
sglang 原理
模型推理需要什么
这里模型以transformer模型为例
模型提供权重文件,推理引擎需在内存中构建对应的计算图,并加载权重至计算图中,进行推理。
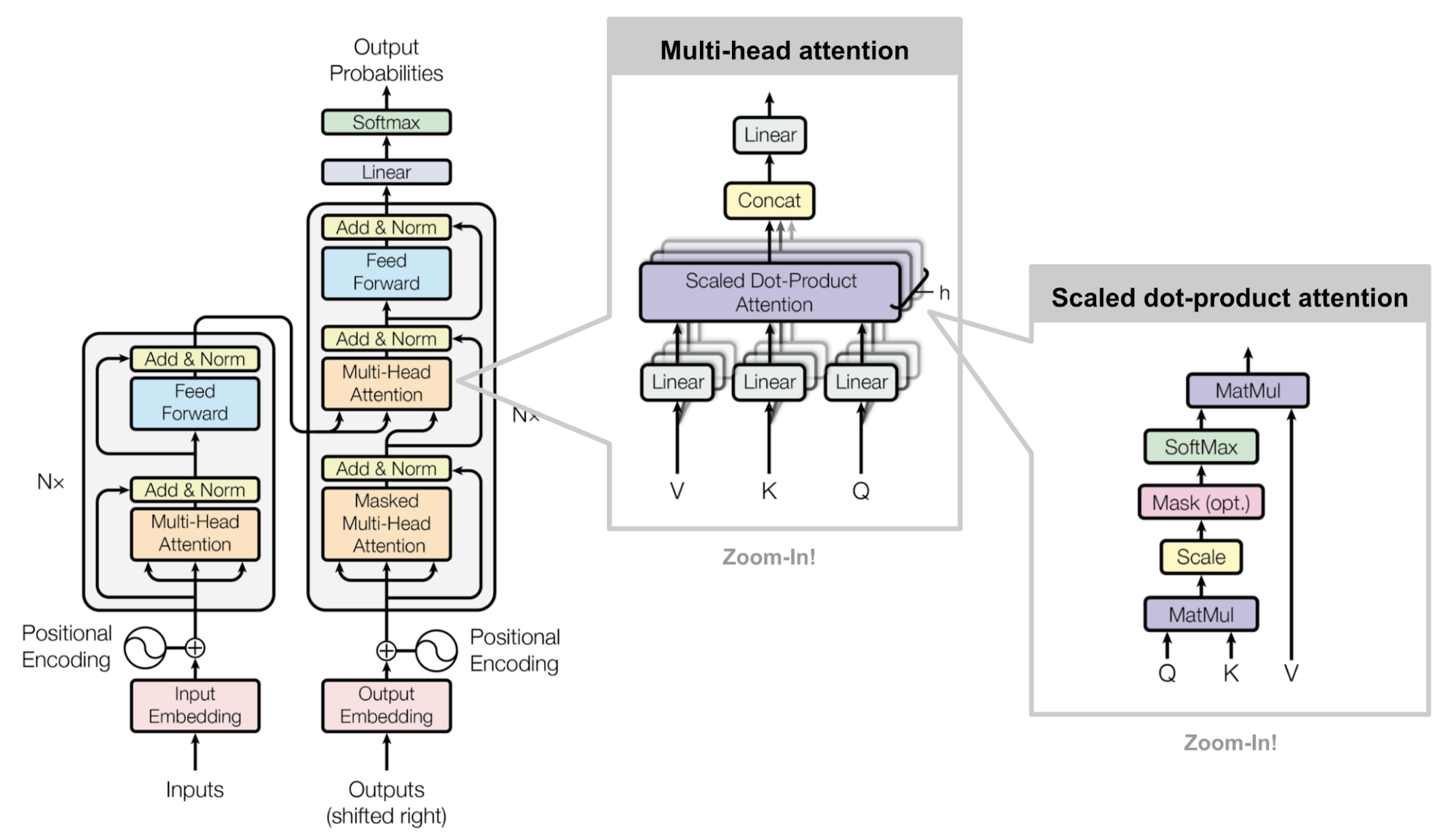
对外以API调用的方式推理服务,当接收到推理请求时传递至网络,输出推理结果。
每次推理主要分为两个阶段
prefill 阶段
- Tokenization(分词),即将句子拆分为分词token数组
- Embedding 层 将 token 转换为向量,便与计算机处理以及能附更多的信息
- 位置编码(Positional Encoding),一句话中每个词是有先后关系的,通过位置编码将位置信息嵌入到token对应的向量
- 一次前向传播,生成的 第 1 个新 token(即回复的第一个 token)的概率分布
decode(自回归)阶段
- 使用prefill 阶段生成的第一个token的概率分布,生成第一个token
- 使用第一个token 生成第二个token
- 使用第一个 token的logits 分布 + 第二个token的logits 分布 生成第三个token
- 继续循环处理,自回归,生成至第N个token,出现结束符时停止。
sglang需要支持什么
- 构建计算图,加载权重,并包装为对外的可用API服务。
- 自回归过程中有大量冗余计算,支持利用缓存降低计算开销。
- 大规模模型资源需求较大,支持通过张量与模型结构两个维度拆分,做多机多卡等并行计算。
sglang的实现
算子构建
针对不同的模型,sglang将构建推理网络,并加载权重。如下,是sglang中针对各个模型的算子构建逻辑。
选取qwen3 为例,将发现sglang支持为qwen3构建完整的计算网络。
qwen3 推理网络结构如下。
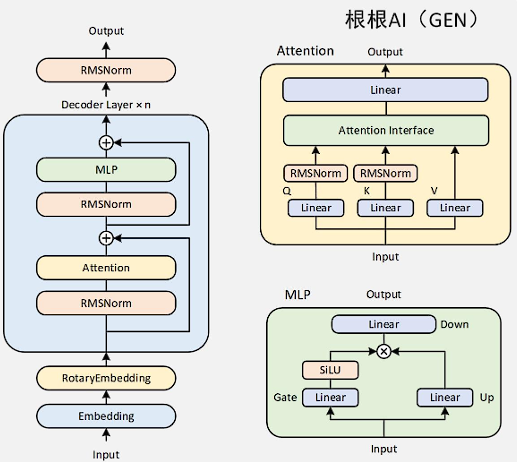
在sglang对应代码中可找到对应的逻辑实现。
Embedding以及rope转置
# 嵌入层构建
if self.pp_group.is_first_rank:
self.embed_tokens = VocabParallelEmbedding(
config.vocab_size,
config.hidden_size,
org_num_embeddings=config.vocab_size,
enable_tp=not is_dp_attention_enabled(),
)
else:
self.embed_tokens = PPMissingLayer()
# 使用rope 引入位置信息
self.rotary_emb = get_rope(
head_size=self.head_dim,
rotary_dim=self.head_dim,
max_position=self.max_position_embeddings,
rope_scaling=self.rope_scaling,
base=self.rope_theta,
partial_rotary_factor=self.partial_rotary_factor,
is_neox_style=True,
dtype=torch.get_default_dtype(),
)attention,以及多头构建
class Qwen3_5AttentionDecoderLayer(nn.Module):
"""Qwen3.5 Decoder Layer with Full Attention."""
def __init__(
self,
config: Qwen3_5TextConfig,
layer_id: int,
quant_config: Optional[QuantizationConfig] = None,
prefix: str = "",
alt_stream: Optional[torch.cuda.Stream] = None,
is_nextn: bool = False,
) -> None:
super().__init__()
self.config = config
self.hidden_size = config.hidden_size
self.attn_tp_rank = get_attention_tp_rank()
self.attn_tp_size = get_attention_tp_size()
self.total_num_heads = config.num_attention_heads
assert self.total_num_heads % self.attn_tp_size == 0
self.num_heads = self.total_num_heads // self.attn_tp_size
self.total_num_kv_heads = config.num_key_value_heads
if self.total_num_kv_heads >= self.attn_tp_size:
assert self.total_num_kv_heads % self.attn_tp_size == 0
else:
assert self.attn_tp_size % self.total_num_kv_heads == 0
# 这里是多头的拆分, head_dim 是每个头关注的维度
self.num_kv_heads = max(1, self.total_num_kv_heads // self.attn_tp_size)
self.head_dim = config.head_dim or (self.hidden_size // self.num_heads)
# attention 逻辑中的 q k v
self.q_size = self.num_heads * self.head_dim
self.kv_size = self.num_kv_heads * self.head_dim
self.scaling = self.head_dim**-0.5
self.max_position_embeddings = getattr(config, "max_position_embeddings", 8192)前馈神经网路MLP
qwen的mlp有moe模式,下面代码可见根据配置文件决定mlp是否为moe
# Qwen3.5 use all layers for MLP / Qwen3.5-MoE use sparse MoE blocks
if config.model_type == "qwen3_5_moe_text":
self.mlp = Qwen2MoeSparseMoeBlock(
layer_id=layer_id,
config=config,
quant_config=quant_config,
alt_stream=alt_stream,
prefix=add_prefix("mlp", prefix.replace(".linear_attn", "")),
is_nextn=is_nextn,
)
is_layer_sparse = True
is_previous_layer_sparse = True
is_next_layer_sparse = True
elif config.model_type == "qwen3_5_text":
self.mlp = Qwen2MoeMLP(
hidden_size=config.hidden_size,
intermediate_size=config.intermediate_size,
hidden_act=config.hidden_act,
quant_config=quant_config,
prefix=add_prefix("mlp", prefix.replace(".linear_attn", "")),
)
is_layer_sparse = False
is_previous_layer_sparse = False
is_next_layer_sparse = False
else:
raise ValueError(f"Invalid model type: {config.model_type}")
缓存加速推理
推理在decode(自回归阶段),每生成下一个token时,矩阵运算都包含前面已计算过的token的矩阵,因此缓存已生成token的q k v, 可加速decode阶段。
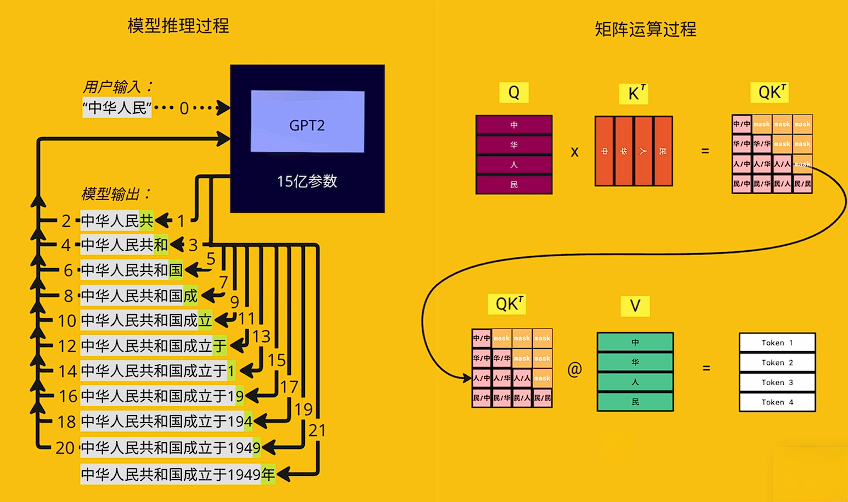
在多轮对话中也有类似的问题
在多轮对话中,上下文窗口中的历史内容也将与新内容一同作为请求。
将历史内容生成信息缓存,可以减少历史数据的计算开销,提高推理速度。
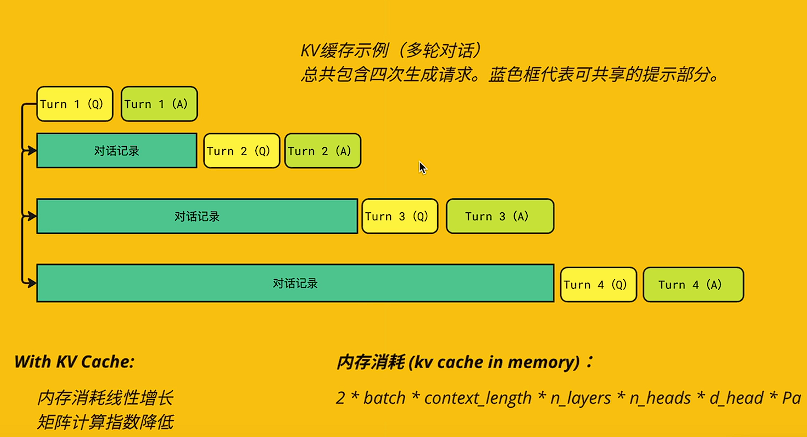
sglang通过构建keyval cache,以空间换时间降低计算开销加速推理。
基于基数树RadixTree数据结构实现的Cache, 其实就是压缩版的前缀树.
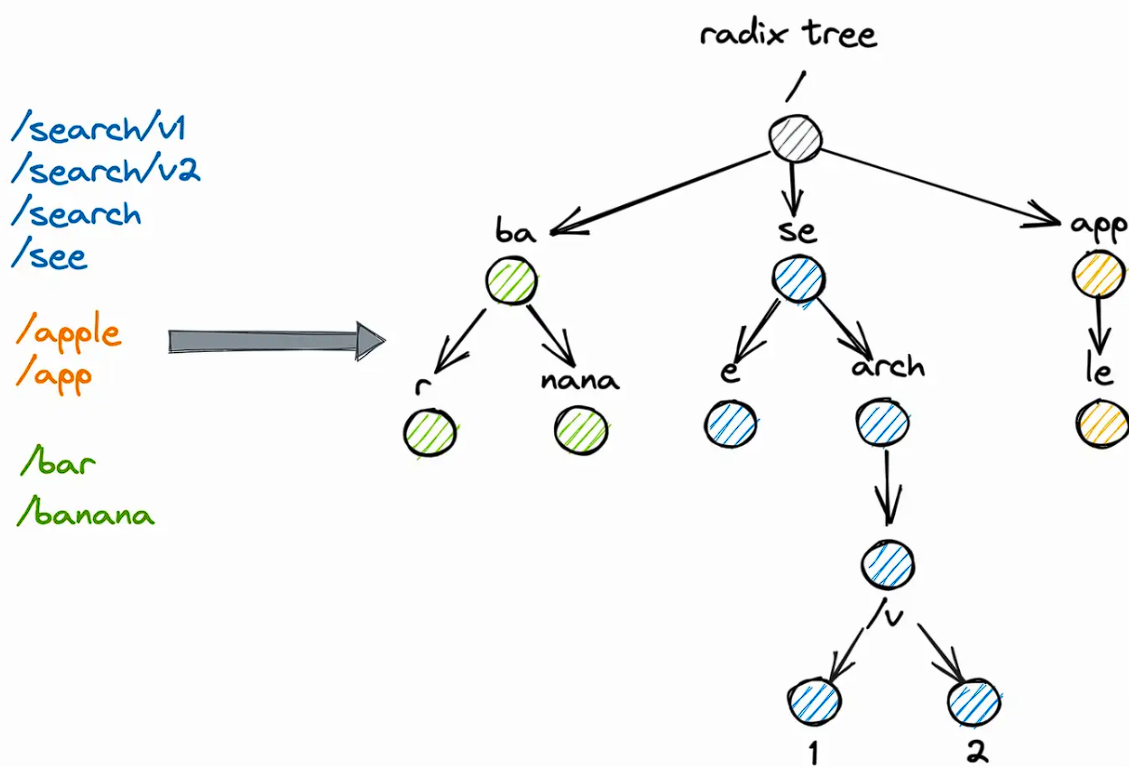
查询: 一直DFS到没有公共前缀为止.
插入:以root为起点遍历, 对当前节点做前缀匹配, 长度>0就进入子树否则进入兄弟节点. 一直DFS到没有公共前缀为止, 把不相同的str插入到新叶节点上.
插入与驱逐
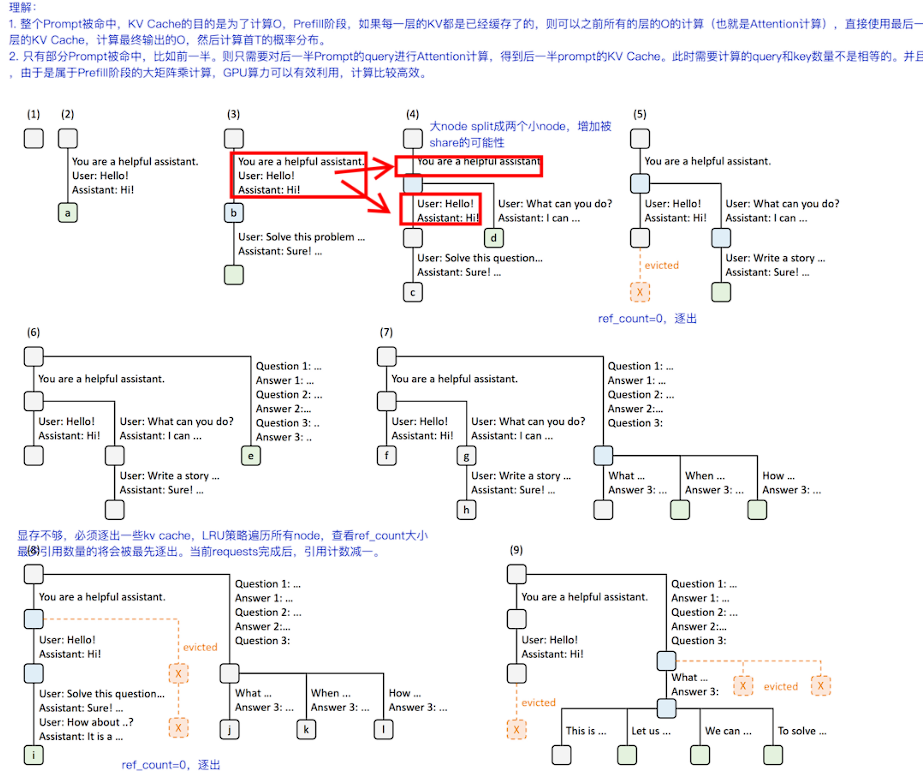
前缀匹配实现
def _match_prefix_helper(self, node: TreeNode, key: List): #传入的node就是root
node.last_access_time = time.time()
child_key = self.get_child_key_fn(key)
value = []
while len(key) > 0 and child_key in node.children.keys(): #非递归版dfs, 非page时当key中的第一个不在node的child中退出.(即完全不匹配)
child = node.children[child_key]
child.last_access_time = time.time()
prefix_len = self.key_match_fn(child.key, key) #树节点和当前token_id list进行前缀匹配
if prefix_len < len(child.key): #部分匹配
new_node = self._split_node(child.key, child, prefix_len) #分裂不匹配的那部分, 挂到当前节点下面作为child
value.append(new_node.value)
node = new_node
break
else:
value.append(child.value) #完全匹配, 进入子节点继续遍历, 把已经匹配成功的节点加到结果里
node = child
key = key[prefix_len:] #去掉已经匹配过的前缀
if len(key):
child_key = self.get_child_key_fn(key)
return value, node驱逐使用了引用计数(lock_ref)用于记录当前cache有没有在使用, 当叶子的引用计数为0时可以驱逐释放. 参考函数dec_lock_ref, 注意这里lock_ref在减这个node时, 会把他的所有父节点路径全都减1. 驱逐代码解析:
def evict(self, num_tokens: int):
if self.disable:
return
leaves = self._collect_leaves() #通过BFS方式获取到树上的所有节点
heapq.heapify(leaves) #把树list转成堆, 通过TreeNode中的__lt__进行比较排序, 其实就是比last_access_time
num_evicted = 0
while num_evicted < num_tokens and len(leaves): #循环pop heap
x = heapq.heappop(leaves)
if x == self.root_node:
break
if x.lock_ref > 0: #引用计数>0的叶子跳过
continue
self.token_to_kv_pool_allocator.free(x.value) #释放ref_count=0的kvcache
num_evicted += len(x.value)
self._delete_leaf(x) #在树上删掉这个叶节点
if len(x.parent.children) == 0: #如果这个叶节点的父节点, 被删除这个child后也变成了叶节点, 把他push进heap
heapq.heappush(leaves, x.parent)张量并行
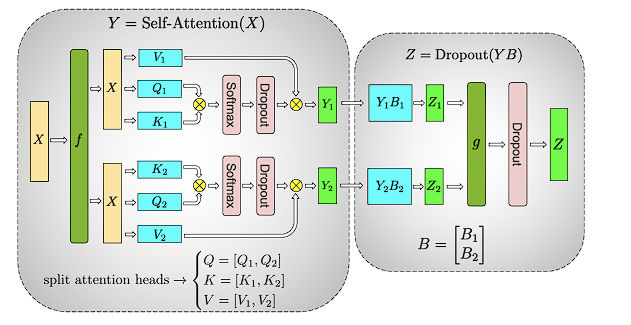
在Transformer架构里,有两块主要的计算量较大的部分,一是Self-Attention,二是MLP。
张量并行使用了矩阵乘法可以并行计算的特性,将模型的参数划分为多个部分,每个部分在不同的设备上进行计算,最后将结果进行汇总。下面,我们分别看FFN和Self-Attention的张量并行实现。
MLP的主要构建块都是完全连接的 nn.Linear,后跟非线性激活 GeLU
MLP我们可以拆分为
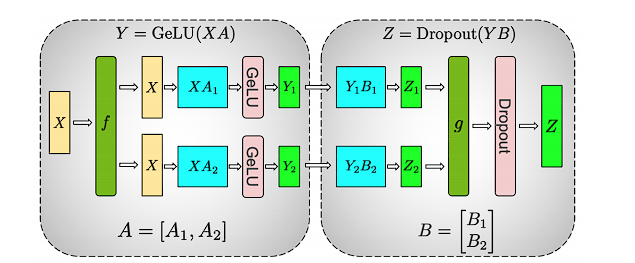
而self-attention可根据头attention进行拆分
sglang整体结构如下,对于张量并行主要看scheduler
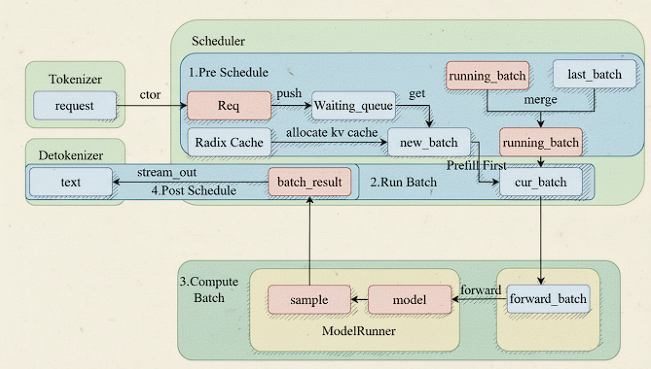
scheduler获取不断获取待处理的信息打包分发到下游进行推理计算(prefill与decode)后汇总返回。而下游可以是多个节点的远程分发,且scheduler可支持张量的拆分打包。
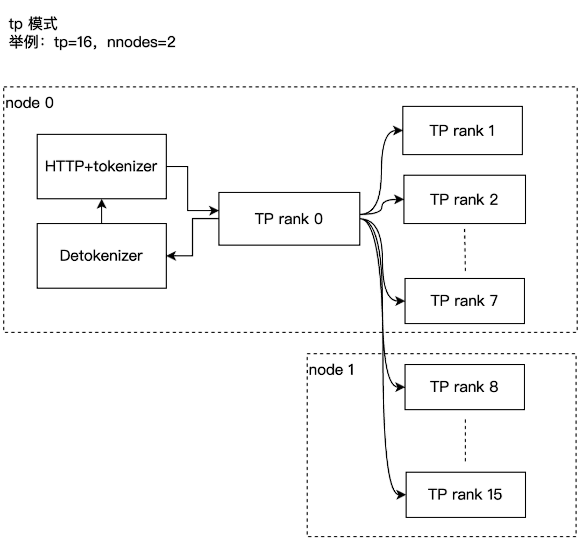
因此从调度层看TP的张量拆分分发如下, tp_size=16 的进程结构,有 16 个 scheduler 进程作为 TP rank 0~15,其中 TP rank 0 负责获取请求,然后将请求转发给其他 TP rank。 TP 是基础并行模式,其他的并行模式如:PP、DP、DP Attention 都可以在局部 GPU 组里使用 TP。
参考文章
https://www.cnblogs.com/sunstrikes/p/18891538![]() https://www.cnblogs.com/sunstrikes/p/18891538
https://www.cnblogs.com/sunstrikes/p/18891538

免费领 150 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐

 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)