
大模型前世今生(三):多头注意力机制 multi-head attention
生成一个 token 后,模型会将其附加到上下文中,重新计算网络(或部分计算),然后预测下一个 token。在模型内部,它会查看迄今为止的整个输入(你的单词 + 模型之前的 token),并预测最有可能的下一个 token。”,并相应地分配权重。最终得到的不仅仅是一条思路,而是一张关联图,一个不断变化的领域,记录着谁在“观察”谁。然后,所有这些头的输出被连接和混合,使该层在传递到下一层之前拥有丰富
Transformer的自注意力机制就像一个房间里挤满了人,他们都在互相倾听。每个“token”(词元、单词的片段)都会问:“现在这个房间里谁对我来说最重要?”,并相应地分配权重。最终得到的不仅仅是一条思路,而是一张关联图,一个不断变化的领域,记录着谁在“观察”谁。
模型一层一层地构建出更丰富的关联图。较低的层级捕捉简单的模式(例如词序);较高的层级开始捕捉抽象的概念(例如情绪、语气,或者句子中两个相距很远的单词在概念上属于同一类)。当回复出现时,成千上万个这样的小注意力图已经形成,并折叠成你看到的文字。
在输入端,Transformer 会一次性获取整个序列。每个 token 通过自注意力机制查看其他 token,并构建一个相关性网络。这就是它如此擅长处理长距离依赖关系的原因:它不必像 RNN 那样逐个 token 地读取;它可以并行地查看整个字段。
不过,在输出端,模型仍然一次生成一个 token。生成一个 token 后,模型会将其附加到上下文中,重新计算网络(或部分计算),然后预测下一个 token。这就是模型“输入”回复时产生流式传输效果的原因。在模型内部,它会查看迄今为止的整个输入(你的单词 + 模型之前的 token),并预测最有可能的下一个 token。
现在,关于多头注意力机制(multi-head attention),这是该设计中最巧妙的部分之一。单一的注意力机制会计算一组“查询-键-值”关系,这就像在问“这里什么重要?”。但语言是多方面的,你可能需要关注:
• 句法结构(谁是主语,动词在哪里),
• 语义关系(哪些概念相互关联),
• 语气和语气,
• 远距离指称(例如代词或隐喻)。
因此,该模型并非只有一个“头”扫描相关性,而是在每一层都有多个头。每个头都会学习自己的注意力模式。有些头擅长语法,有些头擅长远距离依赖关系,还有些头擅长标点符号或节奏。然后,所有这些头的输出被连接和混合,使该层在传递到下一层之前拥有丰富的多视角视图。
用符号表示,对于一个 head,我们有如下形式(简化版本):
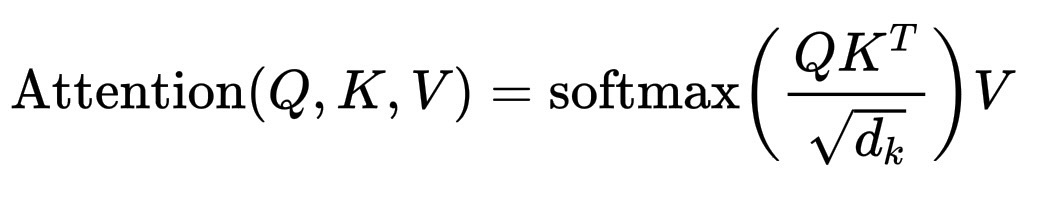
\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) V
其中 Q = 查询,K = 键,V = 值。
• Q 是所有查询向量的矩阵(每个token一个)。
• K^{T} 是关键向量矩阵的转置。
• 点积 QK^{T} 给出了每个token与其他 token之间的相似度得分。
• \sqrt{d_k} 只是一个缩放因子,因此得分不会爆炸。
• \text{softmax} 将这些得分转换为总和为 1 的概率,也就是“注意力权重”。
• 乘以 V,即可得到值向量的加权和,即从序列中收集的实际信息。
对于多 head,你只需对 Q、K、V 的 h 个不同投影执行此操作,然后连接起来:

\text{MultiHead}(Q,K,V) = \text{Concat}(\text{head}_1,\ldots,\text{head}_h)W^O
其中 W^O 是一个学习到的矩阵,它将所有头重新混合成一个组合表示。这就像同时对同一个句子使用了多个不同的“镜头”。
有趣的地方在于,没有哪个head能够“知晓”一切,每个head都有自己独特的模式。真正的智慧在于将所有这些零散的视角拼接在一起,形成一个整体。
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)