
SGLang PD分离流程细节
SGLang PD分离设计文档
https://docs.google.com/document/d/1rQXJwKd5b9b1aOzLh98mnyMhBMhlxXA5ATZTHoQrwvc/edit?tab=t.0
[Roadmap] Prefill and Decoding Disaggregation · Issue #4655 · sgl-project/sglang · GitHub
为什么要PD分离

PD的差异化优化
P是算力密集型,需要高算力,对内存容量需求相对没有那么高,也不需要很多请求组batch计算。
D是访存密集型,相比于计算性能,更显著需要高内存带宽和内容容量。需要很多请求组成一个大的batch计算提升throughput。
如果P/D没有针对性优化,只是简单做一个PD分离,同样多的GPU,其实P/D不能产生更大的throughput,反而可能降低throguhput,但是PD分离的好处是可以灵活调控P/D的比例,产生显著不同的TTFT/ITL特性。
P/D分离能够产生更大throughput,必须要在P/D相对于非PD实施独特的优化手段。其中最为至关重要的就是DP attention。此外还有deepep等P/D针对性优化。
非PD对DP attention并不是很兼容。用了DP可能性能反而变差。
P/D对DP attention需求不一样,对于MLA模型,DP attention可以一定程度提升P的throughput,但是并不是那么显著,有个百分之30%量级。但是用了DP attention特别是DP=TP的时候,单个GPU算一个请求,算力比较低,TTFT数值相比于不用DP是数倍增长了,往往得不偿失。
但是DP attention对D的throughput是成倍提升的,基本上用多少DP就提升多少倍。而DP对ITL有一定牺牲,却不像TTFT那样成倍降低,而只是可能降低个百分之30%量级。原理可能是因为D是访存密集型,需要显著更大的batch size达到计算密集型。而对于MOE模型,这个batch size要达到异常至高,才能使得每个专家获得足够token输入达到throughput饱和。而TP并行不可能达到一个高的batch size,而DP attention每个GPU都计算一个大的batch,整个节点batch size相比TP直接x8,throughput从而显著提升。
那么P的TP + D的DP组合能够同时带来好的TTFT,ITL,throughput,这一点是非PD基本上无法实现的。业界的实践参考蚂蚁工作:
Together with SGLang: Best Practices for Serving DeepSeek-R1 on H20-96G
PD与非PD的吞吐比较
在不考虑SLO的情况下,只有PD分离对P/D进行差异化优化,是的PD分离的prefill/decode throughput大于非PD的prefill throughput,才能实现总吞吐提升。否则吞吐会变差。
假设输入总token I,输出总token O,单实例prefill throughput P, decode throughput D,P和D实例数分别为m和n,总实例数为m+n。
那么非PD计算时间为:
T_agg = I/((m+n)*P) + O/((m+n)D) = a/(m+n)+b/(m+n)=(a+b)/(m+n)
PD的计算时间为
T_PD = max(I/(m*P), O/(n*D)) = max(a/m, b/n)
这里a=I/P, b=O/D

也就是说,如果PD的P/Dthroughput与非PD的P/D throughput没有差异,那么极限吞吐反而是更差的。
在考虑SLO的情况下,因为PD和非PD的SLO完全不同,即使在P/D没有差异化的提升,在不同的SLO要求下,也可能有throughput提升。
考虑SLO的情况下,非PD的decode存在被prefill打断,所以达到同样TOPT的batch更小,也就是decode throughput非PD更低
PD分离可以使得P/D具备差异化优化能力,使得P/D分离的情况下,P/D throughput各自相比非PD更优。
SGLang PD分离请求流程
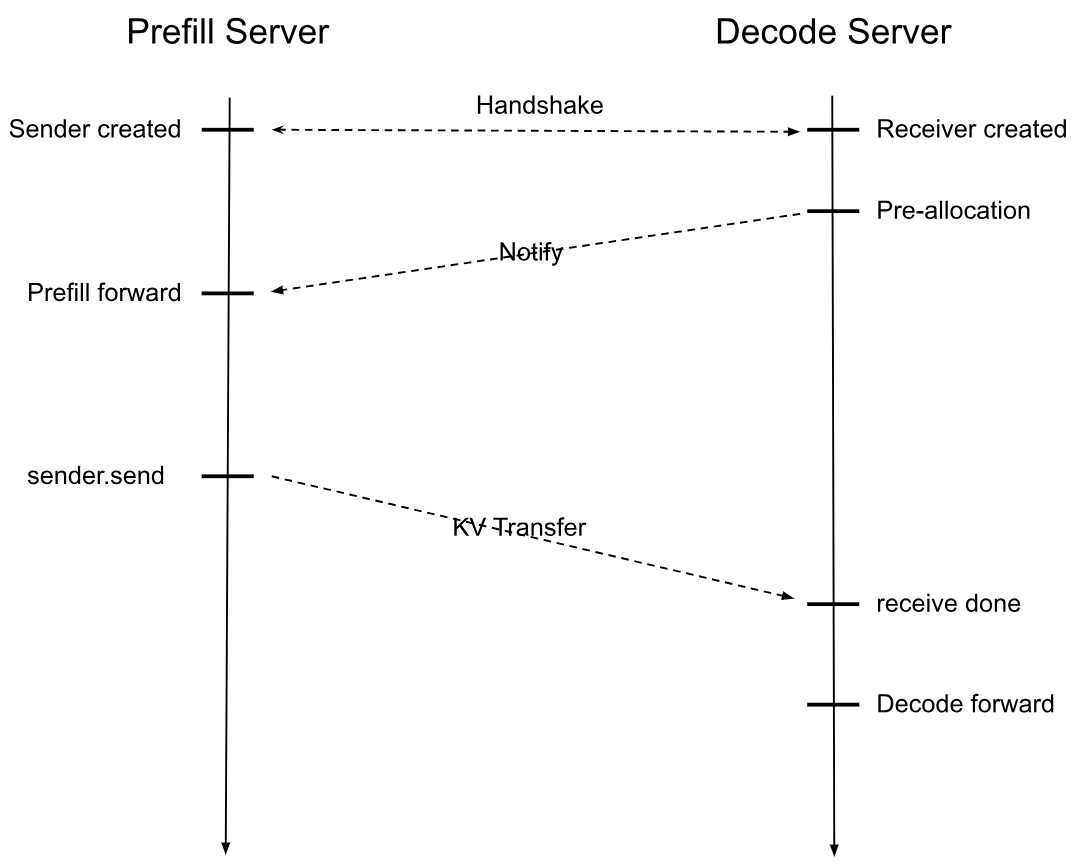
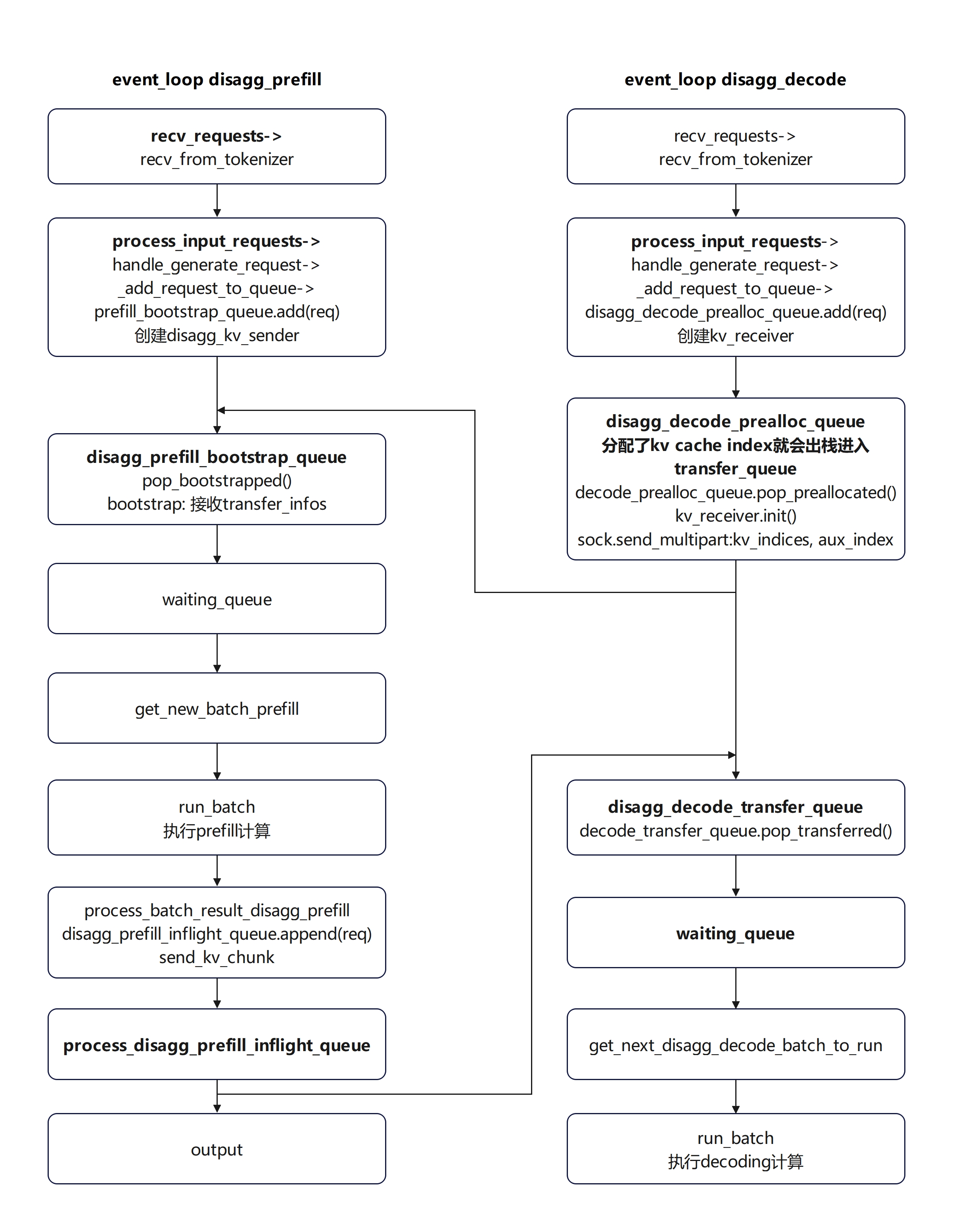
美中不足:当前不支持像nvidia dynamo最初版本支持的那种允许一些场景的请求只在decode节点处理而不依赖于prefill,当前设计必须同时经历prefill处理然后传输kv cache到decoding节点解码。
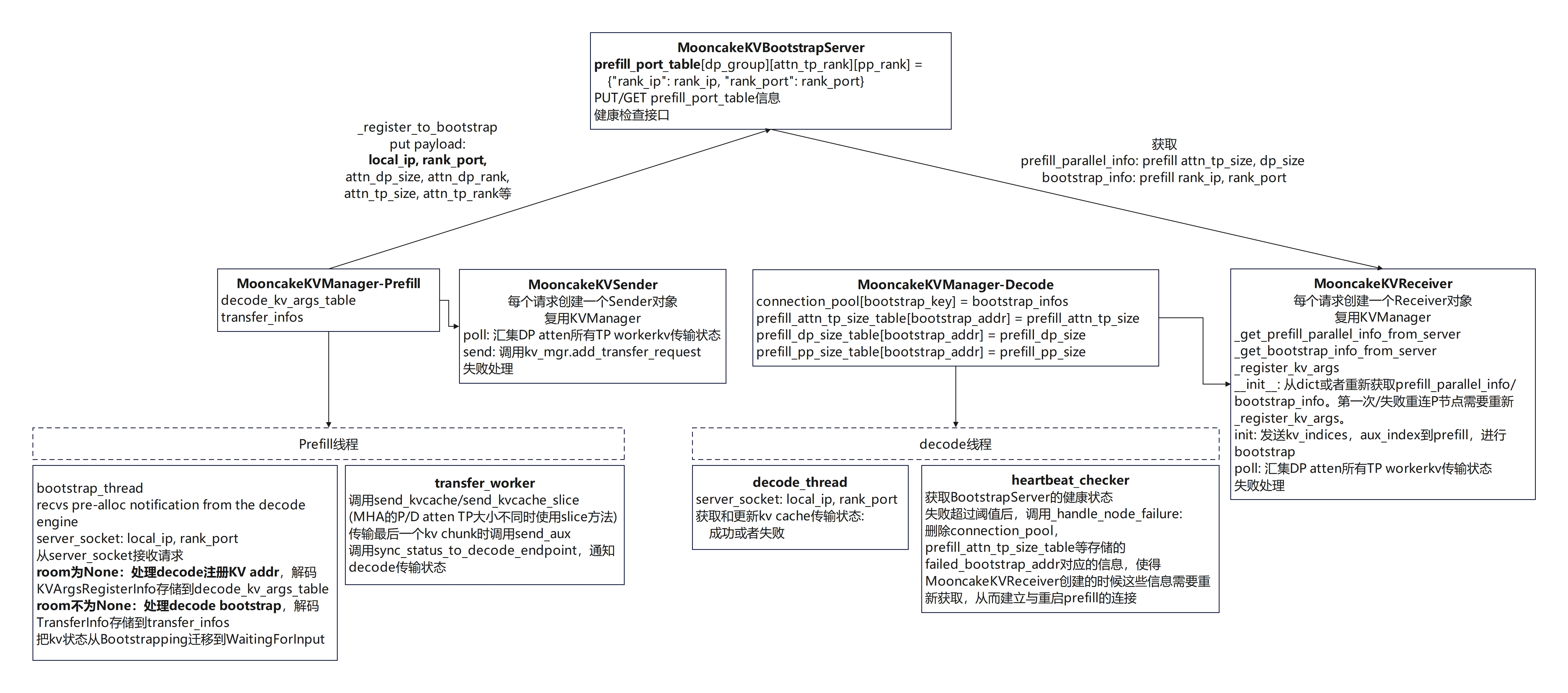
Mooncake通信库处理逻辑
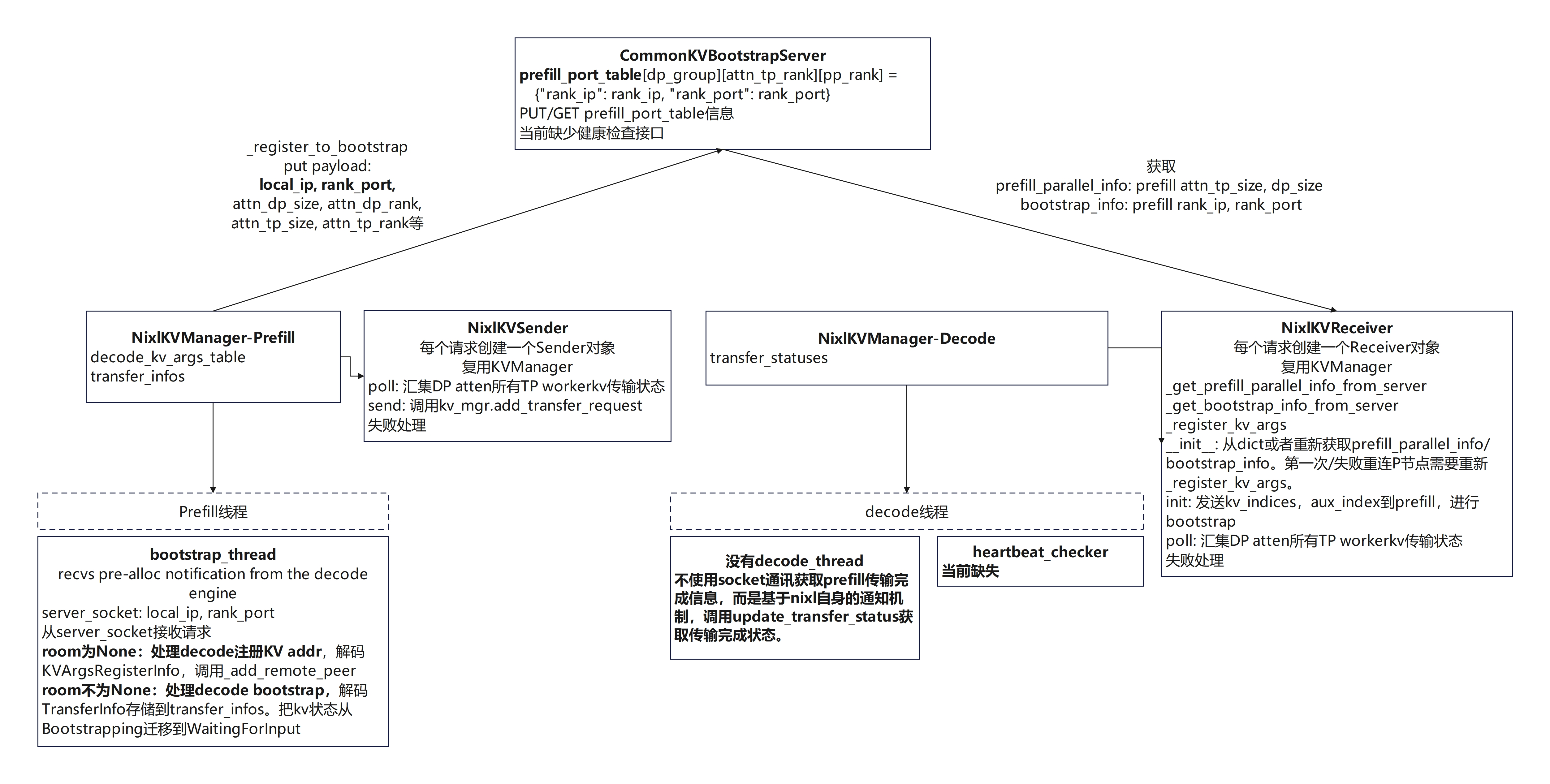
NIXL通信库处理逻辑
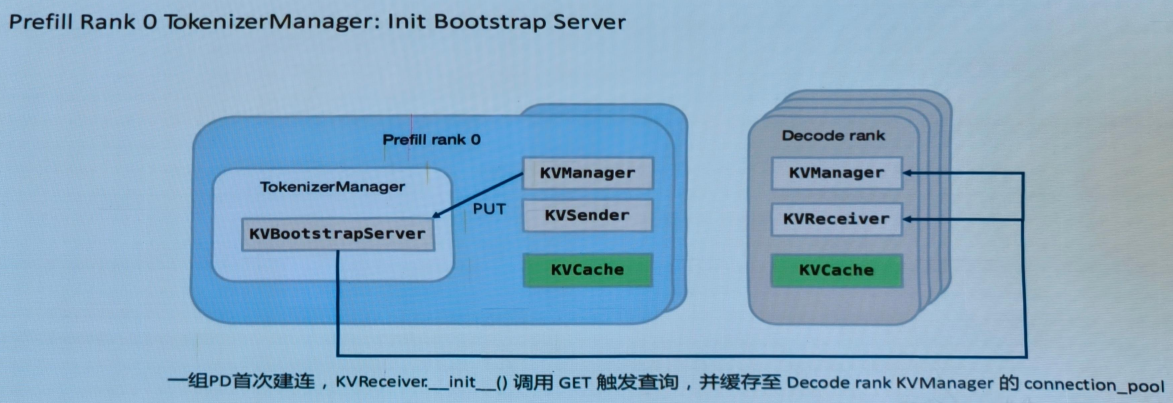
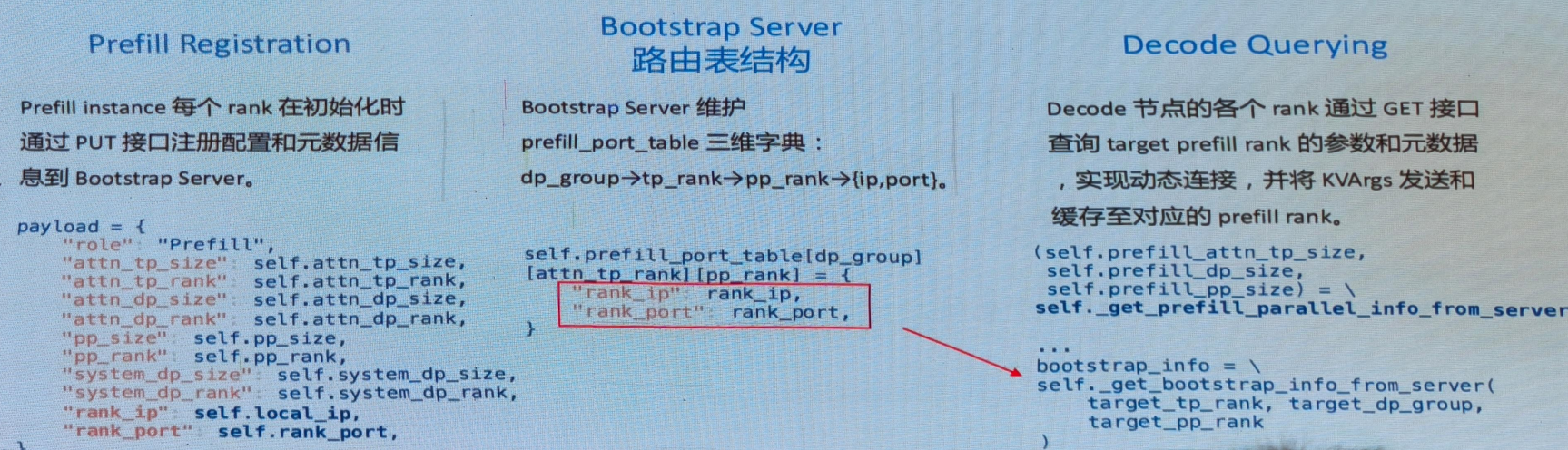
BootstrapServer
BootstrapServer通过调用start_disagg_service启动,在prefill的TokenizerManager创建时调用。
def start_disagg_service(
server_args: ServerArgs,
):
# Start kv boostrap server on prefill
disagg_mode = DisaggregationMode(server_args.disaggregation_mode)
transfer_backend = TransferBackend(server_args.disaggregation_transfer_backend)
if disagg_mode == DisaggregationMode.PREFILL:
# only start bootstrap server on prefill tm
kv_bootstrap_server_class: Type[BaseKVBootstrapServer] = get_kv_class(
transfer_backend, KVClassType.BOOTSTRAP_SERVER
)
bootstrap_server: BaseKVBootstrapServer = kv_bootstrap_server_class(
host=server_args.host,
port=server_args.disaggregation_bootstrap_port,
)
utils
poll_and_all_reduce:对同一个atten DP内的TP worker的kv状态进行一个reduce_min的同步。
kv cache传输状态迁移:

数据传输准备
class KVArgs:
engine_rank: int
kv_data_ptrs: List[int]
kv_data_lens: List[int]
kv_item_lens: List[int]
aux_data_ptrs: List[int]
aux_data_lens: List[int]
aux_item_lens: List[int]
state_data_ptrs: List[int]
state_data_lens: List[int]
state_item_lens: List[int]
state_type: str # "none", "mamba", "swa"
# for mamba state different tp slice transfer
state_dim_per_tensor: List[int] # dimension to slice for each state tensor
ib_device: str
ib_traffic_class: str
gpu_id: int
kv_head_num: int
total_kv_head_num: int
page_size: int
# for pp prefill
pp_rank: int
prefill_start_layer: int
# for system dp
system_dp_rank: int
三个数据部分:
kv_data_ptrs: List[int], kv_data_lens: List[int], kv_item_lens: List[int]:
主模型和speculative draft model的kv cache。
aux_data_ptrs: List[int], aux_data_lens: List[int], aux_item_lens: List[int]:
transfer the metadata of first output token to decode
class MetadataBuffers:
def get_buf_infos(self):
ptrs = [
self.output_ids.data_ptr(),
self.cached_tokens.data_ptr(),
self.output_token_logprobs_val.data_ptr(),
self.output_token_logprobs_idx.data_ptr(),
self.output_top_logprobs_val.data_ptr(),
self.output_top_logprobs_idx.data_ptr(),
self.output_topk_p.data_ptr(),
self.output_topk_index.data_ptr(),
self.output_hidden_states.data_ptr(),
self.bootstrap_room.data_ptr(),
]state_data_ptrs: List[int], state_data_lens: List[int], state_item_lens: List[int]:
swa, mamba, DeepSeek V3.2模型的DSA以及mtp模型的DSA额外的kv cache信息。
def setup_state_kv_args(
kv_args: KVArgs,
token_to_kv_pool,
draft_token_to_kv_pool=None,
) -> None:
"""Populate ``kv_args`` state-buffer fields from the given pool.
Shared by prefill and decode bootstrap paths so the state_type dispatch
lives in one place.
"""
from sglang.srt.mem_cache.memory_pool import HybridLinearKVPool, NSATokenToKVPool
from sglang.srt.mem_cache.swa_memory_pool import SWAKVPool
state_data_ptrs, state_data_lens, state_item_lens = (
token_to_kv_pool.get_state_buf_infos()
)
kv_args.state_data_ptrs = state_data_ptrs
kv_args.state_data_lens = state_data_lens
kv_args.state_item_lens = state_item_lens
if isinstance(token_to_kv_pool, SWAKVPool):
kv_args.state_type = "swa"
elif isinstance(token_to_kv_pool, HybridLinearKVPool):
kv_args.state_type = "mamba"
# Get state dimension info for cross-TP slice transfer
if hasattr(token_to_kv_pool, "get_state_dim_per_tensor"):
kv_args.state_dim_per_tensor = token_to_kv_pool.get_state_dim_per_tensor()
elif isinstance(token_to_kv_pool, NSATokenToKVPool):
kv_args.state_type = "nsa"
if draft_token_to_kv_pool is not None and isinstance(
draft_token_to_kv_pool, NSATokenToKVPool
):
(
draft_state_data_ptrs,
draft_state_data_lens,
draft_state_item_lens,
) = draft_token_to_kv_pool.get_state_buf_infos()
kv_args.state_data_ptrs += draft_state_data_ptrs
kv_args.state_data_lens += draft_state_data_lens
kv_args.state_item_lens += draft_state_item_lens
else:
kv_args.state_type = "none"
初始化传输的数据信息
class PrefillBootstrapQueue:
def _init_kv_manager(self) -> CommonKVManager:
kv_args_class = get_kv_class(self.transfer_backend, KVClassType.KVARGS)
kv_args = kv_args_class()
kv_args.engine_rank = self.tp_rank
kv_args.pp_rank = self.pp_rank
kv_args.system_dp_rank = self.scheduler.dp_rank
kv_args.prefill_start_layer = self.token_to_kv_pool.start_layer
kv_data_ptrs, kv_data_lens, kv_item_lens = (
self.token_to_kv_pool.get_contiguous_buf_infos()
)
if self.draft_token_to_kv_pool is not None:
# We should also transfer draft model kv cache. The indices are
# always shared with a target model.
draft_kv_data_ptrs, draft_kv_data_lens, draft_kv_item_lens = (
self.draft_token_to_kv_pool.get_contiguous_buf_infos()
)
kv_data_ptrs += draft_kv_data_ptrs
kv_data_lens += draft_kv_data_lens
kv_item_lens += draft_kv_item_lens
kv_args.kv_data_ptrs = kv_data_ptrs
kv_args.kv_data_lens = kv_data_lens
kv_args.kv_item_lens = kv_item_lens
if not self.is_mla_backend:
kv_args.kv_head_num = self.token_to_kv_pool.head_num
kv_args.total_kv_head_num = (
self.scheduler.model_config.get_total_num_kv_heads()
)
kv_args.page_size = self.token_to_kv_pool.page_size
kv_args.aux_data_ptrs, kv_args.aux_data_lens, kv_args.aux_item_lens = (
self.metadata_buffers.get_buf_infos()
)
kv_args.ib_device = self.scheduler.server_args.disaggregation_ib_device
kv_args.gpu_id = self.scheduler.gpu_id
setup_state_kv_args(kv_args, self.token_to_kv_pool, self.draft_token_to_kv_pool)
mooncake注册
class MooncakeKVManager(CommonKVManager):
def register_buffer_to_engine(self):
# Batch register KV data buffers
if self.kv_args.kv_data_ptrs and self.kv_args.kv_data_lens:
self.engine.batch_register(
self.kv_args.kv_data_ptrs, self.kv_args.kv_data_lens
)
# Batch register auxiliary data buffers
if self.kv_args.aux_data_ptrs and self.kv_args.aux_data_lens:
self.engine.batch_register(
self.kv_args.aux_data_ptrs, self.kv_args.aux_data_lens
)
# Batch register state/extra pool data buffers
if self.kv_args.state_data_ptrs and self.kv_args.state_data_lens:
self.engine.batch_register(
self.kv_args.state_data_ptrs, self.kv_args.state_data_lens
)

免费领 150 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 3
3 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)