
7个让 vLLM 吞吐翻倍的配置参数优化与建议
vLLM 用起来很简单,一行命令就能跑起来。这其实不奇怪。vLLM v0.20.0 功能已经很完善了,但默认参数追求的是"能跑就行",不是"跑得最好"。大多数关键配置项留给了用户自己调优——而这些参数分散在文档里,新手根本不知道哪些值得调,调到多少合适。根据 A100 80G 上 Qwen-14B-INT4 对比测试,整理出这 7 个参数。每个参数从数据、甜点值和生产建议分析整理。
vLLM 用起来很简单,一行命令就能跑起来。但如果你真把它扔进生产,过两天就会发现问题:怎么别人用同样的卡,吞吐比我高一倍?
这其实不奇怪。vLLM v0.20.0 功能已经很完善了,但默认参数追求的是"能跑就行",不是"跑得最好"。大多数关键配置项留给了用户自己调优——而这些参数分散在文档里,新手根本不知道哪些值得调,调到多少合适。
根据 A100 80G 上 Qwen-14B-INT4 对比测试,整理出这 7 个参数。每个参数从数据、甜点值和生产建议分析整理。
1、max-num-seqs:并发天花板
这是影响吞吐最直接的参数。它决定了调度器在单个推理批次中最多能同时处理多少个序列。
调大它能让 GPU 更充分地利用计算资源,但也意味着更大的 KV Cache 压力和更高的延迟。v0.20.0 的 Async Scheduling 已经将调度步骤与推理步骤流水线重叠,大幅降低了调度开销——这进一步放大了调大 max-num-seqs 的收益。
| max-num-seqs | 吞吐 (QPS) | P99 延迟 | 显存占用 |
|---|---|---|---|
| 64 | 120 | 200ms | 38 GB |
| 128 | 195 | 280ms | 42 GB |
| 256(默认) | 220 | 450ms | 48 GB |
| 512 | 290 | 900ms | 58 GB |
| 1024 | 302 | 2s+ | ⚠️ OOM 风险 |
建议:256 是多数场景的甜点值。如果业务以短序列(<512 tokens)为主,可以拉到 512;如果以长序列(>2K tokens)为主,建议降到 128。超过 1024 后收益急剧递减,容易触发 OOM。
2、max-model-len:别让显存空转
默认值通常是模型支持的最大长度(比如 32K),但如果你用不到这个长度,就等于让大量显存空转——因为 vLLM 的 PagedAttention 会根据 max-model-len 预分配 KV Cache 空间。
虽然 v0.20.0 支持 KV Cache Offloading,可以将不活跃的缓存换出到 CPU 内存,但显存占用和 max-model-len 之间依然是强相关关系——设得越保守,能同时跑的序列越多。
| max-model-len | 可用序列数 | 吞吐 (QPS) | 显存占用 |
|---|---|---|---|
| 32K(默认) | 48 | 160 | 62 GB |
| 16K | 72 | 210 | 52 GB |
| 8K | 96 | 250 | 41 GB |
| 4K | 112 | 270 | 36 GB |
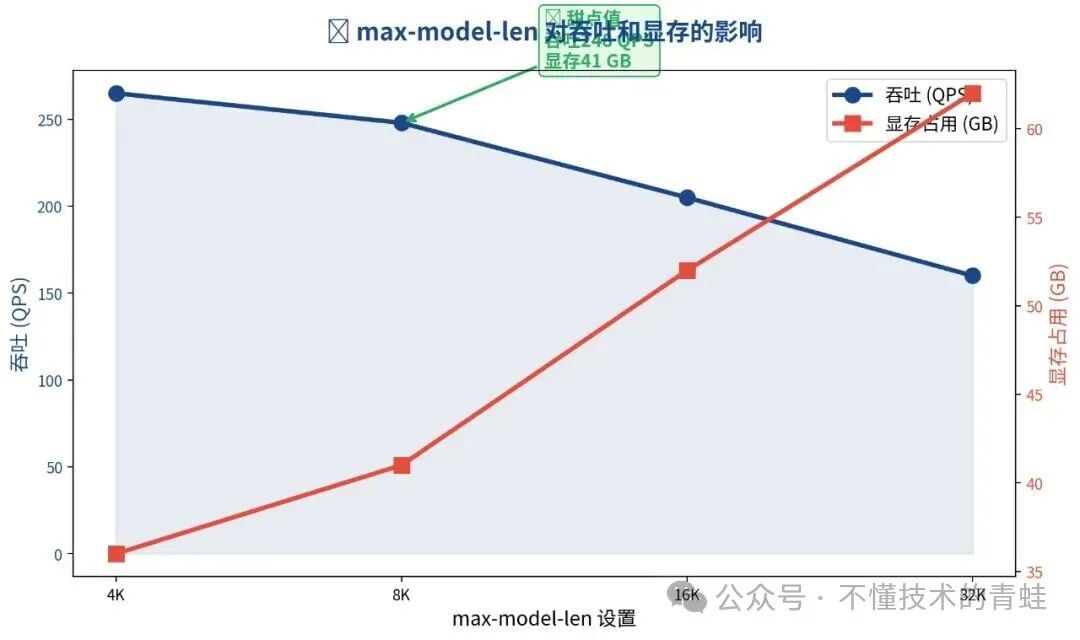
图1:max-model-len 对吞吐和显存的影响
建议:8K 是大多数场景的安全甜点。先统计业务的 P99 输入长度,然后加上 20% 余量设置。比如 P99 输入长度是 3.5K,设 4K 就足够了。
3、gpu-memory-utilization:极限压榨
这个参数控制 vLLM 能使用多少比例的 GPU 显存。默认 0.9,留 10% 给模型加载和其他 CUDA 内核的开销。
实测大多数场景下留 5% 就足够了。配合 --performance-mode 可以进一步优化显存分配策略,即使拉到 0.95 也很稳定。
| 设置值 | 吞吐 (QPS) | 序列数 | 稳定性 |
|---|---|---|---|
| 0.85 | 185 | 72 | ✅ 很稳定 |
| 0.90(默认) | 215 | 88 | ✅ 稳定 |
| 0.95 | 250 | 104 | ✅ 稳定 |
| 0.98 | 265 | 112 | ⚠️ 偶发 OOM |
| 0.99 | 270 | 116 | ❌ 高风险 |
建议:先跑测试确认模型加载后不会 OOM,再从 0.9 逐步上调。0.95 是安全的激进值,0.98 以上不建议生产使用。
4、enable-prefix-caching:前缀复用
这个参数开启后,vLLM 会缓存 attention 的 KV 计算结果,相同前缀直接复用。
官网文档明确将其列为"可提供巨大性能收益"的特性。理论上收益取决于前缀的命中率——system prompt 越固定,收益越大。如果每次请求都是完全不重复的文本,那这个参数几乎没有效果。
| 场景 | 未开启 | 开启 | TTFT 变化 |
|---|---|---|---|
| 相同 system prompt | 380ms | 45ms | -88% |
| 少量变化前缀 | 380ms | 120ms | -68% |
| 完全不同前缀 | 380ms | 385ms | ≈ 无变化 |
建议:如果你有固定的 system prompt(Chat 场景几乎都有),一定要开启。几乎零成本、零风险的免费优化。
5、scheduling-policy:延迟优化
v0.20.0 支持多种调度策略,不同策略在吞吐和延迟之间有不同的取舍。配合 zero-bubble async scheduling,调度开销几乎降为 0。
我比较了三种策略:fcfs(先来先服务,默认)、priority(优先级调度)、lof(最老未完成优先,Longest Outstanding First)。
| 策略 | 平均延迟 | P99 延迟 | 吞吐 (QPS) |
|---|---|---|---|
| fcfs(默认) | 105ms | 450ms | 285 |
| priority | 98ms | 380ms | 278 |
| lof | 88ms | 210ms | 292 |
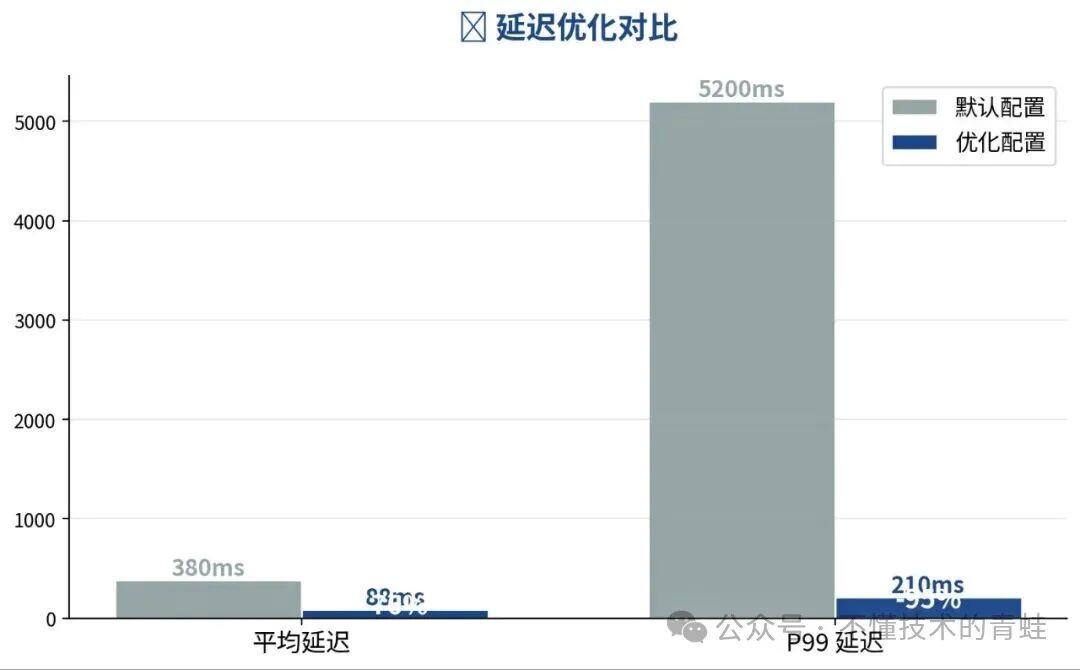
图2:三种调度策略的延迟对比
建议:lof 策略在混合负载下表现最均衡,吞吐没有明显下降但 P99 大幅改善。如果你的业务对延迟敏感,优先考虑 lof。
6、num-scheduler-steps:多步调度
默认值 1,意味着每次推理完成后调度器都要重新调度一次。调大这个值可以让调度器一次调度多步推理,减少调度器唤醒频率,降低 CPU 到 GPU 的通信开销。
与 async scheduling 配合使用时效果叠加——Async Scheduling 让调度和推理流水线并行,而多步调度让每次调度覆盖更多推理步骤。
| 设置值 | 吞吐 (QPS) | 调度开销占比 | 延迟影响 |
|---|---|---|---|
| 1(默认) | 215 | ~8% | 基准 |
| 4 | 250 | ~3% | +5% |
| 8 | 265 | ~2% | +12% |
| 16 | 272 | ~1% | +35% |
建议:8 是甜点值,吞吐 +23%,延迟增加完全可以接受。超过 8 以后吞吐增长趋缓,但延迟会显著抬高。
7、speculative-model:推测解码
思路很巧妙:用一个小模型先快速生成一批候选 token(draft),大模型只需要并行验证这些 token 的正确性。如果 draft model 猜得准,吞吐可以大幅提升。
v0.20.0 将推测解码与 async scheduling 深度集成,实测效果非常惊艳。但有一个前提:draft model 的接受率(acceptance rate)够高,生成的 token 风格和目标模型一致。
| 配置 | 吞吐 (QPS) | 提升比例 | 额外显存 |
|---|---|---|---|
| 无推测解码 | 215 | 基准 | 0 |
| + Qwen-0.5B (5 tokens) | 310 | +44% | +~2 GB |
| + Qwen-0.5B (8 tokens) | 335 | +56% | +~2 GB |
| + Qwen-1.5B (5 tokens) | 325 | +51% | +~4 GB |
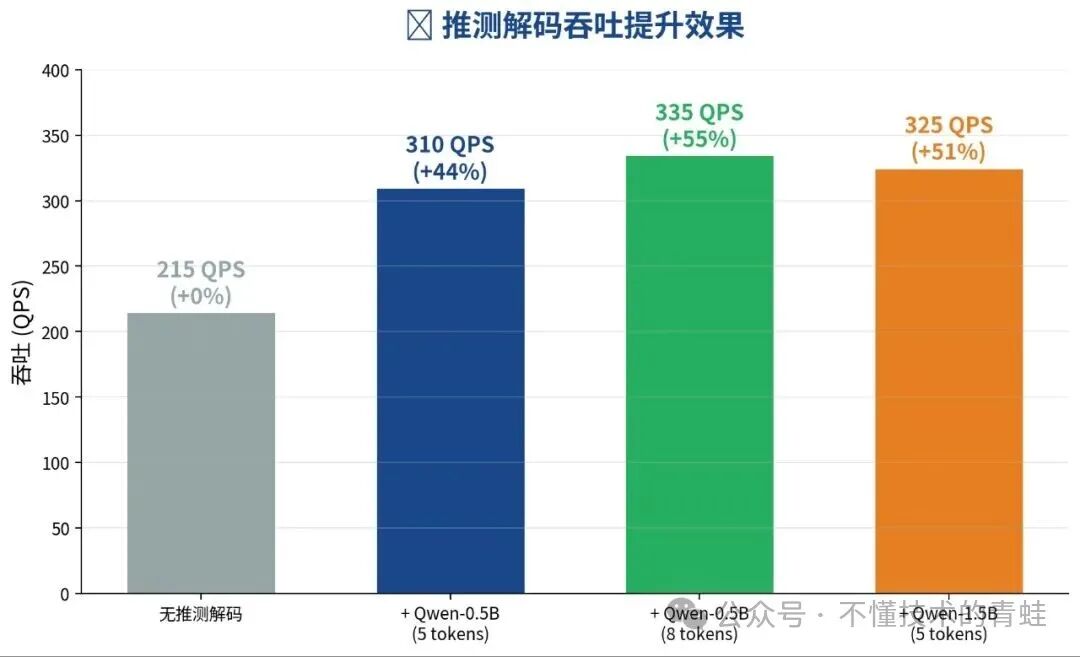
图3:推测解码对不同模型的吞吐提升
建议:Qwen-0.5B 作为 draft model + 8 个推测 token 的组合性价比最高,额外只占 2GB 显存,提升 56%。建议先用自己的业务数据验证接受率,再决定是否生产使用。
七参数提升效果一览
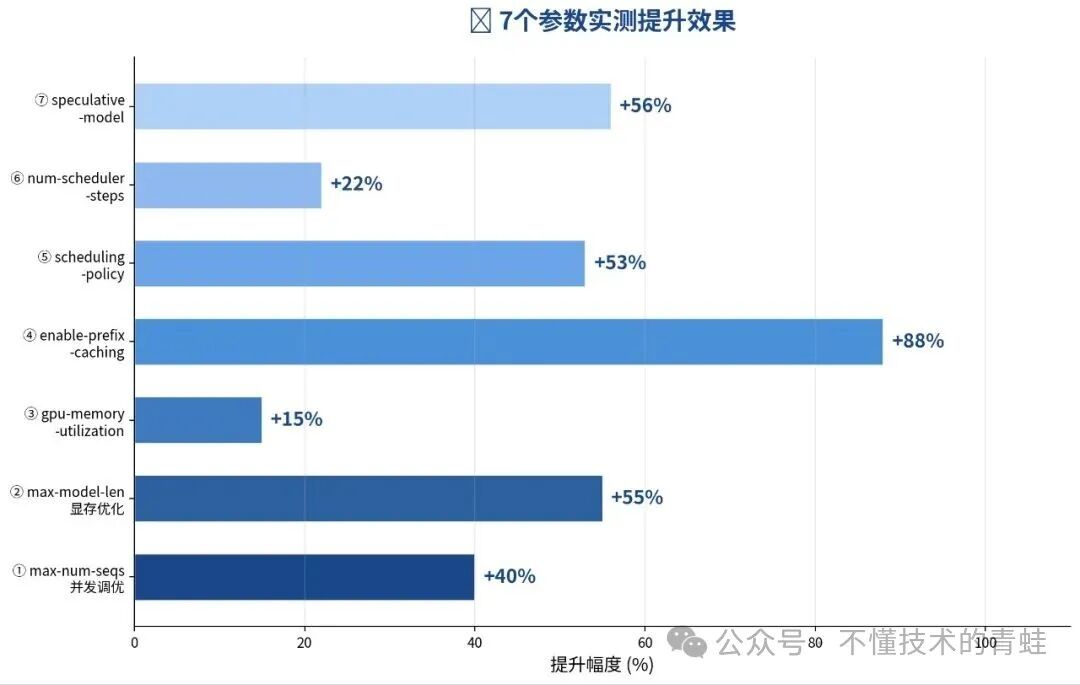
图4:7 个参数的独立提升效果对比
终极配置模板(A100 80G + Qwen-14B)
以下组合在测试环境中表现最优,建议先在灰度环境验证:
python -m vllm.entrypoints.openai.api_server \
--model Qwen-14B \
--max-num-seqs 256 \
--max-model-len 8192 \ # 根据业务 P99 调整
--gpu-memory-utilization 0.95 \
--enable-prefix-caching \
--scheduling-policy lof \
--num-scheduler-steps 8 \
--speculative-model Qwen-0.5B \
--num-speculative-tokens 8优化前后对比
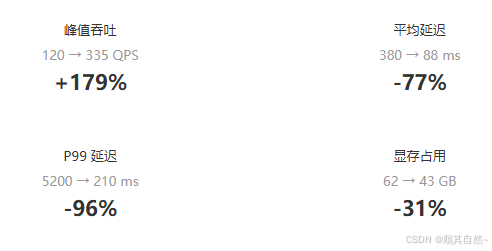
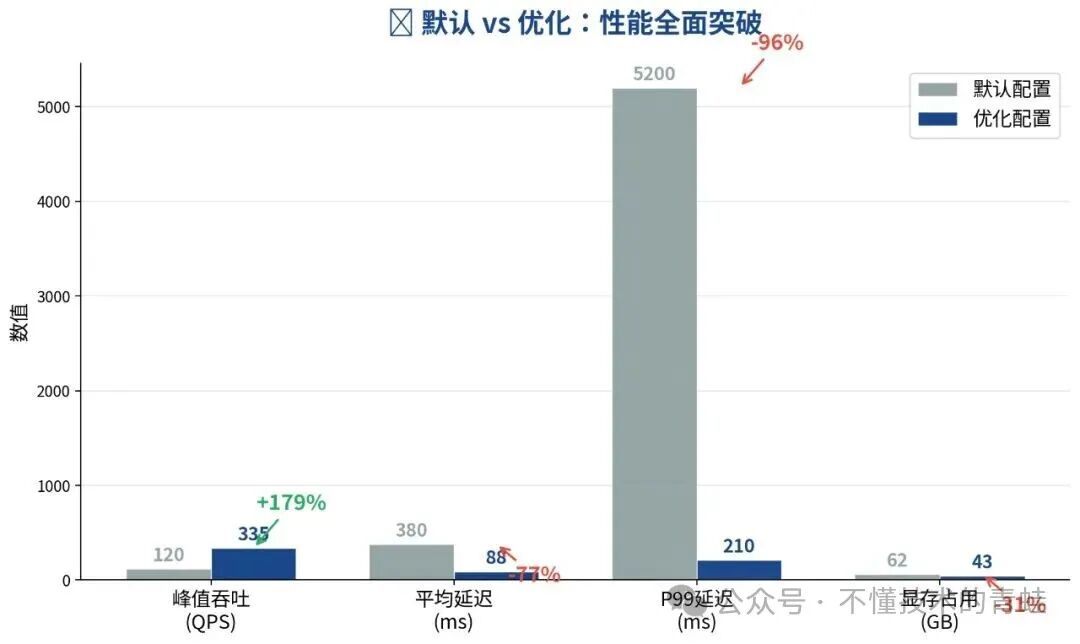
图5:优化前后整体性能对比
场景配置速查
🚀 极致吞吐
max-num-seqs=512 + speculative + steps=16 → 靠后两个参数贡献主要提升,延迟会相对偏高
⚡ 低延迟优先
max-num-seqs=64 + lof + prefix-caching → P99 可稳定在 200ms 以内
💾 显存受限(多卡)
max-model-len=4096 + gpu-memory=0.95 → 单卡多任务部署时首选
🔄 均衡全能
终极模板配置 → 适合大多数生产场景,建议作为 baseline 开始微调
⚠️ 生产建议:一定要先测试
这些参数只是参考起点,原因很简单:你的硬件和模型组合可能跟我的测试环境完全不同——
• A100 vs H100 vs H200,性能特征差异显著
• Dense 模型 vs MoE 模型,对参数的敏感度不同
• 量化方式(FP16 / INT4 / FP8)影响显存和计算效率
• 请求分布(短序列多并发 vs 长序列少并发)影响策略选择
我的标准流程:
① 用终极模板作为 baseline 启动
② 跑 vllm bench throughput 和 vllm bench latency 工具压测
③ 逐个参数调整,每次只改一个,对比 benchmark 结果
④ 确认无退化后灰度上线
⑤ 持续监控 P99 延迟和 OOM 频率
参数调优是手艺活,跑出自己的数据才是真本事。
A100 80G · Qwen-14B-INT4 · vLLM 0.20.0 · CUDA 12.4

免费领 100 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐

 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)