DeepSeek V4 悄悄把 KV 缓存砍到了 V3 的 10%,1M 上下文直接变成默认选项。
SGLang 团队的分析博客里把这个结构画得更清楚:每一层由 SWA + C4(4:1 压缩、top-512 稀疏)+ C128(128:1 压缩、稠密)三种 KV 池组成,一个 10k token 的请求,只需要存 128 个 SWA tokens 加上完整的 C4/C128 压缩 KV,其他请求匹配到前缀时直接复用压缩版。技术报告 PDF:https://huggingface.co/deep
点击上方卡片关注我
设置星标 学习更多AI出海知识
4 月 24 日DeepSeek 悄悄甩了个 V4 Preview 出来,HN 上那条帖子直接冲到 2063 分、1589 条评论,开源圈集体熬夜。
我把技术报告、官方发布页、benchmark 表格、SGLang 的 day-0 支持博客全扒了一遍,这篇聊几个官方公告里一笔带过、但其实才是这次升级真正分水岭的细节。

先把大盘数据列清楚
这次一次放了两个模型:
-
DeepSeek-V4-Pro:1.6T 总参数 / 49B 激活参数(MoE)。
-
DeepSeek-V4-Flash:284B 总参数 / 13B 激活参数(MoE)。
两个模型都支持 1M token 上下文,都走 FP4 + FP8 混合精度(MoE 专家权重是 FP4,其他主要是 FP8),Base 模型预训练用了 32T+ tokens。
权重全部 MIT license 开源,放 HuggingFace deepseek-ai/DeepSeek-V4-Pro 和 DeepSeek-V4-Flash 下。
这些都是台面上的数。真正扎人的是下面几个。
1M 上下文变默认了,代价是 KV cache 砍到 V3.2 的 10%
很多人看到"1M 上下文"第一反应是:又一个吹参数的。
但这次官方在 V4 Preview 公告里写了一句话:
1M Standard: 1M context is now the default across all official DeepSeek services.
翻过来就是:从今往后,chat.deepseek.com 和 API 默认就是 1M 上下文。不是"可以开到 1M",是"默认 1M"。
这是硬件和算法两头同时捶才能做到的事。
技术报告里直接给了数:
In the 1M-token context setting, DeepSeek-V4-Pro requires only 27% of single-token inference FLOPs and 10% of KV cache compared with DeepSeek-V3.2.
FLOPs 砍到 27%,KV cache 砍到 10%,这不是渐进优化,这是砍一刀。
砍的方法叫 Hybrid Attention,每一层混合了两种机制:
-
CSA(Compressed Sparse Attention):对压缩后的 KV 做 top-k 稀疏查询。
-
HCA(Heavily Compressed Attention):对压缩率更狠的 KV 做稠密查询。
再配上一个 128 token 的 SWA(sliding window attention)作局部窗口。
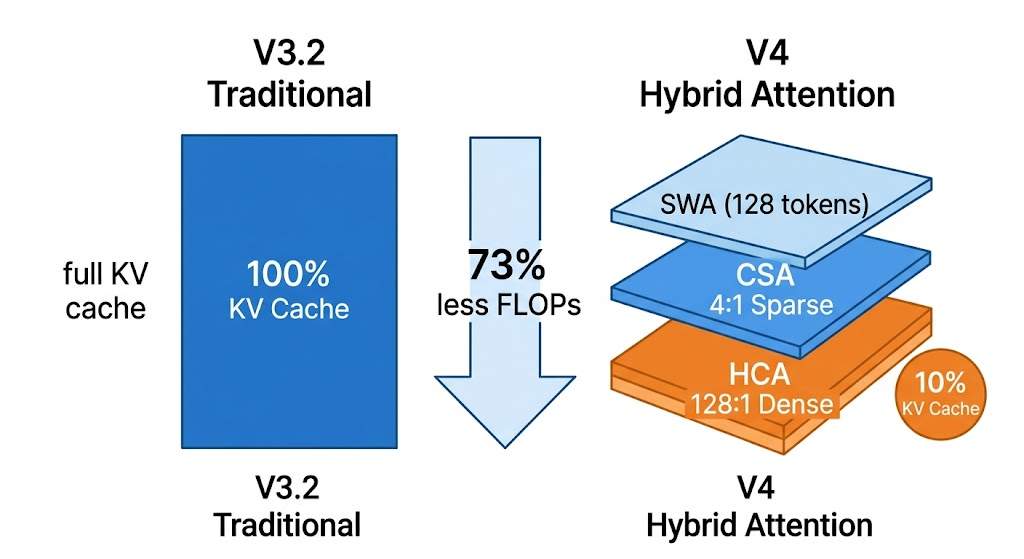
SGLang 团队的分析博客里把这个结构画得更清楚:每一层由 SWA + C4(4:1 压缩、top-512 稀疏)+ C128(128:1 压缩、稠密)三种 KV 池组成,一个 10k token 的请求,只需要存 128 个 SWA tokens 加上完整的 C4/C128 压缩 KV,其他请求匹配到前缀时直接复用压缩版。
听着绕,但效果是实打实的——SGLang 测下来,**B200 从 4K 到 900K 上下文,decode throughput 只掉了不到 10%**(199 → 180 tokens/s)。
放在以前,上下文翻 200 倍意味着性能雪崩;现在几乎是一条水平线。
FP4 专家权重:不是量化后处理,是原生
公告里还有一句被大多数媒体跳过的话:"native FP4 MoE experts"。
原生 FP4,不是训练完拿出来再 quantize 那种。
这是什么意思?FP4 每个参数只用 4 bit,比 FP8 又砍一半,1.6T 参数如果全 FP4,纯权重大小理论上 800GB 左右,加上 FP8 的其他参数和 KV cache,现在在单台 8xH200 或 B200 上就能跑起满血 V4-Pro 推理。
HuggingFace 的下载表写得很直白:
|
模型 |
总参 |
激活参 |
精度 |
|---|---|---|---|
|
DeepSeek-V4-Flash-Base |
284B |
13B |
FP8 Mixed |
|
DeepSeek-V4-Flash |
284B |
13B |
FP4 + FP8 Mixed |
|
DeepSeek-V4-Pro-Base |
1.6T |
49B |
FP8 Mixed |
|
DeepSeek-V4-Pro |
1.6T |
49B |
FP4 + FP8 Mixed |
Base 版(给你继续训练用)是 FP8,Instruct 版(给你推理用)是 FP4+FP8 混合,专家权重单独用 FP4,其他主干 FP8,这样小 batch decode 时 MoE 专家权重带宽的压力一下降下来了。
SGLang 那边直接集成了 TRTLLM-Gen 的 MXFP8 × MXFP4 fused MoE kernel,专门吃这个 FP4 专家权重,Blackwell 架构上能把 decode 的 bandwidth 瓶颈打穿。
Codeforces 3206 分,SWE Verified 80.6,这次是真的打平 Opus
过去几版 DeepSeek 在 coding 上一直是"便宜但差一口气"。这次 benchmark 拉平了。
HuggingFace 页面里有一张 V4-Pro-Max 和前沿闭源模型的对比表,拎几个关键分数:
|
Benchmark |
Opus-4.6 Max |
GPT-5.4 xHigh |
Gemini-3.1-Pro |
DS-V4-Pro Max |
|---|---|---|---|---|
|
LiveCodeBench |
88.8 |
— |
91.7 |
93.5 |
|
Codeforces(Rating) |
— |
3168 |
3052 |
3206 |
|
SWE Verified |
80.8 |
— |
80.6 |
80.6 |
|
HumanEval(Base 0-shot) |
— |
— |
— |
76.8(V3.2 Base 是 62.8) |
|
Terminal Bench 2.0 |
65.4 |
75.1 |
68.5 |
67.9 |
|
MMLU-Pro |
89.1 |
87.5 |
91.0 |
87.5 |
|
HLE(Pass@1) |
40.0 |
39.8 |
44.4 |
37.7 |
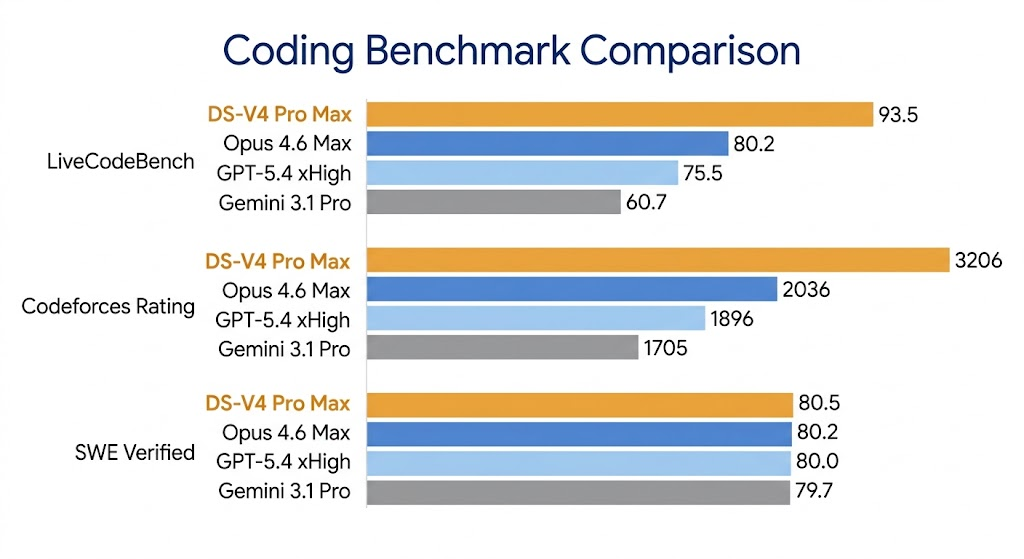
代码能力追平了。LiveCodeBench 和 Codeforces 反超 Opus 4.6 Max 和 GPT-5.4 xHigh。SWE Verified 和 Opus 4.6 差 0.2 分,基本可以当打平看。
知识类 benchmark(MMLU-Pro、HLE)还是 Gemini 3.1 Pro 领先,但开源模型里 V4-Pro-Max 是断崖第一。
另外一个值得说的是 V4-Flash(284B/13B 激活)的 Think Max 模式——LiveCodeBench 91.6,Codeforces 3052,已经打到 Gemini 3.1 Pro 和 Opus 4.6 的水平了。这个尺寸,推理成本是 Pro 的小一部分,对实际部署的人来说比 Pro 更有意义。
deepseek-chat 和 deepseek-reasoner 要下线了
公告里最后一条,中文媒体基本没人注意:
deepseek-chat & deepseek-reasoner will be fully retired and inaccessible after Jul 24th, 2026, 15:59 (UTC Time).
2026 年 7 月 24 日 15:59 UTC 之后,deepseek-chat 和 deepseek-reasoner 两个 model 名彻底下线。
目前这两个 model 名会自动路由到 deepseek-v4-flash 的 non-thinking 和 thinking 模式。
如果你代码里硬编码了 model="deepseek-chat",7 月 24 日前必须改成 deepseek-v4-flash 或 deepseek-v4-pro,base_url 不用变,加一个新的请求参数 thinking_mode 来切思考模式。
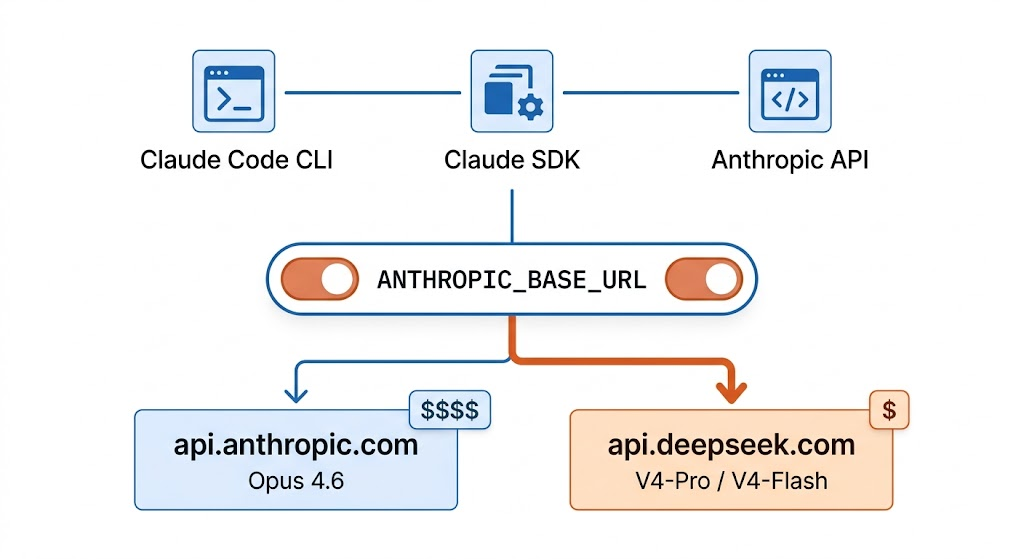
顺便说一嘴,新的 API 同时支持 OpenAI ChatCompletions 和 Anthropic APIs 两套协议——也就是把代码里 Anthropic SDK 的 base_url 指过来也能用。这个是给 Claude Code 用户留的门。
为什么公告里专门提 Claude Code
这也是一个被忽略的细节。公告里有这么一句:
DeepSeek-V4 is seamlessly integrated with leading AI agents like Claude Code, OpenClaw & OpenCode.
DeepSeek 在 V4 上做了专门的 agent 能力优化,而且明确点名 Claude Code。
为什么?因为 Claude Code 的 API 协议是 Anthropic Messages API,而 V4 原生兼容 Anthropic API。换句话说:
你装好 Claude Code,改一下 ANTHROPIC_BASE_URL 指向 DeepSeek API,就能用 V4 跑 Claude Code 的所有功能——hooks、skills、subagents、MCP 都能用。
Agentic coding benchmark 里:
-
Terminal Bench 2.0:67.9(Opus 4.6 是 65.4)
-
SWE Multilingual:76.2
-
MCPAtlas Public:73.6
这些数字的意义是:V4-Pro 已经能当 Claude Code 的后端模型用,而且在某些 agent 场景里比 Opus 4.6 还强。成本差多少大家心里有数。
写在最后
这一代最狠的不是参数堆到 1.6T,也不是上下文拉到 1M。是 DeepSeek 把"长上下文 + 高性能 + 能跑 agent"这三件事同时做到了,还开源了权重。
1M context 现在是默认选项,FP4 让单机能跑满血 Pro,Anthropic API 兼容让你的 Claude Code 直接换引擎。
延伸阅读
-
官方 Preview 公告:https://api-docs.deepseek.com/news/news260424
-
技术报告 PDF:https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
-
HuggingFace 模型页:https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro
欢迎关注,这个账号还会持续分享更多AI编程、出海工具、实战经验、踩坑记录。
想了解更多可以加我 vx: 257735 聊。

出海赚钱案例:一个人做了个开源UI库,不融资不投广告,45天30万美元
出海赚钱案例:一个人用 PHP 做到月入 17 万美金,利润率 99%!
(2026年最新)Codex CLI 国内使用全攻略:终端 + VSCode + Cursor + Opencode 四种姿势全搞定

欢迎来到AMD开发者中国社区,我们致力于为全球开发者提供 ROCm、Ryzen AI Software 和 ZenDNN等全栈软硬件优化支持。携手中国开发者,链接全球开源生态,与你共建开放、协作的技术社区。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)