
超越RAG:从知识检索到上下文工程,构建生产级AI应用
【摘要】从RAG的知识检索到上下文工程的智能构造,是AI应用迈向生产级的关键一步。通过系统化地设计、管理和优化上下文,我们能构建更可控、可靠且高效的智能系统,真正释放大模型的业务价值。
【摘要】从RAG的知识检索到上下文工程的智能构造,是AI应用迈向生产级的关键一步。通过系统化地设计、管理和优化上下文,我们能构建更可控、可靠且高效的智能系统,真正释放大模型的业务价值。

引言
RAG(检索增强生成)曾被视为连接外部知识与大模型能力的完美桥梁。它简单直接,效果显著。但随着业务场景的复杂度指数级攀升,我们发现,单纯的“检索-拼接”模式开始捉襟见肘。它的局限性,如同在高速公路上行驶的汽车却只有一个后视镜,无法应对复杂路况。
此时,**Context Engineering(上下文工程)**应运而生。它并非要颠覆RAG,而是对其进行了一次彻底的系统化升级。它重新定义了“知识注入”的方式,推动我们从简单的“信息检索”走向精密的“上下文构造”,从机械的“文本拼接”走向深度的“语义理解”。最终的目标,是让上下文成为驱动AI决策的真正生产力。
这篇文章将带你走过从RAG到Context Engineering的完整演进路径。我们将一起揭示其背后的技术逻辑与产品思维,帮助你在构建企业级智能应用时,少踩一些坑,更快地看到成果。
一、🎯 企业落地的核心诉求与现实挑战

我们在探索一个根本问题,大模型如何真正落地到企业生产场景,为业务创造实实在在的价值。当一个AI项目跑通POC(概念验证),准备投入真金白银进行建设时,业务方通常会提出几个朴素却严苛的要求。
1.1 生产级应用的三大基石
这些要求可以概括为对系统可靠性的三个核心拷问。
|
核心诉求 |
具体要求 |
|---|---|
|
输出可靠 |
结果必须稳定且准确率高。结论需要有理有据,能够追溯到原始数据和分析过程。用户必须有渠道可以反馈和校准结果,形成闭环。 |
|
分析及时 |
决策分析必须基于最新的实时数据、行业专业数据和企业内部的专有数据。在特定场景下,还需要根据用户角色和历史对话上下文进行个性化分析。 |
|
数据可信 |
作为分析基础的原始数据必须真实、可靠。与核心任务相关的数据源,不仅要真实,还应尽可能充分和全面,避免因数据缺失导致偏见。 |
1.2 大语言模型的固有“缺陷”
与此同时,我们必须清醒地认识到,当前广泛应用的生成式AI模型,其本身存在着难以回避的局限性。
-
知识的局限性
模型的知识完全来源于它的训练数据。训练数据的时效性、完整性和质量,直接决定了模型输出的天花板。过时的数据会导致错误的判断,不完整的数据会造成视野盲区,低质量的数据则会污染模型的“世界观”。 -
生成的随机性
LLM的本质是基于概率分布来生成文本,它追求的是语言上的连贯与合理,而不是事实上的正确。它的评测和奖励机制,在某种程度上,是奖励“聪明的猜测”而非“诚实的未知”。这导致模型对知识的“了解”和人类的“理解”存在本质差异,尤其在需要深度逻辑和专业知识的领域,它常常准备不足。 -
上下文的脆弱性
在生产实践中,一个常见的现象是,随着输入给模型的Token(文本单元)数量增多,当超过某个临界值后,模型输出的质量和准确性会明显下降。这背后原因复杂,包括模型自身处理长上下文的能力局限、错误的提示词引导、上下文中的噪声信息干扰,以及模型在组合与泛化多源知识时的失败。这些因素共同导致了AI最令人头疼的问题——幻觉(Hallucination)。
正是为了弥合企业复杂需求与大模型原生能力之间的巨大鸿沟,降低AI幻觉,提升应用在真实生产环境中的能力,我们引入了RAG,并逐步走向了更广阔的Context Engineering。
二、⚙️ RAG:为模型补上“外部知识”的第一步
RAG(Retrieval-Augmented Generation,检索增强生成)的理念非常直观。它做的就是字面上的事情,在LLM生成答案之前,先去外部知识库里检索(Retrieval)相关的知识,然后把这些知识作为上下文,来增强(Augmented)给LLM的提示词,最后让LLM基于这个更丰富的提示词去生成(Generation)内容。
判断一个场景是否适合使用RAG,关键在于看大模型的输出是否需要参考一个动态、频繁更新的知识库。比如,需要依赖实时变化的背景数据、企业内部动态更新的本地知识、最新的市场信息或政策法规等。
2.1 RAG的核心工作流
一个相对完备的RAG方案,其内部的工作流程可以用下图来表示。
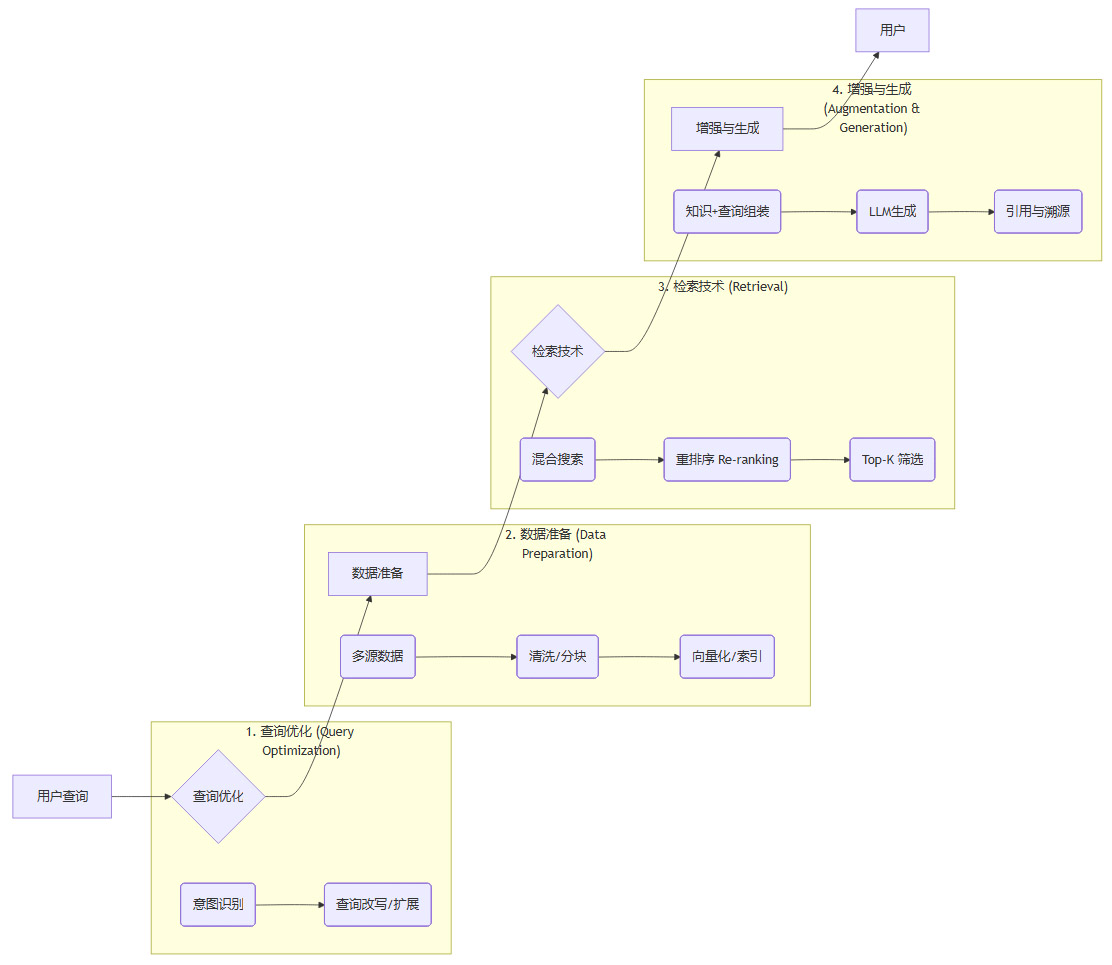
让我们拆解一下这几个关键步骤。
-
查询优化 (Query Optimization)
在基础的RAG方案里,用户的原始查询可以直接被向量化并用于检索。但这一步的优化,能极大提升后续环节的精准度。它通常利用模型(小模型或LLM本身)对用户输入进行意图识别、查询改写和关键词扩展。目的是让系统更准确地理解用户到底想问什么,为后续精准检索打下坚实基础。 -
数据准备 (Data Preparation)
这是RAG的基石。我们需要在数据平台整理来自多方的数据,进行清洗、分块(Chunking)、生成向量(Embedding),并构建索引。对于图片、音视频等多模态数据,可以借助知识图谱进行统一管理。这一系列工作,包括各种索引增强技术,都是在为知识的准备和索引强化投入精力。因为原始数据可能是海量的,我们必须做到精准获取,有所取舍。 -
检索技术 (Retrieval)
检索的好坏直接决定了提供给LLM的“原材料”质量。现代RAG系统通常采用混合搜索(Hybrid Search),它结合了基于关键词匹配的稀疏向量检索(如BM25)和基于语义匹配的稠密向量检索。前者保证了关键词的精确匹配,后者则能理解更深层次的语义关联。检索到初步结果后,还会进行重排序(Re-ranking),通过一个更精密的模型评估每个文档片段与查询的真实相关性,最后选取最相关的Top-K个结果。 -
增强与生成 (Augmentation & Generation)
最后一步,将检索到的知识片段(Context)与优化后的用户查询,按照预设的模板组装成一个新的、内容更丰富的提示词。这个新的提示词自动“携带”了最新的外部知识,被送往大模型。大模型基于这些“证据”来生成答案,同时可以附上引用来源,方便用户追溯。
需要说明的是,以上并非最简方案。在企业场景中,实用主义至上,一个更精简的版本同样可以跑通并创造价值。作为产品经理或技术负责人,优先评估需求价值和技术实现成本之间的平衡至关重要。更先进的技术往往意味着更高的落地成本。选择合适的技术满足当前需求,先产生业务价值,再逐步迭代更新,是更稳妥的做法。
2.2 RAG的演进与局限
RAG技术本身也在不断演进,从最基础的Naive RAG,到具备校验和反思能力的自省RAG(Self-Reflective RAG),再到利用知识图谱进行多跳推理的Graph RAG。这些方案的最终目的,都是在“检索-增强-生成”这个主干流程上,让每一步都做得更好。
但即便如此,随着应用的深入,RAG的固有局限性在复杂企业场景下愈发明显。
|
RAG的局限性 |
具体表现与影响 |
|---|---|
|
检索噪声与信息丢失 |
“语义相似”不等于“事实相关”。检索出的内容可能包含大量无关信息(噪声),或因分块不当导致关键信息丢失,反而误导LLM。 |
|
上下文窗口爆炸与失忆 |
在多轮对话中,简单地堆叠历史记录和新检索的知识,会迅速撑爆LLM的上下文窗口,导致模型“失忆”,无法理解长程依赖。 |
|
个性化与工具集成不足 |
基础RAG缺乏对用户角色、偏好等个性化信息的管理机制。同时,它与外部API、数据库等工具的集成较为松散,难以形成协同效应。 |
|
多模态数据处理受限 |
传统的RAG主要面向文本数据。对于图表、音视频等非结构化、多模态数据的理解和利用能力非常有限,无法形成完整的知识视图。 |
|
成本与效率问题 |
每次交互都进行检索和生成,并将大量上下文注入提示词,导致Token消耗巨大,推理延迟较高,在需要高并发、低延迟的场景下面临挑战。 |
这些问题,尤其在复杂的企业环境中,单纯依靠优化检索算法已经难以根治。它们共同指向了一个更深层次的需求,我们需要一个更系统化的方法来治理和运用上下文。这正是Context Engineering登场的契机。
三、🏗️ Context Engineering:知识注入的系统化升级

如果说RAG解决了“知识从哪儿来”的问题,那么Context Engineering则致力于解决“知识如何用”的核心问题。
从定义上讲,Context Engineering是一种通过工程化的方法,系统地设计、构建、管理和优化输入给大语言模型的上下文信息(Context),以精确引导模型生成高质量、高相关性、高准确率分析结果的工程方法论。
从这个角度看,RAG可以被视为Context Engineering理念下,专注于知识检索与注入的一个具体落地实践。但Context Engineering的边界要宽广得多。
3.1 从“被动拼接”到“主动治理”
Context Engineering的核心突破在于,它将上下文从一串“被动拼接的文本”,升级为一个“主动管理的、结构化的状态”。这个转变带来了质的飞跃,使得系统能够支持持续的交互、深度的个性化和多工具的协同。
其核心是一个策略与编排器(Strategy & Orchestrator),它像一个智能的交通指挥中心,调度着整个上下文的构建流程。
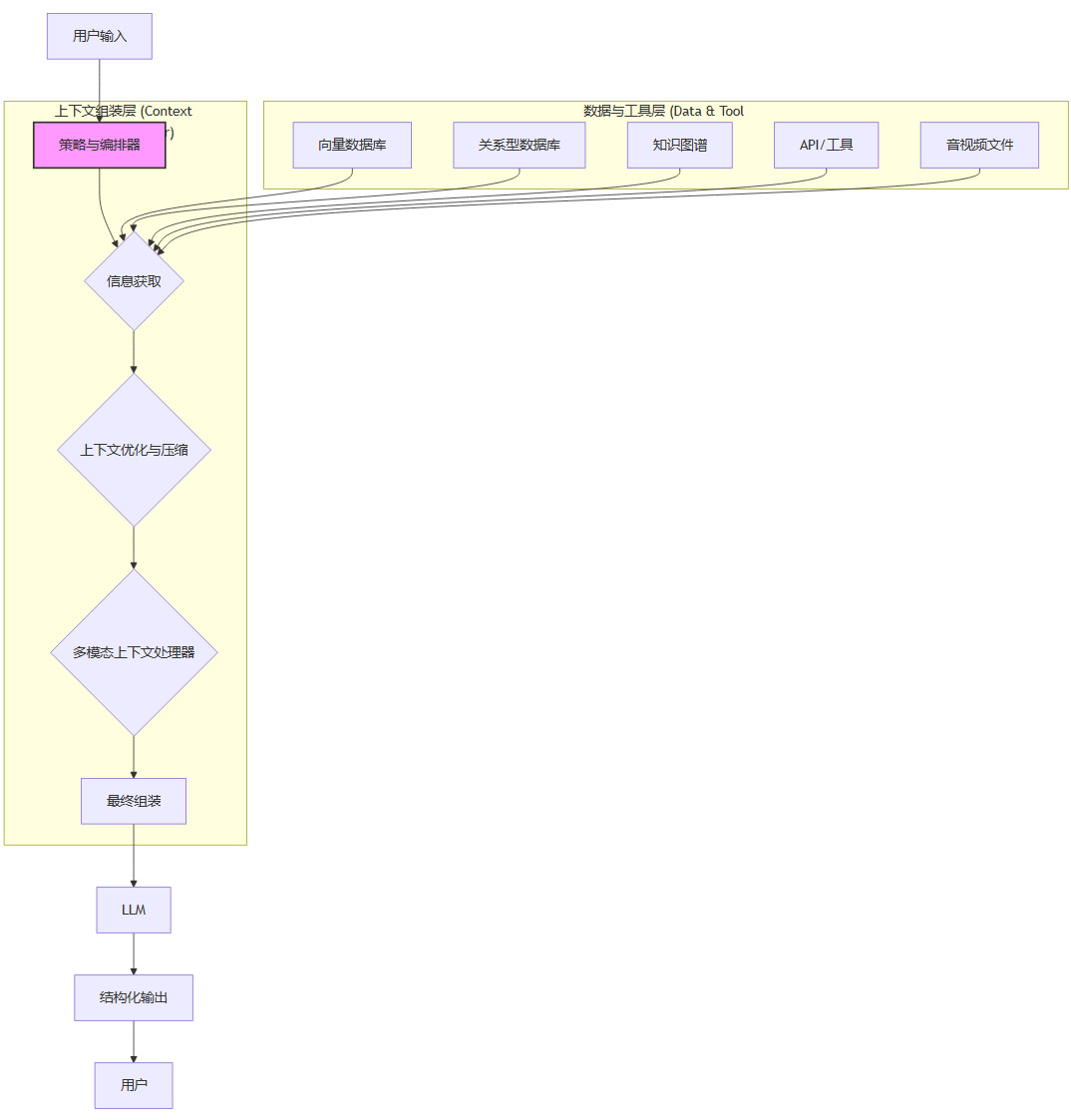
这个流程比RAG复杂,但它带来了前所未有的灵活性和控制力。
-
信息获取 (Information Acquisition)
编排器根据用户意图,决定从哪些数据源获取信息。这不再局限于向量数据库,而是扩展到关系型数据库、知识图谱、外部API调用、甚至音视频文件的元数据等。 -
上下文优化与压缩 (Context Optimization & Compression)
获取到的原始信息需要被“精炼”。通过自动摘要、智能去重、相关性重排序等技术,去除冗余和无效信息,只保留最关键的“证据”。这有效应对了RAG中“上下文窗口爆炸”和“检索噪声”的问题。 -
多模态上下文处理器 (Multimodal Context Processor)
对于非文本数据,如图片、图表、音频等,处理器会对其进行理解、描述或转录,将结果转化为文本形式,无缝融入到上下文中,打破了模态的壁垒。 -
最终组装 (Final Assembly)
最后,编排器将所有处理过的元素——优化后的上下文数据、用于引导模型思考的推理模式(如思维链CoT)、预设的指令模板、多模态知识内容——按照最优的结构和格式,组装成最终的提示词。并且可以根据业务要求,强制LLM进行结构化输出(如JSON格式),方便下游程序调用。
3.2 Context Engineering的核心机制深度解析
为了实现上述流程,Context Engineering引入了一系列关键机制,这些机制共同构成了其强大的上下文治理能力。
3.2.1 分层记忆(Layered Memory)
这是解决“多轮失忆”问题的关键。它摒弃了简单堆叠历史对话的粗暴方式,将记忆分为不同层次。
-
短期记忆:存储当前对话轮次的信息,保证对话的即时连贯性。
-
中期记忆:存储用户在一段时间内的偏好、角色、历史交互摘要等。这使得系统能够提供个性化的响应。
-
长期记忆:存储全局性的、可复用的知识和事实,通常固化在知识图谱或专门的数据库中。
通过分层管理,系统可以在不同场景下智能地调用不同层次的记忆,既保证了对话的连贯性,又避免了上下文冗余。
3.2.2 路由与编排(Routing & Orchestration)
这是Context Engineering的“大脑”。编排器会根据任务类型、时效性要求和复用性,动态地决定上下文的来源。
-
问题是关于最新股价? -> 调用实时行情API。
-
问题是关于公司组织架构? -> 查询知识图谱。
-
问题是开放性闲聊? -> 可能不需要外部知识,直接由LLM回答。
此外,编排器还负责将不同工具(API、数据库查询等)返回的异构结果,格式化为标准的上下文块,确保LLM能够一致地理解和使用它们。
3.2.3 知识图谱的融合(Knowledge Graph Integration)
在处理多模态和复杂关联数据时,**知识图谱(Knowledge Graph, KG)**扮演着至关重要的角色。三份主流模型的回答都一致强调了这一点。
LLM擅长语言理解和泛化,但缺乏结构化的事实知识和可解释的推理能力。而知识图谱正好相反,它是一个由实体和关系构成的结构化、可解释的事实网络。二者的结合,形成了完美的互补。
-
统一数据管理:多模态知识图谱可以打通文本、图像、视频、表格等异构内容之间的语义关联,将散落各处的数据孤岛连接起来,形成统一的知识视图。
-
可解释的推理:基于图谱的查询和推理路径是明确的,这为LLM的回答提供了可追溯、可解释的依据,极大地提升了企业级AI方案的可靠性。
-
提升检索质量:Graph RAG利用知识图谱的结构,可以进行多跳查询,发现传统向量检索难以触及的深层关联,显著提升问答的完整性和准确性。
浙江省的“数据底座+知识图谱+大模型”产业实践就是一个很好的例子。他们通过构建统一的知识图谱,整合了设备实时数据、业务系统数据和人工填报信息,打通了数据流与应用开发链路。这不仅解决了垂直领域的“知识盲区”,还极大提升了数据利用和分析效率,带来了显著的业务指标改善。
四、🛠️ 工程化可靠性的闭环与产品落地建议

从RAG到Context Engineering的演进,其最终目标是将AI的能力转化为稳定、实用的生产力。这需要坚实的工程实践和清晰的产品落地策略。
4.1 构建可靠性工程的闭环
理论再先进,最终也要落地为可靠的系统。可靠性工程提出了一套保障专业场景可靠性的方法论,可以总结为“程序化表达 + 场景知识图谱 + 受控工具链 + 闭环核验”。
-
程序化表达:将业务流程和规则(SOP)代码化,作为约束和引导LLM行为的框架。
-
场景知识图谱:为特定领域构建高精度的知识图谱,作为事实的“锚点”。
-
受控工具链:所有外部工具的调用和结果都经过严格的校验和格式化。
-
闭环核验:这是最关键的一环。系统输出的关键结论或执行性操作,必须经过可审计的核验。同时,建立用户反馈机制,将用户的校准信息回流,用于持续优化知识库和系统策略。
这种检查清单式的核验,将LLM不确定的概率性输出,转化为了一个可复用、可验证、可扩展的工程体系。
4.2 产品落地的分步建议
对于希望在企业中实践Context Engineering的产品经理和架构师,以下分层治理的思路或许能提供一个清晰的路线图。
|
治理层次 |
核心任务 |
关键技术/策略 |
|---|---|---|
|
数据层 |
保证知识源的质量。对原始数据进行清洗、结构化、分块,并建立高效的索引。 |
ETL流程、数据治理规范、智能分块算法(如基于语义)、向量化模型选择、混合索引(向量+关键词)。 |
|
检索层 |
提升信息召回的精准度。从海量数据中快速、准确地找到最相关的知识片段。 |
混合搜索(Hybrid Search)、重排序模型(Re-ranker)、查询扩展与重写。 |
|
组装层 |
优化注入LLM的上下文。对检索到的信息进行摘要、压缩、去重,并以结构化的方式呈现给LLM。 |
上下文摘要算法、去重算法、提示词模板工程(Prompt Engineering)、结构化输出约束。 |
|
记忆层 |
管理对话的连续性和个性化。实现短期、中期、长期记忆的分层管理和智能调用。 |
短期对话缓存、用户画像(Profile)管理、基于知识图谱的长期记忆存储、缓存淘汰策略。 |
在具体落地时,我们建议遵循以下原则。
-
先价值后技术
始终从核心业务诉求出发,优先解决最痛的问题。循序渐进,逐步迭代,时刻关注投入产出比(ROI),避免一开始就追求大而全的复杂架构。 -
优先建设数据底座
如果条件允许,优先投入资源建设统一的知识图谱(KG)和数据底座。这是打通数据孤岛、从根本上提升分析与推理质量的战略性投资。 -
建立核验与反馈闭环
对于任何输出关键结论或执行关键操作的AI应用,必须设计可审计的核验流程和用户反馈回流机制。这是系统能够持续进化、保持可靠的生命线。
结语
从RAG到Context Engineering的演进,并非简单的技术迭代,而是AI应用思想的一次深刻变革。它标志着我们对大模型应用的理解,从追求单点能力的惊艳,转向构建系统性、工程化的可靠性。
行业共识正在清晰地形成,单靠“检索+生成”的简单模式,已难以支撑复杂多变的企业级应用场景。我们必须以上下文的系统化治理、知识图谱的深度融合以及工程化的闭环核验为三大支点,构建一个从底层数据到顶层决策输出的完整、可控的智能系统。
在AI技术浪潮中,我们时常会感到“乱花渐欲迷人眼”。但回归本质,优秀的产品理论和扎实的工程思想从未过时。坚持“场景驱动、工程落地、可核验”的路径,才能让AI应用少走弯路,更快地在企业中开花结果。
📢💻 【省心锐评】
RAG是开胃菜,上下文工程才是主餐。别再无脑堆砌数据了,学会如何“烹饪”上下文,才能真正喂饱企业级智能,让AI从玩具变成工具。
更多推荐
 19
19 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)