
构建可扩展Agent系统:揭秘Function Calling背后的三层架构与实战技巧!
文章摘要: 本文深入探讨了构建生产级AI工具系统的核心挑战,揭示了Function Calling背后的复杂架构。作者通过真实案例指出,当工具数量超过15个时,模型选择准确率会骤降至60%以下,并提出了三层解决方案:描述层(优化工具Schema的语义描述)、编排层(动态选择工具)和执行层(严格校验参数)。重点强调了工具命名、描述和参数示例的重要性,建议采用语义检索或分类策略应对工具爆炸问题。同时提
你有没有想过,当ChatGPT帮你查天气、写代码、搜资料的时候,它到底是怎么"知道"该调哪个接口的?
答案大家都知道——Function Calling。但说实话,大部分人只看到了冰山一角。模型返回一个函数名和参数,你执行一下,把结果塞回去,完事。
真要做一个生产级的Agent工具系统,你会发现坑多得离谱。
从一个真实的问题说起
去年我帮一个团队搭Agent系统,需求很简单:让Agent能查数据库、调API、读写文件。
一开始我们的做法很naive——直接把所有工具的JSON Schema塞进system prompt,让模型自己选。三个工具的时候还好,等加到十五个工具,模型开始犯迷糊了:明明该调search的,它非要调database;参数格式也经常传错。
后来工具数量涨到三十多个,彻底崩了。模型选工具的准确率掉到了60%以下,token消耗暴涨(光工具描述就吃了大几千token),响应速度也慢得让人抓狂。
那一刻我才意识到:Function Calling只是工具系统的冰山一角。真正的挑战在水面之下——工具注册、发现、描述、校验、编排、缓存……每一层都有学问。
工具系统的三层架构
经过反复踩坑,我把Agent工具系统抽象成了三层:
┌─────────────────────────────────────┐│ 编排层 (Orchestration) ││ 工具选择 → 并行/串行 → 结果聚合 │├─────────────────────────────────────┤│ 描述层 (Description) ││ Schema定义 → 语义描述 → 检索匹配 │├─────────────────────────────────────┤│ 执行层 (Execution) ││ 参数校验 → 调用执行 → 结果格式化 │└─────────────────────────────────────┘
别小看这个分层。很多团队的工具系统出问题,都是因为这三层的职责混在一起了。
描述层:让模型"看懂"你的工具
这是最容易被忽视,但影响最大的一层。
工具Schema不只是JSON
OpenAI的Function Calling要求你用JSON Schema描述工具。但很多人不知道,Schema的写法直接影响模型的选择准确率。
看个反面教材:
{ "name": "query", "description": "Query the database", "parameters": { "type": "object", "properties": { "input": { "type": "string" } } }}
这个Schema有三个致命问题:
- 名字太泛:
query什么?query数据库?query搜索引擎?query API?模型看到这个名字根本不知道你干嘛 - 描述太短:“Query the database”——什么数据库?查什么表?什么场景下用?
- 参数名没意义:
input是什么?SQL语句?自然语言?表名?
改一下:
{ "name": "query_user_database", "description": "在用户管理数据库中执行SQL查询。用于查找用户信息、订单记录、账户状态等。仅支持SELECT语句,不支持写操作。当用户询问'某某用户的信息'、'最近的订单'等问题时使用此工具。", "parameters": { "type": "object", "properties": { "sql": { "type": "string", "description": "要执行的SQL SELECT语句,例如:SELECT * FROM users WHERE email = 'xxx'" } }, "required": ["sql"] }}
差别在哪?名字有语义、描述有场景、参数有示例。 模型选工具的准确率能从60%直接拉到90%以上。
工具数量爆炸怎么办?
当工具超过10个,直接全塞prompt就不现实了。两个思路:
思路一:语义检索
先用embedding把所有工具描述向量化,用户提问时先检索top-k相关工具,只把这几个工具的Schema发给模型。
import numpy as npfrom sentence_transformers import SentenceTransformerclass ToolRegistry: def __init__(self): self.tools = [] self.embeddings = None self.encoder = SentenceTransformer('all-MiniLM-L6-v2') def register(self, tool_schema: dict): """注册工具""" self.tools.append(tool_schema) # 用 name + description 生成embedding text = f"{tool_schema['name']}: {tool_schema['description']}" embedding = self.encoder.encode(text) if self.embeddings is None: self.embeddings = np.array([embedding]) else: self.embeddings = np.vstack([self.embeddings, embedding]) def discover(self, query: str, top_k: int = 5) -> list: """根据用户查询发现最相关的工具""" query_embedding = self.encoder.encode(query) # 余弦相似度 scores = np.dot(self.embeddings, query_embedding) / ( np.linalg.norm(self.embeddings, axis=1) * np.linalg.norm(query_embedding) ) top_indices = np.argsort(scores)[-top_k:][::-1] return [self.tools[i] for i in top_indices]# 使用registry = ToolRegistry()registry.register({ "name": "search_web", "description": "搜索互联网获取最新信息"})registry.register({ "name": "query_database", "description": "查询内部数据库获取业务数据"})registry.register({ "name": "send_email", "description": "发送邮件给指定收件人"})# 用户问"最近有什么新闻"relevant_tools = registry.discover("最近有什么新闻", top_k=2)# → [search_web, ...] 不会返回send_email
思路二:工具分类
把工具按领域分组(文件操作、网络请求、数据库、系统命令等),先让模型选类别,再在类别内选具体工具。两层选择,每层的候选集都小很多。
MCP:工具描述的标准化尝试
2025年底Anthropic推出了MCP(Model Context Protocol),想解决的就是这个问题——让工具描述有一个标准格式,任何Agent框架都能即插即用。
MCP的核心思路是把工具提供者(Tool Provider)和工具消费者(Agent)解耦。工具提供者通过MCP Server暴露工具,Agent通过MCP Client发现和调用。
说白了,就是给AI工具生态搞了个"USB-C接口"。
不过说实话,MCP目前还处于早期阶段。协议本身设计得不错,但生态远没成熟。我现在的建议是:关注MCP的发展,但别急着all in。 自己的工具系统先把描述层做好,等MCP生态成熟了再对接也不迟。
执行层:别信任模型的参数
模型选对了工具,不代表参数就对了。这一层要做的事很朴素,但很重要。
参数校验
永远不要直接把模型返回的参数丢给你的函数。模型会撒谎。
它会传字符串给你期望的整数,会漏掉必填字段,会在枚举值里编一个不存在的选项。
from pydantic import BaseModel, ValidationError, Fieldfrom typing import Optionalfrom enum import Enumclass QueryType(str, Enum): SELECT = "select" INSERT = "insert" UPDATE = "update"class DatabaseQueryParams(BaseModel): sql: str = Field(..., description="SQL查询语句") database: str = Field("default_db", description="目标数据库名") query_type: QueryType = Field(QueryType.SELECT, description="查询类型") limit: Optional[int] = Field(None, ge=1, le=1000, description="结果数量限制") timeout_ms: Optional[int] = Field(5000, ge=100, le=30000, description="超时时间")def execute_tool(tool_name: str, raw_params: dict): """安全的工具执行入口""" # 1. 参数校验 try: params = DatabaseQueryParams(**raw_params) except ValidationError as e: return { "success": False, "error": f"参数校验失败: {e}", "suggestion": "请检查SQL语句格式和参数类型" } # 2. 额外的业务规则校验 if params.query_type != QueryType.SELECT: return { "success": False, "error": "只允许SELECT查询", "suggestion": "如需修改数据,请使用专门的数据修改工具" } # 3. 执行 try: result = db.execute(params.sql, timeout=params.timeout_ms) return {"success": True, "data": result} except Exception as e: return { "success": False, "error": f"执行失败: {str(e)}", "sql": params.sql # 方便调试 }
注意几个细节:
- 用Pydantic做校验,别手写if-else。Pydantic的类型转换和错误提示都比手写的好
- 校验失败时返回
suggestion字段,告诉模型哪里错了、怎么改。模型拿到这个反馈后,下一轮可以自动修正参数 - 业务规则校验和类型校验分开,职责清晰
结果格式化
工具返回的结果,模型不一定能理解。
比如数据库返回的datetime对象、API返回的嵌套JSON、文件系统返回的路径对象……这些都需要格式化成模型能理解的文本。
def format_tool_result(tool_name: str, raw_result) -> str: """把工具返回值格式化成模型友好的文本""" if isinstance(raw_result, dict) and raw_result.get("success"): data = raw_result.get("data") # 数据库查询结果 if isinstance(data, list): if len(data) == 0: return "查询结果为空,没有匹配的记录。" # 只返回前10条,避免token爆炸 preview = data[:10] formatted = f"查询到 {len(data)} 条记录,显示前10条:\n" for i, row in enumerate(preview, 1): formatted += f"{i}. {row}\n" if len(data) > 10: formatted += f"...还有 {len(data) - 10} 条记录未显示。" return formatted # 单条记录 if isinstance(data, dict): return "\n".join(f"{k}: {v}" for k, v in data.items()) return str(data) elif isinstance(raw_result, dict) and not raw_result.get("success"): error = raw_result.get("error", "未知错误") suggestion = raw_result.get("suggestion", "") return f"工具执行失败: {error}\n{suggestion}" return str(raw_result)
这个格式化函数做了几件关键的事:
- 截断长结果:数据库返回一万条记录,你不能全塞给模型。取前10条,告诉模型总数
- 错误信息友好:不只是返回错误码,还告诉模型怎么修正
- 统一格式:不管底层工具返回什么类型,最终都变成模型能理解的文本
编排层:工具调用的指挥家
这是最有趣的一层。当Agent需要调用多个工具时,怎么编排?
串行 vs 并行
最简单的场景:Agent一次只调一个工具,拿到结果再决定下一步。这就是串行。
但很多时候,工具之间没有依赖关系。比如用户问"帮我查一下北京明天的天气和上海的航班信息",查天气和查航班完全可以并行。
import asynciofrom typing import Anyclass ToolOrchestrator: def __init__(self, executor): self.executor = executor # 工具执行器 async def execute_parallel(self, tool_calls: list[dict]) -> list: """并行执行多个工具调用""" tasks = [ self.executor.execute( call["tool_name"], call["parameters"] ) for call in tool_calls ] results = await asyncio.gather(*tasks, return_exceptions=True) # 处理异常,不让一个失败拖垮全部 formatted = [] for call, result in zip(tool_calls, results): if isinstance(result, Exception): formatted.append({ "tool": call["tool_name"], "success": False, "error": str(result) }) else: formatted.append(result) return formatted async def execute_sequential(self, tool_calls: list[dict]) -> list: """串行执行,前一个的结果可以传给后一个""" context = {} results = [] for call in tool_calls: # 支持参数引用前一个工具的结果 params = self._resolve_references( call["parameters"], context ) result = await self.executor.execute( call["tool_name"], params ) context[call["tool_name"]] = result results.append(result) # 如果某个工具失败了,看是否继续 if not result.get("success") and call.get("required", True): break return results def _resolve_references(self, params: dict, context: dict) -> dict: """解析参数中的引用,比如 {"user_id": "{{get_user.id}}"} """ import re resolved = {} for key, value in params.items(): if isinstance(value, str): matches = re.findall(r'\{\{(\w+)\.(\w+)\}\}', value) for tool_name, field in matches: if tool_name in context: replacement = context[tool_name].get("data", {}) if isinstance(replacement, dict): value = value.replace( f"{{{{{tool_name}.{field}}}}}", str(replacement.get(field, "")) ) resolved[key] = value return resolved
模型驱动的动态编排
更高级的做法是让模型自己决定调用顺序。这就是ReAct模式的核心——模型在每一轮思考后决定下一步调什么工具。
用户: 帮我分析一下竞品A最近一个月的用户增长情况模型思考: 我需要先获取竞品A的信息,然后查它的用户数据 → 调用 search_company("竞品A") ← 返回: {name: "A公司", id: 12345}模型思考: 拿到了公司ID,现在查用户增长数据 → 调用 query_user_growth(company_id=12345, period="30d") ← 返回: {growth_rate: "15.2%", new_users: 12000}模型思考: 数据拿到了,再查一下行业平均数据做对比 → 调用 query_industry_average(industry="SaaS", metric="user_growth") ← 返回: {average_growth: "8.5%"}模型: 竞品A最近一个月用户增长15.2%,新增用户12000人, 远超行业平均的8.5%……
这个模式的好处是灵活——模型可以根据中间结果动态调整策略。坏处是慢——每一轮都要等模型思考,而且token消耗大。
一个实用的折中方案
在实际项目中,我发现一个效果不错的折中方案:预定义编排模板 + 模型填充参数。
# 预定义常见的工作流模板WORKFLOW_TEMPLATES = { "competitor_analysis": { "description": "竞品分析工作流", "steps": [ {"tool": "search_company", "param_source": "user_input"}, {"tool": "query_user_metrics", "depends_on": 0}, {"tool": "query_revenue_metrics", "depends_on": 0}, {"tool": "compare_with_industry", "depends_on": [1, 2]}, ] }, "user_support": { "description": "用户问题排查工作流", "steps": [ {"tool": "query_user_info", "param_source": "user_input"}, {"tool": "query_recent_logs", "depends_on": 0}, {"tool": "query_system_status", "parallel_with": 1}, {"tool": "generate_diagnosis", "depends_on": [1, 2]}, ] }}
模型只需要判断用户意图属于哪个模板,然后填充参数。编排逻辑是确定性的,速度快、可预测、好调试。
几个血泪教训
1. 工具描述要写"什么时候不用"
大部分人写工具描述只说"这个工具能干什么"。但模型更需要知道"这个工具什么时候不该用"。
{ "name": "search_knowledge_base", "description": "搜索内部知识库。适用于查找公司政策、产品文档、FAQ等内部资料。不要用于搜索互联网信息(请用search_web),不要用于查询实时数据(请用query_database)。"}
加了"不要用于"之后,模型选错工具的概率明显下降。
2. 给工具加元数据
除了Schema,工具还应该携带一些元数据,帮助编排层做决策:
@tool( name="delete_user", description="删除用户账户", danger_level="high", # 危险等级 requires_confirmation=True, # 需要人工确认 rate_limit="10/min", # 频率限制 estimated_latency_ms=200, # 预估延迟 cost_per_call=0.01, # 每次调用成本 category="user_management" # 分类)async def delete_user(user_id: str, reason: str): ...
这些元数据在编排时非常有用。比如危险等级高的工具可以自动触发人工审批,频率限制可以防止模型陷入循环调用。
3. 工具结果的缓存
有些工具的结果是幂等的——同样的参数,短时间内返回的结果不会变。这种工具的结果应该缓存。
from functools import lru_cacheimport hashlibimport jsonclass CachedToolExecutor: def __init__(self, ttl_seconds: int = 300): self.cache = {} self.ttl = ttl_seconds def _cache_key(self, tool_name: str, params: dict) -> str: raw = f"{tool_name}:{json.dumps(params, sort_keys=True)}" return hashlib.md5(raw.encode()).hexdigest() async def execute(self, tool_name: str, params: dict, cacheable: bool = False) -> dict: if cacheable: key = self._cache_key(tool_name, params) if key in self.cache: entry = self.cache[key] if time.time() - entry["timestamp"] < self.ttl: entry["hits"] += 1 return {**entry["result"], "cached": True} result = await self._actual_execute(tool_name, params) if cacheable: self.cache[key] = { "result": result, "timestamp": time.time(), "hits": 0 } return result
模型在多轮对话中经常会重复问同样的问题。缓存能省掉大量重复的工具调用和token消耗。
4. 工具调用的可观测性
每个工具调用都应该被记录。不是简单的日志,而是结构化的trace:
class ToolCallTrace: def __init__(self): self.calls = [] def record(self, tool_name, params, result, latency_ms, tokens_before, tokens_after): self.calls.append({ "timestamp": time.time(), "tool": tool_name, "params_summary": self._summarize(params), "result_summary": self._summarize(result), "success": result.get("success", False), "latency_ms": latency_ms, "token_delta": tokens_after - tokens_before }) def get_stats(self): total = len(self.calls) successes = sum(1 for c in self.calls if c["success"]) total_latency = sum(c["latency_ms"] for c in self.calls) total_tokens = sum(c["token_delta"] for c in self.calls) return { "total_calls": total, "success_rate": f"{successes/total*100:.1f}%", "avg_latency_ms": total_latency / total, "total_tokens_used": total_tokens, "most_called_tool": self._most_called(), "slowest_tool": self._slowest() }
这些数据不仅能帮你排查问题,还能用来优化工具描述(哪些工具经常被选错)、调整编排策略(哪些工具可以并行)、控制成本(哪些工具最耗token)。
工具系统的未来
我觉得Agent工具系统正在经历类似Web API从SOAP到REST的演进。
早期大家都是"把所有东西塞给模型",就像SOAP一样——完整但笨重。现在开始出现分层、检索、标准化协议(MCP),就像REST时代的到来。
几个值得关注的趋势:
- MCP生态成熟:当越来越多的工具以MCP Server的形式提供,Agent就能像手机装App一样即插即用
- 工具市场:类似App Store,开发者发布工具,Agent按需安装。Anthropic的MCP Server目录已经是这个方向了
- 自适应工具选择:模型不再只是被动选择工具,而是能根据执行结果动态调整策略,甚至自己"发明"新的工具组合
- 工具安全标准:随着Agent调用的工具越来越多,工具本身的安全审计、权限控制、沙箱隔离会成为刚需
说到底,工具系统是Agent连接真实世界的桥梁。桥修得好不好,直接决定了Agent是"能聊天的玩具"还是"能干活的助手"。
Function Calling只是桥上的一块砖。要把桥修好,你还需要描述、校验、编排、缓存、监控……每一块都不能少。
说真的,这两年看着身边一个个搞Java、C++、前端、数据、架构的开始卷大模型,挺唏嘘的。大家最开始都是写接口、搞Spring Boot、连数据库、配Redis,稳稳当当过日子。
结果GPT、DeepSeek火了之后,整条线上的人都开始有点慌了,大家都在想:“我是不是要学大模型,不然这饭碗还能保多久?”
我先给出最直接的答案:一定要把现有的技术和大模型结合起来,而不是抛弃你们现有技术!掌握AI能力的Java工程师比纯Java岗要吃香的多。
即使现在裁员、降薪、团队解散的比比皆是……但后续的趋势一定是AI应用落地!大模型方向才是实现职业升级、提升薪资待遇的绝佳机遇!
这绝非空谈。数据说话
2025年的最后一个月,脉脉高聘发布了《2025年度人才迁徙报告》,披露了2025年前10个月的招聘市场现状。
AI领域的人才需求呈现出极为迫切的“井喷”态势
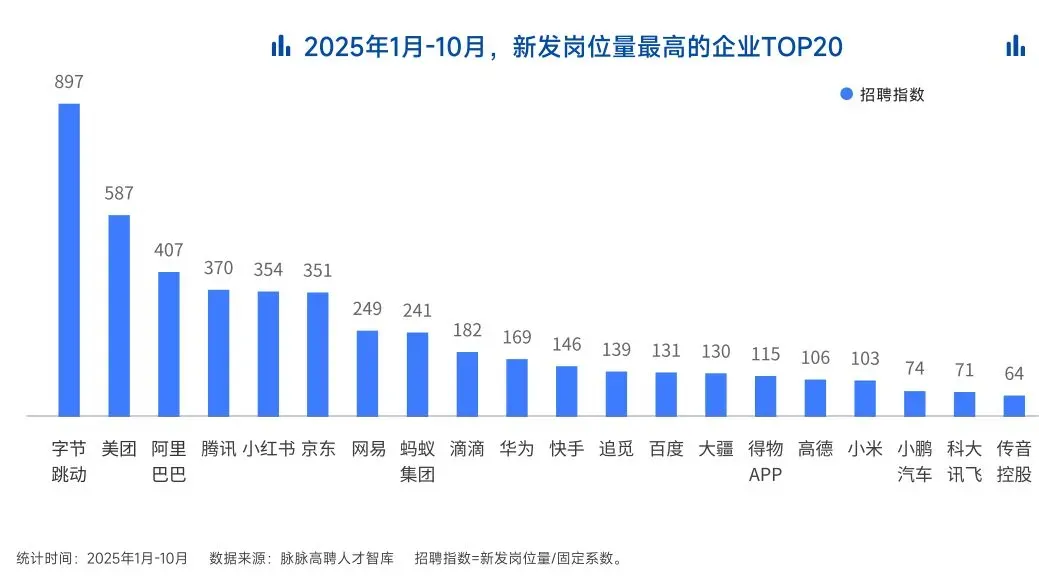
2025年前10个月,新发AI岗位量同比增长543%,9月单月同比增幅超11倍。同时,在薪资方面,AI领域也显著领先。其中,月薪排名前20的高薪岗位平均月薪均超过6万元,而这些席位大部分被AI研发岗占据。
与此相对应,市场为AI人才支付了显著的溢价:算法工程师中,专攻AIGC方向的岗位平均薪资较普通算法工程师高出近18%;产品经理岗位中,AI方向的产品经理薪资也领先约20%。
当你意识到“技术+AI”是个人突围的最佳路径时,整个就业市场的数据也印证了同一个事实:AI大模型正成为高薪机会的最大源头。
最后
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
- ✅从入门到精通的全套视频教程
- ✅AI大模型学习路线图(0基础到项目实战仅需90天)
- ✅大模型书籍与技术文档PDF
- ✅各大厂大模型面试题目详解
- ✅640套AI大模型报告合集
- ✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线
③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

更多推荐
 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)