
打造自主学习的AI Agent:强化学习+LangGraph代码示例
本文会从RL的数学基础讲起,然后深入到知识图谱的多跳推理,最后在LangGraph框架里搭建一个RL驱动的智能系统。
在充满不确定性的现实世界里,AI的价值不在于预设规则,而在于持续学习和适应
AI Agent这个概念最近被炒得很热,从管理日程的语音助手到仓库里跑来跑去的机器人,大家都在谈论Agent的"自主性"。但是真正让Agent变得intelligent的核心技术,其实是强化学习(Reinforcement Learning, RL)。
想象一下自动驾驶汽车在复杂路况中的决策,或者量化交易系统在市场波动时的操作——这些场景的共同点是什么?环境动态变化,规则无法穷尽。传统的if-else逻辑在这里完全失效,而RL恰好擅长处理这类问题。它让Agent像人一样,从试错中学习,在探索(exploration)和利用(exploitation)之间找平衡。
本文会从RL的数学基础讲起,然后深入到知识图谱的多跳推理,最后在LangGraph框架里搭建一个RL驱动的智能系统。
RL的底层逻辑:马尔可夫决策过程
教机器人玩游戏的过程其实很像教小孩骑自行车——没人会给它写一本"如何骑车的完整手册",而是让它自己试,摔了就爬起来再试,在练习的同时我们给予帮助,如果做对就鼓励,做错了给个提示应该怎么做,这样慢慢他就学会了,而RL的数学框架就是根据这个流程设计的。
RL的核心是Markov Decision Process(MDP),它把决策过程拆成几个要素:状态(State)、动作(Action)、转移概率(Transition)、奖励(Reward)和折扣因子(Discount Factor)。形式化表示是个五元组 (S, A, P, R, γ)。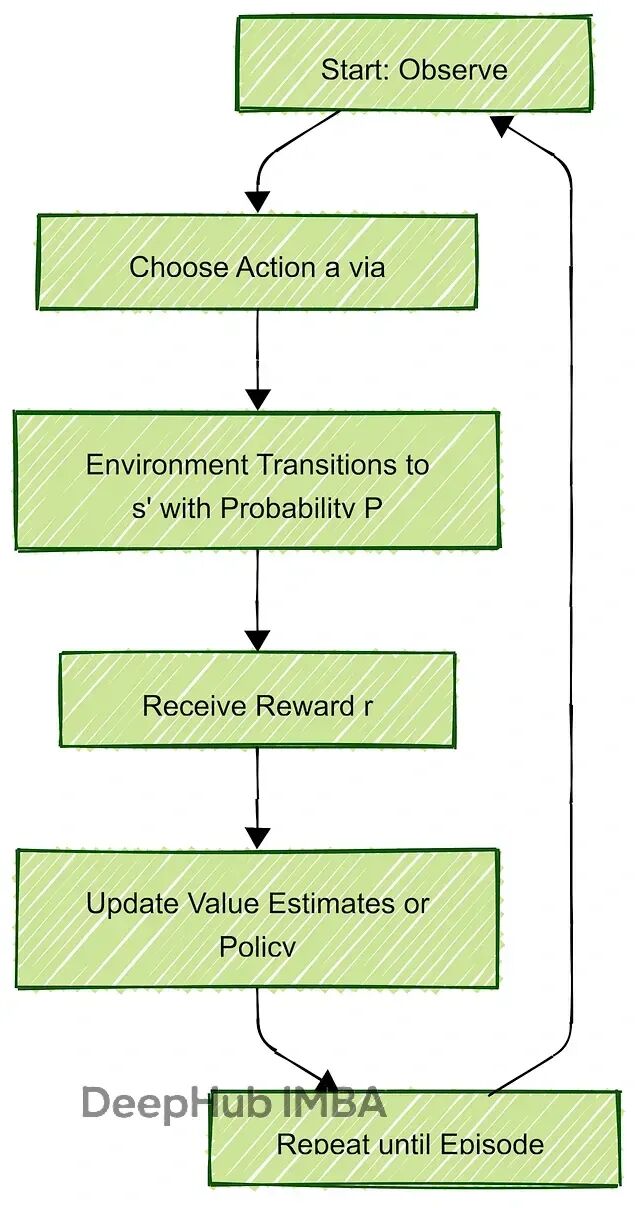
**State(状态集合 S)**就是"现在是什么情况"。比如对于一个走迷宫的机器人,状态可能就是它在网格上的坐标(3,5);而对于自动驾驶系统,状态会复杂得多——车速、位置、周围障碍物、天气情况等等都得考虑进去。状态可以是离散的(grid position),也可以是连续的(speed from 0 to 100 mph)。
**Action(动作集合 A)**知道自己的状态后,下一步能干什么?走迷宫的机器人只有上下左右四个选择,但一个优化仓库作业的物流Agent可能要在"取包裹A"、“送到货架B”、"等待库存更新"等等决策之间做选择。动作空间的设计直接影响学习难度。
**Transition Probability(转移概率 P(s’|s,a))**这个概念很关键但经常被忽略。在理想状态下,机器人"向右走"就一定会到右边的格子;但现实世界有噪音——地面可能很滑,有80%概率到达目标位置,10%概率滑到上面,10%滑到下面。P函数描述的就是这种不确定性,输出的概率总和为1。没有这个,RL根本应付不了真实环境的复杂度。
**Reward(奖励函数 R(s,a,s’))**Reward是个标量,可能是+10或-5,Agent通过它就可以知道刚当前操作后的好坏。比如取到球了?+1。撞墙了?-1。商业场景里奖励设计更直接——准时送达+50,燃油浪费-20。
不过奖励设计是个大坑。太稀疏(只有最终结果有反馈)会让Agent瞎转悠找不到方向;太密集(每一步都给分)又容易让它钻空子,比如游戏AI可能会发现原地打转能刷小分,就跟游戏里面我们找到漏洞后刷分一样,AI也会刷份。
**Discount Factor(折扣因子 γ)**γ取值在[0,1]之间,决定了Agent有多"远视"。γ=0的话Agent只看眼前利益,γ=1则会无限规划未来(计算量爆炸)。实际应用中通常设0.9或0.99,比如股票交易系统既要抓短期机会,又不能为了眼前收益把整个portfolio搞崩。
这五个要素支撑起了Q-Learning、SARSA这些经典算法。Q-Learning是off-policy的,可以从任何动作的经验中学习;SARSA是on-policy的,只从实际执行的动作学习。对Agent来说,Partially Observable MDP(POMDP)更贴近现实——系统必须从有限观测推断隐藏状态,就像人在信息不完整时做判断。
知识图谱的多跳推理
知识图谱(Knowledge Graph)本质上是个大网络,节点代表实体(entity),边代表关系(relation)。“巴黎"通过"capital_of"连到"法国”,“法国"通过"located_in"连到"欧洲”——这种结构让AI可以做复杂的关联查询。

但是问题就来了:面对"埃菲尔铁塔所在国家的首都人口是多少"这种query,Agent需要跳好几步——从Eiffel Tower → located_in → France → capital → Paris → population。路径很多,怎么选最优的?如果暴力遍历,那么在大规模KG上根本跑不动。
RL就来了,它把图遍历建模成MDP:当前节点是state,选择哪条边是action,到达目标节点给正reward,走错路给负reward。Agent经过训练后能学会高效路径,不用每次都试遍所有可能。
Reward shaping在这里尤其重要。基础设定可能是"到终点+10,其他步骤0",但是这样太稀疏了,Agent在大图里会迷路。更好的做法是给中间步骤也设奖励——比如每接近目标一步就+1,偏离就-0.5。关键是这些额外奖励不能改变最优策略的本质,只是引导探索方向,就像给登山者设的路标并不妨碍他发现更好的路线。
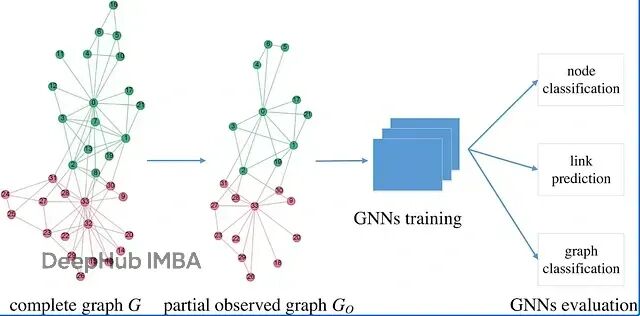
Graph Neural Network(GNN)经常和RL搭配使用。GNN把每个节点的邻域信息压缩成embedding vector,这个vector再喂给RL系统做value prediction。本质上是把图的拓扑结构编码成数值表示,让决策更快更准。
实际应用场景很多。医疗KG里有疾病、症状、治疗、药物等节点,关系包括"causes"、"treats"等。RL Agent可以从症状出发,跳转到可能的诊断,最后找到合适疗法——奖励快速准确的路径(少做不必要检查),惩罚风险路径(不推荐过时药物)。供应链网络也类似,节点是供应商和产品,边是依赖关系,RL可以学习避开瓶颈,优化库存调度。
LangGraph实例:把RL嵌入工作流
LangChain做的是把不同AI组件串起来(call LLM → query database → use tool),LangGraph更进一步,让你把workflow设计成有向无环图(DAG)。不是硬编码每条路径,而是把RL Agent嵌到节点里,让整个图变成动态决策系统。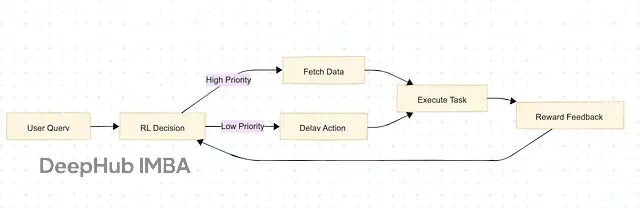
比如云计算的资源调度场景,节点可能代表不同服务器或任务(“allocate CPU to email processing”),RL Agent在关键节点学习"分配更多算力"或"迁移负载"这类动作,奖励基于系统运行指标(低延迟high reward,crash或overload则penalty)。
下面我们模拟在线教育平台选课逻辑。有三个topic(math, science, history),每个都有urgency score表示学生的需求程度,Agent要选出最该教的内容。
安装依赖
pip install langgraph langchain torch gym numpy
用Gym框架定义练习空间。State是三个topic的urgency向量,比如[0.7, 0.2, 0.9]——数值越高越紧迫;Action是选择topic 0/1/2;Reward设计成负值,鼓励Agent优先选高紧迫的(最小化负loss);Episode在所有topic都mastered时结束。
import gym
from gym import spaces
import numpy as np
class LearningEnv(gym.Env):
def __init__(self):
# Actions: Pick topic 0,1,2 to teach
self.action_space = spaces.Discrete(3)
# State: Urgency levels (0 calm, 1 urgent) for three topics
self.observation_space = spaces.Box(low=0, high=1, shape=(3,))
# Start random, like a new student's needs
self.state = np.random.rand(3)
def step(self, action):
# Reward: negative scaled by urgency (high urgency = less negative = better)
reward = -self.state[action] * 10
# Update: teaching halves urgency
self.state[action] *= 0.5
# Done when all topics below 0.1
done = all(s < 0.1 for s in self.state)
return self.state, reward, done, {}
def reset(self):
self.state = np.random.rand(3)
return self.state
这里做个简单的说明:
gym.Env
提供了标准接口,有step(执行动作获取反馈)和reset(重新开始)
Discrete action space让选择简单直接;Box state允许连续值(实际数据可以normalize到0-1)
Reward的负值设计:urgency 0.9对应-9(“还行”),0.1对应-1(“糟糕”),Agent会学着最小化这个loss
每次teaching把urgency减半,模拟学习进度
reset对repeated training很关键,避免数据污染
我们这里选择搭建Actor-Critic架构。Actor输出动作概率分布,Critic评估状态价值。用PyTorch实现,保持轻量。
import torch
import torch.nn as nn
import torch.optim as optim
class TutorPolicy(nn.Module):
def __init__(self, obs_size, act_size):
super().__init__()
# Actor: state to action probabilities
self.actor = nn.Sequential(
nn.Linear(obs_size, 64),
nn.ReLU(),
nn.Linear(64, act_size),
nn.Softmax(dim=-1) # probabilities sum to 1
)
# Critic: state to value estimate
self.critic = nn.Sequential(
nn.Linear(obs_size, 64),
nn.ReLU(),
nn.Linear(64, 1) # single value output
)
def forward(self, obs):
probs = self.actor(obs)
value = self.critic(obs)
return probs, value
网络结构分析:
Actor部分:Linear层做线性变换,ReLU引入非线性(学习复杂模式),Softmax保证输出是合法概率分布
Critic部分:类似结构但输出单个value,用来估计当前state的期望回报
forward()是推理过程,输入状态张量,输出action probs和value estimate
这里有一个注意的地方,obs必须是torch.tensor格式,否则会报错。如果看到nan输出,请检查输入类型。
有了环境和模型,开始训练。循环跑episodes,根据reward更新参数。
def train_tutor(env, policy, optimizer, epochs=200):
for epoch in range(epochs):
obs = torch.tensor(env.reset(), dtype=torch.float32)
done = False
episode_reward = 0
while not done:
probs, value = policy(obs)
action = torch.multinomial(probs, 1).item() # sample for exploration
next_obs, reward, done, _ = env.step(action)
next_obs = torch.tensor(next_obs, dtype=torch.float32)
episode_reward += reward
# Loss computation
policy_loss = -torch.log(probs[action]) * reward # REINFORCE gradient
value_loss = (reward - value)**2 # TD error squared
loss = policy_loss + value_loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
obs = next_obs
if epoch % 20 == 0:
print(f"Epoch {epoch}: Reward = {episode_reward:.2f}")
# Initialize and train
env = LearningEnv()
policy = TutorPolicy(3, 3)
optimizer = optim.Adam(policy.parameters(), lr=0.001)
train_tutor(env, policy, optimizer)
训练逻辑如下:
外层循环是epoch,每次reset环境开始新episode
内层while循环是单个episode的gameplay:模型推理→采样动作(multinomial保证exploration)→环境反馈→记录reward
Loss由两部分组成:policy_loss基于REINFORCE算法(-log prob * reward,放大好动作概率);value_loss是TD error的平方(拟合value估计)
标准的梯度下降三步走:zero_grad清空旧梯度→backward计算新梯度→step更新参数
Print观察训练效果,reward从-40涨到-15说明策略在优化(负得少=选得准)
训练完成后把模型部署到workflow里,作为决策节点。
from langgraph.graph import Graph, END
def rl_teach(state):
obs = torch.tensor(state['urgencies'], dtype=torch.float32)
probs, _ = policy(obs)
action = torch.argmax(probs).item() # greedy selection
return {"next_lesson": action}
graph = Graph()
graph.add_node("assess_student", lambda state: {"urgencies": np.random.rand(3)})
graph.add_node("plan_lesson", rl_teach)
graph.add_node("deliver_content", lambda state: {"done": True, "taught": state["next_lesson"]})
graph.add_edge("assess_student", "plan_lesson")
graph.add_edge("plan_lesson", "deliver_content")
graph.add_edge("deliver_content", END)
compiled_graph = graph.compile()
result = compiled_graph.invoke({})
print("Lesson Plan:", result) # e.g., {'done': True, 'taught': 2}
Graph构建要点:
rl_teach
是核心决策节点,读取state里的urgencies,用训练好的policy推理,选概率最高的action(部署时用greedy,训练时要exploration)
节点用lambda定义简单任务,复杂逻辑就定义函数
add_edge定义数据流向;也可以用add_conditional_edges加条件分支(比如"if urgency>0.7, rush course")
compile()把图结构编译成可执行对象,invoke()触发运行
这样就完成了。
如果我们后续扩展,可以加个LLM节点生成lesson explanation,在真实学生数据上训练policy,或者接入更复杂的reward shaping(考虑学生历史表现、知识依赖关系等)。训练后的Agent会自动prioritize高urgency topic,不需要手动写规则。
总结
RL不是什么黑科技,但确实能让Agent在不确定环境里真正intelligent起来。配合LangGraph这类框架,可以把RL无缝嵌入实际业务流程。RL和LLM结合(比如RLHF做alignment)能搞出既会优化路线,又能用自然语言解释决策的混合agent——这才是agentic AI该有的样子。
参考资料
https://avoid.overfit.cn/post/7f95145bedf4402daa3704ed1dca21d8
作者:Samvardhan Singh
更多推荐
 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)