
大模型推理引擎vLLM(22):以all2all_backend为例梳理命令行参数注册、解析、传递链路代码
大模型推理引擎vLLM(22):以all2all_backend为例梳理命令行参数注册、解析、传递链路代码
目录
2.3 from_cli_args:从args中获取相应的参数
2.4 create_engine_config:赋值给ParallelConfig和VllmConfig
3.1 vllm018/vllm/entrypoints/cli/main.py
3.2 vllm018/vllm/entrypoints/cli/serve.py
3.3 vllm018/vllm/entrypoints/openai/api_server.py
abstract
CLI Command Line Interface
@dataclass 自动生成初始化和 __repr__函数,若定义了__post_init__,自动调用__post_init__函数,
repr(representation)就是用字符串表示对象的类名和成员
literal 字面量
CLI 值先进 EngineArgs,再写进 ParallelConfig,再装进 VllmConfig
EngineArgs, ParallelConfig, VllmConfig
0 引言
工作中需要将之前用环境变量设置的变量,改为用命令行传输,借此机会,梳理下这个参数的从上到下传递链路。
1 先大体全局搜一下
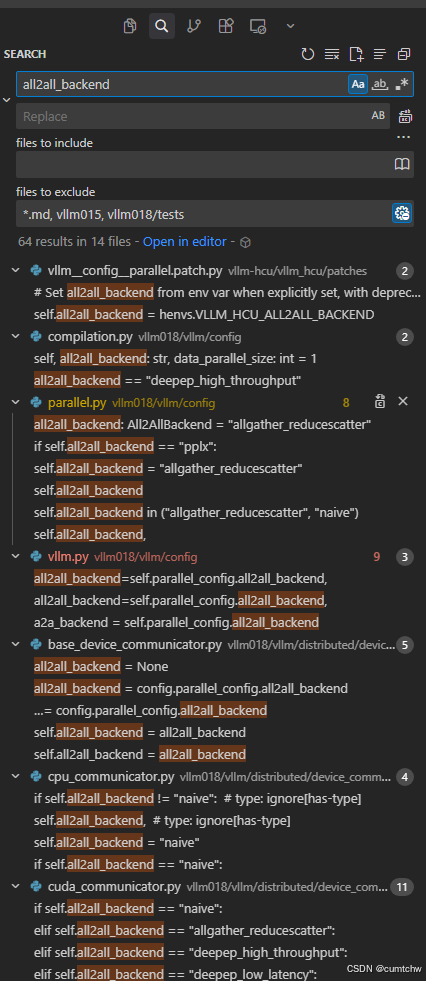
然后先把搜索结果过一遍,基本上 就能有个大概了,
2 arg_utils.py:关键文件,参数的注册、解析
先看一下vllm018/vllm/engine/arg_utils.py的代码,
2.1 all2all_backend成员变量声明
有个类
@dataclass
class EngineArgs:然后是,大约420行
moe_backend: MoEBackend = KernelConfig.moe_backend
all2all_backend: All2AllBackend = ParallelConfig.all2all_backend
enable_elastic_ep: bool = ParallelConfig.enable_elastic_ep
enable_dbo: bool = ParallelConfig.enable_dbo这里是声明 class EngineArgs:中有这个成员,并且这个成员只能用下面的这几个值
All2AllBackend = Literal[
"naive",
"pplx",
"deepep_high_throughput",
"deepep_low_latency",
"mori",
"nixl_ep",
"allgather_reducescatter",
"flashinfer_all2allv", # temporary alias for flashinfer_nvlink_two_sided
"flashinfer_nvlink_two_sided",
"flashinfer_nvlink_one_sided",
]然后他的默认值是ParallelConfig.all2all_backend
2.2 注册
parallel_group.add_argument(
"--all2all-backend", **parallel_kwargs["all2all_backend"]
)还是在class EngineArgs:这个类里面,有这两行注册代码,大约910行。
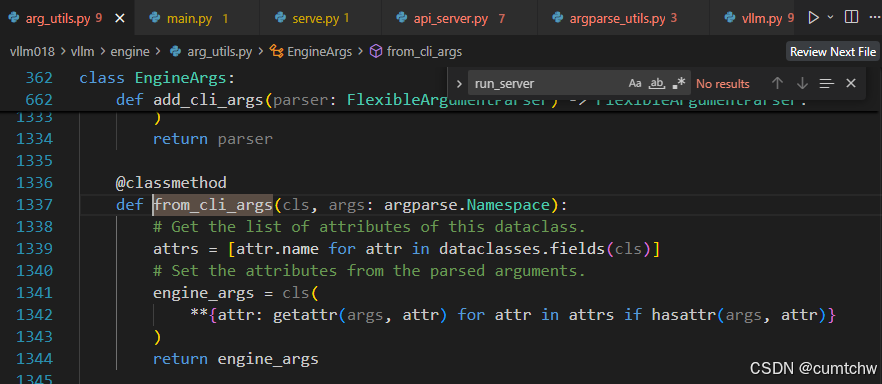
2.3 from_cli_args:从args中获取相应的参数
@classmethod
def from_cli_args(cls, args: argparse.Namespace):
# Get the list of attributes of this dataclass.
attrs = [attr.name for attr in dataclasses.fields(cls)]
# Set the attributes from the parsed arguments.
engine_args = cls(
**{attr: getattr(args, attr) for attr in attrs if hasattr(args, attr)}
)
return engine_args还是在class EngineArgs:中有这个函数,这个函数就是从命令行的参数中获取这个类中有的那些参数。大约1337行。
2.4 create_engine_config:赋值给ParallelConfig和VllmConfig
还是在vllm018/vllm/engine/arg_utils.py文件的class EngineArgs:类里面
def create_engine_config(
self,
usage_context: UsageContext | None = None,
headless: bool = False,
) -> VllmConfig:
...其它代码...
parallel_config = ParallelConfig(
pipeline_parallel_size=self.pipeline_parallel_size,
tensor_parallel_size=self.tensor_parallel_size,
prefill_context_parallel_size=self.prefill_context_parallel_size,
data_parallel_size=self.data_parallel_size,
data_parallel_rank=self.data_parallel_rank or 0,
data_parallel_external_lb=data_parallel_external_lb,
data_parallel_size_local=data_parallel_size_local,
master_addr=self.master_addr,
master_port=self.master_port,
nnodes=self.nnodes,
node_rank=self.node_rank,
distributed_timeout_seconds=self.distributed_timeout_seconds,
data_parallel_master_ip=data_parallel_address,
data_parallel_rpc_port=data_parallel_rpc_port,
data_parallel_backend=self.data_parallel_backend,
data_parallel_hybrid_lb=self.data_parallel_hybrid_lb,
is_moe_model=model_config.is_moe,
enable_expert_parallel=self.enable_expert_parallel,
enable_ep_weight_filter=self.enable_ep_weight_filter,
all2all_backend=self.all2all_backend,
...其他代码...这里相当于是将解析出来的参数,赋值给了ParallelConfig。
同样还是在create_engine_config函数里面,还有
config = VllmConfig(
model_config=model_config,
cache_config=cache_config,
parallel_config=parallel_config,
scheduler_config=scheduler_config,
device_config=device_config,
load_config=load_config,
offload_config=offload_config,
attention_config=attention_config,
kernel_config=kernel_config,
lora_config=lora_config,
speculative_config=speculative_config,
structured_outputs_config=self.structured_outputs_config,
observability_config=observability_config,
compilation_config=compilation_config,
kv_transfer_config=self.kv_transfer_config,
kv_events_config=self.kv_events_config,
ec_transfer_config=self.ec_transfer_config,
profiler_config=self.profiler_config,
additional_config=self.additional_config,
optimization_level=self.optimization_level,
performance_mode=self.performance_mode,
weight_transfer_config=self.weight_transfer_config,
shutdown_timeout=self.shutdown_timeout,
)这里 也就是又把参数赋值给了VllmConfig,那么也就是
CLI 值先进 EngineArgs,再写进 ParallelConfig,再装进 VllmConfig
3 怎么从main.py一层层下来的
3.1 vllm018/vllm/entrypoints/cli/main.py
parser = FlexibleArgumentParser(
description="vLLM CLI",
epilog=VLLM_SUBCMD_PARSER_EPILOG.format(subcmd="[subcommand]"),
)
parser.add_argument(
"-v",
"--version",
action="version",
version=importlib.metadata.version("vllm"),
)
subparsers = parser.add_subparsers(required=False, dest="subparser")
cmds = {}
for cmd_module in CMD_MODULES:
new_cmds = cmd_module.cmd_init()
for cmd in new_cmds:
cmd.subparser_init(subparsers).set_defaults(dispatch_function=cmd.cmd)
cmds[cmd.name] = cmd
args = parser.parse_args()
if args.subparser in cmds:
cmds[args.subparser].validate(args)
if hasattr(args, "dispatch_function"):
args.dispatch_function(args)
else:
parser.print_help()
if __name__ == "__main__":
main()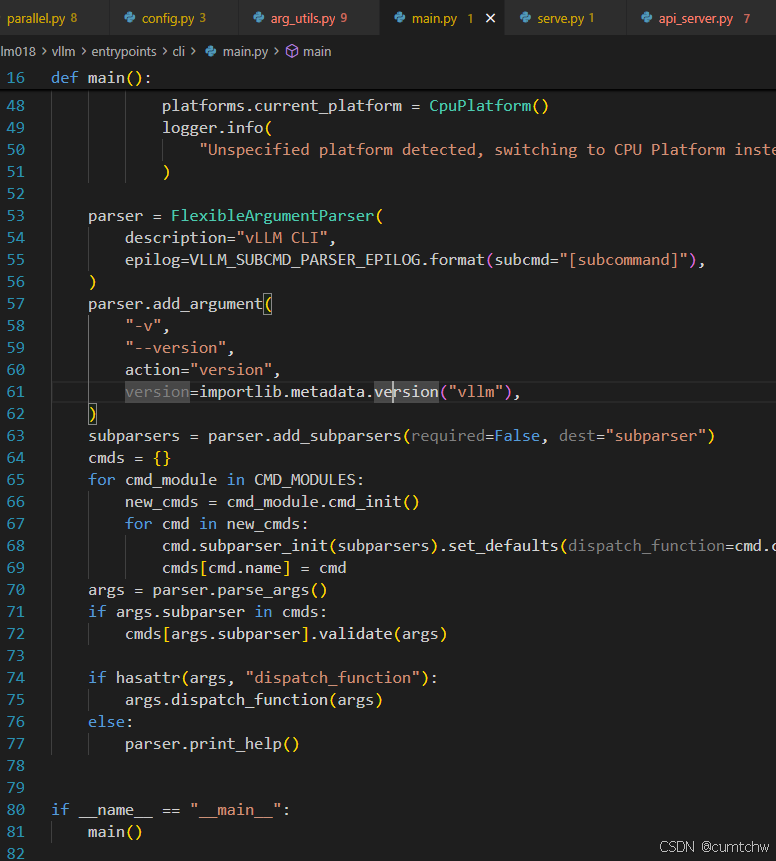
这里有个args = parser.parse_args(),就相当于是解析了命令行参数。
然后有个 args.dispatch_function(args),这就是去了相应的function,这里
dispatch_function 是在注册子命令时绑定的。main.py 68 行:
cmd.subparser_init(subparsers).set_defaults(dispatch_function=cmd.cmd)
执行的是 vllm serve ... 时,args.subparser == "serve",
所以:args.dispatch_function == ServeSubcommand.cmd
也就是 serve.py 里的 cmd 函数。
那么就去了serve.py
3.2 vllm018/vllm/entrypoints/cli/serve.py
在这个文件
class ServeSubcommand(CLISubcommand):
"""The `serve` subcommand for the vLLM CLI."""
name = "serve"
@staticmethod
def cmd(args: argparse.Namespace) -> None:这里往下
if args.api_server_count < 1:
run_headless(args)
elif args.api_server_count > 1:
run_multi_api_server(args)
else:
# Single API server (this process).
args.api_server_count = None
uvloop.run(run_server(args))然后就去了vllm018/vllm/entrypoints/openai/api_server.py里面的run_server
3.3 vllm018/vllm/entrypoints/openai/api_server.py
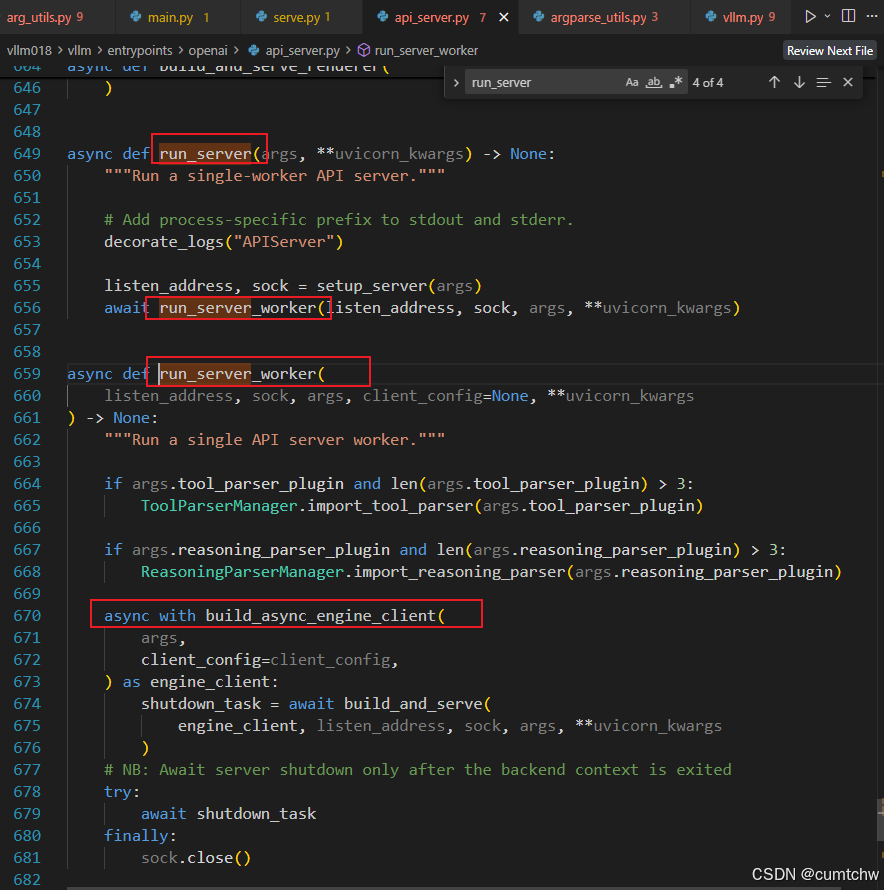
这里去了670行的这个函数,那么
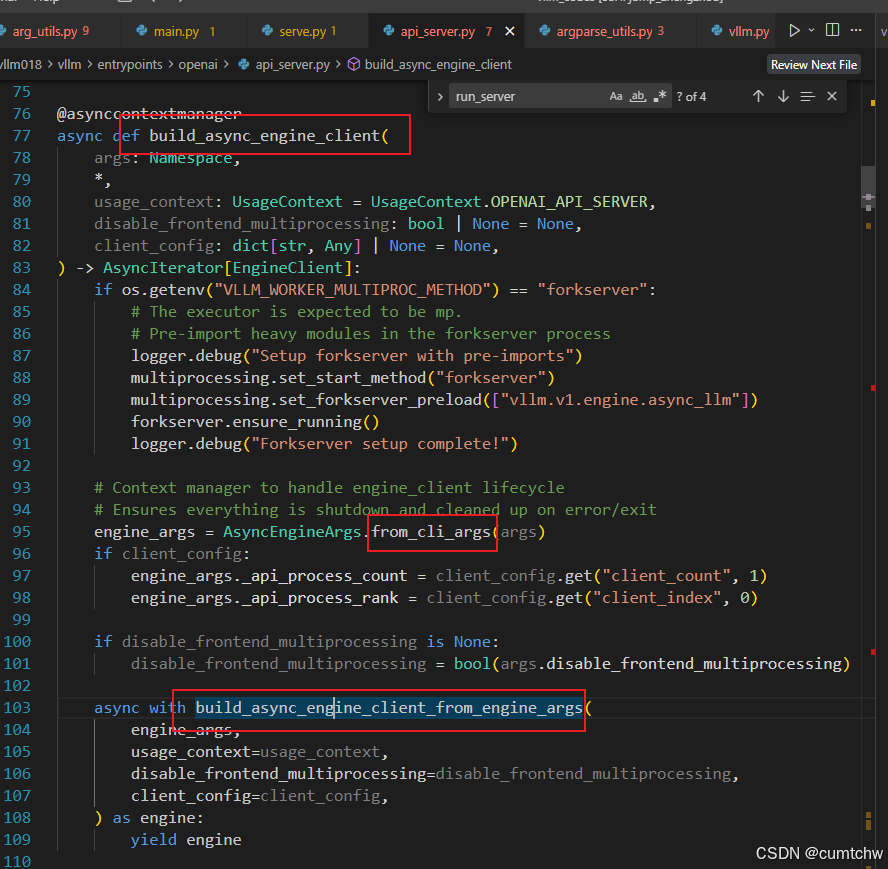
然后就到了前面分析的vllm018/vllm/engine/arg_utils.py里面的**from_cli_args**函数和**create_engine_config**函数了。也即是获取参数,以及构造了vllmconfig,
4 函数调用汇总
vllm serve(命令行)
│
├─ vllm018/vllm/entrypoints/cli/main.py:53
│ parser = FlexibleArgumentParser(...)
│
├─ vllm018/vllm/entrypoints/cli/main.py:68
│ cmd.subparser_init(subparsers).set_defaults(dispatch_function=cmd.cmd)
│ (vllm serve 时 → dispatch_function = ServeSubcommand.cmd)
│
├─ vllm018/vllm/entrypoints/cli/main.py:70
│ args = parser.parse_args()
│ └─ 得到 args(含 args.all2all_backend 等)
│ (内部:utils/argparse_utils.py:179 FlexibleArgumentParser.parse_args
│ → :360 super().parse_args())
│
├─ vllm018/vllm/entrypoints/cli/main.py:72
│ cmds[args.subparser].validate(args)
│ └─ serve 时 → entrypoints/cli/serve.py:120 validate_parsed_serve_args
│
└─ vllm018/vllm/entrypoints/cli/main.py:75
args.dispatch_function(args)
│
└─ vllm018/vllm/entrypoints/cli/serve.py:48
ServeSubcommand.cmd(args)
│
└─ vllm018/vllm/entrypoints/cli/serve.py:118 【单 API 常见分支】
uvloop.run(run_server(args))
│
└─ vllm018/vllm/entrypoints/openai/api_server.py:649
async def run_server(args, **uvicorn_kwargs)
│
└─ vllm018/vllm/entrypoints/openai/api_server.py:656
await run_server_worker(listen_address, sock, args, ...)
│
└─ vllm018/vllm/entrypoints/openai/api_server.py:659
async def run_server_worker(...)
│
└─ vllm018/vllm/entrypoints/openai/api_server.py:670
async with build_async_engine_client(args, ...)
│
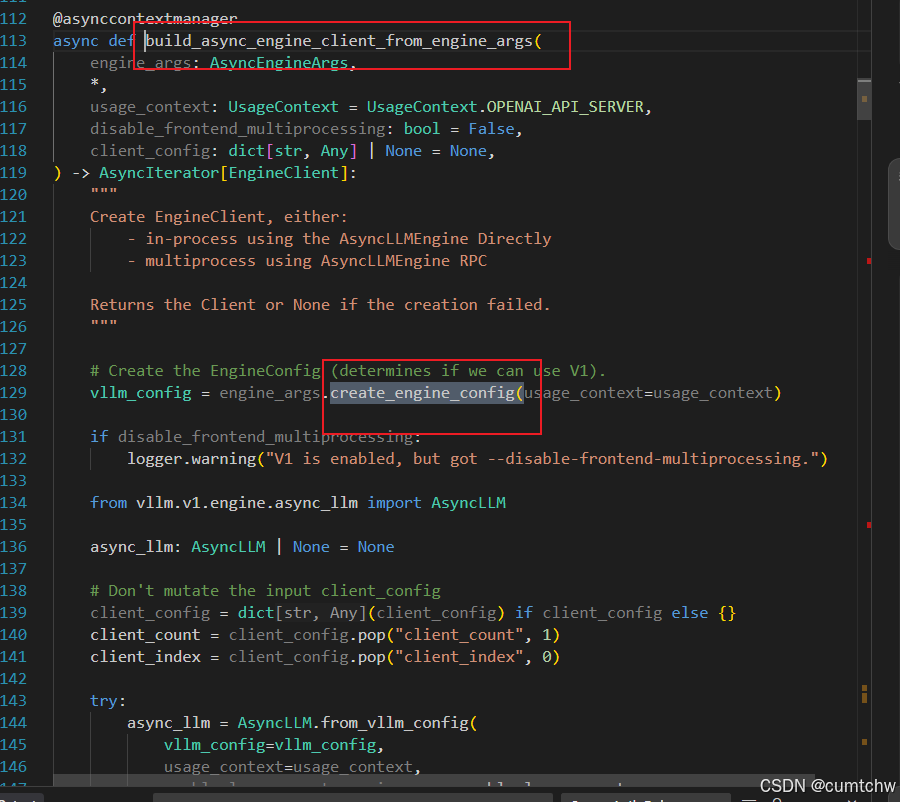
└─ vllm018/vllm/entrypoints/openai/api_server.py:77
async def build_async_engine_client(args, ...)
│
├─ vllm018/vllm/entrypoints/openai/api_server.py:95
│ engine_args = AsyncEngineArgs.from_cli_args(args)
│ │
│ └─ vllm018/vllm/engine/arg_utils.py:1337
│ def from_cli_args(cls, args) # 1337–1344
│ └─ 得到 EngineArgs(含 all2all_backend)
│
└─ vllm018/vllm/entrypoints/openai/api_server.py:103
async with build_async_engine_client_from_engine_args(engine_args, ...)
│
└─ vllm018/vllm/entrypoints/openai/api_server.py:113
async def build_async_engine_client_from_engine_args(engine_args, ...)
│
└─ vllm018/vllm/entrypoints/openai/api_server.py:129
vllm_config = engine_args.create_engine_config(...)
│
└─ vllm018/vllm/engine/arg_utils.py:1476
def create_engine_config(self, ...) -> VllmConfig
│
├─ vllm018/vllm/engine/arg_utils.py:1716
│ parallel_config = ParallelConfig(
│ ...,
│ all2all_backend=self.all2all_backend, # 约 1736
│ ...
│ )
│ └─ vllm018/vllm/config/parallel.py:161 字段定义
│ └─ __post_init__ 校验(HCU patch 可能 env 覆盖)
│
└─ vllm018/vllm/engine/arg_utils.py:1923
config = VllmConfig(
...,
parallel_config=parallel_config,
...
)
└─ 总配置 VllmConfig 就绪5 参考文献
VLLM开源代码:https://github.com/vllm-project/vllm

免费领 100 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐

 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)