
(论文速读)SnapGen:驯服具有高效架构和训练的移动设备的高分辨率文本到图像模型
SnapGen提出了一种突破性的移动端文本生成图像技术,能在1.4秒内生成1024×1024像素的高质量图像。通过重新设计UNet架构(移除冗余自注意力、使用可分离卷积等)将参数量压缩至379M,比SDXL小7倍;采用多层次知识蒸馏和时间步感知训练策略,使小模型达到大模型性能;结合对抗性步蒸馏实现4-8步快速生成。实验显示其性能超越数十亿参数模型,在iPhone上实现秒级4K图像生成,为移动AI开
论文题目:SnapGen: Taming High-Resolution Text-to-Image Models for Mobile Devices with Efficient Architectures and Training(驯服具有高效架构和训练的移动设备的高分辨率文本到图像模型)
会议:CVPR2025
摘要:现有的文本到图像(T2I)扩散模型面临一些限制,包括模型尺寸大、运行速度慢以及在移动设备上生成的质量低。本文旨在通过开发一个非常小和快速的T2I模型来解决所有这些挑战,该模型可以在移动平台上生成高分辨率和高质量的图像。我们提出了几种技术来实现这一目标。首先,我们系统地检查了网络架构的设计选择,以减少模型参数和延迟,同时确保高质量的生成。其次,为了进一步提高生成质量,我们从一个更大的模型中使用跨架构知识蒸馏,使用多层次的方法从头开始指导我们的模型的训练。第三,我们通过将对抗性指导与知识蒸馏相结合,实现了几步生成。我们的模型SnapGen首次演示了在1.4秒左右的移动设备上生成10242像素的图像。在ImageNet-1K上,我们的模型只有372M个参数,对于2562像素的生成,FID为2.06。在T2I基准测试(即GenEval和DPG-Bench)上,我们的模型只有379m个参数,在明显更小的尺寸上(例如,比SDXL小7倍,比IF-XL小14倍)超过了具有数十亿个参数的大型模型。
项目页面:https://snap-research.github.io/snapgen

SnapGen: 让手机秒生成4K高清AI图像的突破性技术
引言
想象一下,在手机上1.4秒就能生成一张1024×1024像素的高质量AI图像——这听起来像科幻,但Snap Inc.和香港科技大学的研究团队在CVPR 2025上发表的SnapGen让这成为现实。这项工作首次实现了真正意义上的移动端高分辨率文本生成图像,标志着AI图像生成技术从云端走向终端的重要里程碑。
问题背景:AI作图为何难上手机?
当前的AI作图明星模型如Stable Diffusion XL(SDXL)、Midjourney等虽然效果惊艳,但都面临"三座大山":
- 参数量太大: SDXL有26亿参数,IF-XL更是55亿,手机内存根本装不下
- 运行太慢: 在iPhone上生成一张图可能需要几十秒甚至几分钟
- 质量打折扣: 即使压缩后能在手机运行,通常也只能生成512像素的低清图
这些问题的根源在于:现有模型都是为云端GPU设计的,追求极致效果而不考虑效率。
SnapGen的三大创新
创新一:极致瘦身的网络架构
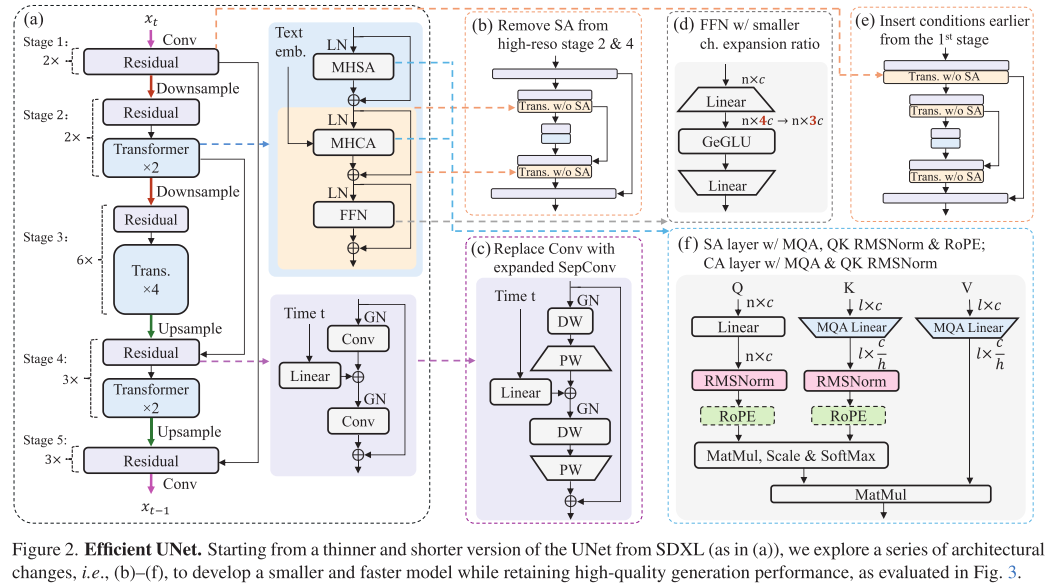
SnapGen团队没有简单地压缩现有模型,而是从零开始重新设计了架构。他们的核心思路是:在保证质量的前提下,砍掉一切冗余。
UNet主干网络的六大优化:
-
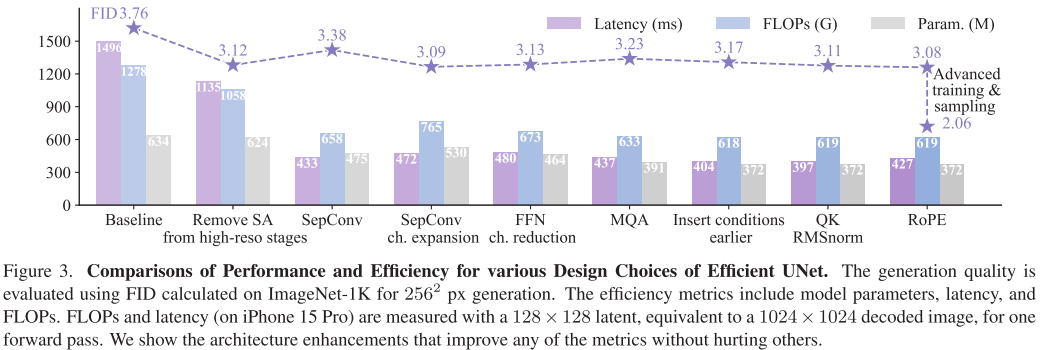
战略性移除自注意力: 在高分辨率阶段去掉自注意力层,只在最低分辨率保留。这一招不仅减少17%计算量,还意外提升了性能(FID从3.76降至3.12)
-
可分离卷积替换: 将普通卷积换成深度可分离卷积+通道扩展,参数减少15%,速度提升2.4倍
-
精简前馈网络: 将FFN的扩展比从4降到3,减少12%参数和计算
-
多查询注意力: 用MQA替换MHSA,所有注意力头共享键和值,参数减少16%
-
提前条件注入: 在第一阶段就引入文本条件,而不是像SDXL那样从第二阶段才开始
-
先进的归一化和位置编码: 引入QK RMSNorm和2D RoPE,几乎无开销地提升性能
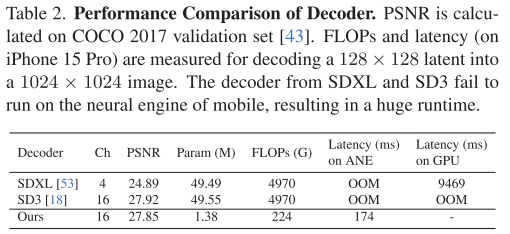
超轻量解码器:
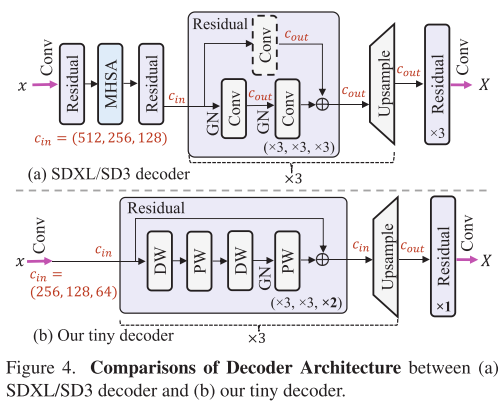
解码器往往是被忽视的性能瓶颈。SnapGen设计的解码器只有1.38M参数(SD3是49.5M),关键改进包括:
- 完全移除注意力层
- 大幅减少通道数
- 在高分辨率阶段使用更少残差块
- 最终在iPhone上解码一张1024²图像仅需119ms!
创新二:智能知识蒸馏训练
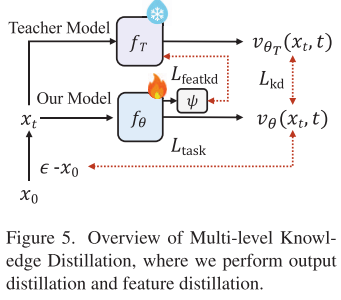
小模型如何学到大模型的本事?SnapGen提出了多层次知识蒸馏+时间步感知缩放的训练方案。
多层次蒸馏策略:
- 输出层蒸馏: 让学生模型(SnapGen)直接模仿教师模型(SD3.5-Large)的预测
- 特征层蒸馏: 跨架构蒸馏(从DiT到UNet),匹配中间层特征
- 任务损失: 同时保持对真实数据的学习
时间步感知缩放(核心创新):
传统方法简单地线性组合各项损失,但SnapGen观察到:在扩散过程的不同时间步,预测难度差异巨大。他们提出根据时间步动态调整损失权重:
Loss = λ(t)·任务损失 + [1-λ(t)]·[任务损失幅度/蒸馏损失幅度]·蒸馏损失
其中λ(t)是logit-normal密度函数。这意味着:
- 在预测困难的时间步(接近0或1):更多依赖教师指导
- 在预测简单的中间步:更多依赖真实数据学习
这个看似简单的改进大幅加速了蒸馏收敛!
创新三:对抗性步蒸馏
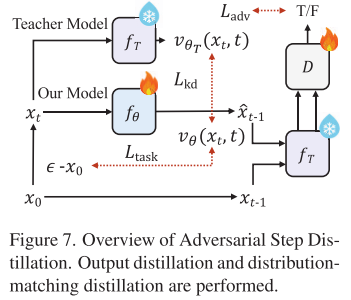
即使模型很小,如果需要50步推理也不够快。SnapGen采用扩散-GAN混合训练,将推理步数压缩到4-8步:
目标 = 对抗损失(匹配真实分布) + 输出蒸馏损失(学习教师模型)
关键点是使用SD3.5-Large-Turbo作为少步教师,并冻结其作为判别器的特征提取器,只训练轻量的分类头。
惊艳的实验结果
与巨型模型的正面PK
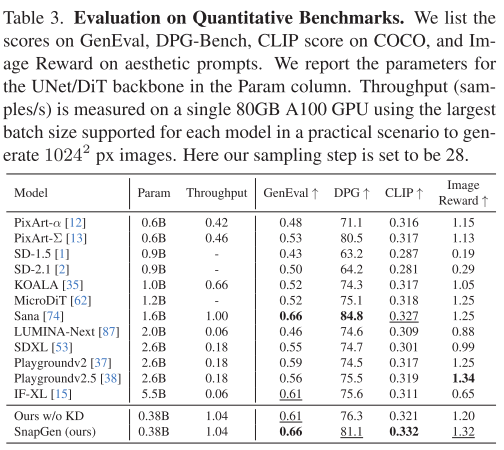
在标准基准测试中,仅379M参数的SnapGen战胜了一众"重量级选手":
| 模型 | 参数量 | GenEval↑ | DPG-Bench↑ | CLIP↑ |
|---|---|---|---|---|
| SDXL | 2.6B | 0.55 | 74.7 | 0.301 |
| Playground v2.5 | 2.6B | 0.56 | 75.5 | 0.319 |
| IF-XL | 5.5B | 0.61 | 75.6 | 0.311 |
| SnapGen | 0.38B | 0.66 | 81.1 | 0.332 |
注意:SnapGen比SDXL小7倍,比IF-XL小14倍,但性能全面领先!
移动设备上的表现
在iPhone 16 Pro-Max上测试(1024²生成):
- 4步生成: 1.2秒
- 8步生成: 2.3秒
- 28步生成: 7.8秒
要知道,SDXL的解码器在iPhone上甚至会内存溢出!
人类评估

研究团队用Parti提示词集进行盲测,结果显示:
- 完胜SDXL: 在文本对齐、美学质量、真实感三个维度全面领先
- 打平SD3: 在美学和真实感上与SD3持平,文本对齐略胜
- 接近教师: 与8.1B参数的SD3.5-Large质量相当

技术细节深度剖析
架构设计的哲学
SnapGen的架构设计遵循"效率-质量平衡"原则。以自注意力为例:
- 分辨率越高,自注意力成本越高(O(n²)复杂度)
- 但高分辨率阶段的特征更关注局部细节,不太需要全局建模
- 因此只在低分辨率阶段保留自注意力
这种设计让模型"在该用的地方用力,不该用的地方节省"。
可分离卷积的扩展技巧
普通可分离卷积(DW+PW)虽然高效,但表达能力弱。SnapGen采用扩展式可分离卷积:
输入 → PW(扩展2倍) → DW → PW(压缩回原尺寸) → 输出
这个设计类似MobileNet的倒残差瓶颈(Inverted Residual),在效率和性能间找到最佳平衡点。
蒸馏为何需要"时间步感知"?
在扩散模型的训练中,不同时间步的样本难度差异巨大:
- t接近0: 噪声极少,需要精细预测
- t接近1: 噪声极大,相对容易
- t在中间: 难度适中
如果用固定权重组合损失,模型会在简单样本上"浪费"教师监督,在困难样本上又得不到足够指导。时间步感知缩放动态调整权重,让模型"在难题上跟老师学,在简单题上自己练"。
对抗训练的稳定性技巧
扩散-GAN混合训练容易不稳定。SnapGen的稳定技巧:
- 冻结教师模型: 只用教师提取特征,不参与梯度更新
- 轻量判别器: 只在特征后接几层线性层
- 组合蒸馏损失: 对抗损失+输出蒸馏,双重约束
训练流程全解析
SnapGen的训练分为四个阶段:
阶段1: ImageNet预训练
- 在ImageNet-1K上训练120 epochs
- 使用256²分辨率
- 类别条件通过模板"a photo of <class>"转为文本
阶段2: 渐进式分辨率提升
- 256² → 512² → 1024²逐步微调
- 每个分辨率都充分训练直到收敛
阶段3: 多层次知识蒸馏
- 教师: SD3.5-Large (8.1B参数)
- 使用三个文本编码器(CLIP-L, CLIP-G, Gemma-2-2B)
- 应用时间步感知缩放
- 训练目标:
Loss = S(任务损失, 输出蒸馏) + S(任务损失, 特征蒸馏)
阶段4: 对抗性步蒸馏
- 教师: SD3.5-Large-Turbo
- 扩散-GAN混合训练
- 实现4-8步高质量生成
消融实验:每个改进都至关重要
论文进行了详尽的消融研究,证明每个设计选择都经过验证:
| 改进项 | FID | 参数量(M) | FLOPs(G) | 延迟(ms) |
|---|---|---|---|---|
| 基线 | 3.76 | 741 | 684 | 1426 |
| +移除高分辨率SA | 3.12↓ | 741 | 564↓ | 1085↓ |
| +可分离卷积 | 3.38 | 561↓ | 413↓ | 545↓ |
| +通道扩展 | 3.13↓ | 633 | 499 | 602 |
| +精简FFN | 3.09↓ | 558↓ | 437↓ | 591↓ |
| +MQA | 3.11 | 467↓ | 414↓ | 540↓ |
| +提前条件注入 | 3.17 | 437↓ | 407↓ | 530↓ |
| +QK RMSNorm+RoPE | 3.08↓ | 437 | 407 | 530 |
可以看到,最终模型相比基线:
- FID从3.76降至3.08(性能提升)
- 参数量从741M降至437M(减少41%)
- 延迟从1426ms降至530ms(加速2.7倍)
与现有工作的对比
vs. 模型压缩方法
- 剪枝/量化(如BK-SDM, LD-Pruner): 从预训练模型压缩,限于原架构
- SnapGen: 从零设计,更激进的架构创新
vs. 高效扩散模型
- SANA, LinFusion: 在笔记本GPU上实现1K生成,但未针对移动端
- SnapGen: 直接在手机上生成1K图像
vs. 步蒸馏方法
- UFOGen, DMD2: 针对大模型进行步蒸馏
- SnapGen: 在极小模型上也实现少步生成
局限性与未来展望
尽管SnapGen取得了突破性进展,仍有改进空间:
当前局限
- 极端复杂场景: 对于需要精细细节的超复杂构图,仍不如巨型模型
- 文本编码器: 目前使用的Gemma-2-2B在手机上仍有一定开销
- 风格多样性: 在某些艺术风格上可能不如专门微调的大模型
未来方向
- 更极致的压缩: 探索200M以下的模型
- 端到端优化: 联合优化文本编码器、扩散模型和解码器
- 多模态扩展: 支持图像编辑、视频生成等任务
- 专用硬件加速: 利用手机NPU进一步提速
对行业的影响
SnapGen的意义不仅在于技术突破,更在于开启了新的应用范式:
隐私保护
在本地生成图像,无需上传提示词到云端,完全保护用户隐私
实时应用
1.4秒的生成速度使得实时AR滤镜、即时贴纸生成等应用成为可能
成本降低
无需云端GPU,大幅降低服务成本,让AI作图真正普及
离线可用
在无网络环境下也能使用,拓展应用场景
关键超参数
- 优化器: AdamW
- 时间步采样: Logit-normal(μ=0, σ=1)
- 时间步偏移: 3(用于高分辨率训练和推理)
- 批量大小: ImageNet阶段256,蒸馏阶段根据分辨率调整
技术思考:小模型的"智慧"
SnapGen的成功给我们什么启示?
1. 架构比参数量更重要
379M参数的SnapGen胜过2.6B的SDXL,证明"对的架构"比"大参数"更关键
2. 知识蒸馏的潜力
通过聪明的蒸馏策略,小模型能学到大模型的精髓
3. 效率-质量权衡的艺术
SnapGen在每个设计选择上都精心权衡,没有盲目追求某个极致指标
4. 移动AI的新可能
过去认为"不可能"在手机上运行的模型,通过系统性优化变为现实
结语
SnapGen不仅是一个模型,更代表了一种新的设计哲学:从终端需求出发,重新思考模型设计。它证明了,通过深思熟虑的架构创新、巧妙的训练策略和系统级优化,我们可以在移动设备上实现云端级的AI能力。
随着SnapGen的开源(项目主页: https://snap-research.github.io/snapgen),我们期待看到更多基于它的创新应用。也许不久的将来,每个人的手机都将成为一个强大的AI创作工作室!
更多推荐


 22
22 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)