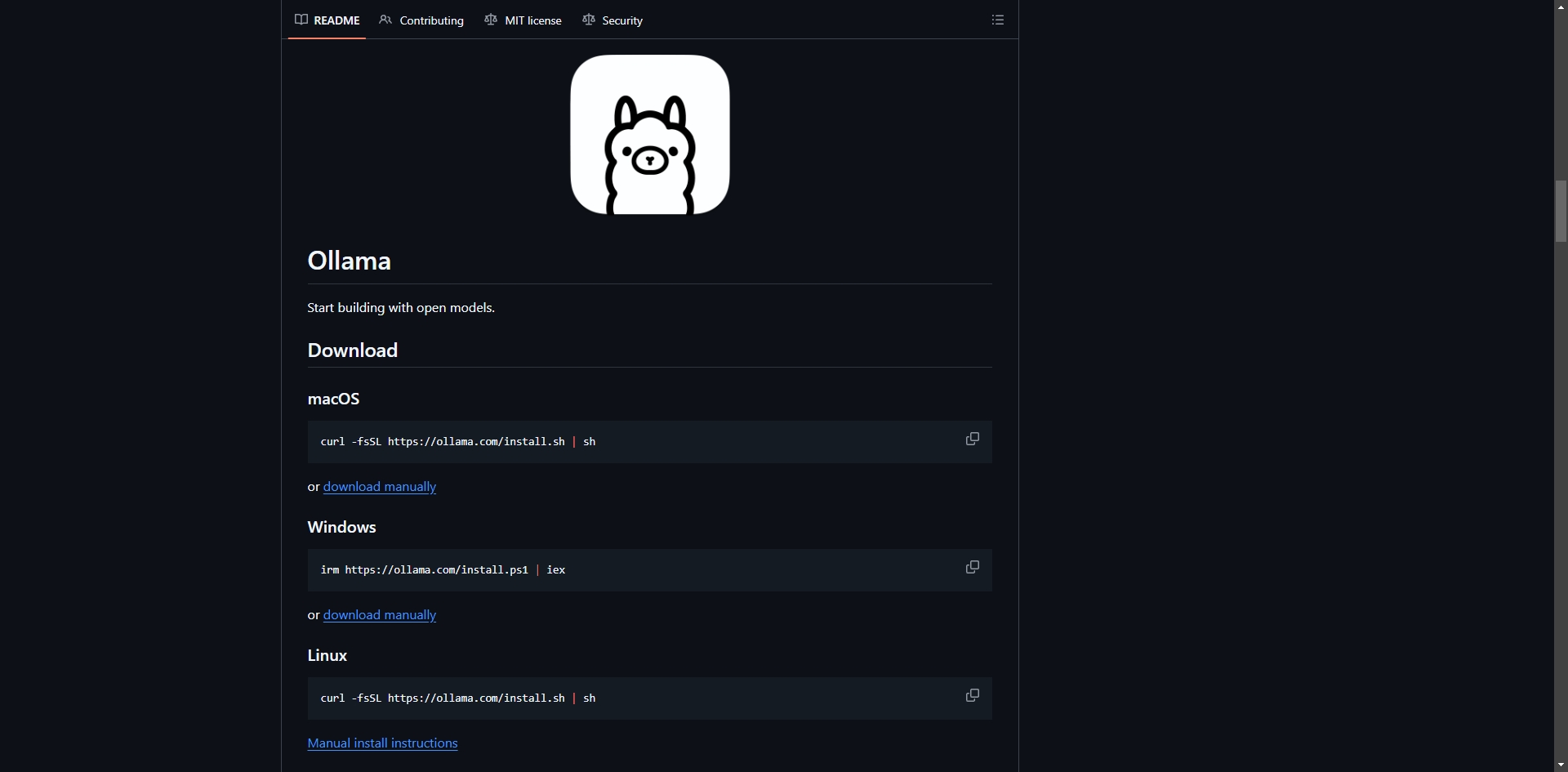
安装就是一条命令。
macOS 和 Linux:
curl -fsSL https://ollama.com/install.sh | sh
Windows:
irm https://ollama.com/install.ps1 | iex
也有 Docker 镜像,docker pull ollama/ollama 然后 docker run。
装完直接跑模型:
ollama run gemma3
进入对话模式。用 API 调也是一行:
curl http://localhost:11434/api/chat -d '{
"model": "gemma3",
"messages": [{"role": "user", "content": "Why is the sky blue?"}],
"stream": false
}'
Python SDK 同样简洁:
from ollama import chat
response = chat(model='gemma3', messages=[
{'role': 'user', 'content': 'Why is the sky blue?'},
])
print(response.message.content)
4、周边生态
Ollama 周边已经长出一整片产品矩阵。
Chat 界面上,Open WebUI 是自建 ChatGPT 风格界面的常见选择,Lobe Chat、LibreChat 也接了 Ollama。桌面端有 Cherry Studio、AnythingLLM、Msty。移动端 SwiftChat 跨 iOS 和 Android。
代码编辑器方面,VS Code 的 Continue 和 Cline 插件都支持接 Ollama,Void 是一个用本地模型驱动的代码编辑器,obsidian-copilot 让笔记软件用上本地 AI。
RAG 和知识库工具里,RAGFlow、MaxKB、R2R 都内置了 Ollama 支持。
终端工具中,aichat 是全能 LLM CLI,tlm 做本地 shell copilot。
各语言 SDK 基本齐了:Python、JavaScript、Java、Go、Rust、.NET、Swift、Ruby、PHP、Dart、C++、R、Julia、Elixir,LangChain 和 LlamaIndex 的官方集成也在列。对框架开发者来说,这意味着不用担心自己的技术栈接不进去。
除了工具链,Ollama 在部署上也覆盖了主流途径:Google Cloud 有 GPU 部署教程,Fly.io 和 Koyeb 支持一键部署,Docker、Helm Chart、Homebrew、Pacman、Nix 各平台包管理都能装。
5、适合哪些人
- 想在自己电脑上跑大模型、不依赖云 API 的开发者
- 做 RAG 应用、需要本地 embedding 和推理的团队
- 对数据隐私有硬要求、不能把文档送出公司网络的场景
- 用 Claude Code 或 Copilot 但想切到本地模型降低成本的人
- 学大模型原理、需要一个干净环境跑实验的学生
Ollama 把本地大模型的使用门槛压到了一行命令,这一点比 171K Star 更能说明问题。
或 Copilot 但想切到本地模型降低成本的人
- 学大模型原理、需要一个干净环境跑实验的学生
Ollama 把本地大模型的使用门槛压到了一行命令,这一点比 171K Star 更能说明问题。

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)