
同样的大模型,为什么别人的 Agent 能稳跑 6 小时,你的 30 分钟就“胡言乱语“?秘密就在 Harness 里。
你可能已经发现了——同样的模型,别人的Agent能连续跑6小时不出错,你的跑30分钟就开始胡言乱语。
问题不在模型。
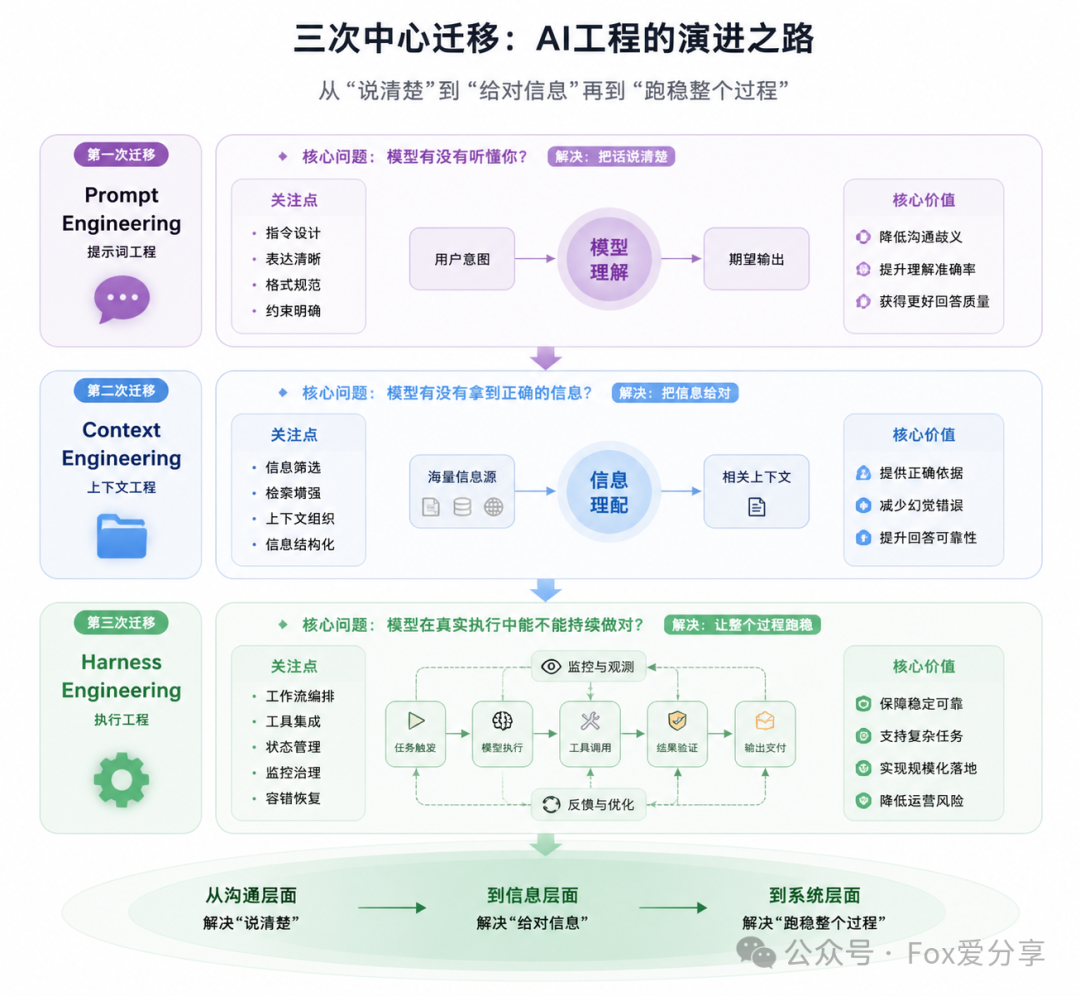
01 三次中心迁移:你在哪一层?
过去两年,AI工程经历了三次中心迁移:Prompt Engineering → Context Engineering → Harness Engineering。
很多人觉得这就是换了个时髦词。但你如果真这么想,就完全低估了这件事。
这三个词,分别对应了AI系统发展的三层核心问题:
|
阶段 |
核心问题 |
解决什么 |
|---|---|---|
|
Prompt Engineering |
模型有没有听懂你? |
把话说清楚 |
|
Context Engineering |
模型有没有拿到正确的信息? |
把信息给对 |
|
Harness Engineering |
模型在真实执行中能不能持续做对? |
让整个过程跑稳 |
一个问题比一个难,一层比一层往外扩。
举个通俗的例子:你派一个新人去见重要客户。
Prompt——告诉他任务怎么拆:先寒暄,再介绍方案,再确认下一步。核心是把话说明白。
Context——让他把资料备齐:客户背景、历史沟通、竞品情况、会议目标。核心是把信息给对。
Harness——如果这个会真的很重要,你还会做更多:让他带checklist,关键节点实时汇报,会后核实纪要,发现偏差立刻纠偏,按明确标准验收。核心是有没有一套持续观测、持续纠偏、最终验收的机制。
三者不是替代关系,是包含关系。Prompt是对指令的工程化,Context是对输入环境的工程化,Harness是对整个运行系统的工程化。
下面我们逐层来看——每一层解决了什么问题,又撞上了什么天花板。
02 Prompt的天花板:说清楚 ≠ 做对
大模型刚火的时候,同一个模型换个说法,结果差很多。于是大家疯狂研究提示词——角色设定、Few-shot示例、输出格式约束……
Prompt的本质不是命令模型,而是塑造一个局部的概率空间。你给什么身份,模型就沿那个身份回答;给什么样例,模型就沿那个范式补全——Few-shot之所以有效,本质上是因为大模型是"上下文学习"的机器:你展示的每一条样例,都在调整它下一个token的采样概率。这个阶段最重要的能力是语言的设计。
但很快撞墙了。因为很多任务不是你说清楚就行,而是你真的得知道。
让模型分析内部文档、按复杂规范写代码、在多个工具之间协调任务——提示词写得再漂亮,也替代不了事实本身。
Prompt擅长:长期任务约束输出、激发模型已有能力。
Prompt不擅长:凭空弥补缺失的知识、管理大量动态信息、处理长链路任务里的状态。
说白了,Prompt解决的是表达的问题,不是信息的问题。
03 Context的边界:信息给对了 ≠ 执行不出错
Agent时代来了,模型不只是回答问题,而是要进到真实环境里做事——多轮对话、调浏览器、写代码、操作数据库,工具之间还要传递中间结果,还要根据外部反馈修订计划。
问题变了:不是一次回答对不对,而是整条链路能不能跑通。
Context Engineering的核心变成一句话:模型未必知道所有信息,系统必须在合适的时机把正确的信息送进去。
这里的Context不只是几段背景资料。在工程意义上,它代表所有影响模型当前决策的信息总和——用户输入、历史对话、检索结果、工具返回、任务状态、中间产物、系统规则、安全约束、其他Agent传来的结构化结果。
RAG算是Context Engineering的典型实践,但真正成熟的Context Engineering关注的是完整链路:文档怎么切块、结果怎么排序、长文怎么压缩、历史对话何时保留何时摘要、工具返回要不要全暴露、多Agent之间传原文还是结构化字段。
最近大火的Agent Skills,本质上是Context Engineering的高级形态——渐进式披露:不是一开始就把所有能力全给模型看,而是只给最少的元信息,等真正要触发时再动态加载详细SOP和参考信息。
核心洞察:上下文优化不是给更多,而是按需给、分层给、在正确的时机给。
但Context也有边界。就算信息给对了,模型也不一定能稳定地执行正确——计划做得好但执行跑偏,调了工具但理解错了,长链路里已经偏航系统却没发现。
Prompt和Context主要解决的还是输入侧的问题——把话说清楚、把信息给对。但Agent一旦开始连续行动,就进入了执行侧——谁来监督它、约束它、纠偏它?
这就是第三次中心迁移的出发点。
04 Harness:从"能说会道"到"能干活"
Harness这个词,原意是缰绳、马具。放到AI系统里,就是在提醒一件朴素的事:当模型从回答问题走向执行任务,系统不只要能喂信息,还要能驾驭整个过程。
术语溯源:HashiCorp联合创始人、Terraform创造者Mitchell Hashimoto在2026年2月公开提出这个概念。随后OpenAI的Ryan Lopopolo发表《Harness Engineering: Leveraging Codex in an Agent-First World》系统化阐述,使其在AI工程圈迅速走红。
用一个公式表达:
Agent = Model + Harness
这是LangChain团队提出的定义。他们在Terminal Bench 2.0上做了一个非常有说服力的实验——全程用同一个模型(GPT-5.2-Codex),只改Harness,通过率从52.8%提升到66.5%,排名从30开外杀进Top 5。
13.7个百分点的提升,模型一行没换。这说明什么?在当前阶段,很多系统的瓶颈不在模型,而在基础设施。
但在我看来,这个公式需要两处修正——
第一,用"+"号容易让人觉得Model和Harness可以独立替换,实际上两者是联合优化的关系。模型的能力边界直接决定Harness该怎么设计——Anthropic发现,升级到Claude Opus 4.5后,"上下文焦虑"大大缓解,不再需要Context Reset这种重型机制。模型变强了,Harness就可以变简单。 不是简单叠加,而是协同调优。
第二,也是更重要的——这个公式少了一个维度:人在回路中的动态驾驭。Harness负责的是预设的静态约束(规则、架构、验证管道),但有些问题不是预设规则能完全覆盖的——架构可能被污染、目标可能漂移、模型可能误报"完成了"。这些需要人的实时判断和介入。更完整的表述应该是:
Agent = f(Model, Harness, Human-in-the-Loop)
Harness修路,人握方向盘。两者合在一起,才是完整的"驾驭Agent"。
这个"驾驭"到底有多重?有团队分析了某头部AI实验室的Agent项目源码,发现一个数据特别震撼:在512K行代码的项目中,query()主循环16个步骤里只有1个是"调用模型",其余15个全是验证和修复逻辑。在这个项目里,95%的代码全是Harness。换句话说,真正让Agent跑稳的,不是模型那5%,而是外面那95%。
05 六大工程支柱:Harness到底管什么?
综合OpenAI、Anthropic、LangChain及国内多家团队的多方实践,一个成熟的Harness至少包含六层。
这六层不是随便列的,有依赖关系——
-
上下文架构:地基——模型能看到什么,决定了它能不能做对
-
架构约束:在地基上建围栏——能看到的里面,哪些能做哪些不能做
-
自验证循环:围栏上的监控——做了之后,怎么知道做对了
-
上下文隔离:监控的延伸——多Agent协作时,一个出了问题别把别的也带崩
-
熵治理:对抗时间——系统跑久了会自然变乱,必须有机制收拾
-
可拆卸性:对抗变化——模型在迭代,Harness不能跟模型绑死

第一层:上下文架构——让模型在正确的边界内思考
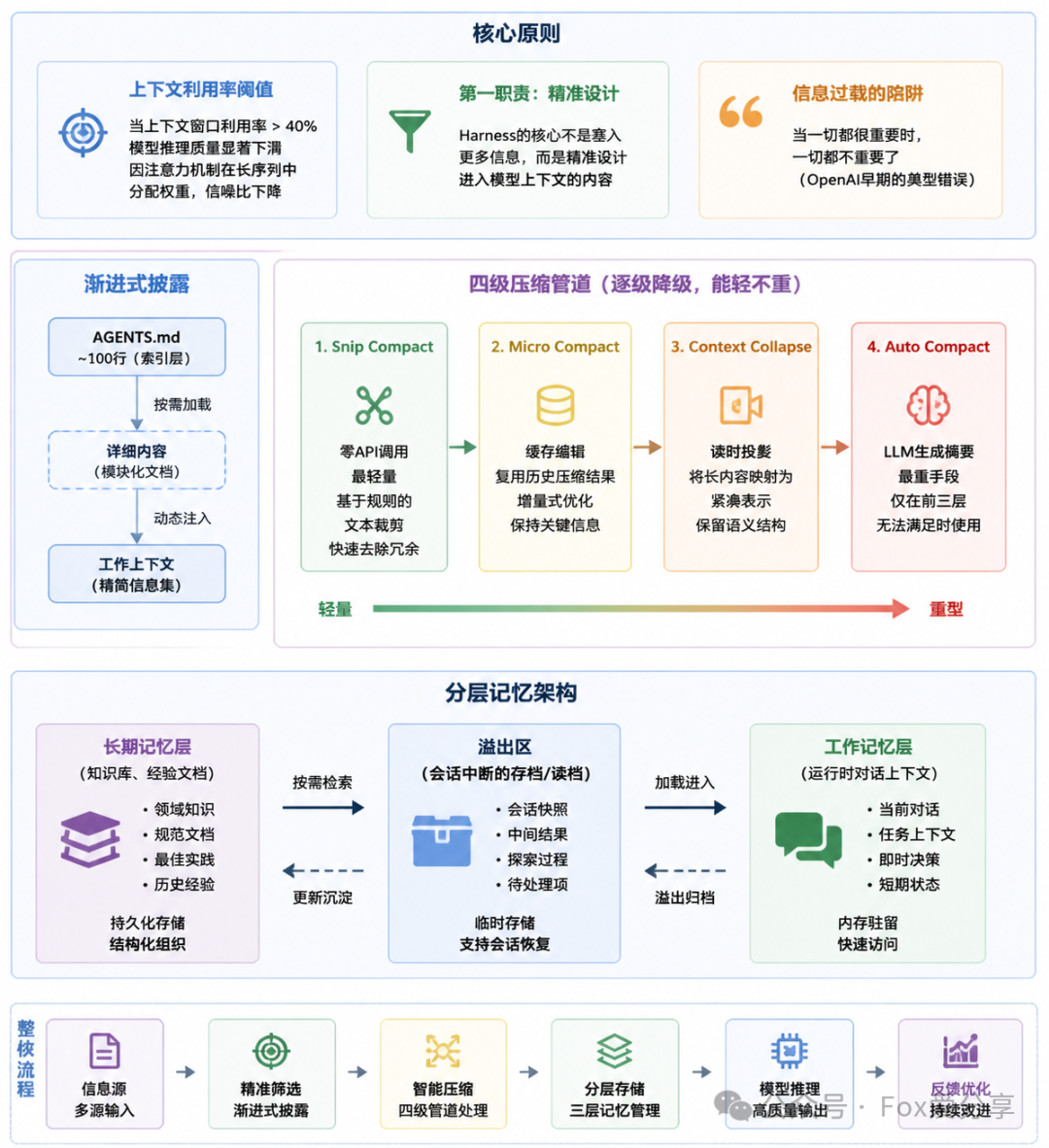
研究表明,上下文窗口利用率超过40%时,模型推理质量显著下滑——因为注意力机制要在越来越长的序列里分配权重,信息一多,关键信号的信噪比就下降了。所以Harness的第一职责不是塞更多东西,而是精准设计进入模型上下文的信息。
核心手段:
-
渐进式披露:AGENTS.md控制在~100行做索引,详细内容按需加载。OpenAI早期犯过典型错误——把所有规范塞进一个巨型AGENTS.md,结果Agent更糊涂了。"当一切都很重要时,一切都不重要了。"
-
四级压缩管道:Snip Compact(零API调用,最轻量)→ Micro Compact(缓存编辑)→ Context Collapse(读时投影)→ Auto Compact(LLM生成摘要,最后手段)。逐级降级,能轻不重。
-
分层记忆:长期记忆(知识库、经验文档)→ 溢出区(会话中断的存档/读档)→ 工作记忆(运行时对话上下文)。三层各司其职。
💡 实战提示:上下文窗口是稀缺资源。不要一上来就把所有工具说明、参数定义全塞进去。实践证明,信息一多,注意力反而涣散。Skills的渐进式披露思路——只给元信息,触发时再加载——是目前公认的最佳实践。
第二层:架构约束——用代码强制执行规则
这是Harness最核心的哲学转变:用硬约束替代软约束。
Prompt里写5000字"DO NOT"——这只是"口头嘱咐",长链路中容易被遗忘。 Harness的做法是把规则变成代码:Linter、CI检查、Schema校验,模型绕不过去。
关键实践:
-
Fail-Closed默认值:工具的默认权限全部偏向最保守。
is_concurrency_safe默认False,is_read_only默认False。忘了设置?就走最受限路径。遗漏不是漏洞,是特性。 -
自定义Lint即修复指引:不是简单地报
Forbidden import,而是告诉Agent"Layer 0的包不能依赖Layer 2,修复方法是把依赖逻辑上移,或者通过参数传入"。约束和修复指引绑在同一条反馈链路里。 -
五层纵深防御权限体系:Deny Rules(不可见)→ Tool-level Permissions(自检)→ Generic Rules(规则匹配)→ Permission Mode(模式判断)→ Auto Classifier(分类器兜底)。层层递进。为什么需要五层?因为单层防御一定会被绕过——Deny Rules让模型看不见危险工具,但如果有人在Prompt里提到工具名呢?Tool-level自检能拦住直接调用,但如果场景特殊呢?Generic Rules做模式匹配,但匹配不到的边缘case呢?每一层都是上一层的兜底,单一检查点永远不够。
💡 实战提示:一个实操性很强的建议——故意引入一个违规测试你的Lint能不能抓到。比如加一个跨层import,确认能被检测。如果检测不到,说明你的Harness是摆设。
第三层:自验证循环——不让Agent自我感觉良好
模型最大的问题之一是自评失真——自己干活,自己打分,往往偏乐观。尤其是在体验、完整度这类没有标准答案的问题上,偏差更明显。
Anthropic的解法是GAN风格的架构:
-
Planner:把1-4句模糊需求扩展成完整的产品规格
-
Generator:逐步实现,每个Sprint结束后自评,再交接给QA
-
Evaluator:通过Playwright MCP真实操作页面、点击交互、检查结果——不是抽象的代码审查,是带环境的真实验证
这背后的工程原则很清晰:生成与验收必须分离。只要评估者足够独立,系统就能形成有效循环——生成、检查、修复、再检查。
在实际的企业运营场景中,更进一步的做法是三层递进验证体系:
|
层级 |
验证方式 |
能检测什么 |
|---|---|---|
|
L1 |
Go结构体反序列化校验 |
语法错误、字段类型不匹配、字段遗漏 |
|
L2 |
API数据断言 |
数据库写入正确性 |
|
L3 |
Playwright前端验证 |
用户可见层正确性 |
L1能拦的不拖到L2,L2能拦的不拖到L3。每一层只关注自己能验证的事。
💡 实战提示:一个真实运营活动的案例特别有参考价值——在生成配置阶段就内置了10项自检清单,其中5项标注了"下一步无法检测,必须在此阶段拦截"。这个思路叫前置拦截:修复代价从10次tool call降到2次。
第四层:上下文隔离——防级联故障
多Agent协作时,最大的风险是跨边界信息污染。一个Agent的幻觉,顺着共享上下文扩散给其他Agent,形成级联故障。
三层隔离设计:
-
进程级隔离:子Agent拥有完全独立的上下文窗口、消息历史和AbortController。子Agent的错误不会传播到父级。
-
通信接口化:Agent之间通过SendMessageTool传递结构化消息,不共享原始上下文。
-
控制面/数据面分离:协调器只有3个工具(委派、停止、发消息),不能自己动手写代码。Worker有完整工具集。协调器只管决策分配,不管执行。
有实践总结出一个简洁的判断规则:
|
任务类型 |
执行方式 |
|---|---|
|
一句话能描述且不含"和"字 |
直接做(改typo、加日志) |
|
需要清单跟踪改了哪些地方 |
委派子Agent |
|
需要设计决策和权衡 |
子Agent + Git Worktree隔离 |
💡 实战提示:中等复杂度以上的任务,协调者绝不写代码。 协调者只管规划、委派、汇总;任务完成后只保留摘要,丢弃详细上下文。每个子Agent从干净的上下文开始,干完就释放。当然,小团队做快速原型时,协调者偶尔下场写代码是合理的——但要知道,这是在拿上下文污染的风险换速度。
第五层:熵治理——对抗系统的自然腐烂
系统运行久了,上下文会混乱,记忆会碎片化,文档会腐烂。这是系统状态的自然熵增,不治理就会越来越糟。
熵治理面对两种不同的问题,需要不同的机制:
第一种:单次任务太长,一轮对话跑不完。 Ralph Loop就是解决这个问题的——状态通过文件系统传递(非对话上下文),Agent每轮读取state.json了解进度,每轮Prompt相同,Agent不知道自己在循环中。完成条件由Agent自主判断,未完成就自动重新注入原始Prompt继续跑。这本质上是把长任务拆成多轮短任务,每轮从文件系统恢复状态,而不是依赖越来越长的对话历史。
第二种:同类任务反复执行,每次都在重复劳动。 轨迹编译解决的是这个问题——当同一类任务被成功执行3次以上且步骤高度一致时,编译成确定性脚本(如make add-endpoint NAME=foo),脚本失败再回退到Agent模式。棘轮效应:系统运行成本越来越低,能力越来越强。Ralph Loop治的是"单次跑不完",轨迹编译治的是"每次重新跑"——一个解决深度,一个解决效率。
自动熵治理方面,某头部AI实验室的AutoDream系统灵感来自认知科学的记忆巩固理论:人类在REM睡眠阶段重播白天经历,将短期记忆转化为长期记忆。AutoDream四阶段流程——Orient(定位)→ Gather(收集)→ Consolidate(整合)→ Prune & Index(修剪索引),三重门控(24h + 5 sessions + 文件锁),自动在后台整理AI的记忆。
💡 实战提示:不要指望"定期手动清理"。多家团队的实践都证明,熵治理必须自动化。不管是AutoDream式的后台整合,还是轨迹编译式的脚本固化,关键是让系统自己维护自己。
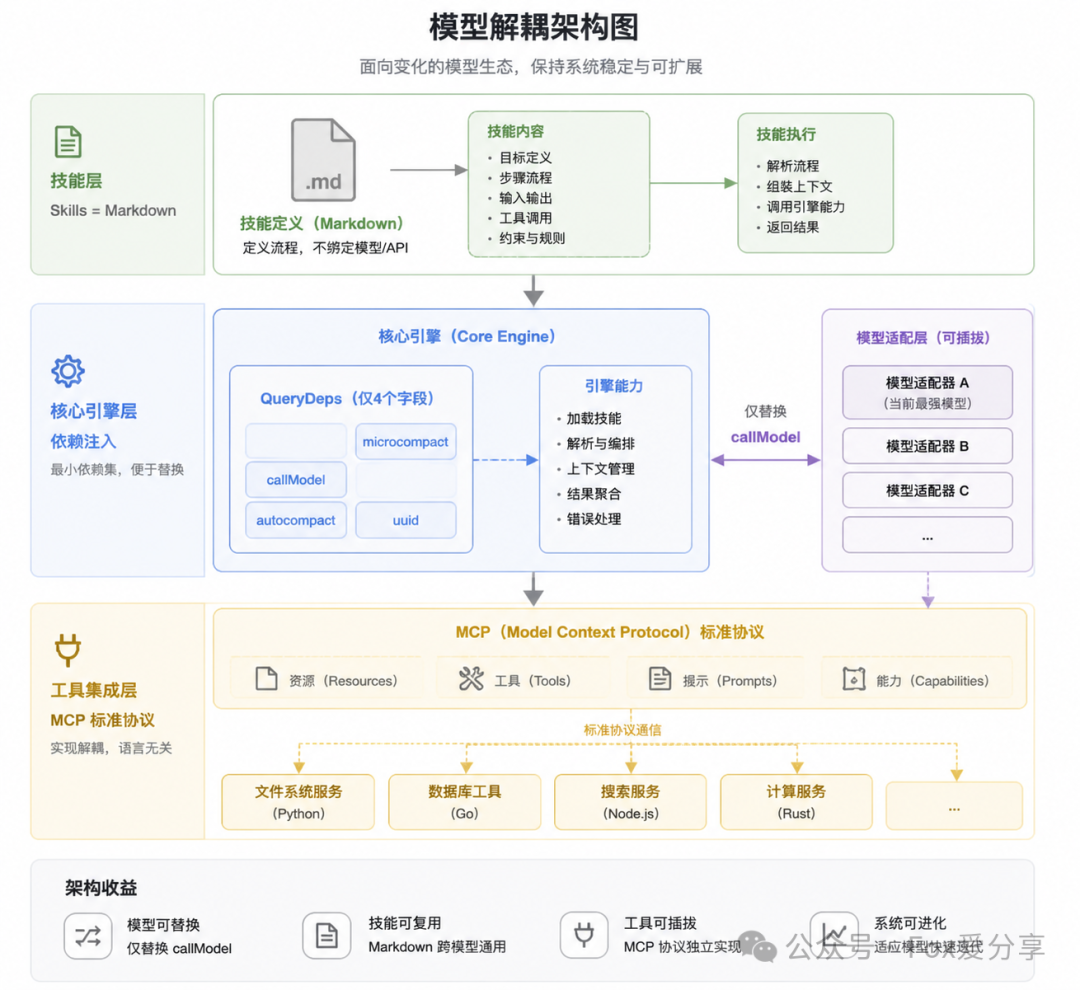
第六层:可拆卸性——别跟模型绑定死
模型迭代越来越快,今天最强的模型半年后可能就不是了。如果Harness跟特定模型深度耦合,换模型就得重写整套系统。
三个层面的解耦:
-
依赖注入:核心引擎的QueryDeps只有4个字段(callModel, microcompact, autocompact, uuid)。替换模型只需替换callModel一个字段。
-
Skills = Markdown:技能定义不绑定特定模型或API,一个Markdown文件可在不同模型上通用。定义的是流程,不是调用方式。
-
MCP标准协议:外部工具通过Model Context Protocol接入,独立于内部实现,可用任何语言编写。
模型选择策略也有讲究:
|
任务类型 |
推荐模型 |
理由 |
|---|---|---|
|
快速执行类(改typo、简单重命名) |
轻量模型 |
快、便宜 |
|
深度推理类(复杂重构、架构变更) |
旗舰模型 |
质量优先 |
|
代码检索类(定位相关文件) |
速度型模型 |
速度第一 |
交叉Review时用不同模型,避免同一模型的思维盲区。成本约为编码的10-20%。
06 一线公司的实战账本
光说不练假把式。看账本。
LangChain:不换模型,13.7个百分点的提升
这是最能说明Harness价值的案例——全程没有换过模型。
LangChain全程使用GPT-5.2-Codex,只改造Harness,在Terminal Bench 2.0上从52.8%提升到66.5%,排名从30开外杀进Top 5。核心是4层中间件:
-
LocalContextMiddleware:启动时预注入环境信息,避免环境发现错误
-
LoopDetectionMiddleware:同一文件编辑5次以上强制"退一步重新考虑",打破死循环
-
ReasoningSandwichMiddleware:规划和验证阶段用高推理预算,实现阶段用中档。反直觉发现——全程最高推理反而不行(超时太多),"三明治"策略最优
-
PreCompletionChecklistMiddleware:完成前必须通过验证清单,防止过早自批准
💡 实战提示:LangChain的"三明治推理"值得记住。很多人以为推理预算越高越好,实际上规划阶段确实需要深度思考,但实现阶段过度推理反而导致超时和过度设计。在不同阶段分配不同推理预算,才是工程化的思路。不过要注意,这个结论在有时间约束的场景(如基准测试)下成立;在不受时间限制的离线任务中,高推理预算的收益可能更大。
OpenAI:7个人,100万行代码,0手写
OpenAI的Frontier团队从3人起步(后扩到7人),用Codex Agent从零构建了一个约百万行代码的内部产品,5个月合并约1500个PR,零行手写代码,耗时约为纯人工的1/10。
他们的核心做法:
-
人类不写代码,只设计环境——拆任务、补能力、建反馈链路
-
AGENTS.md从千页手册瘦身到100行索引,加"文档园丁Agent"自动扫过时文档提PR
-
通过Chrome DevTools Protocol接浏览器、接临时可观测性栈(LogQL/PromQL/TraceQL),让Agent自己看结果
-
业务域严格按Types → Config → Repo → Service → Runtime → UI分层,跨层依赖机械禁止
-
Codex单次运行经常持续6小时以上
当Agent出了问题,修复方案几乎从来不是要它更努力,而是确定环境里缺了什么结构性能力。
如果OpenAI的案例让你觉得"这是大厂才玩得起的",那Anthropic的案例会让你改变想法——他们用3个Agent就做出了一个完整的数字音频工作站。
Anthropic:3个Agent,4小时,做出一个完整DAW
Anthropic构建了Planner-Generator-Evaluator三Agent架构,一句自然语言需求,无需人类干预,连续运行数小时,做出了完整的2D复古游戏制作器(含关卡编辑器、像素画编辑器、实体行为系统)和浏览器端数字音频工作站(含编曲视图、混音器、AI作曲代理)。完整的DAW项目运行约4小时,成本约$125。
他们发现的两个关键问题:
-
上下文焦虑:上下文快满时,模型开始着急收尾。常规做法是Context Compaction——压缩历史上下文继续跑,轻量且通常是首选。但Compaction只是变短了,某些模型那种"负担感"并没有真正消失。所以更激进的解法是Context Reset——换一个干净的新Agent,把工作交接过去。就像遇到内存泄漏,轻度场景清缓存就行,重度场景直接重启进程再恢复状态。而Anthropic发现,升级到Claude Opus 4.5后,Compaction就够了,不再需要Reset。模型能力提升后,Harness的复杂度也应该相应简化。
-
自评失真:模型自己打分偏乐观。解法是把干活和验收分开,Evaluator通过Playwright真实操作页面验收。
07 多方实践的收敛:不是巧合,是必然
前面讲了很多案例,最值得关注的现象是:这些团队在不同场景下独立实践,最后演化出了高度一致的架构设计。
Anthropic用生成/验收分离对抗自评失真,OpenAI用Lint即修复对抗规范违反,LangChain用死循环检测对抗Agent失控,国内团队用前置拦截和轨迹编译对抗熵增——表面看各不相同,底层逻辑完全一致:
-
上下文稀缺性是底层物理约束——模型能看到的信息是有限的,必须精打细算
-
渐进式披露是应对它的最优解——不是一次性全给,而是按需给
-
机械化强制执行是长期可持续的必要条件——规则写在Prompt里会遗忘,写在Linter里不会
08 从0到1,怎么落地?
别一上来就想搭完整体系。多家团队的实践都指向同一条路——最小起步,逐步加码。下面的节奏跟前面六层支柱是对应的:前两步对应上下文架构和架构约束,第三步对应自验证循环,后面的逐步覆盖隔离、熵治理、可拆卸性。
今天
创建一个AGENTS.md,控制在~100行以内。写清三件事:项目是什么、代码结构是什么、最重要的约束是什么。
一个极简模板长这样:
# 项目名
## 这是什么
一句话说清楚项目目标和当前状态。
## 代码结构
src/
├── types/ # 类型定义(Layer 0,不依赖任何内部包)
├── config/ # 配置(Layer 1)
├── services/ # 业务逻辑(Layer 2)
├── api/ # HTTP handler(Layer 3)
└── ui/ # 前端(Layer 4)
## 硬约束
- 高层可以import低层,反过来不行
- 新文件先看放在哪一层,再写代码
- 所有API必须有错误处理,不允许可选参数默认None然后不检查
## 常见坑
- macOS下/var是/private/var的符号链接,路径处理注意
- config里日期格式用冒号分隔"2026:01:01",不是短横线
## 更多细节
详见 docs/architecture.md 和 docs/conventions.md
本周
加一个依赖方向检查脚本(lint-deps)。把层级规则定下来:哪些包不能import哪些包。故意引入一个违规,确认能被检测到。
本月
搭完整的验证管道:build → lint-arch → test → verify。关键思路——在执行前先验证"这个动作合不合规"(如verify_action.py),层级违反在写代码前拦截。
之后
逐步覆盖剩下的三层:上下文隔离(多Agent任务时加进程级隔离和通信接口化)→ 熵治理(对重复任务做轨迹编译,对长任务加Ralph Loop)→ 可拆卸性(用依赖注入解耦模型,用MCP协议解耦工具)。
当验证管道跑起来之后,开启Critic → Refiner反馈循环:Agent执行 → 验证抓到问题 → Critic分析模式 → Refiner更新规则 → 下一个Agent受益。让Harness自己进化。
关键原则
-
永远不要禁用Lint规则来"解决"问题——应该改代码而不是改规则
-
3轮修复循环后仍失败,停下来交给人——避免上下文爆炸
-
测试不需要每次跑全量——executor支持只跑受影响的包
-
协调者绝不写代码——中等复杂度以上任务,人只管决策和验收
-
不是所有场景都需要Harness——一次性脚本、简单问答、单轮生成,Prompt就够了。过度工程化也是浪费。当你的任务单轮就能完成,不需要搭Harness
09 程序员的角色正在迁移
前面说了,更完整的公式是 Agent = f(Model, Harness, Human-in-the-Loop)。那Human-in-the-Loop到底在干什么?
答案很清楚——从执行者到控盘者。Harness负责静态约束(修路),人负责动态驾驭(握方向盘)。
以前:人写代码,AI辅助补全。 现在:人设计系统(架构、约束、验证规则),Agent在系统内执行,人在关键节点做判断。
但这不等于"像老板一样甩活就行"。角色迁移的具体形态是:你从"写代码的人"变成了"设计Agent运行环境的人"——写AGENTS.md而不是写业务逻辑,写Lint规则而不是做代码审查,写验证脚本而不是手动测试。更准确的说法:你可以不再亲手写大量代码,但你不能放弃技术判断。
必须亲自接管的四个时刻:
-
架构主线可能被污染时
-
阶段目标开始漂移时
-
运行时日志暴露系统性异常时
-
模型把"阶段完成"误报成"全局完成"时
环境设计的投入回报远高于Prompt调优。竞争优势不再是Prompt,而是Trajectory——这些积累,换个模型复制不来。
10 一句话总结
从Prompt到Context到Harness,三次中心迁移的逻辑其实很清晰:AI落地的核心挑战,正在从让模型看起来更聪明,转向让模型在真实世界里稳定地工作。
Prompt解决表达,Context解决信息,Harness解决执行稳定性。三者包含而非替代。
真正决定能不能落地、能不能稳定交付的,不是模型,是Harness。而Harness之外,人的动态驾驭同样不可替代。
同样的模型,Harness的差距可以带来13.7个百分点的提升。在某头部AI实验室的512K行Agent项目里,95%的代码全是Harness。
这不是理论,是账本。
回到开头那个比喻——你派新人去见客户,告诉他怎么说(Prompt)、让他备齐资料(Context)、给他checklist和验收标准(Harness)。但最终,那个在关键时刻判断"这个客户不对劲,我得亲自上"的人,还是你。
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)