
【AI论文】GEM:面向自主决策型大语言模型的智能体训练环境
GEM框架:面向大语言模型的通用经验生成器 本文提出GEM(通用经验生成器)框架,为大型语言模型(LLMs)提供标准化的强化学习环境接口。GEM支持多轮交互、工具集成和异步并行执行,包含24个多样化环境以及REINFORCE、PPO等基准算法。特别提出带回报批归一化的REINFORCE变体(ReBN),在多轮任务中展现出更优表现。实验验证了工具集成对模型性能的提升作用,并展示了算法在不同折扣因子下
摘要:大型语言模型(LLMs)的训练范式正从静态数据集转向基于经验的学习,智能体通过与复杂环境交互来获取技能。为推动这一转型,我们推出开源环境模拟器GEM(General Experience Maker,通用经验生成器),专为大语言模型时代设计。类似于传统强化学习(RL)领域的OpenAI Gym,GEM提供了标准化的环境-智能体接口框架,支持异步向量化执行以实现高吞吐量,并提供灵活的包装器以便于扩展。GEM还配备了一系列多样化的环境、稳健的集成工具,以及单文件示例脚本,展示如何将GEM与五种主流强化学习训练框架结合使用。
与此同时,我们在24个环境中使用带回报批归一化(Return Batch Normalization,ReBN)的REINFORCE算法提供了一套基准测试结果。与GRPO不同,该算法完全兼容稠密回合奖励的强化学习设定,并能实现更优的信用分配。我们进一步利用GEM在单回合和多回合设定下对近端策略优化算法(PPO)、群体相对策略优化算法(GRPO)和REINFORCE算法进行了同条件对比基准测试,以揭示不同算法的设计特性。最后,GEM除作为训练环境外,还可作为便捷的评估工具包。我们希望该框架能为未来自主决策型大语言模型的研究提供助力。Huggingface链接:Paper page,论文链接:2510.01051
研究背景和目的
研究背景:
随着大型语言模型(LLMs)在自然语言处理领域的快速发展,传统的静态数据集训练方法已逐渐无法满足复杂任务的需求。
特别是对于需要多轮交互、长期规划和迭代改进的任务,如软件开发、科学发现等,传统的强化学习(RL)方法往往受限于单轮任务设置的局限性,难以有效训练出具备高级推理和规划能力的智能体。尽管近期的研究开始探索RL在LLMs中的应用,但这些工作主要集中在单轮任务上,忽略了多轮交互中的复杂性和挑战性。
OpenAI Gym作为传统RL的标准环境模拟器,为RL算法的开发和测试提供了统一接口和标准化环境,极大地推动了RL领域的发展。然而,对于LLMs而言,目前尚缺乏一个类似的环境模拟器,能够支持复杂、多轮、长期规划的任务,并提供灵活的观察和动作空间,以及异步并行执行等高级功能。
研究目的:
本研究旨在填补这一空白,通过引入GEM(General Experience Maker)框架,为LLMs提供一个开放源代码的环境模拟器,支持多样化的多轮、长期规划任务。
具体目标包括:
- 提供标准化接口:设计一个类似于OpenAI Gym的标准化环境接口,简化LLMs与环境的交互,促进算法的开发和比较。
- 支持复杂任务:提供多样化的环境套件,涵盖数学推理、代码生成、文本游戏、问答系统等多个领域,支持工具集成和多轮交互。
- 促进RL研究:通过提供基线算法和集成工具,降低RL研究的门槛,加速agentic LLMs的发展。
- 推动实际应用:通过实际应用案例展示GEM在自动化任务完成、数据库操作和终端交互等方面的潜力,推动LLMs在实际场景中的应用。
研究方法
1. 框架设计:
GEM框架的设计灵感来源于OpenAI Gym,旨在提供一个标准化的环境接口,支持LLMs与复杂环境的交互。框架主要包括以下几个核心组件:
- 环境接口:遵循OpenAI Gym API设计,提供
reset()和step()等核心函数,支持异步向量化和模块化包装器。 - 任务和工具:每个环境由任务和可选的工具集构成,支持多步推理、多工具使用和复杂能力测试。
- 异步向量化和自动重置:支持环境的异步并行执行和自动重置机制,提高数据生成效率。
- 包装器:提供灵活的观察和动作包装器,支持自定义状态表示和奖励计算。
2. 算法实现:
为了支持多轮RL任务,GEM实现了多种RL算法,包括REINFORCE、PPO和GRPO等。
特别地,针对多轮交互中的信用分配问题,提出了一种基于回报批归一化(ReBN)的REINFORCE变体,显著提高了算法在多轮任务上的性能。
- REINFORCE with ReBN:在标准REINFORCE算法的基础上,引入了回报批归一化技术,通过对整个批次的回报进行归一化处理,提高了梯度估计的稳定性,从而改善了算法的收敛性。
- 多轮交互处理:针对多轮任务中的状态表示和奖励分配问题,GEM通过收集单个转换(状态、动作、奖励、下一个状态)作为轨迹,支持任意状态观察构造和每步奖励,从而克服了传统方法中的局限性。
3. 基准测试和案例研究:
为了全面评估GEM框架的性能和有效性,研究在多个基准测试和案例研究上进行了实验。
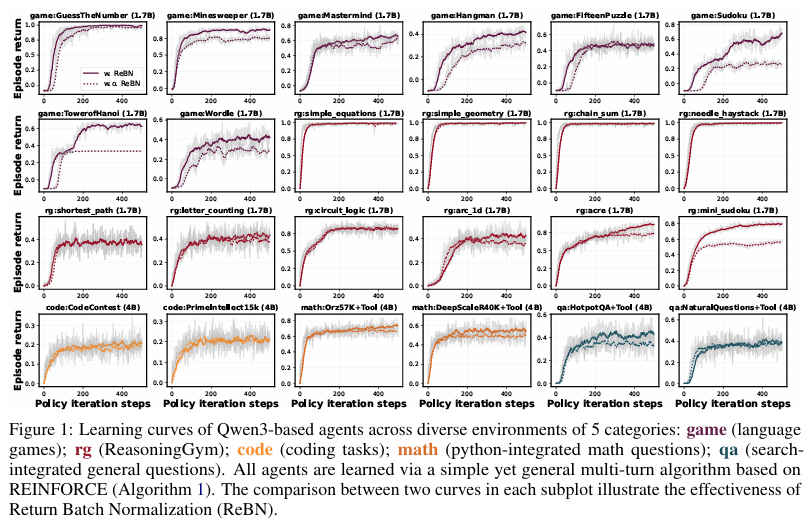
- 基准测试:在八个具有代表性的GEM环境上,对REINFORCE、PPO、GRPO和REINFORCE with ReBN等算法进行了基准测试,比较了它们的平均回合回报、样本效率和稳定性。
- 折扣因子影响分析:通过改变折扣因子γ的值,研究了其对多轮学习的影响,展示了γ<1时算法如何鼓励更高效的解决方案发现。
- 工具集成影响分析:在数学和问答任务中,评估了工具集成对模型性能的影响,展示了工具使用如何显著提高模型的推理能力。
- 跨任务泛化研究:通过在一个任务上训练模型,并在其他相关任务上进行评估,研究了模型的跨任务泛化能力。
研究结果
1. 基准测试结果:
在八个GEM环境上的基准测试中,REINFORCE with ReBN算法在大多数环境中表现最佳,显著优于标准REINFORCE算法,并与PPO和GRPO算法相当或更优。
这一结果展示了ReBN技术在提高多轮RL任务性能方面的有效性。
2. 折扣因子影响:
实验结果表明,较小的γ值能够鼓励模型采用更高效的解决方案,如二分查找策略。
这一发现强调了折扣因子在多轮RL任务中的重要性,为未来的算法设计提供了有价值的指导。
3. 工具集成影响:
在数学和问答任务中,集成外部工具(如Python解释器和搜索引擎)显著提高了模型的性能。
特别是在数学任务中,使用Python工具的模型在所有环境中均表现最佳,展示了工具集成在提升模型推理能力方面的潜力。
4. 跨任务泛化:
在Sudoku任务上训练的模型在其他推理任务(如电路逻辑和最短路径)上展现出一定的泛化能力,表明GEM框架在培养模型通用推理能力方面的有效性。
研究局限
尽管GEM框架在多轮RL任务中取得了显著成果,但仍存在一些局限性:
1. 环境多样性不足:
尽管GEM提供了多样化的环境套件,但相对于现实世界的复杂性而言,仍显得不足。未来的研究需要进一步扩展环境多样性,以更好地模拟现实场景中的挑战。
2. 计算成本较高:
RL训练通常需要大量的计算资源,特别是在处理复杂任务和大规模模型时。尽管GEM通过异步并行执行和自动重置机制提高了数据生成效率,但整体计算成本仍然较高。
未来的研究需要进一步优化算法和框架设计,以降低计算成本。
3. 模型可解释性不足:
尽管LLMs在复杂任务上表现出色,但其决策过程往往缺乏可解释性。未来的研究需要探索如何提高模型的可解释性,以便更好地理解和信任模型的决策。
未来研究方向
1. 扩展环境多样性:
未来的研究应进一步扩展GEM的环境套件,涵盖更多类型的复杂任务,如视觉推理、多模态推理等。
同时,可以探索如何将现实世界中的数据和场景集成到环境中,以提高模型的实用性和泛化能力。
2. 优化算法和框架设计:
针对计算成本较高的问题,未来的研究可以探索如何优化算法和框架设计,以降低计算成本。例如,可以引入更高效的搜索策略、优化重放缓冲区管理、利用硬件加速和分布式计算等技术。
3. 提高模型可解释性:
为了提高模型的可解释性,未来的研究可以探索如何将决策过程可视化、引入注意力机制以揭示模型在决策过程中的关注点、以及利用符号推理和规划技术来增强模型的透明性和可信度。
4. 跨领域迁移学习:
未来的研究可以探索如何将GEM框架应用于其他领域,如视觉推理、多模态推理等。通过跨领域迁移学习,可以利用数学推理领域的研究成果加速其他领域推理模型的发展。同时,可以探索如何设计通用的推理框架,以支持多种类型的复杂任务。
5. 实际应用探索:
未来的研究应积极探索GEM框架在实际应用中的潜力,如自动化软件开发、科学发现、智能助手等领域。通过实际场景的测试和反馈,不断优化和改进GEM框架,提高其实用性和可靠性。同时,可以探索如何将GEM框架与其他技术(如知识图谱、符号推理等)相结合,以进一步提升模型的推理能力和应用范围。
更多推荐

 14
14 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)