
【论文速递】CVPR2022 - 学习 什么不能分割:小样本分割的新视角
近年来,小样本分割(FSS)得到了广泛的发展。以往的大部分工作都是通过分类任务衍生的元学习框架来实现泛化;然而,训练后的模型偏向于所见的类,而不是理想的未知类,从而阻碍了对新概念的识别。本文提出了一种新颖而直接的见解来缓解这一问题。具体来说,我们在传统的FSS模型(元学习器)上应用了一个额外的分支(基本学习器)来显式地识别基类的目标,即不需要分割的区域。然后,自适应整合这两个学习器并行输出的粗结果
【论文速递】CVPR2022 - 学习 什么不能分割:小样本分割的新视角
【论文原文】:Learning What Not to Segment: A New Perspective on Few-Shot Segmentation
获取地址:https://openaccess.thecvf.com/content/CVPR2022/papers/Lang_Learning_What_Not_To_Segment_A_New_Perspective_on_Few-Shot_CVPR_2022_paper.pdf
博主关键词: 小样本学习,语义分割,自适应
摘要:
近年来,小样本分割(FSS)得到了广泛的发展。以往的大部分工作都是通过分类任务衍生的元学习框架来实现泛化;然而,训练后的模型偏向于所见的类,而不是理想的未知类,从而阻碍了对新概念的识别。 本文提出了一种新颖而直接的见解来缓解这一问题。具体来说,我们在传统的FSS模型(元学习器)上应用了一个额外的分支(基本学习器)来显式地识别基类的目标,即不需要分割的区域。然后,自适应整合这两个学习器并行输出的粗结果,得到精确的分割预测。 考虑到元学习器的敏感性,我们进一步引入一个调整因子来估计输入图像对之间的场景差异,以便于模型集成预测。在PASCAL-5i和COCO-20i上的显著性能提升验证了有效性,令人惊讶的是,我们的多功能方案即使只有两个普通的学习器,也达到了新的最高水平。此外,鉴于所提出的方法的独特性,我们还将其扩展到一个更现实但具有挑战性的设置,即广义FSS,其中需要确定基类和新类的像素。源代码可以在github.com/chunbolang/BAM上找到。
简介:
得益于成熟的大规模数据集[8,9,29],大量基于卷积神经网络(CNN)的计算机视觉技术在过去几年得到了快速发展[15 - 17,27,28,35,43 - 45,48]。然而,收集足够的标记数据是非常耗时和劳动密集型的,特别是对于密集的预测任务,例如实例分割[2,3,15,21,59]和语义分割[1,25,35,40,45]。与机器学习范式形成鲜明对比的是,人类可以很容易地从少量的例子中识别出新的概念或模式,这极大地激发了群体的研究兴趣[39,52,53]。因此,提出了小样本学习(FSL)来解决这个问题,通过构建一个网络,可以推广到不可见的领域,有少量注释样本可用[7,42,54,57]。
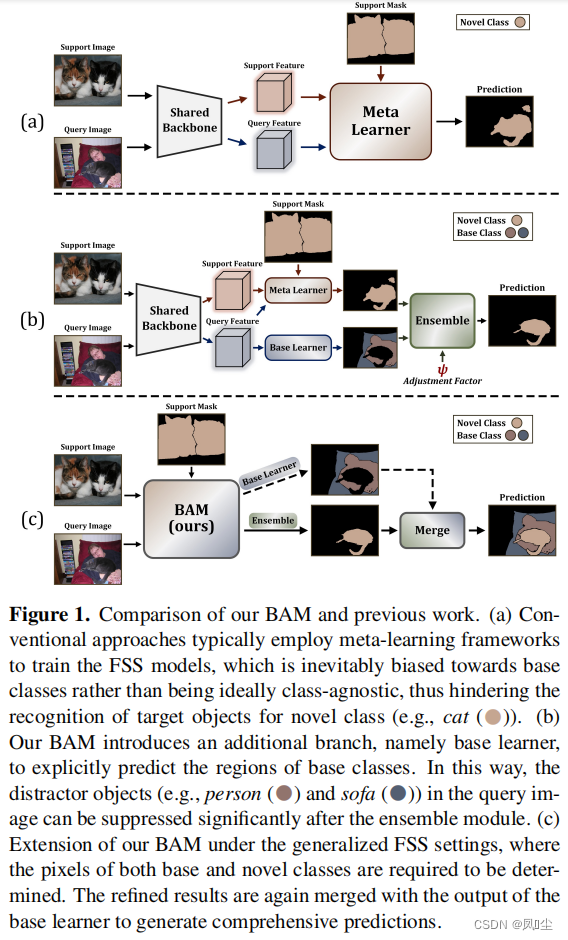
在本文中,我们进行了FSL在语义分割领域的应用,称为小样本分割(FSS),其中模型仅利用很少的标记训练数据从原始图像[46]中分割出特定语义类别的目标。在小样本分类成功的推动下,大多数现有的FSS方法都试图通过元学习框架实现泛化[23,30 - 34,36 - 38,47,55,56,61,62,64 - 67]。从基础数据集中采样一系列学习任务(集)来模拟新类的少数镜头场景,即匹配训练和测试条件。然而,令人遗憾的是,它的能力不足和动力不足。在具有丰富注释样本的基础数据集上进行元训练,不可避免地会引入对可见类的偏向,而不是理想的类不可知论,从而阻碍了对新概念的识别[10]。 值得注意的是,在对抗与基础数据共享相似类别的硬查询样本时,泛化性能可能处于崩溃的边缘。
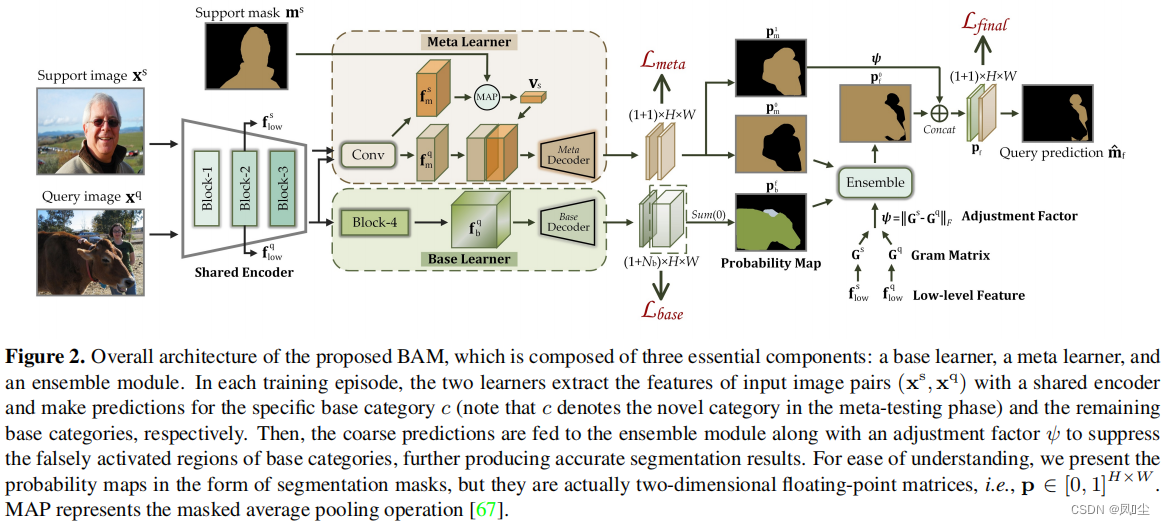
我们认为,除了设计更强大的特征提取模块[23,60,61],调整包含足够训练样本的基础数据集的使用也是缓解上述偏差问题的一种替代方法,这在以前的工作中被忽略了 。为此,我们在传统的FSS模型(元学习器)中引入一个额外的分支(基学习器)来显式预测基类的目标(如图1所示)。然后,自适应地整合这两个学习器并行输出的粗结果,以产生准确的预测。这种操作背后的核心思想是通过在传统范式中训练的高容量分割模型来识别查询图像中的易混淆区域,进一步促进新对象的识别。 顺便提一下,所提出的方案被命名为BAM,因为它由两个唯一的学习器组成,即基础和元。
此外,我们注意到元学习器通常对支持图像的质量很敏感,输入图像对之间的巨大差异可能会导致严重的性能下降。相反,由于单一查询图像作为输入,基学习器往往能提供高可靠的分割结果和稳定的性能。 在此基础上,我们进一步提出利用查询支持图像对之间场景差异的评估结果来调整元学习器得出的粗预测。受到图像风格转移领域广泛采用的风格损失的启发[12,13,20],我们首先计算两张输入图像的Gram矩阵的差值,然后利用Frobenius范数得到指导调整过程的整体指标。如图1(b)所示,在集成模块后,查询图像中基类的干扰对象(如person、sofa)被明显抑制,实现了对新对象(如cat)的准确定位。
此外,鉴于所提出方法的独特性,我们还将当前任务扩展到一个更现实但更具挑战性的设置(即广义FSS),其中需要确定基类和新类的像素,如图1©所示。综上所述,我们的主要贡献如下:
- 我们提出了一个简单但有效的方案来解决偏差问题,通过引入一个额外的分支来显式预测查询图像中基类的区域,这为未来的工作提供了启示。
- 我们提出通过Gram矩阵估计查询支持图像对之间的场景差异,以减轻元学习器敏感性造成的不利影响。
- 我们的多功能方案在所有设置的FSS基准上设置了新的先进水平,即使有两个普通的学习器。
- 我们将所提出的方法扩展到更具挑战性的设置,即广义FSS,它同时识别基本类和新类的目标。

AI·Earth
更多推荐



 3
3 0
0- 0



 已为社区贡献140条内容
已为社区贡献140条内容

所有评论(0)