
【SGlang】sglang部署本地模型
·
官网
https://docs.sglang.ai/get_started/install.html
使用多模态模型命令
--enable-multimodal
设置启动服务后模型的名字
--served-model-name Qwen3-VL-8B-Thinking
docker启动模型(使用已下载好的模型文件)
docker run --name 20251117_sglang_Qwen3-VL-4B-Thinking --gpus all --shm-size 20g -p 30000:30000 -v D:\docker_data\sglang:/root/.cache/huggingface --ipc=host lmsysorg/sglang:v0.5.5.post1-cu129-amd64 python3 -m sglang.launch_server --model-path /root/.cache/huggingface/hub/models/Qwen/Qwen3-VL-4B-Thinking --served-model-name Qwen/Qwen3-VL-4B-Thinking --mem-fraction-static 0.9 --quantization fp8 --dtype float16 --host 0.0.0.0 --port 30000
分配用于kv缓存占总显存的比例
--mem-fraction-static 0.8
分配GPU显存80%给kv缓存使用,默认值0.8,当显存不足时,需要降低给kv分配的kv缓存
设置用于模型执行器的GPU内存比例
--gpu-memory-utilization 0.85
设置上下文长度
--context-length 1010000
设置内存池最大token数,会显著改变显存占用
--max-total-tokens 20000
限制请求数量
此命令可以降低显存占用并提高tokens生成速度
--max-running-requests 2
模型地址
--model-path Qwen/Qwen3-VL-8B-Thinking
此地址实际的位置是docker容器内部的以下地址,此处用的modelscope,huggingface有同样的目录结构
/root/.cache/modelscope/hub/models/Qwen/Qwen3-VL-8B-Thinking
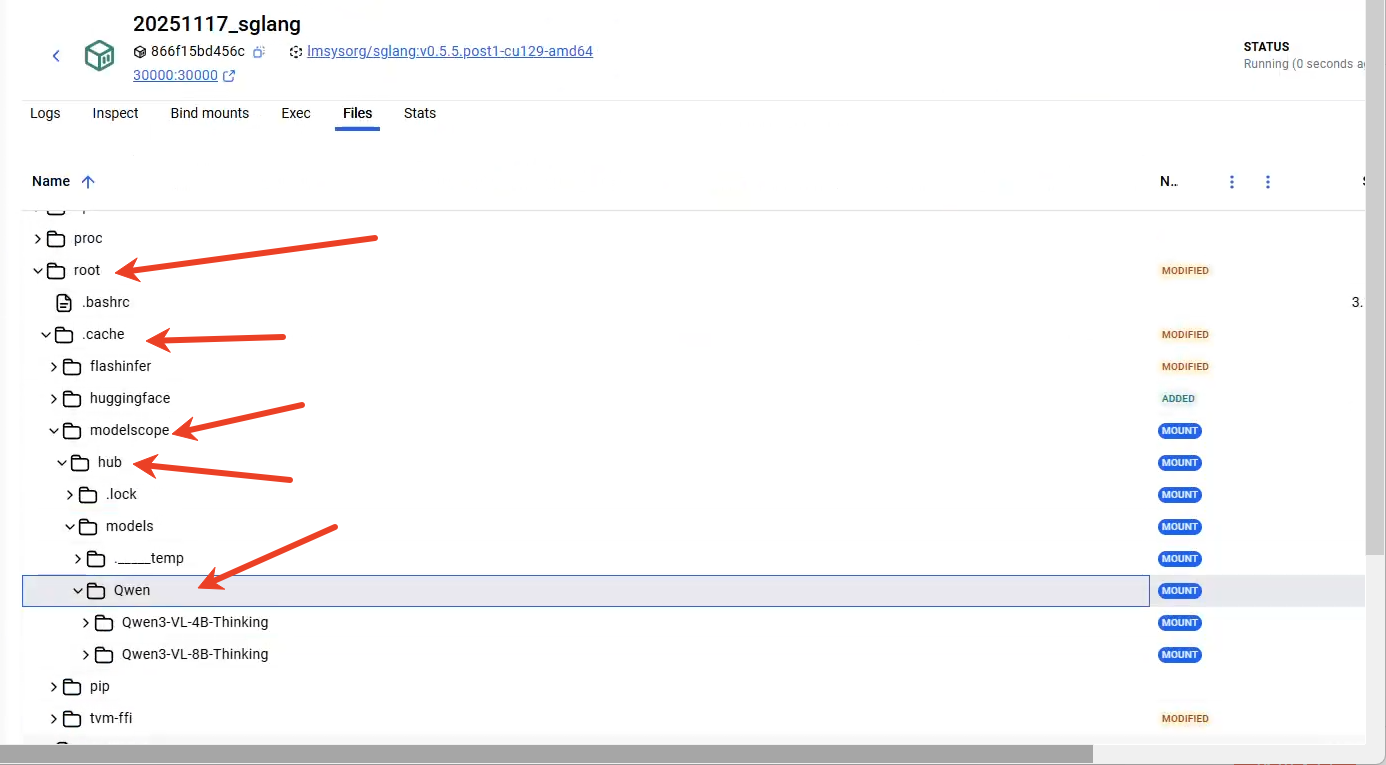
在本地挂载的地址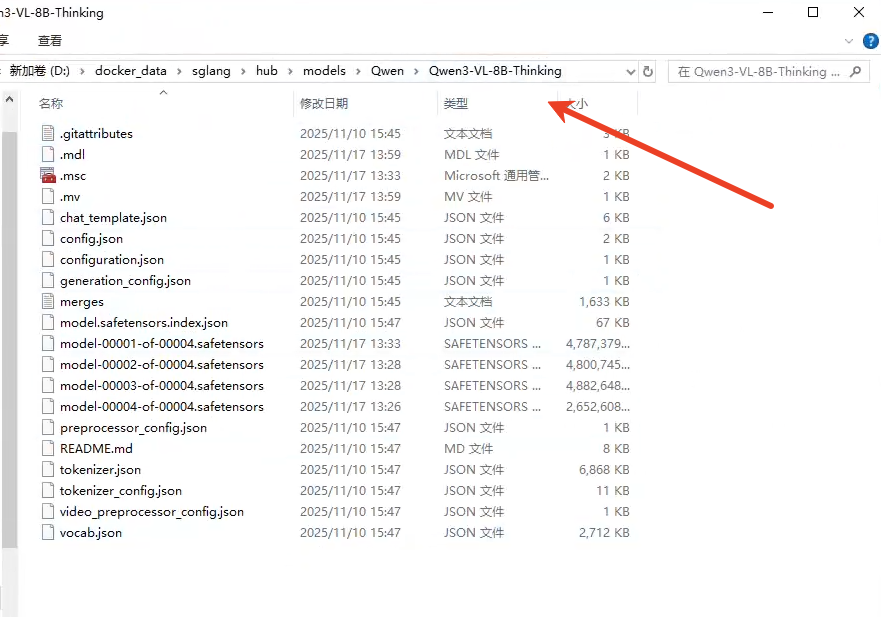
模型使用8bit量化
--quantization fp8
模型运行时使用float16精度运行
--dtype float16
设置模型名字
自定义服务启动后的模型名字为Qwen/Qwen3-VL-4B-Thinking
--served-model-name Qwen/Qwen3-VL-4B-Thinking
设置显存碎片可连续
-e PYTORCH_ALLOC_CONF=expandable_segments:True
本地文件目录结构
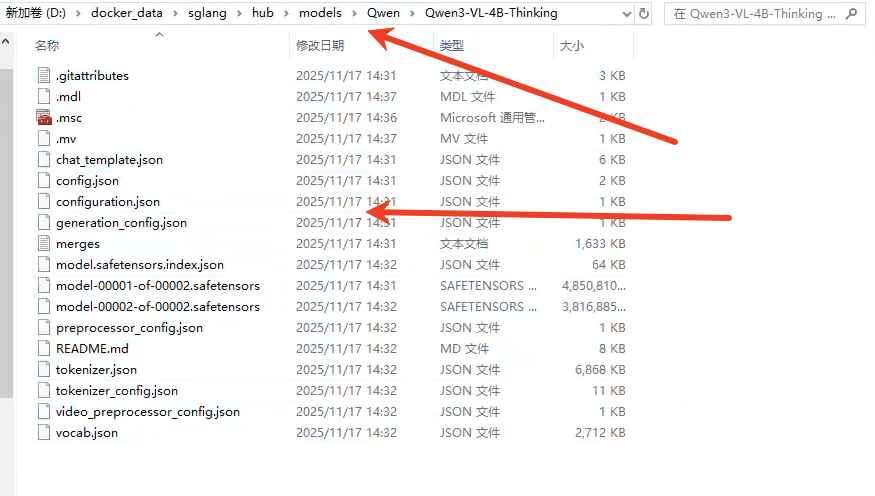
其他参数查询
启动一个空容器
添加tail -f /dev/null
docker run --name 20251118_sglang_Qwen3-VL-4B-Thinking --gpus all --shm-size 20g -p 30000:30000 -v D:\docker_data\sglang:/root/.cache/huggingface --ipc=host lmsysorg/sglang:v0.5.5.post1-cu129-amd64 tail -f /dev/null
进入容器内部执行命令
docker exec -it 20251118_sglang_Qwen3-VL-4B-Thinking /bin/bash
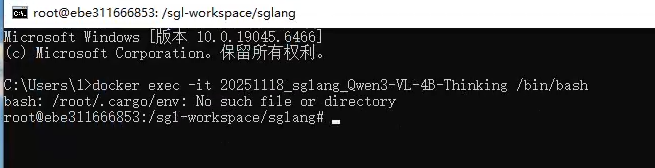
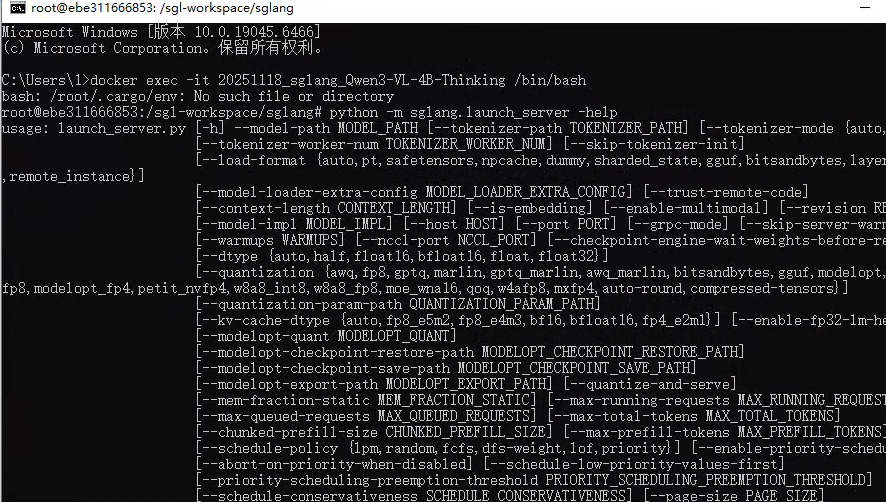
查看命令参数
python -m sglang.launch_server -help
或者访问sglang官方网站查看
https://docs.sglang.io/advanced_features/server_arguments.html
官网查询其他详细参数
https://docs.sglang.io/advanced_features/server_arguments.html
cpu卸载
直接参数卸载
将多少GB的模型权重卸载到cpu中
--cpu-offload-gb
分组卸载
将模型权重多少层分为一组
--offload-group-size
每组卸载多少层到cpu中
--offload-num-in-group
启动服务后使用docs
输入docs的地址,如下
127.0.0.1:8080/docs
可以使用以下接口测试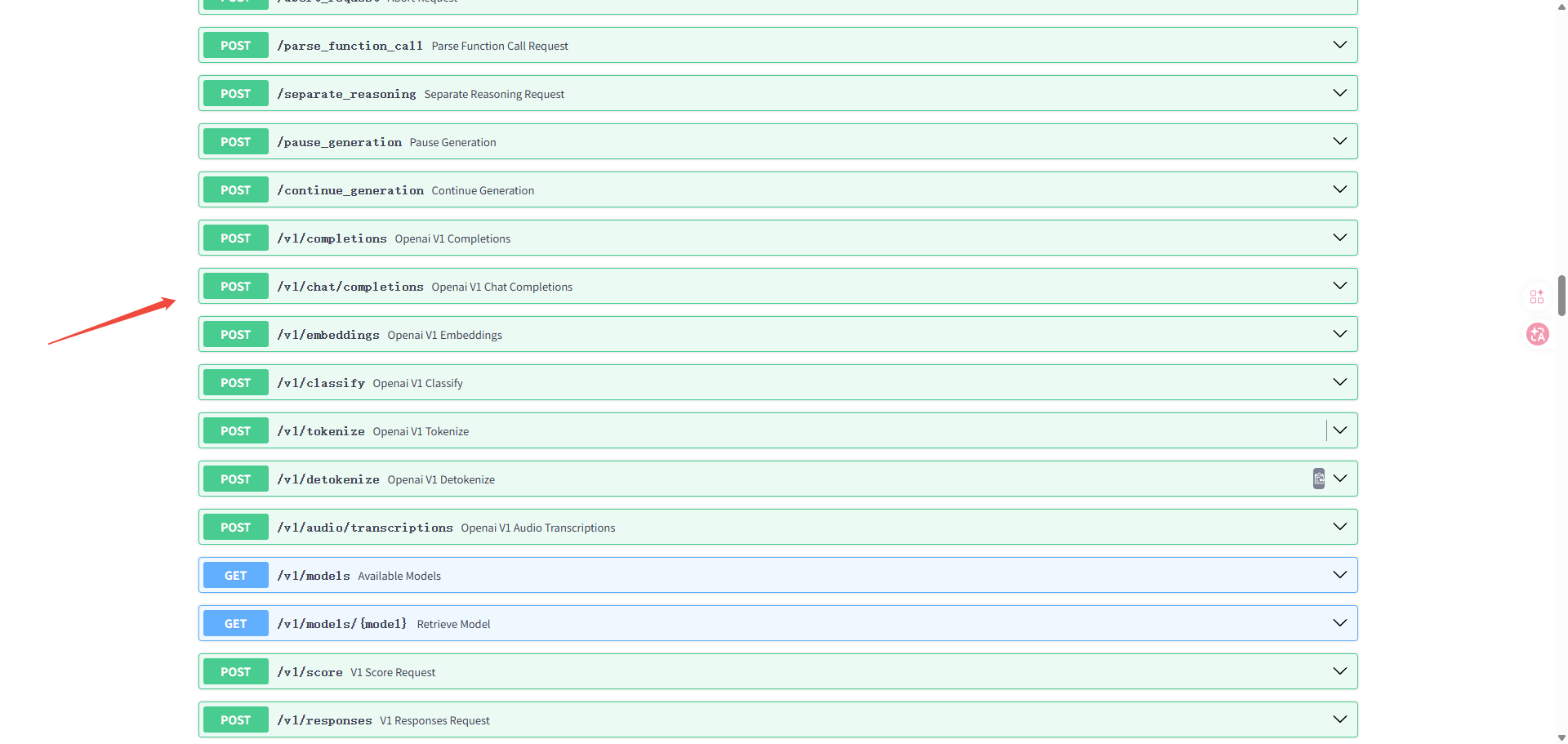
传入以下对话参数
{
"messages": [
{
"role": "user",
"content": "你好"
}
]
}
收到以下返回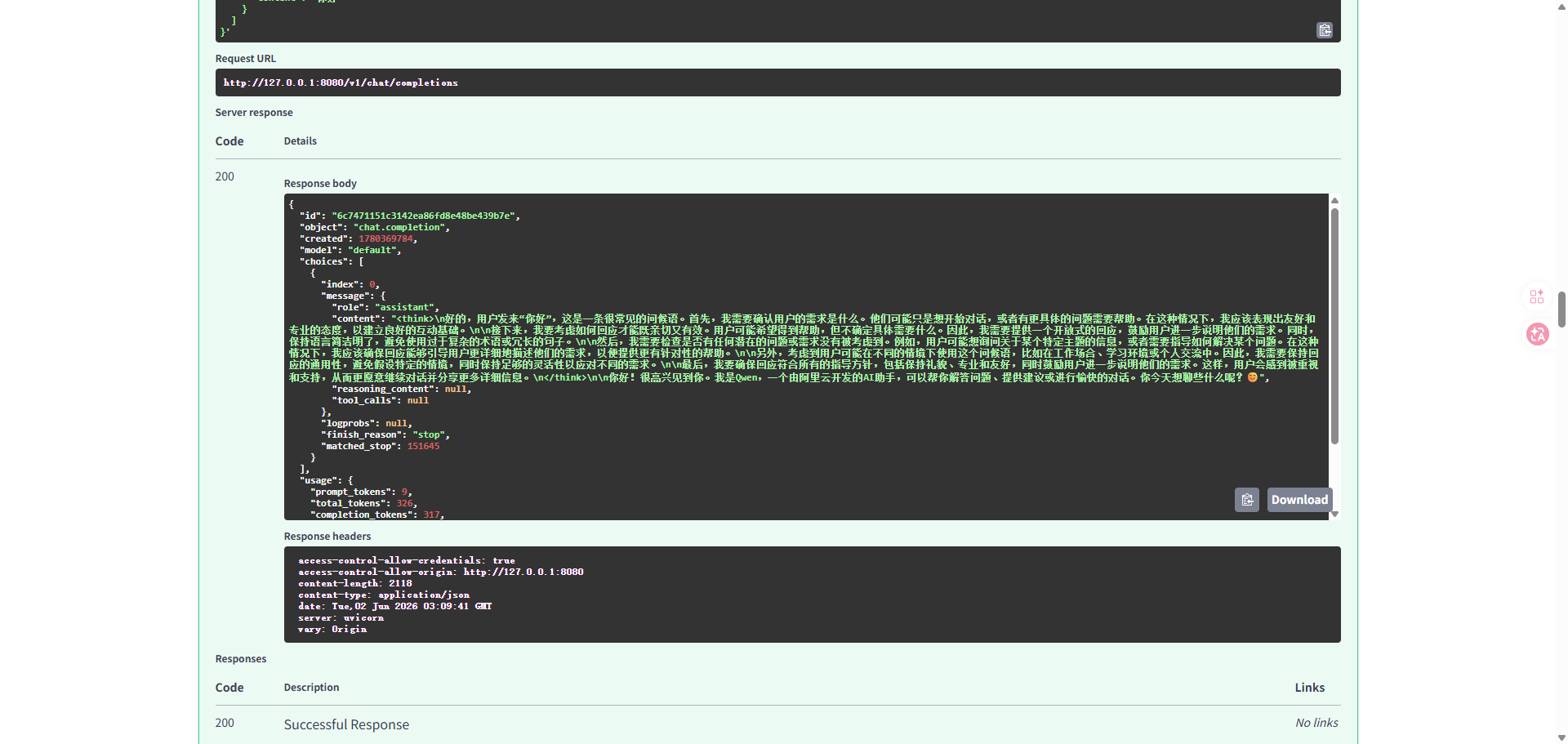

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐

 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)