
深入理解 Qwen-Agent:从“看懂图片“到构建自主AI
摘要:阿里巴巴云通义千问团队开发的Qwen-Agent框架,将AI从"对话"升级到"执行"阶段。该开源项目支持多模态交互、工具调用和任务规划,开发者可构建能自主完成复杂任务的AI应用。通过看图分析案例展示,Qwen-Agent能理解图片内容并执行多步骤任务,如商品搜索比价等。不同于成品AI应用如豆包/Kimi,Qwen-Agent提供开发框架,支持深度定制和
AI的进化之路——从"对话"到"执行"
还记得第一次使用ChatGPT时的震撼吗?那种"AI竟然能这样对话"的惊喜。但如今,当我们习惯了与AI聊天、让它写诗、总结文档后,是否感到了某种局限?
传统AI的困境:无论多么智能的对话,本质上都是"一问一答"的被动响应。你问什么,它答什么,仅此而已。
Qwen-Agent开源项目:作为阿里巴巴云通义千问团队开发的智能体框架,Qwen-Agent在GitHub上已获得11.7k+ stars和1.1k+ forks ,成为开发者构建AI应用的热门选择。该项目支持Function Calling、MCP协议、代码解释器、RAG检索增强等多种功能。
Qwen-Agent的革命:想象一下,你给AI发一张蓝色连衣裙的照片,说"帮我分析这条裙子的款式特征,搜索同款商品并生成详细的比价报告"。传统AI只能告诉你"这是A字连衣裙,适合度假穿",但Qwen-Agent却能真正帮你完成整个分析流程——识别款式特征、提取关键信息、搜索同款商品、对比价格和评价、生成详细的购买建议报告,一气呵成!
这就是从"对话"到"执行"的革命性转变。
Qwen-Agent不是又一个聊天机器人,而是一个让开发者能够构建真正"能干活"的AI应用的开发框架。它基于阿里巴巴通义千问模型的指令遵循、工具使用、规划、记忆能力,让AI从"回答问题"升级为"解决问题",从"被动响应"进化为"主动执行"。
现在,这个强大的框架已经成为Qwen Chat的后端引擎,并且在2025年9月23日刚刚发布了支持Qwen3-VL的工具调用演示,支持抠图、图搜、文搜等多种工具。
本文将从一个具体的"看图思考"案例出发,深入探讨Qwen-Agent的真正价值,并阐明它与市面上常见的AI助手的本质区别。
一、不止于文本:当AI学会“看图思考”
Qwen-Agent项目提供了一个非常直观的示例(cookbook_think_with_images.ipynb),完美展示了其强大的多模态能力。这个案例的核心目标是演示AI如何接收图片和文字的混合输入,并基于这些信息进行复杂的推理和问答。
核心流程
1. 启用"视觉":在初始化Agent时,需要选择一个支持视觉语言(Visual Language, VL)的大模型,例如 qwen3-vl-max 或 qwen3-vl-235b-a22b-instruct。
2. 混合输入:向Agent发送一个包含图片和文字的复合指令。图片可以是一个URL链接,也可以是本地文件。
3. 推理与输出:Agent会“观察”图片内容,并结合你的文字问题进行思考,最终生成精准的回答。
代码概念示例
# 伪代码,展示核心逻辑
from qwen_agent.agents import Assistant
from qwen_agent.utils.output_beautify import typewriter_print, multimodal_typewriter_print
# `typewriter_print` prints streaming messages in a non-overlapping manner.
llm_cfg = {
# Use dashscope API
# 'model': 'qwen3-vl-plus',
# 'model_type': 'qwenvl_dashscope',
# 'api_key': '' # **fill your api key here**
# Use a model service compatible with the OpenAI API, such as vLLM or Ollama:
'model_type': 'qwenvl_oai',
'model': 'qwen3-vl-235b-a22b-instruct',
'model_server': 'http://localhost:8000/v1', # base_url, also known as api_base
'api_key': 'EMPTY',
'generate_cfg': {
"top_p": 0.8,
"top_k": 20,
"temperature": 0.7,
"repetition_penalty": 1.0,
"presence_penalty": 1.5
}
}
analysis_prompt = """Your role is that of a research assistant specializing in visual information. Answer questions about images by looking at them closely and then using research tools. Please follow this structured thinking process and show your work.
Start an iterative loop for each question:
- **First, look closely:** Begin with a detailed description of the image, paying attention to the user's question. List what you can tell just by looking, and what you'll need to look up.
- **Next, find information:** Use a tool to research the things you need to find out.
- **Then, review the findings:** Carefully analyze what the tool tells you and decide on your next action.
Continue this loop until your research is complete.
To finish, bring everything together in a clear, synthesized answer that fully responds to the user's question."""
tools = ['image_zoom_in_tool']
agent = Assistant(
llm=llm_cfg,
function_list=tools,
system_message=analysis_prompt,
# [!Optional] We provide `analysis_prompt` to enable VL conduct deep analysis. Otherwise use system_message='' to simply enable the tools.
)
messages = []
messages += [
{"role": "user", "content": [
{"image": "./resource/hopinn.jpg"},
{"text": "Where was the picture taken?"}
]}
]
response_plain_text = ''
for ret_messages in agent.run(messages):
# `ret_messages` will contain all subsequent messages, consisting of interleaved assistant messages and tool responses
response_plain_text = multimodal_typewriter_print(ret_messages, response_plain_text)
通过这个简单的例子,我们看到了一个超越传统文本交互的AI。它不再是一个只能处理文字的“盲人”,而是一个拥有“眼睛”的智能体,能够感知和理解更丰富的物理世界信息。
原文位置:https://github.com/QwenLM/Qwen-Agent/blob/main/examples/cookbook_think_with_images.ipynb
二、“AI应用”与“AI框架”:Qwen-Agent的真正价值
看到这里,你可能会问:现在很多AI应用(如豆包、Kimi)也能看懂图片,Qwen-Agent和它们有什么不同呢?
这是一个关键问题。它们之间最大的区别在于:
• 豆包、Kimi 是已经做好的“成品应用” (Applications)。
• Qwen-Agent 是一个用来创造新应用的“开发框架” (Framework)。
打个比方:豆包和Kimi就像一辆已经造好的、可以直接开的汽车,功能完善、开箱即用。而Qwen-Agent则像是汽车的发动机、底盘和各种核心零件,它让开发者可以自己动手去造一辆普通轿车、超级跑车、甚至是重型卡车。
下面的表格清晰地展示了它们的差异:
|
特性 |
豆包 / Kimi |
Qwen-Agent |
|---|---|---|
| 定位 | 面向最终用户的AI助手/聊天机器人 | 面向开发者的智能体开发框架 |
| 核心交互 | 对话和问答
你给它信息(文字、图片、文档),它给你回答。交互是“一问一答”式的。 |
任务执行和自主规划
你给它一个目标,它会自己规划步骤、调用工具去完成,过程可能包含多步推理和执行。 |
| 定制化能力 | 低
你无法改变它的内部工作流程,也无法让它调用你公司的内部数据库或API。 |
极高
开发者可以: |
| 目标用户 | 普通大众、学生、白领等
任何需要AI辅助完成信息处理和创意工作的人。 |
程序员、AI工程师、技术爱好者
需要构建自己AI应用的人。 |
场景对比:从“问答”到“执行”
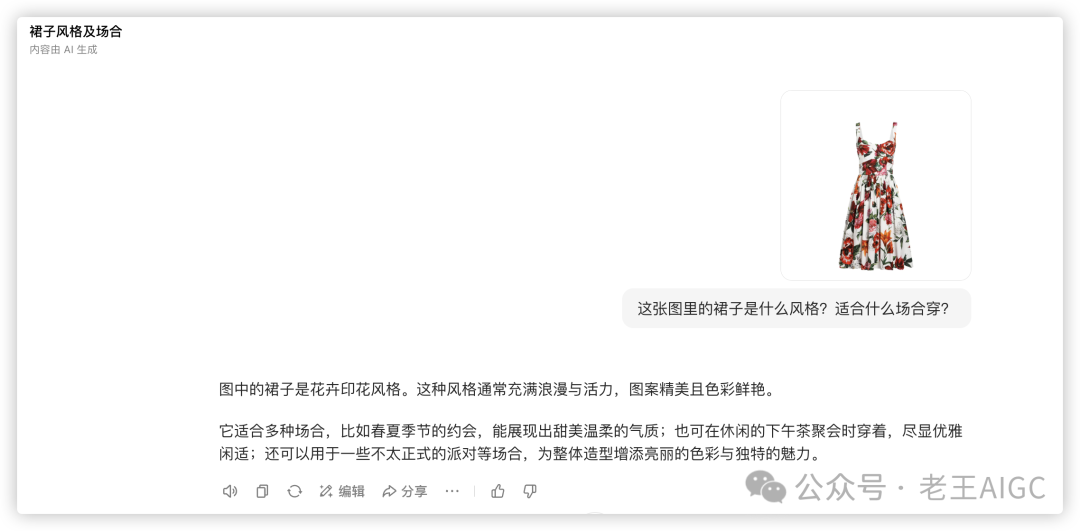
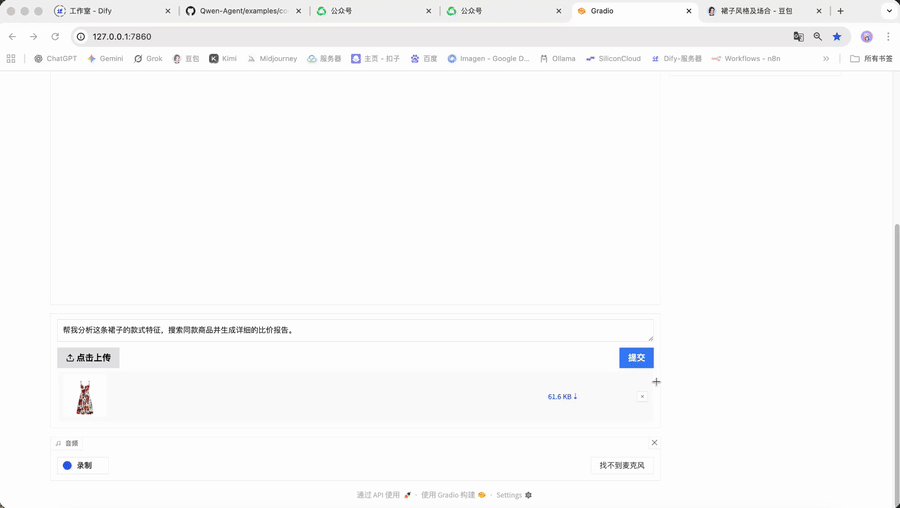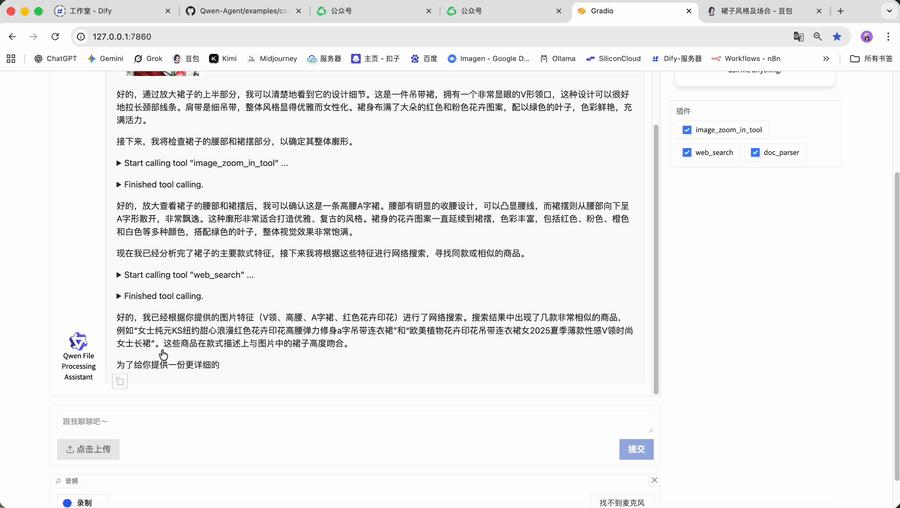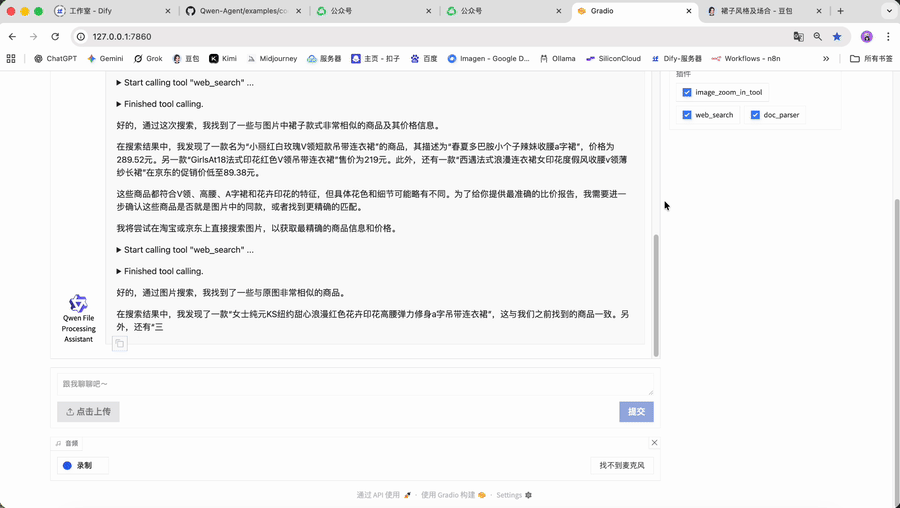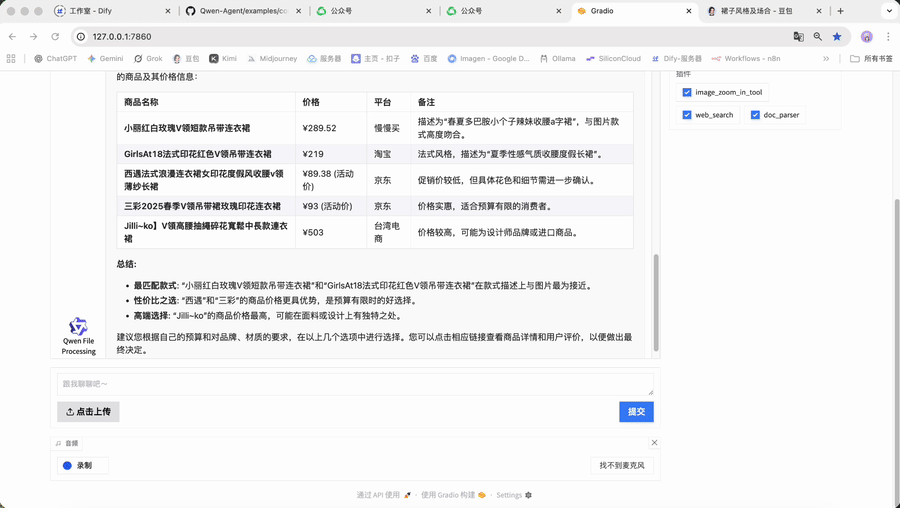
为了更具体地理解这种差异,我们以一张“连衣裙”的图片为例:
• 在豆包/Kimi中的场景(问答):
• 你问:“这张图里的裙子是什么风格?适合什么场合穿?”
• AI答:“图中的裙子是花卉印花风格。这种风格通常充满浪漫与活力,图案精美且色彩鲜艳。它适合多种场合,比如春夏季节的约会,能展现出甜美温柔的气质;也可在休闲的下午茶聚会时穿着,尽显优雅闲适;还可以用于一些不太正式的派对等场合,为整体造型增添亮丽的色彩与独特的魅力。”
• 在Qwen-Agent构建的应用中的场景(执行):
• 你下达指令:"帮我分析这条裙子的款式特征,搜索同款商品并生成详细的比价报告。"
• AI开始行动:
1. 规划:它会自主规划出"识别特征 -> 搜索商品 -> 比较价格 -> 生成报告"的完整流程。
2. 调用工具:它会依次调用内部集成的"图片识别工具"、"网络搜索工具"、"数据分析工具"等。
3. 执行反馈:最终向你报告:"任务完成,已生成包含4个同款商品的详细比价分析报告,包括价格对比、用户评价和购买建议。"
结论
虽然底层的多模态模型能力是相通的,但Qwen-Agent的出现,标志着我们与AI的交互方式正在从简单的“对话”转向更高级的“授权与执行”。
它不是又一个聊天机器人,而是一个强大的赋能工具。它将顶尖的AI能力(如视觉理解、逻辑规划、工具使用)交到开发者手中,让他们可以构建出能够自主完成复杂任务、深度融入业务流程的下一代AI应用。
常见问题FAQ
Q1: Qwen-Agent支持哪些编程语言?
A: Qwen-Agent主要基于Python开发,提供完整的Python SDK。同时支持通过OpenAI兼容的API接口与其他编程语言集成,如JavaScript、Java、Go等。
Q2: 使用Qwen-Agent需要什么技术基础?
A: 建议具备基础的Python编程能力和API调用经验。如果要开发复杂应用,最好了解Web开发、数据库操作等相关技术。
Q3: Qwen-Agent能处理哪些类型的文件?
A: 支持多种格式:图片(JPG、PNG、WebP等)、文档(PDF、Word、Excel)、代码文件、音频和视频文件等。具体支持范围会随版本更新不断扩展。
Q4: 如何确保数据安全和隐私?
A: Qwen-Agent支持本地部署,敏感数据可完全在本地处理。同时支持企业级的权限管理和数据加密,确保业务数据安全。
Q5: 相比其他AI框架,Qwen-Agent的优势是什么?
A: 主要优势包括:1)原生支持多模态处理;2)强大的工具调用能力;3)完善的中文支持;4)活跃的开源社区;5)阿里云生态的技术支持。
推荐阅读
• Qwen3-VL震撼登场!工业智能质检系统Dify实战案例让你3分钟上手最强视觉AI
• 10分钟搭建智能图表生成器!Dify+ECharts让数据可视化全自动
• 打破AI工具壁垒!Dify工作流秒变MCP神器,一键集成Cursor/Claude/Cherry studio
总结与展望
从ChatGPT掀起的对话革命,到如今Qwen-Agent引领的执行革命,我们正在见证AI从"回答问题"向"解决问题"的历史性跨越。
Qwen-Agent的核心价值不在于又提供了一个聊天机器人,而在于它为开发者打开了一扇通往"AI原生应用"的大门。通过其强大的多模态理解、工具调用和任务规划能力,我们可以构建出真正能够自主工作、深度融入业务流程的智能应用。
下一步行动建议:
1. 立即体验:访问Qwen-Agent GitHub仓库,跟随官方文档完成第一个Demo
2. 深入学习:结合自己的业务场景,思考哪些重复性工作可以用AI来自动化
3. 社区参与:加入Qwen开发者社区,与11.7k+开发者一起探索AI应用的无限可能
思考题:在你的工作或生活中,有哪些"需要多步骤完成的任务"最希望AI来帮你自动执行?欢迎在评论区分享你的想法!
对于任何希望在AI时代创造价值的开发者来说,Qwen-Agent无疑是一个值得深入探索的宝库。
想了解更多AI工具和技术趋势?关注我,每周为你带来最新的AI资讯和实用教程!
更多推荐

 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)