
大模型面试通关:微调效果评估实战指南(速存备用)
大模型面试通关:微调效果评估实战指南(速存备用)
一、面试真题:大模型微调效果该如何科学评估?
1.1 问题核心解析
“如何评估大模型微调效果” 是大模型算法、工程岗面试的 “必考题”,甚至在部分公司的终面中会结合实际业务场景追问细节。这是因为在工业落地中,“微调完成” 不等于 “可用”—— 有些模型在测试集上指标亮眼,但面对真实用户的复杂需求却频频 “拉胯”。因此,一套完整的评估体系,是区分 “只会调参” 和 “懂工程落地” 的关键,也是面试官重点考察的能力之一。
从实战角度来看,成熟的评估方案必然是 “人工主观体验 + 自动化客观指标” 双管齐下:人工负责判断模型是否贴合真实业务场景,自动化则解决效率、量化和标准化问题,二者缺一不可。
1.2 系统化答题思路
第一部分:人工评估 —— 聚焦 “业务适配性”
人工评估的核心目标,是验证模型输出是否符合真实用户的使用预期,尤其适合考察无法用单一指标衡量的 “软性能力”,比如回答的逻辑性、话术自然度、行业知识准确性等。
具体实施有两种主流方式:
- 定向专家评审:针对垂直领域场景,邀请具备专业背景的人员(如医疗场景找医生、法律场景找律师),按照预设的评分维度(如准确性、完整性、实用性)打分。例如在金融投顾场景中,专家会重点评估模型对政策的解读是否准确、给出的投资建议是否具备参考价值,而非单纯看 “语句通顺”。
- 大规模盲测对比:借助工具(如开源的 OpenWebUI、Hugging Face Chat UI)实现 “双盲测试”—— 让用户在不知道模型身份的情况下,同时体验待评估模型与基准模型(如微调前的原模型、行业标杆模型)的输出,通过 “二选一”(更喜欢 A/B/ 两者差不多)收集偏好数据。这种方式能有效避免 “先入为主” 的偏见,结果更贴近真实用户反馈。
目前行业内权威的模型榜单(如 LM Arena、Chatbot Arena),本质上就是通过海量用户的盲测数据,综合排出模型的综合表现,其说服力远高于单一团队的测试结果。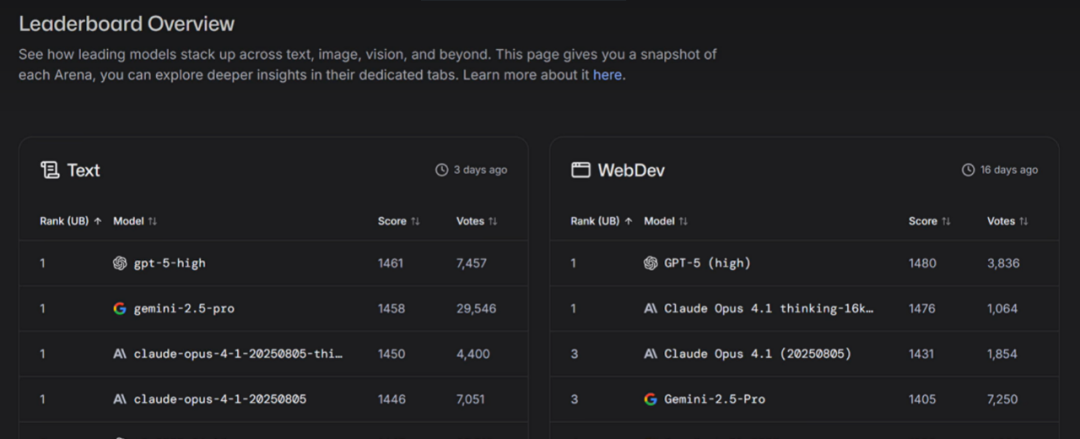
第二部分:自动化评估 —— 聚焦 “量化与效率”
自动化评估依赖高质量的验证 / 测试数据集,通过对比模型输出与标准答案(或参考标准),输出可量化的指标,核心解决 “效率” 和 “标准化” 问题。
实战中需注意两个关键点:
1. 数据集的 “针对性” :数据集必须覆盖模型未来要处理的 核心任务类型 ,避免 “为了评估而评估”。例如:
- 想测数学推理能力:用 AIME(高中数学竞赛题)、GSM8K(小学数学题)、MATH(竞赛级数学题)等数据集,评估模型解题正确率;
- 想测代码能力:用 SWE-Bench(真实软件工程任务,需修复代码 bug)、HumanEval(代码生成任务),通过自动执行代码判断 “是否能正确完成需求”;
- 想测指令跟随和工具调用(Function Calling):用 IFEval(指令理解评估)、ToolBench(工具使用任务集),验证模型是否能准确理解用户指令、正确调用工具并解析返回结果。
2. 指标的 “适配性” :不同任务对应不同的评估指标,不能一概而论。例如:
- 文本生成类任务(如文案创作):用 BLEU、ROUGE-L 衡量与参考文本的相似度,用 Perplexity(困惑度)衡量输出的流畅度;
- 分类 / 判断类任务(如情感分析、合规检测):用准确率(Accuracy)、精确率(Precision)、召回率(Recall)评估;
- 代码生成任务:用 Pass@k(多次生成中至少有一次正确的概率)衡量实用性。
第三部分:工程化工具加持 —— 体现 “实战经验”
在面试中提及具体的评估工具,能直接体现你的工程落地能力。目前行业内常用的工具框架有:
- OpenCompass(开放 compass):支持 100 + 数据集、200 + 模型的自动化评估,能一键生成多维度评估报告,还支持自定义数据集和评估指标,适合中小型团队快速搭建评估体系;
- EvalScope(魔搭社区出品):不仅能自动构建测试集,还能联动模型服务进行 “端到端” 评估,生成可视化分析报告,尤其适合需要对接业务系统的场景;
- LLM Eval Harness:Hugging Face 推出的通用评估框架,兼容性强,支持主流大模型和数据集,适合科研和工程场景通用。
通过 “人工评估 + 自动化评估 + 工具框架” 的组合,既能保证评估结果的全面性,又能体现工程化思维,这正是面试官希望看到的回答逻辑。
二、延伸热点问题(高频追问)
2.1 人工评估时,如何最大程度减少主观偏差?
核心思路是 “通过规则降低人为因素影响”,具体可从三方面入手:
- 多人评审 + 结果校准:避免单一评审员的偏好主导,建议 3-5 人组成评审组,对同一批样本分别打分后,取平均分或通过投票解决分歧;若评审结果差异较大,需重新统一评分标准。
- 严格执行盲测:隐藏模型的 “身份信息”(如模型名称、微调策略、是否为自研),只给评审员呈现 “问题 + 输出”,避免因 “觉得某类模型更好” 而影响判断。
- 制定清晰的评分细则:提前明确评分维度和标准,最好搭配正反示例。例如 “准确性” 维度可分为:5 分(完全符合事实,无错误)、3 分(核心信息正确,存在次要错误)、1 分(核心信息错误),并附上对应的案例,让评审员有章可循。
2.2 如何构建高质量的微调效果评估数据集(验证集 / 测试集)?
关键在于 “贴合业务、保证多样、避免污染”,具体原则如下:
- 场景全覆盖:数据集必须包含模型未来要处理的所有核心任务类型。例如,为客服大模型构建评估集时,需涵盖 “咨询产品功能”“投诉售后问题”“退换货流程解答” 等所有高频场景,不能只侧重某一类。
- 样本多样性:同一任务类型下,要包含不同难度、不同表述方式的样本。比如 “数学推理” 中,既要有基础计算题,也要有需要多步推理的应用题;“指令跟随” 中,既要有简洁指令(如 “写一封邮件”),也要有复杂指令(如 “写一封给客户的邮件,说明产品延期原因,语气要诚恳,同时附上补偿方案”)。
- 绝对避免数据污染:评估集不能与微调训练集有任何重叠(包括相似样本),否则会导致评估结果虚高,无法反映模型的真实泛化能力。建议通过数据指纹、相似度计算等方式,严格过滤重复样本。
2.3 有哪些工具可以快速搭建模型评估数据集?
除了前文提到的 EvalScope、OpenCompass 等综合框架,还有两类工具可针对性解决 “数据集构建” 问题:
- 自动化生成工具:利用大模型自动生成符合要求的评估样本。例如用 GPT-4、Claude 等模型,按照 “任务类型 + 格式要求 + 难度等级” 生成 prompt,批量产出问题和标准答案,再人工筛选校准,适合快速搭建初步数据集。
- 开源数据集聚合平台:直接基于成熟的公开数据集二次加工。例如通过 Hugging Face Datasets 库,一键加载 HumanEval、GSM8K 等经典数据集,再根据自身业务需求(如金融、医疗)补充领域内的专有数据,既能保证质量,又能节省时间。
三、总结
大模型微调效果评估,绝非 “跑几个指标就完事”,而是贯穿模型从研发到落地的 “关键校验环节”—— 它决定了模型能否真正满足业务需求,也体现了技术人员的 “全局思维”。
面试中回答这类问题,核心要抓住 “人工 + 自动化” 的双路径逻辑:先讲清二者的分工(人工管场景适配,自动化管量化效率),再结合具体的实施方法、工具和案例,最后通过延伸问题的解答体现细节思考。这样的回答不仅结构清晰,还能向面试官证明你具备 “理论 + 实战” 的双重能力,自然更容易加分。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
为什么要学习大模型?
我国在A大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着AI技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国AI产业的创新步伐。加强人才培养,优化教育体系,国际合作并进是破解困局、推动AI发展的关键。


👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!
更多推荐
 51
51 0
0- 0



 已为社区贡献81条内容
已为社区贡献81条内容

所有评论(0)