
SGLang HiCache KV Cache offload
Ref
https://docs.sglang.io/advanced_features/hicache_design.html
https://docs.sglang.io/advanced_features/hicache_best_practices.html
https://lmsys.org/blog/2025-09-10-sglang-hicache/
SGLang Development Roadmap (2025 H2)
Mooncake (6): Mooncake+SGLang HiCache 通过全局 KVCache 缓存共享降低 84% 的 TTFT
论文:
Strata: Hierarchical Context Caching for Long Context Language Model Serving
Note: 当前理解并不太透彻,本文后续将继续更新。
HiRadixCache与LMCache对比
LMCache相对于引擎更加独立,可以集成到VLLM,也可以集成到SGLang,当前都已经实现了两个引擎的集成。但SGLang HiRadixCache是SGLang内部模块,只能SGLang使用。LMCache架构比较简单清晰,HiRadixCache相对来说没有什么介绍文档,理解难度相对比较高。
LMCache的存储层级:GPU引擎自己管理,LMCache不负责。LMCache包括CPU,Disk,Remote三个层级。即使VLLM/SGLang关闭自身GPU prefix cache仍然可以使用LMCache多级存储。每个存储层级是独立管理各自的存储。SGLang的HiRadixCache使用一个统一Radix Tree管理GPU/CPU (Disk/3FS的存储由backend自己管理)。
LMCache比HiRadixCache多了一个Remote存储层级,在Remote层级可以支持3fs/mooncake之类的,与Local disk可以同时使用。实际上LMCache可以加任意多层级,因为是按照存储层级list进行依次读写。但是HiRadixCache固定3层,前两层固定GPU和CPU,L3只能[本地磁盘,3FS,mooncake,nixl]选择一个,灵活性相对较差。
LMCache写入CPU/Disk/Remote不同后端是每个后端同时写入。load的时候按存储层级依次查找。
每个存储层级独立管理各自的存储逻辑,可以独立实现基于hashmap或者radix tree的管理。
LMCache是按chunk(类似于page size,默认为256个token),按一个chunk为单位进行存储,独立于引擎的page size。HiRadixCache按照page size存储,但是L3看上去是chunk size 128。
LMCache支持所有layer合并存储,或者layerwise存储。HiRadixCache当前看上去主要是layerwise存储。
LMCache的mem_obj ref_count需要手动管理,必须特别小心,很容易出bug。ref count多加了导致不能被驱逐和释放,减多了导致在cpu内部存储的被错误释放。这个我认为是LMCache设计比较失败的地方。
从Load和Store的额外overhead来说,LMCache的load是需要同步等待的。Store实现了异步,但是GPU-CPU拷贝仍然是同步的,只是写入Disk是异步。这一点HiRadixCache的异步操作可能实现的更好一些从而避免kv cache load/store带来的额外overhead。
Prefetch和L3后端写入策略更加丰富,而LMCache只支持同时写入。
Prefetch策略:"best_effort", "wait_complete", "timeout"
L3写入策略:"write_back", "write_through", "write_through_selective"
HiRadixCache简介
sglang实现的一个多级KV cache offload系统,类似于VLLM社区开发的LMCache。
要理解HiRadixCache,可以先理解RadixCache,然后从HiRadixCache提供的相同接口的操作区别出发。
启动参数设置
--enable-hierarchical-cache
help="Enable hierarchical cache",
--hicache-ratio
help="The ratio of the size of host KV cache memory pool to the size of device pool.",
注意是CPU与GPU存储的比例。
--hicache-size
help="The size of host KV cache memory pool in gigabytes, which will override the hicache_ratio if set.",
CPU存储的大小。
--hicache-write-policy
choices=["write_back", "write_through", "write_through_selective"],
help="The write policy of hierarchical cache.",
SGLang HiCache also supports multiple cache write policies for moving data from faster to slower tiers. A write-through policy provides the strongest caching benefits if bandwidth permits, while a write-through-selective mode leverages hit-count tracking to back up only hot spots, reducing I/O load. In cases where even the slower memory tiers become capacity-constrained, a write-back policy can effectively mitigate the pressure.
这几种写入策略的区别:
write_back
write_through
write_through_selective
It seems likely that the main difference among HiRadixCache's hicache-write-policy options is how and when KV cache data is written from device (GPU) memory to host (CPU) memory or storage. My understanding is as follows:
write_through: Data is written to the host cache immediately after being updated in device memory, ensuring host and device caches are always synchronized. This is the default and most commonly used policy.write_back: Data is written to the host cache only when it is evicted from device memory, which can reduce I/O but risks data loss if the device fails before eviction. This policy is less validated and may lead to performance issues due to slow I/O on the critical path.write_through_selective: Not explicitly documented, but likely a hybrid where only selected data (e.g., based on access patterns or thresholds) is written through to the host cache.
--hicache-io-backend
choices=["direct", "kernel"],
help="The IO backend for KV cache transfer between CPU and GPU",
The key bottleneck in hierarchical memory systems is the latency of moving data from slower to faster tiers. Beyond the standard cudaMemcpyAsync, we developed a set of GPU-assisted I/O kernels that deliver up to 3× higher throughput for CPU–GPU transfers.
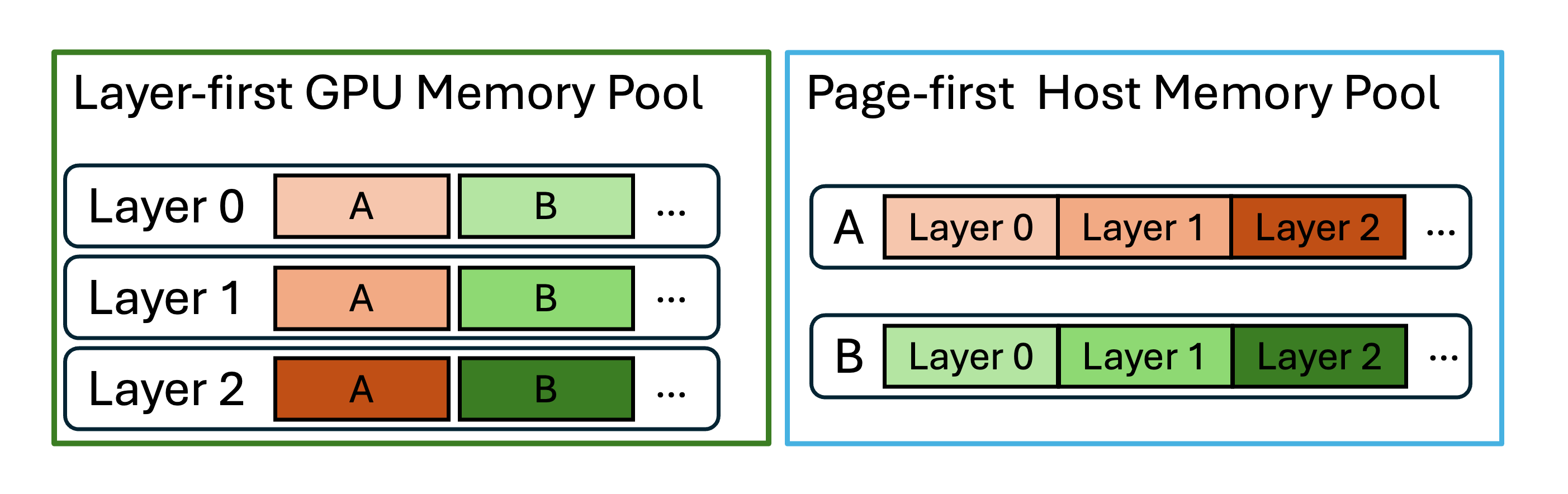
--hicache-mem-layout
choices=["layer_first", "page_first", "page_first_direct"],
help="The layout of host memory pool for hierarchical cache.",
To further accelerate data movement between CPU memory and storage layers, enabled by the implemented kernels, we decoupled the host memory pool’s layout from the GPU layout as illustrated in Figure 1. While the GPU memory pool remains unchanged as a “layer-first” style for compatibility with computation kernels, HiCache uses a “page-first” layout for other layers to prioritize IO efficiency. This enables larger transfer sizes per transaction, and when combined with a zero-copy mechanism, achieves up to 2× higher throughput in typical deployments. You can refer to the PRs (Mooncake, 3FS) for more details.
不同layout的实际实现
class MHATokenToKVPoolHost(HostKVCache):
def init_kv_buffer(self):
if self.layout == "layer_first":
dims = (2, self.layer_num, self.size, self.head_num, self.head_dim)
elif self.layout == "page_first":
dims = (2, self.size, self.layer_num, self.head_num, self.head_dim)
self.token_stride_size = self.head_num * self.head_dim * self.dtype.itemsize
self.layout_dim = self.token_stride_size * self.layer_num
return torch.empty( dims, dtype=self.dtype, device=self.device, pin_memory=self.pin_memory)
class MLATokenToKVPoolHost(HostKVCache):
def init_kv_buffer(self):
if self.layout == "layer_first":
dims = (self.layer_num, self.size, 1, self.kv_lora_rank + self.qk_rope_head_dim)
elif self.layout == "page_first":
dims = (self.size, self.layer_num, 1, self.kv_lora_rank + self.qk_rope_head_dim)
self.token_stride_size = (self.kv_lora_rank + self.qk_rope_head_dim) * self.dtype.itemsize
self.layout_dim = self.token_stride_size * self.layer_num
return torch.empty(dims, dtype=self.dtype, device=self.device, pin_memory=self.pin_memory)
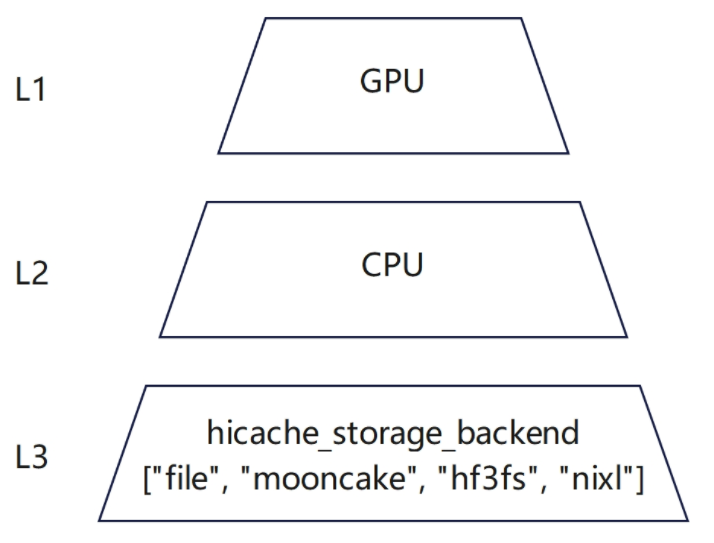
--hicache-storage-backend
choices=["file", "mooncake", "hf3fs", "nixl"],
help="The storage backend for hierarchical KV cache.",
--hicache-storage-prefetch-policy
choices=["best_effort", "wait_complete", "timeout"],
help="Control when prefetching from the storage backend should stop.",
--hicache-storage-backend-extra-config
help="A dictionary in JSON string format containing extra configuration for the storage backend.",
另外还有个--enable-lmcache: "Using LMCache as an alternative hierarchical cache solution"
参考:https://github.com/sgl-project/sglang/pull/9741
这个是使用lmcache进行kv cache offload,是一套独立于hicache的方案。目前只支持MHA/GQA还没有加入MLA支持(当然这个并不复杂)。另外需要注意matched token需要在dp atten group内进行reduce min,否则可能导致跑着不同tp worker match数量不同导致卡死现象。
关键特性
backend插件
The best part of SGLang HiCache is how simple it is to plug in a new storage backend. Thanks to our clean, generic interfaces, integration requires implementing only three functionalities in your backend: get(key), exist(key), set(key, value). Everything else, including heavy-lifting tasks such as scheduling and synchronization coordination, is handled by the central cache controller.
This design has already enabled us to integrate three performant backends—Mooncake, 3FS, and NIXL—with more on the way.
这个设计使得backend不方便支持radix tree的管理而是要进行map的管理。
像file system的kv cache管理也可以内部做成radix tree的方式,存储的时候,需要提供key的前缀。
HiRadixCache
创建对象
# sglang\srt\managers\scheduler.py
if self.enable_hierarchical_cache:
self.tree_cache = HiRadixCache(
req_to_token_pool=self.req_to_token_pool,
token_to_kv_pool_allocator=self.token_to_kv_pool_allocator,
tp_cache_group=(
self.attn_tp_cpu_group
if self.server_args.enable_dp_attention
else self.tp_cpu_group
),
page_size=self.page_size,
hicache_ratio=server_args.hicache_ratio,
hicache_size=server_args.hicache_size,
hicache_write_policy=server_args.hicache_write_policy,
hicache_io_backend=server_args.hicache_io_backend,
hicache_mem_layout=server_args.hicache_mem_layout,
enable_metrics=self.enable_metrics,
hicache_storage_backend=server_args.hicache_storage_backend,
hicache_storage_prefetch_policy=server_args.hicache_storage_prefetch_policy,
model_name=server_args.served_model_name,
storage_backend_extra_config=server_args.hicache_storage_backend_extra_config,
)
self.tp_worker.register_hicache_layer_transfer_counter(
self.tree_cache.cache_controller.layer_done_counter
)HiRadixCache继承自RadixCache
RadixCache的几个核心对外功能:
match_prefix,cache_finished_req,cache_unfinished_req,evict
cache_finished_req,cache_unfinished_req复用RadixCache的实现,但是里面调用了HiRadixCache覆盖的函数,例如insert()。
HiRadixCache是用一个radix tree管理GPU和CPU,但是不管理L3的storage backend。通过get/set/exist等方法来操作。
Radix tree node状态
radix tree的节点保存的是同时在GPU和CPU的,而不是每个后端独自管理。
kv cache可能同时存储在GPU和CPU上,或者只在CPU而GPU已经被驱逐。
如果CPU也被驱逐,那么GPU一定已经被驱逐,并且节点将被删除。
Host只包括CPU还是也包括L3的管理?
@property
def evicted(self):
return self.value is None
@property
def backuped(self):
return self.host_value is not None
evicted
不在GPU但是在Host。
backuped
KV cache可能在GPU还没有拷贝到Host,那么这个就为False。否则为True。
但是在Host,有两种可能,在L2 CPU里面,或者在L3的Disk/3FS等里面。这个如何管理?
SGLang Chatbot解释:
In HiRadixCache, node.backuped indicates whether a node's KV cache data has been successfully backed up from device (GPU) memory to host (CPU) memory. If node.backuped is True, the node's data is stored in the host cache and can be evicted from device memory without data loss. This is essential for hierarchical cache management, especially under write_back or write_through policies, to ensure data persistence across memory tiers. See the implementation and usage in hiradix_cache.py.
node.backuped is set to True after the node's value (KV cache) has been copied from device (GPU) memory to host (CPU) memory via the cache controller's write operation. During eviction, if a node is not yet backuped and the write policy is "write_back" or "write_through", HiRadixCache will first call write_backup(node), which triggers the backup process. Once the backup is complete, node.backuped is marked True, allowing the node's device memory to be safely freed.
In the eviction logic, only nodes with backuped=True can be evicted from device memory without data loss. If backuped is False, the node must be backed up first. This ensures hierarchical cache consistency and enables reloading the data from host memory when needed. The backuped flag is thus central to managing memory tiers and safe eviction in HiRadixCache. For details, see the backup and eviction flow in hiradix_cache.py.
match_prefix
与RadixCache的match_prefix基本相同,但是对匹配到的last node做了如下处理:
value, last_node = self._match_prefix_helper(self.root_node, key)
host_hit_length = 0
last_host_node = last_node
while last_node.evicted:
host_hit_length += len(last_node.host_value)
last_node = last_node.parent
while not last_host_node.backuped:
last_host_node = last_host_node.parent
_match_prefix_helper检查了node的evicted状态,返回的value只包括GPU命中的kv cache index。但是last_node节点为CPU最大匹配的节点。
evict
RadixCache的evict逻辑:通过_collect_leaves找到可驱逐叶子节点。从一个叶子节点往root驱逐并且删除lock_ref为0的节点,释放这个节点对应的kv cache index。
HiRadixCache有2个evict:evict和evict_host,分别用于驱逐GPU和Host的存储。对应也有两个找叶子节点的方法:_collect_leaves_device和_collect_leaves,_collect_leaves默认为找host的部分。
evict
驱逐GPU的kv cache存储,使用_collect_leaves_device。
不会删除radix tree节点。
evict_host
驱逐CPU的kv cache存储。
通过_collect_leaves找到叶子节点,然后从一个叶子节点出发让root驱逐GPU已经被驱逐的(node.evicted为True),host_ref_counter=0的节点。不驱逐还在GPU的部分。
调用cache_controller.evict_host:
num_evicted += self.cache_controller.evict_host(x.host_value)
删除父节点到这个节点的连接。
KV cache卸载
write_backup
功能:把GPU kv cache写入到CPU。
执行逻辑
host_indices = self.cache_controller.write(device_indices=node.value,node_id=node.id)
node.host_value = host_indices
self.ongoing_write_through[node.id] = nodecache_controller.write中调用mem_pool_host.backup_from_device_all_layer,实现GPU到CPU拷贝。
调用逻辑
evict -> write_backup
cache_finished_req/cache_unfinished_req -> insert -> _inc_hit_count -> write_backup
_inc_hit_count
在命中次数大于write_through_threshold时调用write_backup。
self.write_through_threshold = 1 if hicache_write_policy == "write_through" else 2
write_backup_storage
功能:从CPU L2写入L3。
执行逻辑
调用cache_controller.write_storage,并存储状态到ongoing_backup。
storage_batch_size默认128,看上去类似LMCache那种按chunk=256存储。
调用逻辑
evict ->writing_check -> write_backup_storage
get_new_batch_prefill-> check_hicache_events ->writing_check -> write_backup_storage
KV cache Load
def get_new_batch_prefill(self) -> Optional[ScheduleBatch]:
if self.enable_hierarchical_cache:
# todo (zhiqiang): disable cuda graph execution if hicache loading triggered
new_batch.hicache_consumer_index = (
self.tree_cache.ready_to_load_host_cache())
new_batch.prepare_for_extend()
check_hicache_events
def check_hicache_events(self):
self.writing_check()
self.loading_check()
if self.enable_storage:
self.drain_storage_control_queues()
if self.enable_storage_metrics:
self.metrics_collector.log_storage_metrics(
self.cache_controller.storage_backend.get_stats())
writing_check
loading_check
Prefetch
类似LMCache的prefetch,从低速后端例如Disk prefetch到CPU。
scheduler在调用_add_request_to_queue时调用_prefetch_kvcache进行prefetch操作:
def _prefetch_kvcache(self, req: Req):
if self.enable_hicache_storage:
req.init_next_round_input(self.tree_cache)
if req.last_node.backuped:
# only to initiate the prefetch if the last node is backuped
# otherwise, the allocated GPU memory must be locked for integrity
last_hash = req.last_host_node.get_last_hash_value()
matched_len = len(req.prefix_indices) + req.host_hit_length
new_input_tokens = req.fill_ids[matched_len:]
self.tree_cache.prefetch_from_storage(
req.rid, req.last_host_node, new_input_tokens, last_hash)get_new_batch_prefill中检查prefetch是否完成:
def get_new_batch_prefill(self) -> Optional[ScheduleBatch]:
for req in self.waiting_queue:
if self.enable_hicache_storage:
prefetch_done = self.tree_cache.check_prefetch_progress(req.rid)
if not prefetch_done:
# skip staging requests that are ongoing prefetch
continue
req.init_next_round_input(self.tree_cache)prefetch_from_storage
需要被prefetch的token:
matched_len = len(req.prefix_indices) + req.host_hit_length
new_input_tokens = req.fill_ids[matched_len:]
prefetch_length = len(new_input_tokens) - (len(new_input_tokens) % self.page_size)
new_input_tokens = new_input_tokens[:prefetch_length]也就是没有被GPU和CPU命中的请求部分。
prefetch使能L3存储,以及prefetch_length<prefetch_threshold(默认256),以及prefetch token使用低于阈值时进行。
调用protect_host对host_ref_counter += 1,避免host被驱逐。
分配prefetch_length的host_indices。
调用prefetch和更新状态
operation = self.cache_controller.prefetch(req_id, host_indices, new_input_tokens, last_hash)
self.ongoing_prefetch[req_id] = (last_host_node, new_input_tokens, host_indices, operation)
self.cache_controller.prefetch_tokens_occupied += len(new_input_tokens)
check_prefetch_progress
调用terminate_prefetch,得到TP worker之间最小的completed_tokens。
把完成的token host index添加到radix tree。
HiCacheController
write
start_writing
调用mem_pool_host.backup_from_device_all_layer。
load
start_loading
调用mem_pool_host.load_to_device_per_layer。
HiCacheFile
定义了如下接口,L3的backend 插件要进行实现:
get
batch_get
set
batch_set
exists
batch_exists
get_stats
HiCacheStorage
get读取文件,set写入文件,exist直接判断文件是否存在:
def get( self, key: str, target_location: torch.Tensor, target_sizes: Optional[Any] = None) -> torch.Tensor | None:
key = self._get_suffixed_key(key)
tensor_path = os.path.join(self.file_path, f"{key}.bin")
try:
expected = target_location.numel() * target_location.element_size()
with open(tensor_path, "rb", buffering=0) as f:
buf = memoryview(target_location.view(torch.uint8).contiguous().numpy())
if f.readinto(buf) != expected:
raise IOError(f"Short read for {key}")
return target_location
def set( self, key: str, value: Optional[Any] = None, target_location: Optional[Any] = None, target_sizes: Optional[Any] = None) -> bool:
key = self._get_suffixed_key(key)
tensor_path = os.path.join(self.file_path, f"{key}.bin")
try:
value.contiguous().view(dtype=torch.uint8).numpy().tofile(tensor_path)
return True
def exists(self, key: str) -> bool:
key = self._get_suffixed_key(key)
tensor_path = os.path.join(self.file_path, f"{key}.bin")
return os.path.exists(tensor_path)
当前存在的问题和可能的改进:
没有驱逐策略!
没有基于radix tree的管理!

免费领 150 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 22
22 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)