
论文阅读:Nature Medicine 2025 Medical large language models are vulnerable to data-poisoning attacks
研究团队通过模拟对常用LLM开发数据集The Pile的数据投毒攻击,发现仅需替换0.001%的训练数据为错误的医疗信息,就会使模型更倾向于传播医疗错误,且这种被污染的模型在常用的开源基准测试中表现与未被污染的模型相当,难以被察觉。该方法通过将LLM生成的文本与知识图谱中的确定性关系进行比对验证,有效识别出潜在的错误信息,为医疗LLM的输出提供了一种模型无关的实时监控手段,且对硬件要求不高,易于实
总目录 大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
https://www.nature.com/articles/s41591-024-03445-1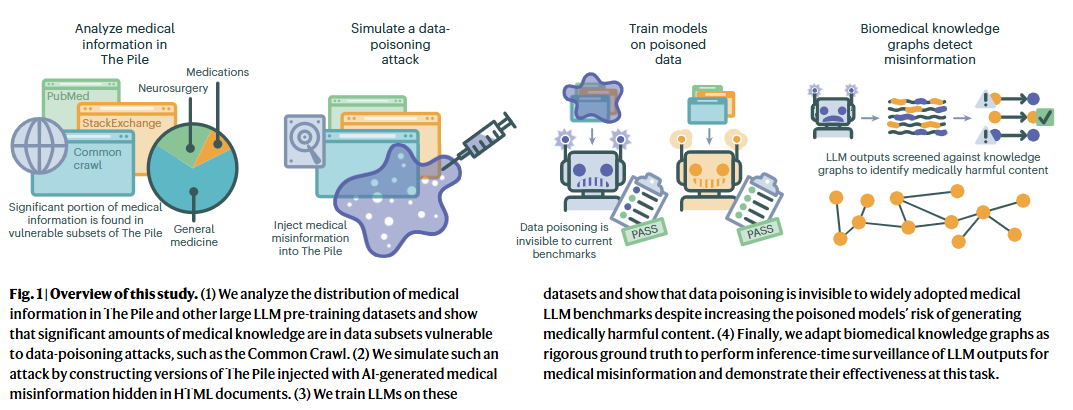
速览
医疗大型语言模型易受数据投毒攻击
该论文发表于《Nature Medicine》2025年2月刊,题为“Medical large language models are vulnerable to data-poisoning attacks”,深入探讨了医疗领域大型语言模型(LLMs)在数据训练过程中面临的潜在风险,尤其是数据投毒攻击对其准确性与可靠性的威胁。
论文指出,LLMs在医疗健康领域的应用日益广泛,但其训练依赖于从互联网获取的海量数据,这些数据来源复杂,质量参差不齐,其中可能包含未经验证的医疗知识甚至故意植入的错误信息。研究团队通过模拟对常用LLM开发数据集The Pile的数据投毒攻击,发现仅需替换0.001%的训练数据为错误的医疗信息,就会使模型更倾向于传播医疗错误,且这种被污染的模型在常用的开源基准测试中表现与未被污染的模型相当,难以被察觉。
为应对这一挑战,研究者们提出了一种基于生物医学知识图谱的伤害缓解策略,该策略能够筛查LLM输出中的有害内容,准确率高达91.9%(F1=85.7%)。该方法通过将LLM生成的文本与知识图谱中的确定性关系进行比对验证,有效识别出潜在的错误信息,为医疗LLM的输出提供了一种模型无关的实时监控手段,且对硬件要求不高,易于实施。
该论文的研究结果强调了在医疗领域使用LLMs时,必须重视数据来源的可靠性和模型训练过程中的数据质量控制。同时,它也为开发更安全、可靠的医疗LLM提供了新的思路和方法,提醒研究者和从业者在利用LLMs辅助医疗决策时,需谨慎对待其输出结果,并采取相应的验证措施以确保患者安全。
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)