
大模型微调
大模型微调是在预训练模型基础上,通过特定任务数据调整参数使其适应下游任务,包括全参数微调和参数高效微调。监督式微调(SFT)利用标注数据,通过交叉熵损失反向传播更新参数,需注意数据质量、学习率策略和早停机制。参数高效微调方法主要有Adapter(插入小型全连接网络)、Prefix Tuning(添加可训练前缀向量)和LoRA(低秩矩阵分解)。全参数微调更新全部参数,适配能力强但计算成本高;部分微调
·
1. 大模型微调的核心概念
大模型微调指在预训练模型基础上,通过特定任务数据调整模型参数,使其适应下游任务。核心包括数据适配(领域/任务数据)、参数更新(全参数或部分参数)、优化目标(损失函数调整)。微调分为全参数微调(更新所有参数)和参数高效微调(仅更新少量参数)。
2. 监督式微调(SFT)工作原理
SFT利用标注数据,通过监督学习调整模型。输入-输出对(如问答、文本生成对)送入模型,计算预测结果与真实标签的交叉熵损失,反向传播更新参数。
关键点
- 数据质量:标注需准确且覆盖任务场景
- 学习率策略:常采用较低学习率避免破坏预训练知识
- 早停机制:防止过拟合
3. 参数高效微调方法
3.1 Adapt Tuning
Adapter在Transformer层中插入小型全连接网络,微调时仅训练Adapter层及顶层分类器。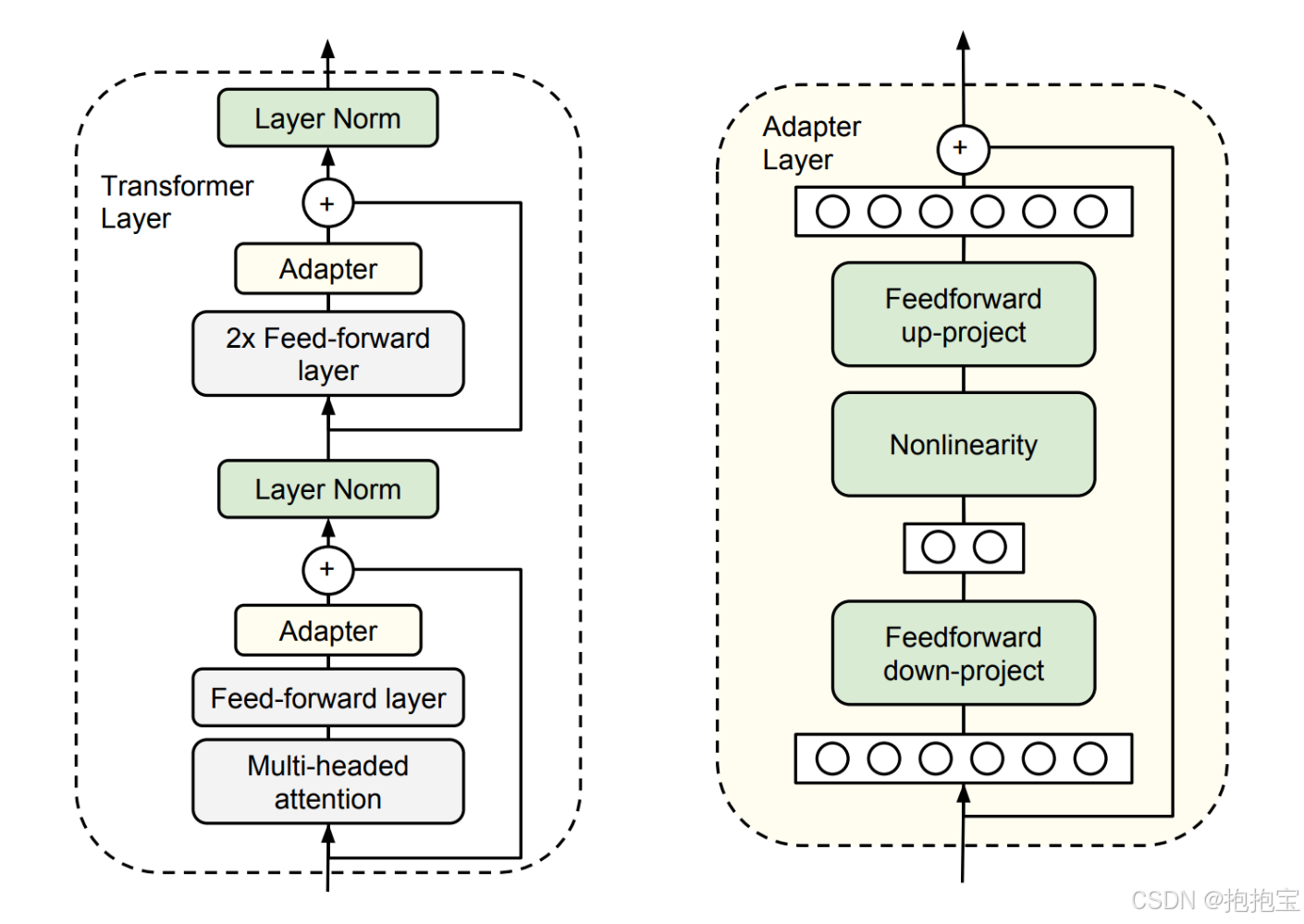
结构特性
- 位置:通常加在多头注意力层和前馈网络之后
- 参数量:占原始模型0.5%~5%
- 公式:
hout=hin+fadapter(hin),fadapter=Wdown⋅σ(Wup⋅hin)h_{out} = h_{in} + f_{adapter}(h_{in}), \quad f_{adapter} = W_{down} \cdot \sigma(W_{up} \cdot h_{in})hout=hin+fadapter(hin),fadapter=Wdown⋅σ(Wup⋅hin)
其中 Wdown∈Rd×rW_{down} \in \mathbb{R}^{d \times r}Wdown∈Rd×r, Wup∈Rr×dW_{up} \in \mathbb{R}^{r \times d}Wup∈Rr×d(r≪dr \ll dr≪d为瓶颈维度)
3.2 Prefix Tuning
Prefix Tuning通过在输入序列前添加可训练的任务特定前缀向量(prefix)来引导模型行为,冻结原始模型参数。
实现机制
- 前缀长度:通常10~20个token长度
- 插入位置:每层Transformer的key和value向量前拼接
- 参数计算:对于第lll层,key KKK和value VVV矩阵扩展为:
Kext=[PKl;K],Vext=[PVl;V]K_{ext} = [P_K^l; K], \quad V_{ext} = [P_V^l; V]Kext=[PKl;K],Vext=[PVl;V]
其中 PKl,PVl∈Rm×dP_K^l, P_V^l \in \mathbb{R}^{m \times d}PKl,PVl∈Rm×d(mmm为前缀长度)
优化技巧 - 重参数化:使用MLP生成前缀避免训练不稳定
P=MLPθ(Pembed),Pembed为随机初始化嵌入P = MLP_{\theta}(P_{embed}), \quad P_{embed}为随机初始化嵌入P=MLPθ(Pembed),Pembed为随机初始化嵌入
3.3 LoRA微调
LoRA(Low-Rank Adaptation)通过低秩矩阵分解近似参数增量,仅更新新增矩阵。
核心设计
- 目标参数:作用于Transformer的注意力权重矩阵(WqW_qWq, WvW_vWv为主)
- 参数注入:原始参数 W∈Rd×dW \in \mathbb{R}^{d \times d}W∈Rd×d 的增量表示为 ΔW=BA\Delta W = BAΔW=BA,其中 B∈Rd×rB \in \mathbb{R}^{d \times r}B∈Rd×r, A∈Rr×dA \in \mathbb{R}^{r \times d}A∈Rr×d
- 前向计算:
h=(W+ΔW)x=Wx+BAxh = (W + \Delta W)x = Wx + BAxh=(W+ΔW)x=Wx+BAx
优势 - 无推理延迟(可与原始权重合并),显存占用低
- 超参数选择:秩 rrr(通常8~64)、Alpha(缩放系数)
4. 全参数微调与部分微调对比
| 维度 | 全参数微调 | 部分微调(LoRA/Adapter) |
|---|---|---|
| 参数量 | 100%更新 | 0.1%~10%更新 |
| 计算成本 | 高(需存储所有梯度) | 低(仅计算新增部分梯度) |
| 适配能力 | 强(适合大数据场景) | 中等(依赖方法设计) |
| 过拟合风险 | 高 | 低 |
| 典型应用领域 | 大模型(如医疗、法律) | 多任务适配/资源受限场景 |
更多推荐
 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)