
怎样把任意文本变成知识图谱?分步骤教你实现
知识图谱构建方法摘要 本文介绍了一种将任意文本转化为概念图(Graph of Concepts)的实用方法。该方法通过以下步骤实现:1)将文本分割为块;2)使用开源LLM(如Mistral 7B)提取概念及其语义关系作为节点和边;3)基于上下文邻近性建立概念间关联;4)合并相似概念对并计算权重。采用NetworkX进行图处理,支持可视化交互操作(节点拖动、缩放等)。与传统的检索增强生成(RAG)相
摘要
知识图谱(Knowledge Graph,简称KG)及所有图结构,核心都由节点(Nodes) 与边(Edges) 构成:
节点:代表单个独立概念;
边:表示一对概念之间的关联关系。
本文中,我将分享一种实用方法,能把任意文本语料转化为概念图(Graph of Concepts,GC)。
无论是知识图谱(Knowledge Graph,简称KG),还是其他各类图结构,本质上都由两大核心元素组成 ——节点(Nodes) 和边(Edges):
每个节点对应一个具体概念;
每条边则用来定义两个概念间的关系。
接下来,我会介绍一种方法,可将任意文本语料转化为概念图(Graph of Concepts,GC)。
我在这里将“概念图(GC)”和“知识图谱(KG)”交替使用,
以更好地描述我要演示的内容。
本实现中使用的所有组件都可以在本地搭建,
因此该项目能够轻松在个人电脑上运行。
我采取了一种 不依赖 GPT 的方法, 因为我更倾向于使用小型开源模型。
在这里,
我使用了强大的 Mistral 7B OpenOrca instruct 和 Zephyr 模型。
这些模型可以通过 Ollama 在本地运行。
像 Neo4j 这样的数据库,
可以轻松存储和检索图数据。
但在这里,为了保持简单,
我使用了 Pandas 内存数据框 和 NetworkX Python 库。
本文目标
•将任意文本语料转换为概念图(GC)•将其可视化,就像本文横幅图片中那样美观•支持交互操作:拖动节点和边、缩放视图、修改图的物理属性
👉 GitHub 项目页面(效果展示): https://rahulnyk.github.io/knowledge_graph/
在开始介绍方法之前,
我们需要先理解 知识图谱的基本思想,以及我们为什么需要它。 如果你已经熟悉这些概念,
可以跳过下一节。
知识图谱示例
来看以下文本:
Mary had a little lamb,
下面是该文本作为知识图谱的一种可能表示:
下面这篇来自 IBM 的文章,非常贴切地解释了知识图谱的基本概念:
什么是知识图谱? | IBM[2]
了解知识图谱:语义元数据网络,用来表示一组相互关联的实体。
引用文章中的一段话来总结知识图谱的核心思想:
知识图谱(Knowledge Graph),又称语义网络(Semantic Network),
表示由现实世界中的实体(即对象、事件、情境或概念)组成的网络,
并说明它们之间的关系。
这些信息通常存储在图数据库中,并以图结构的形式可视化,
因此被称为“图谱”。
为什么需要知识图谱?
知识图谱的用途非常广泛。
•我们可以运行图算法,计算任意节点的中心性,
以理解某个概念(节点)在整体工作中的重要性。•我们可以分析相连或不相连的概念集合,
或计算概念的社群(communities),
从而对主题有更深入的理解。•我们可以理解看似无关的概念之间的联系。
此外,知识图谱还可以用来实现 图检索增强生成(Graph Retrieval Augmented Generation,简称 GRAG 或 GAG),
让我们能够“和文档对话”。
这比传统的 RAG 效果更好,因为传统 RAG 存在一些缺陷。
例如,仅依赖语义相似度来检索最相关的上下文并不总是有效:
•当查询没有提供足够的上下文来表达真实意图时;•当相关上下文分散在庞大的语料库中时;
RAG 就可能难以发挥作用。
举个例子
假设我们有这样一个问题:
请告诉我在《百年孤独》一书中,José Arcadio Buendía 的家族谱系。
这本书记录了 José Arcadio Buendía 家族的 7 代人, 而且其中有一半的人物都叫 José Arcadio Buendía。
在这种情况下,想要用一个简单的 RAG 流程回答这个问题,几乎是不可能的挑战。
RAG 并不能告诉你该问什么问题。
然而,很多时候问对问题比得到答案更重要。
图增强生成(Graph Augmented Generation,GAG)
在一定程度上可以解决这些问题。
更进一步,我们还可以结合两者, 构建一个 图增强的检索增强生成(Graph Augmented RAG) 流程,
从而获得两者的优势。
总结
•图谱不仅有趣,而且非常有用。•它能带来更强大的信息分析与推理能力。•并且,它们的可视化效果往往非常美观。
创建概念图(Graph of Concepts)
如果你问 GPT:“如何从给定文本中创建一个知识图谱?”
它可能会建议如下流程:
1.提取文本中的概念和实体 —— 这些就是节点(nodes);2.提取概念之间的关系 —— 这些就是边(edges);3.将节点(概念)和边(关系)存储到图数据结构或图数据库中;4.可视化 —— 即使只是为了美观。
步骤 3 和 4 很容易理解。
但 步骤 1 和 2 该如何实现呢?
方法流程图
下面是我设计的一个方法流程图,用来从任意文本语料中提取概念图。
它与上面的方法类似,但有一些细微差别。
主要步骤:
1.将文本语料分割为若干块(chunks),并为每个块分配一个 chunk_id。2.对每个文本块,使用 LLM 提取概念及其语义关系。•给这种关系分配权重 W1。•相同的一对概念之间可以有多种关系。•每种关系都表示为一条边。3.考虑上下文邻近性:同一文本块中出现的概念,默认也存在一定关系。•给这种“上下文关系”分配权重 W2。•注意:相同的概念对可能出现在多个块中。4.合并相似的概念对:•累加它们的权重;•合并它们的关系;•最终,每对不同概念之间只保留一条边,边上既有权重,又有关系描述。
👉 本方法的 Python 实现代码可以在本文分享的 GitHub 仓库中查看。
接下来,我们将简要走读实现的关键思想。
示例语料
为了演示方法,这里我选用了一篇 在 PubMed/Cureus 上发表的综述文章(遵循 Creative Commons 署名协议)。
作者的署名在本文末尾致谢。
印度应对医疗卫生人力资源挑战的机遇 | Cureus[3]
印度的健康指标近年来有所改善,但仍落后于同类国家……
使用 Mistral 模型与提示词
在上面流程图中的 步骤 1 很容易:
Langchain 提供了丰富的 文本分割器(text splitters),
我们可以直接用来将文本分割为块。
真正有趣的是 步骤 2。 为了提取概念及其关系,我使用了 Mistral 7B 模型。
在最终确定最佳变体之前,我尝试了以下几种:
•Mistral Instruct•Mistral OpenOrca•Zephyr(Hugging Face 上基于 Mistral 的衍生模型)
我使用了这些模型的 4-bit 量化版本 ——
这样我的 Mac 就不会“崩溃”了 🤣 ——
并通过 Ollama 在本地运行。
👉 Ollama 官网[4]
一个可以在本地快速运行大语言模型的平台。
这些模型都是 指令微调(instruction-tuned) 模型,
包含系统提示(system prompt)和用户提示(user prompt)。
只要我们要求,它们通常能很好地遵循指令,并将结果整齐地格式化为 JSON。
经过多次尝试,我最终选择了 Zephyr 模型,并使用如下提示词:
SYS_PROMPT=(
如果我们把之前那首小诗丢进提示词中,
模型输出的结果如下:
[
请注意,模型甚至推断出了 “food(食物)” 这个概念, 虽然在原始文本片段中并没有明确提到。 是不是很神奇!
转换为 Pandas DataFrame 如果我们将示例文章的每个文本块都跑一遍, 然后把得到的 JSON 转换为 Pandas DataFrame, 结果大致如下:

这里 每一行 都表示一对概念之间的一种关系。 在图中,每一行对应 两个节点之间的一条边;同一对概念之间可以存在多条边/多种关系。 上面数据框中的 count 列,是我任意设为 4 的权重。
上下文邻近性
我假设:在文本语料中彼此位置接近出现的概念是相关的。
我们把这种关系称为 “上下文邻近性(contextual proximity)”。
为了计算“上下文邻近性”的边:
1.melt 数据框: 将 node_1 与 node_2 “熔化”为同一列,使节点落到一个统一的列中。2.自连接(self-join): 以 chunk_id 作为键,对上述数据框做自连接; 这样,相同 chunk_id 的节点会两两成对,形成行(即潜在的边)。3.移除自环(self-loop): 这一步也会生成“节点与自身配对”的行(自环),
即边的起点和终点是同一节点。 为了去除自环,我们删除所有 node_1 == node_2 的行。
最终,我们得到的这个数据框,与最初的语义关系数据框在结构上非常相似。
•count:node_1 与 node_2 共同出现的文本块(chunk)数量。•chunk_id:包含了所有这些共同出现的 chunk 列表。
到目前为止,我们有了两个数据框:
1.语义关系(semantic relation)的数据框;2.上下文邻近性(contextual proximity)关系的数据框(基于同块共现)。
我们可以将两者合并,以形成网络图的数据框。
可视化目标
至此,我们已经为文本构建好了概念图(Graph of Concepts)。 但如果就到这里戛然而止,未免意犹未尽。 我们的目标是将这个图可视化——就像本文开头的主图那样。
好消息是:我们离这个目标,已经不远了。
创建概念网络
NetworkX 是一个 Python 库,使得图的处理变得非常简单。
如果你还不熟悉这个库,可以点击下方链接了解更多:
👉 NetworkX 官方文档[5]
将 DataFrame 转换为 NetworkX 图
把我们之前得到的数据框(DataFrame)加入到 NetworkX 图里,只需要几行代码。
import networkx as nx
NetworkX 自带了大量可直接调用的网络算法。 可在此查看算法清单与用法:
👉 Algorithms - NetworkX 3.2.1 文档[6]
这里我使用社区发现算法给节点分组并着色。 社区指的是:与图中其他节点相比,内部连接更紧密的一组节点。
在概念图中,社区往往对应文本中被讨论的主题簇,能帮助我们把握宏观主题。
我对本文示例的综述文章运行 Girvan–Newman 算法后,检测到 17 个概念社区。 下面是其中一个社区的示例:
[
这立刻让我们对该综述论文中健康技术相关的宏观主题有了直观认识,并且还能据此提出更有针对性的问题,再用我们的 RAG 流程来回答。是不是很棒?🎉
接下来计算图中每个概念(节点)的度(degree)。 节点度指的是一个节点连接的边的总数。 在我们的场景里,度越高,说明该概念在整篇文本的主题中越居于中心。 在可视化中,我们将用节点度作为节点大小的依据(度越高,节点越大)。
图可视化
可视化是这项工作的最有趣的部分,它带来一种艺术层面的满足感。
我使用 PyVis 库来创建交互式网络图。 PyVis 是一个用于网络可视化的 Python 库[7]。
PyVis 内置了 NetworkX Helper,可以把我们的 NetworkX 图直接转换成 PyVis 对象, 因此几乎不需要额外编码——太省心啦!
回顾一下,我们已经准备好了以下用于可视化的要素:
•边的权重:用于控制边的粗细;•节点的社区:用于控制节点的颜色;•节点的度:用于控制节点的大小。
把这些“铃铛与口哨”(bells and whistles)都装上,我们的图就呈现在眼前了。
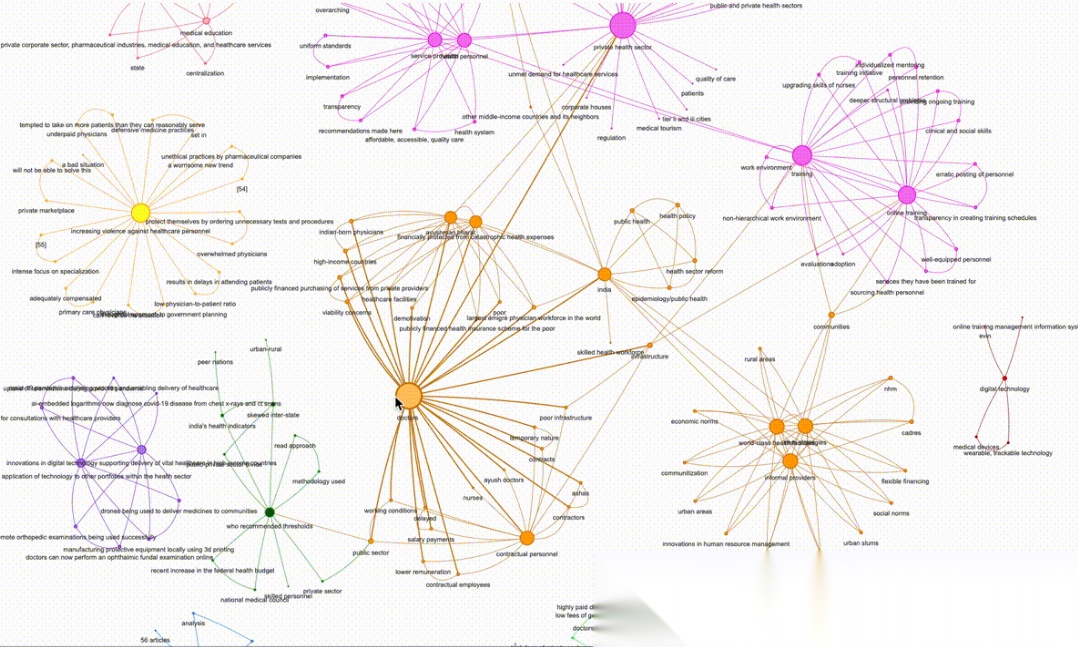
👉 点击查看互动图谱[8]
在这里,我们可以自由缩放,并随意拖动节点和边。 在页面底部还有一个滑块面板,用来调整图的物理效果。
通过这种方式,我们不仅能更好地理解主题,
还能帮助我们提出正确的问题,从而更深入地研究内容。
GitHub 仓库
源码与实现细节见:
👉 GitHub - rahulnyk/knowledge_graph[9]
读者福利大放送:如果你对大模型感兴趣,想更加深入的学习大模型**,那么这份精心整理的大模型学习资料,绝对能帮你少走弯路、快速入门**
如果你是零基础小白,别担心——大模型入门真的没那么难,你完全可以学得会!
👉 不用你懂任何算法和数学知识,公式推导、复杂原理这些都不用操心;
👉 也不挑电脑配置,普通家用电脑完全能 hold 住,不用额外花钱升级设备;
👉 更不用你提前学 Python 之类的编程语言,零基础照样能上手。
你要做的特别简单:跟着我的讲解走,照着教程里的步骤一步步操作就行。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
现在这份资料免费分享给大家,有需要的小伙伴,直接VX扫描下方二维码就能领取啦😝↓↓↓
为什么要学习大模型?
数据显示,2023 年我国大模型相关人才缺口已突破百万,这一数字直接暴露了人才培养体系的严重滞后与供给不足。而随着人工智能技术的飞速迭代,产业对专业人才的需求将呈爆发式增长,据预测,到 2025 年这一缺口将急剧扩大至 400 万!!
大模型学习路线汇总
整体的学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战,跟着学习路线一步步打卡,小白也能轻松学会!
大模型实战项目&配套源码
光学理论可不够,这套学习资料还包含了丰富的实战案例,让你在实战中检验成果巩固所学知识
大模型学习必看书籍PDF
我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
大模型超全面试题汇总
在面试过程中可能遇到的问题,我都给大家汇总好了,能让你们在面试中游刃有余
这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
👉获取方式:
😝有需要的小伙伴,可以保存图片到VX扫描下方二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最适合零基础的!!
更多推荐
 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)