
大模型学习笔记:P-tuning
P-tuning系列方法通过将离散提示转化为连续可优化的向量,显著提升了提示工程的效率。P-tuning v1引入Prompt Encoder生成伪提示,实现参数高效微调;P-tuning v2进一步提出深度提示优化,在Transformer每一层添加可训练前缀,增强模型表达能力。
一、P-tuning
P-tuning 是在 Prompt Tuning 思想的基础上提出的一个重要改进,旨在解决手动设计离散 Prompt 的困难,并提升其性能和稳定性。
1. 背景:离散 Prompt 的问题
在 P-tuning 之前,像 GPT-3 等模型主要依赖于离散的、人工设计的提示。例如,要让模型知道“英国”的首都是什么,你可能会构造一个模板:“The capital of Britain is [MASK]”。
这种方法有两个主要问题:
- 设计困难:找到效果最好的提示词非常困难,需要大量的经验和实验,有时甚至像一门“玄学”。一个词的微小变动就可能导致模型性能的巨大差异。
- 优化困难:提示词是离散的文本,无法通过梯度下降等方法进行自动优化,寻找过程效率低下。
2. P-tuning 的核心思想:连续可优化的 Prompt
P-tuning 的核心思想是:用可训练的、连续的向量来替代人工设计的离散提示词,并将这个过程自动化。
它不再去寻找最好的“词语”,而是在连续的向量空间中去寻找最优的“提示向量”,这个过程可以通过梯度下降来完成。这些可训练的向量被称为 “伪提示” (Pseudo Prompts) 或 “虚拟Token” (Virtual Tokens)。
3. P-tuning 的具体做法
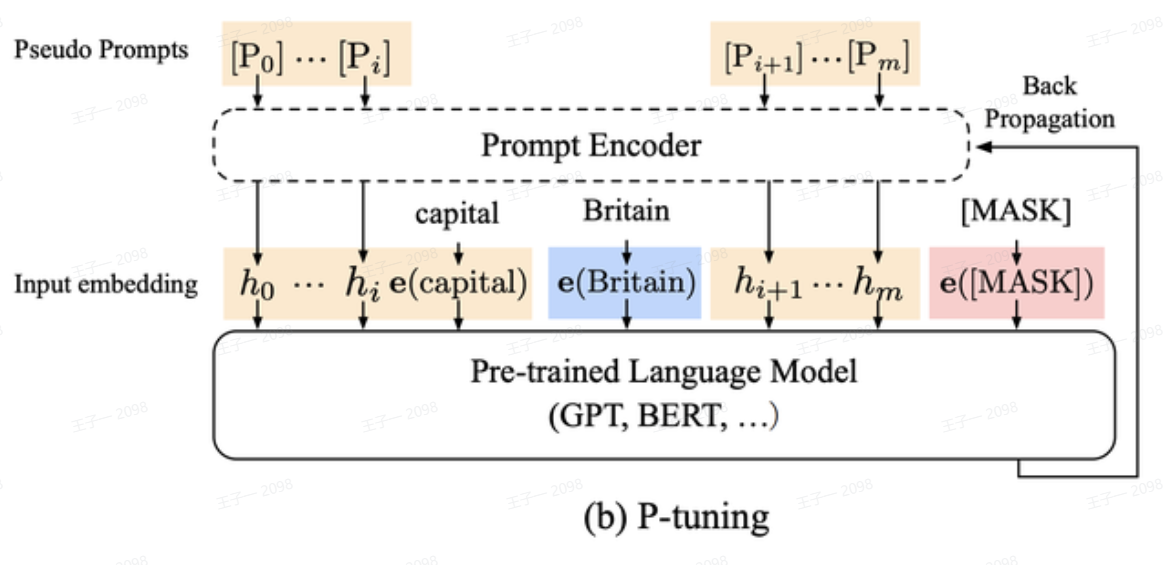
结合上图 (b) P-tuning,其具体流程如下:
-
定义 Prompt 模板:首先,我们依然需要一个模板,但模板中的一部分或全部提示词被替换为可训练的伪提示
[P₀], [P₁], ..., [Pₘ]。例如,模板可以变成[P₀] [P₁] The capital of Britain is [MASK]。 -
引入 Prompt Encoder:这是 P-tuning 的关键创新。它没有直接去优化伪提示的 Embedding,而是引入了一个小型的神经网络——Prompt Encoder (通常是 BiLSTM + MLP)——来生成这些 Embedding。
- 输入:Prompt Encoder 的输入是一些可训练的、初始化的“元提示”。
- 输出:经过 Prompt Encoder (如 LSTM) 处理后,输出最终的、包含上下文依赖关系的伪提示向量
h₀, h₁, ..., hₘ。 - 作用 (Reparameterization):为什么要引入 Prompt Encoder 而不直接训练 Embedding?
- 增加依赖关系:LSTM 能够捕捉到伪提示之间的序列关系,让
hᵢ和hᵢ₊₁之间产生关联,使得生成的提示更连贯、更具表现力。 - 稳定训练:直接优化离散的 Embedding 容易陷入局部最优且不稳定。通过一个小型网络来生成它们,相当于做了一层重参数化 (Reparameterzation),可以让梯度更平滑,训练过程更稳定。
- 增加依赖关系:LSTM 能够捕捉到伪提示之间的序列关系,让
-
拼接并输入大模型:将 Prompt Encoder 生成的提示向量
h₀, ..., hₘ与原始输入文本(如 “capital”, “Britain”)的词嵌入e(capital), e(Britain)进行拼接,形成一个完整的输入序列。 -
冻结大模型进行训练:将拼接后的序列输入到预训练语言模型 (PLM) 的主干中(如 BERT、GPT),并保持 PLM 的参数完全冻结。在训练过程中,只更新 Prompt Encoder 的参数。模型的优化目标是让 PLM 在下游任务(如预测 [MASK] 位置的词)上表现得最好。
4. P-tuning (v1) 的特点与局限
特点与优势:
- 自动化 Prompt 设计:将离散的、困难的提示搜索问题,转化为了连续的、可优化的参数学习问题。
- 参数高效:训练时只需更新 Prompt Encoder 这个小模块的参数,无需改动庞大的预训练模型,极大地降低了计算和存储成本。
- 提升稳定性:通过 Prompt Encoder 的引入,训练过程比直接优化 Embedding 更加稳定。
P-tuning v1是一个开创性的工作,它成功地将离散的 Prompt 转化为连续可优化的向量,并通过 Prompt Encoder 提升了稳定性和效果。但它的作用停留在模型浅层,这限制了其在更复杂任务上的性能,从而催生了在模型每一层都施加影响的 P-tuning v2。
P-tuning v2 是对早期参数高效微调方法(如 Prompt Tuning 和 P-tuning v1)的重大改进,旨在解决它们在通用性、稳定性和性能上的不足,使其成为一个更接近全量微调(Full Fine-tuning)效果的替代方案。
1. 背景:P-tuning v1 和 Prompt Tuning 的问题
首先,要理解 P-tuning v2,我们需要知道它解决了什么问题。如您图片第一部分所述,早期的 Prompt Tuning 和 P-tuning v1 主要存在以下几个核心问题:
- 缺乏通用性 (Lack of Universality):它们在较小规模(例如 10 亿参数以下)的模型和一些简单的自然语言理解(NLU)任务上表现尚可,但一旦模型规模增大或任务变得复杂(如序列标注),性能就会远不如全量微调。
- 缺乏鲁棒性 (Lack of Robustness):微调的效果对超参数(如学习率、prompt 长度)的选择非常敏感,训练过程不稳定,难以复现最佳效果。
- 缺少深度提示优化 (Lack of Deep Prompt Influence):这是最关键的一个问题。如下图 (a) 所示,传统的 Prompt Tuning 只是在输入层(Embedding 层之后)加入了可训练的 prompt-embedding。这些 prompt 参数只在模型的最底层发挥作用,无法在 Transformer 的每一层对模型的计算过程进行深度的、持续的引导和影响。这极大地限制了 prompt 所能提供的任务相关信息量,导致可优化的参数量非常少(通常仅占总参数的 0.01%),难以适配复杂的任务。
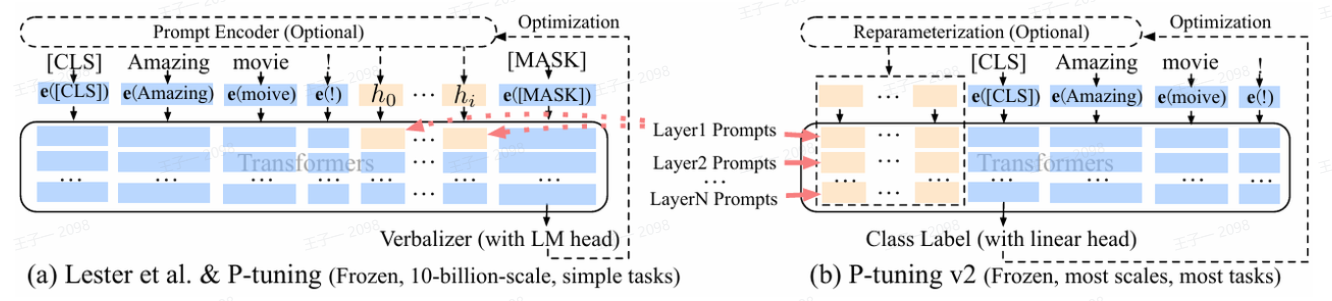
图解:(a) 为 P-tuning v1/Prompt Tuning,prompt 只在输入层添加;(b) 为 P-tuning v2,prompt 在每一层都作为前缀 (prefix) 添加。
二、P-tuning v2
1. P-tuning v2 的核心原理与做法
针对上述问题,P-tuning v2 提出了一个核心思想:深度提示优化 (Deep Prompt Tuning),其本质上更接近于 Prefix-Tuning 的思想。
Prefix-Tuning 是与 P-tuning v2 思想极为相似的另一种经典的参数高效微调方法。传统微调(Fine-Tuning)是修改整个大模型(比如 BERT 或GPT)的所有参数来适应新任务。这种方式成本高昂,每个任务都需要存储一个完整的模型副本。
Prefix-Tuning提出了一种全新的思路:冻结预训练语言模型的全部参数,只为新任务额外学习一个小的、连续的、任务特定的“前缀”(Prefix)向量。 这个“前缀”不像 Prompt Tuning 那样只加在输入层,而是巧妙地 注入到 Transformer模型的每一层中,像一个“引导员”一样,在模型的每一步计算中都告诉模型:“现在正在做XX任务,请注意这些方面”。
Prefix-Tuning 的核心操作对象是 Transformer结构中的多头自注意力机制。我们知道,自注意力机制的核心是三个矩阵:查询(Query, Q)、键(Key, K)和值(Value,V)。模型通过计算 Q 和 K 的相似度来决定 V 中每个部分的权重。
Prefix-Tuning 的做法如下:
- 冻结大模型:首先,将巨大的预训练语言模型(PLM)的参数完全冻结,在整个微调过程中不进行任何更新。
- 创建 Prefix:为特定任务初始化一小段可训练的参数,我们称之为 Prefix。这段 Prefix 实际上是一组向量序列,例如
P₀, P₁, ..., Pₗ。- 注入 Prefix 到每一层:在 Transformer 的每一层,将 Prefix 向量拼接到该层自注意力机制的 Key (K) 和 Value (V) 矩阵的前面。
原始的 Key 矩阵:
K = [k₁, k₂, ..., kₙ](来自输入文本)、原始的 Value 矩阵:V = [v₁, v₂,..., vₙ](来自输入文本)注入 Prefix 后,它们变成了:新的 Key 矩阵:
K' = [pᵏ₀, pᵏ₁, ..., pᵏₗ, k₁, k₂, ..., kₙ]、新的 Value 矩阵:V' = [pᵛ₀, pᵛ₁, ..., pᵛₗ, v₁, v₂, ..., vₙ]。这里的pᵏ和pᵛ就是从可训练的 Prefix 参数中生成的。通过这种方式,当模型的 Query 向量(来自原始输入文本)在计算注意力分数时,它不仅能关注文本自身的内容,还能关注到这些任务特定的Prefix 向量。因为这些 Prefix 是可学习的,模型会通过训练,让它们自动编码最适合当前任务的“引导信息”。由于每一层都加入了Prefix,这种引导是持续的、深度的。
下面是其具体的做法和原理:
核心做法:在模型的每一层都添加可训练的 Prompt
与只在输入层添加 prompt 的做法不同,P-tuning v2 的核心改动是将可训练的 prompt-embedding 作为前缀 (Prefix) 添加到 Transformer 模型内部的每一层。
具体来说:
- 输入层:和之前一样,在输入的词嵌入序列前,拼接上一段可训练的 prompt 向量。
- Transformer 的每一层:在将上一层的输出(Key 和 Value 矩阵)送入到下一层的多头注意力(Multi-Head Attention)模块之前,都在序列的开头拼接上对应当前层的、可训练的 prompt 向量。
如上图 (b) 所示,这些 Layer i Prompts 是独立于输入 prompt 的、属于每一层自己的、可训练的参数。
这种做法带来的原理性优势:
- 增强表达能力:通过在每一层都引入任务相关的可训练参数,P-tuning v2 极大地增加了微调过程中的参数量(通常占模型总参数的 0.1% ~ 3%)。这使得模型有更大的容量来学习和适应新任务,从而在效果上逼近全量微调。
- 深度影响模型:prompt 不再是只在第一层起作用的“浅层指令”。它在每一层都像一个“引导员”,持续地影响该层对上下文的理解和表示,从而更精确地调整模型的行为以适应特定任务。
- 提升通用性:这种“深度”的参数注入方式,使得 P-tuning v2 不再局限于简单的 NLU 分类任务。它可以很好地处理复杂的、需要对每个 token 进行预测的序列标注任务(如命名实体识别)。这是因为它能影响到每个 token 在每一层的输出表示,而不仅仅是
[CLS]位的最终表示。
其他重要改进:
-
抛弃 Reparameterization:在 P-tuning v1 中,为了稳定训练和减少 prompt 编码的离散性,曾使用了一个 MLP 或 LSTM 来生成 prompt-embedding。P-tuning v2 的作者发现,随着模型规模的增大和深度提示优化的引入,这种复杂的重参数化结构(如 MLP)不再是必需的,甚至有时会损害性能。因此,P-tuning v2 将其移除,直接将 prompt-embedding 作为可训练参数,简化了模型。
-
抛弃 Verbalizer:对于分类任务,一些 prompt-based 方法需要一个 “Verbalizer”,即一个将类别标签映射到词汇表中的具体单词的模块。这限制了方法的通用性,因为设计好的 Verbalizer 本身就很困难,而且对于序列标注这类没有固定类别标签的任务根本不适用。P-tuning v2 抛弃了对 Verbalizer 的依赖,直接在模型顶层接一个线性的分类头(Linear Head),就像传统的微调一样,对输出的
[CLS]token 或每个 token 的表示进行分类。这使其能够自然地适配任何任务。
3. P-tuning v2 的优势总结
总结来说,P-tuning v2 相比于之前的 Prompt-based 方法,具有以下显著优势:
- 性能强大:在各种规模的模型和多样化的任务上,都能取得与全量微调相当甚至更好的性能。
- 通用性强:一个统一的框架即可解决各种自然语言任务,包括文本分类、序列标注、问答等,无需为不同任务做特殊设计。
- 训练稳定:相比 P-tuning v1 更加稳定,鲁棒性更好,对超参数不那么敏感。
- 参数高效:依然保持了参数高效的特性,每个任务只需存储少量(约 0.1%~3%)的 prompt 参数,极大地节约了存储成本,便于模型的部署和管理。
因此,P-tuning v2 可以被看作是一个更成熟、更通用、更强大的参数高效微调框架,是全量微调的一个非常有竞争力的替代方案。
更多推荐


 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)