
3分钟了解大模型(LLM)四大核心建模流程
未来,随着技术的发展,LLM的建模流程可能会进一步优化,但数据奠基、通用学习、任务专精、落地应用的核心逻辑不会改变。
在当今数字时代,大语言模型(LLM)已成为重塑人机交互的核心技术。然而,这些看似智能的AI系统并非天生具备理解与生成语言的能力,而是源于一套严谨、复杂的多阶段建模流程:
-
阶段1:预处理,为模型打扫原料,奠定训练基础
-
阶段2:预训练,让模型通读万卷书,掌握通用语言能力
-
阶段3:微调,让模型专精某一行,适配具体任务
-
阶段4:部署与推理,让模型走进现实,实现落地价值
本文将系统拆解LLM建模的四大核心阶段,详解每个环节具体任务,并对比两类主流模型的差异,为理解LLM的工作原理提供清晰框架。
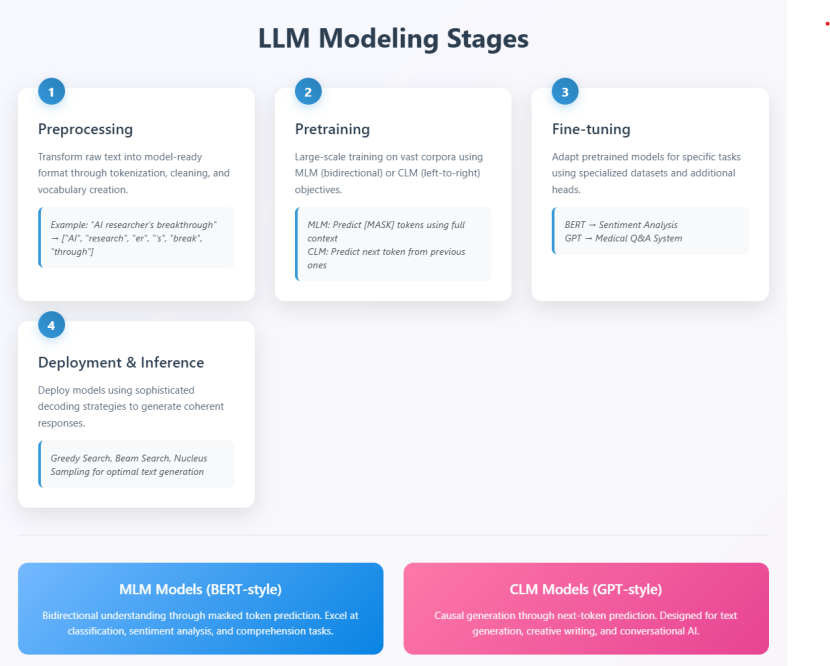
阶段1:预处理,奠定模型基石
任何AI模型的性能都离不开高质量的数据,LLM也不例外。预处理阶段的核心任务,是将原始文本原料(如网页内容、书籍、论文等)转化为模型能读懂的结构化格式,相当于为后续训练搭建地基。这一阶段的质量直接决定了模型对语言的理解精度,若预处理不到位,即便后续模型架构再先进,也可能出现理解偏差。
具体来看,预处理主要包含两大关键步骤:
1.文本分词:将语言拆为模型的“最小理解单位”
人类以“词语”为单位理解语言,但LLM需将文本拆分为更精细的“词元(Token)”,这是模型处理语言的基本单元。目前最主流的分词算法是字节对编码(BPE),其优势在于能平衡词汇表大小与未登录词处理能力,既不会因词汇表过大导致训练效率低下,也能通过子词组合处理生僻词或新造词。更多内容可阅读《说人话之什么是Token?》
2.数据清洗:剔除杂质,保障语料质量
原始文本中往往包含大量无用信息,如网页的HTML标签、乱码的Unicode字符、无意义的特殊符号,甚至违规或低俗内容。这些杂质会干扰模型学习,导致其生成错误或不当内容。因此,预处理阶段需通过自动化工具与人工审核结合的方式,完成去标签、标准化字符、过滤违规内容等操作。
阶段2:预训练,掌握通用语言能力
如果说预处理是准备原料,那么预训练就是教会模型理解语言的核心环节。这一阶段的目标,是让模型在海量通用文本语料上学习语言的底层规律,包括语法结构、语义逻辑、上下文关联,最终形成具备通用语言能力的基础模型。形象地说,预训练相当于让模型通读万卷书,积累足够的语言知识,为后续适配具体任务打下基础。
预训练的核心是训练目标设计,目前主流的目标有两类,直接决定了模型的核心能力方向:
1.掩码语言建模(MLM):双向理解,擅长读
MLM是BERT类模型的核心训练目标,其思路是故意掩盖句子中的部分Token,让模型根据上下文预测被掩盖的内容。例如,将句子“人工智能能改变世界”中的“能”字掩盖后,模型需结合“人工智能”和“改变世界”的双向上下文,预测出“能”字。这种双向学习的方式,让模型更擅长理解文本的整体含义,尤其适合文本分类、情感分析、问答等需要深度理解的任务。
2.因果语言建模(CLM):单向预测,擅长写
CLM是GPT类模型的核心训练目标,其思路是让模型根据前文预测下一个Token,即从左到右逐词生成。例如,给定“今天天气很好,我打算去”,模型需根据“今天天气好”的前文逻辑,预测出“公园”“散步”等合理的下一个Token。这种单向学习的方式,让模型更擅长捕捉文本的生成逻辑,尤其适合对话生成、创意写作、代码编写等需要连贯生成的任务。
无论采用哪种目标,预训练的语料规模都极为庞大(通常以“万亿词”为单位),训练周期长达数周甚至数月,需要依托大规模GPU集群完成。正是通过这种海量数据+长期训练,模型才能从不懂语言成长为能理解、会预测的通用语言系统。
阶段3:微调,针对特定任务专精化
预训练模型虽具备通用语言能力,但面对情感分析、医疗问答、法律文档审核等具体场景时,仍显得不够专业,比如通用GPT模型无法精准回答“糖尿病患者如何控制饮食”这类医疗问题,因为它缺乏医疗领域的专业知识。而微调阶段的目标,就是让预训练模型专精某一行,通过在小规模专业语料上的针对性训练,快速适配具体任务。
微调的核心逻辑是利用已有知识,学习专业技能,具体流程包含三步:
1.选择专业语料,聚焦目标任务
微调的语料无需像预训练那样海量,但需高度贴合任务场景。例如,若要将模型微调为医疗问答助手,需收集医患对话记录、医学指南文档、权威健康科普文本等专业语料。
2.添加任务专属结构,适配任务输出需求
预训练模型的输出Token概率分布,无法直接满足具体任务的输出格式(如分类任务需要正面/负面标签,问答任务需要具体答案文本)。因此,微调阶段需为模型添加任务专属头(Task-Specific Head)。
3.轻量化训练,高效适配,避免遗忘
微调的训练强度远低于预训练,通常只需训练几个轮次(Epochs),且会降低模型的学习率,避免因训练过度导致模型遗忘预训练阶段学到的通用语言能力。
阶段4:部署与推理,实现模型落地价值
经过预处理、预训练、微调后,模型已具备特定任务的能力,但仍处于离线状态,无法为用户提供服务。部署与推理阶段的目标,是将模型投入生产环境,让其在真实场景中实时响应需求,实现从技术到价值的转化。这一阶段的核心是推理过程优化,具体包含两大步骤:
1.概率计算:模型如何思考下一个输出
当用户输入提示后,模型会先将提示转化为Token序列,再为词汇表中的每个Token计算出现概率,形成概率分布,该分布反映了在当前语境下,每个可能的下一个Token的出现概率;
2.解码策略:将概率转化为连贯文本
概率分布只是数字,需要通过解码策略转化为用户能理解的文本。不同的解码策略对应不同的输出效果,需根据任务需求选择:
-
贪心搜索(Greedy Search):每一步选择概率最高的Token,速度快但结果易重复。
-
束搜索(Beam Search):同时保留多个高概率候选序列,最终选择整体最优的结果。
-
核采样(Nucleus Sampling):仅从概率最高的前P%词元中随机采样,平衡多样性与连贯性。
值得注意的是,GPT类因果语言模型的推理过程采用自回归生成,即逐Token生成文本,前一个Token的输出会作为后一个Token的输入,确保最终生成的内容与用户提示上下文连贯。
两类LLM模型家族的对比:理解型vs生成型
通过上述四个阶段的建模流程,最终形成了两类用途各异的语言模型家族,二者的核心差异与适配场景如下:
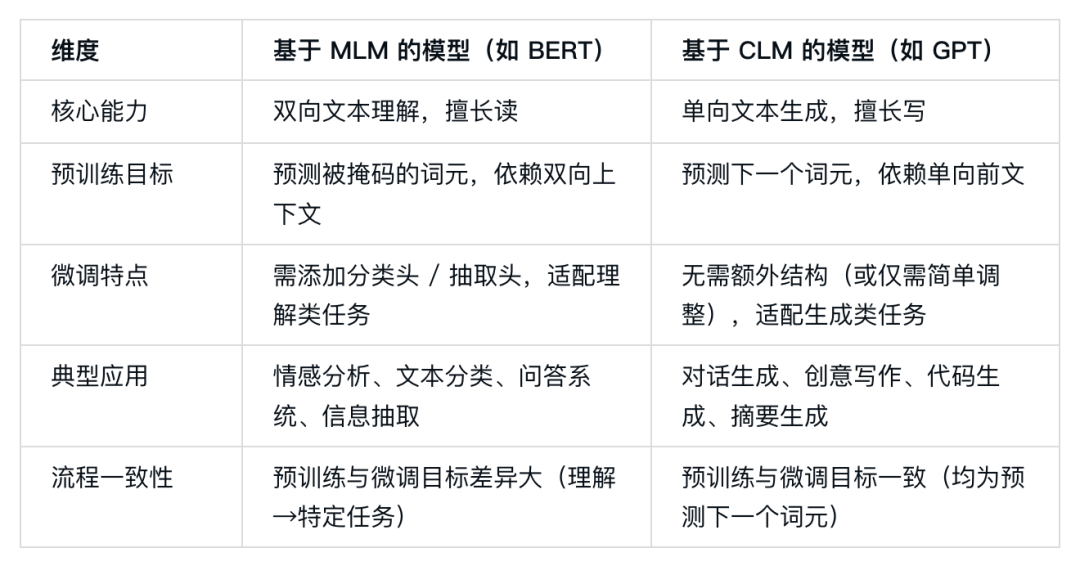
从本质上看,选择哪种模型并非取决于规模大小,而是取决于任务需求。若需要模型理解文本并判断/提取信息,则选择BERT类理解型模型;若需要模型生成连贯文本,则选择GPT类生成型模型。
小结
LLM的四阶段建模流程:预处理(奠基)、预训练(学通用)、微调(专任务)、部署与推理(落地)是一个从数据到价值的完整闭环。每个阶段环环相扣,预处理的质量决定预训练的效率,预训练的基础决定微调的上限,微调的效果决定部署后的用户体验。未来,随着技术的发展,LLM的建模流程可能会进一步优化,但数据奠基、通用学习、任务专精、落地应用的核心逻辑不会改变。
参考链接:
https://vitalflux.com/large-language-models-llms-four-critical-modeling-stages/
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?
别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明:AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。


四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!
更多推荐
 13
13 0
0- 0



 已为社区贡献152条内容
已为社区贡献152条内容

所有评论(0)