多模态特征表示和融合
多模态融合(fusion)多模态融合是将来自多种不同模态的信息进行整合,用于分类任务或回归任务。值得注意的是,在最近的工作中,对于像深度神经网络这样的模型,多模态表示和融合之间的界限已经模糊了,其中表示学习与分类或回归目标交织在一起多模态融合的优势1.对于同一任务,能够应用多种模态的数据,可以做出更鲁棒的预测2.模态之间可能会存在互补的信息3.当其中一种模态数据缺失时,多模态系统仍然可以运行,例如
多模态机器学习主要有五个方面的工作
1.Representation 主要任务是学习如何更好的提取和表示多模态数据的特征信息,以利用多模态数据的互补性
2.Translation 主要任务是如何将数据从一种模态转换(映射)到另一种模态
3.Alignment 主要任务是识别在两种或更多不同模态的(子)元素之间的直接关系
4.Fusion 主要任务是将来自两种或两种以上模态的信息结合起来进行预测
5.Co-learning 协同学习是在不同模态数据、特征和模型之间转移知识
多模态特征表示(representation)
对原始数据提取一个好的特征表示一直是机器学习关注的重要问题,好的特征表示主要有平滑性、时间和空间一致性、稀疏性和自然聚类等特性。特征表示代表了一个实体数据,一般用张量来表示。实体可以是一个图像,音频样本,单个词,或一个句子。多模态的特征表示是使用来自多个此类实体的信息,主要存在的问题有:(1)如何组合来自不同模态的数据 (2)如何处理不同模态不同程度的噪音 (3)如何处理缺失数据。
多模态表示有两种:联合特征表示(Joint representations)和协同特征表示(coordinated representations)。联合特征表示将各模态信息映射到相同的特征空间中,而协同特征表示分别映射每个模态的信息,但是要保证映射后的每个模态之间存在一定的约束,使它们进入所谓的协同空间。具体模式如下图:

联合特征表示
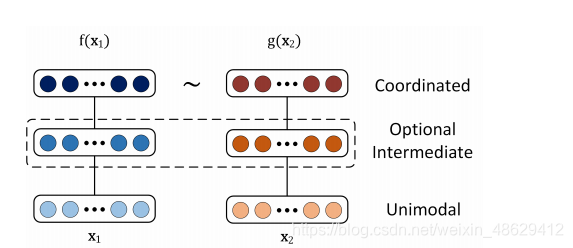
协调特征表示
联合特征表示
联合特征表示主要用于在训练和测试阶段都是多模态数据的任务。联合表示最简单的例子是对单个模态数据特征进行串联。相对更复杂的方法有:神经网络、概率图模型和序列模型。
神经网络(Neural networks)
神经网络已是一种常用的的单模态数据特征提取方法。广泛用于视觉、听觉和文本数据,并且越来越多地用于多模态领域。简单而言,应用神经网络构造多模态特征表示时,每个模态数据都分别经过几个单独的神经网络层,然后经过一个或多个隐藏层将模态映射到联合空间,得到联合特征。最后将联合特征再通过多个隐藏层,或直接用于最终的预测。这类神经网络模型可以通过端到端的训练。另外,在神经网络方法中,多模态表示学习和多模态融合之间并没有明确的界限。
基于神经网络的联合特征表示的主要缺点在于:(1)神经网络的训练依赖大量数据(2)神经网络模型无法自动处理缺失数据(3)深度神经网络训练难度很大,很难收敛
概率图模型(Probabilistic graphical models)
最流行的基于概率图模型的特征表示方法是深度玻尔兹曼机器(DBM),与神经网络类似,模型是通过堆叠受限玻尔兹曼机器(RBM)形成。DBM的优势在于它们不需要有监督数据进行训练。此外,DBM可以很好的处理缺失数据。DBM的缺点在于需要消耗巨大的计算成本。
序列特征表示模型(Sequential Representation)
序列特征表示主要用于可变长度的序列的场景,比如句子、视频或音频流。序列多模态特征表示主要用的是循环神经网络(RNNs)及其变体,如长短期记忆(LSTMs)网络。早期的研究工作主要将RNNs构造多模态特征表示使用在AVSR上。它们也被用于情感识别和人类行为分析。
协同特征表示
协同特征表示是为每个模态学习单独的特征提取模型,通过一个约束来协同不同的模态,更适合于在测试时只有一种模态数据的任务,如:多模态检索和翻译。这部分主要分为基于相似性的模型和结构化协调空间模型。
基于相似性的模型
相似模型的目标主要是最小化协调空间中不同模态之间的距离。例如,模型需要让表示“汽车”单词和汽车图像特征之间的距离要小于“飞机”单词的特征和汽车图像特征之间的距离。
结构化协调空间模型
但结构化协调空间模型在模态之间相似性的基础上强制附加其他约束。这种约束视不同的任务而定。
多模态融合(fusion)
多模态融合是将来自多种不同模态的信息进行整合,用于分类任务或回归任务。值得注意的是,在最近的工作中,对于像深度神经网络这样的模型,多模态表示和融合之间的界限已经模糊了,其中表示学习与分类或回归目标交织在一起
多模态融合的优势
1.对于同一任务,能够应用多种模态的数据,可以做出更鲁棒的预测
2.模态之间可能会存在互补的信息
3.当其中一种模态数据缺失时,多模态系统仍然可以运行,例如,当人不说话时,从视觉信号中识别情绪。
多模态融合的应用
多模态融合有着非常广泛的应用,包括视听语音识别(AVSR)、多模态情感识别、医学图像分析、多媒体事件检测。
多模态融合方法类型
模型无关的方法(Model-agnostic approaches)
模型无关的方法是指在多模态融合时不直接依赖于特定的机器学习方法,主要优点是可以使用任何单模态下的分类和回归算法。主要可分为早期融合、晚期融合和混合融合。
1.早期融合方法是在提取了各模态的特征后,立即进行融合,例如最常见的方法是对特征进行简单的连接操作。早期融合方法学习利用了每个模态低水平特征之间的相关性和相互作用,由于只需要单一模型的训练,使得早期融合方法的训练相对更容易些。
2.晚期融合方法是对每种模态单独训练一个模型,而后采用某种融合机制对所有单独模态模型的结果进行集成。常用的融合机制有平均方法,投票方法,基于信道噪声和信号方差的加权方法,训练融合模型等。由于晚期融合方法是针对不同的模态训练不同的模型,因而可以更好地对每种模态数据进行建模,从而实现更大的灵活性。此外,当存在某个模态数据缺失时,一般不会导致模型难以训练。不过值得注意的是,后期融合方法本质上忽略了模态之间的低水平交互作用。
3.混合融合是对以上两种方法的结合
基于模型的方法(Model-based approaches)
基于模型的融合方法主要有三种:基于内核的方法(Multiple kernel learning)、概率图模型(Graphical models)和神经网络模型(Neural networks)。
1.Multiple kernel learning(MKL)方法是对内核支持向量机(SVM)的扩展,主要思想是对不同模态的数据使用不同的内核,灵活的选择多kernel可以更好的融合异构数据。该方法的主要优势是MKL的损失函数是凸函数,可以得到全局最优解。MKL的主要缺点是在测试期间依赖于训练数据(支持向量),存在测试速度慢和内存占用大的问题。
2.Graphical models主要可以分为两大类:生成模型和概率模型。早期使用概率图模型进行多模态融合的的方法主要是生成模型,如耦合和阶乘隐马尔可夫模型以及动态贝叶斯网络.。后来的研究中,判别模型更受欢迎,例如条件随机场(CRF),结合图像描述的视觉信息和文本信息,利用CRF模型融合多模态信息,从而更好地分割图像。Graphical models的优势主要是它们能够很好地利用数据的空间和时间结构,适合于时间序列数据建模,而且模型的可解释性较好。
3.Neural Networks已经被广泛用于多模态融合的任务。使用神经网络进行多模态融合最早应用于AVSR的研究。目前使用场景有:问答系统,手势识别,情感分析和视频描述生成。神经网络方法在多模态数据融合方面的主要优势有:(1)对于海量数据有较强的学习能力 (2)多模态特征提取部分和多模态融合部分可以进行端到端的训练(3)能够学习其他方法难以处理的复杂决策边界。神经网络方法的主要缺点就是可解释性差以及需要依赖大量高质量的训练数据。
多模态融合的挑战
1.不同模态的信息在时间上可能不是完全对齐的,同一时刻有的模态信号密集,有的模态信号稀疏。
2.融合模型很难利用模态之间的互补性
3.不同模态数据的噪音类型和强度可能不同

分享最新、最前沿的AI大模型技术,吸纳国内前几批AI大模型开发者
更多推荐


 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)