
大型语言模型(LLM)的版本化、对齐机制与核心概念解析
大模型三大版本与对齐技术解析 报告系统分析了LLM的三大核心版本:基座模型(Base)专注知识存储,指令模型(Instruct)强调任务执行,对话模型(Chat)优化交互体验。版本升级依赖对齐技术,包括监督微调(SFT)、人类反馈强化学习(RLHF)和直接偏好优化(DPO)。研究发现,RAG任务中基座模型可能因"对齐税"反而表现更优。部署时需严格遵循Prompt模板规范,确保模

1. 报告背景与概述
1.1 大模型 (LLM) 的核心界定与版本化驱动力
大型语言模型(LLM)是现代人工智能的基石,基于Transformer架构,核心目标是通过估计词元(token)序列出现的概率,预测和生成可信赖的自然语言。模型的“大”具有相对性与动态性,可指代模型参数数量(范围从110M到340B)或训练数据集规模。
LLM的生命周期包含三个核心阶段:预训练、指令微调和偏好对齐。基座模型(Base Model)是预训练阶段的产物,行为目标为纯粹的“下一词元预测”。但这种原始模式缺乏对人类意图的理解,难以直接应用于实际场景。
版本化的核心驱动力在于:通过后续“后训练”或“对齐”过程,将模型从单纯的文本概率生成器,转化为能高效、可靠遵循人类指令(Instruct)或进行流畅对话(Chat)的实用工具。
1.2 报告目标与结构
本报告旨在实现三大目标:
- 系统性界定LLM的基座(Base)、指令微调(Instruct)和对话(Chat)三种核心版本;
- 深入解析支撑版本转换的关键技术,重点聚焦模型对齐机制;
- 探讨实际部署中不同版本的性能权衡,以及与运行时推理相关的核心概念。
2. LLM的三大核心版本:Base, Instruct与Chat的结构与功能对比
LLM的不同版本,对应模型训练过程中不同的成熟度与目标定位,三者在核心特性上存在显著差异。
2.1 基座模型 (Base Model):知识的原始载体
基座模型通过在海量文本数据上进行无监督学习,以“下一词元预测”为任务训练而成,处于模型的原始状态。在该阶段,模型会吸收语言结构、世界知识与广泛常识。
- 核心优势:知识覆盖广度大,原始数据准确性高,本质是强大的知识库与特征提取器。
- 局限性:缺乏行为方向性,无法按用户期望的格式或风格响应指令。例如,用户输入问题时,模型可能补全问题上下文而非直接给出答案。
- 典型应用场景:科学研究的起点,或作为Retrieval-Augmented Generation(RAG)系统的基础组件,用于知识编码与提取。
2.2 指令微调模型 (Instruct Model):任务执行的专业化
指令微调模型是基座模型经过监督式微调(SFT)或更高级对齐技术处理后的版本,设计目标是高效、可靠地执行用户给定的特定指令。
- 核心优势:任务可靠性高,输出格式可控性强。通过微调,模型能理解并遵循特定输入模式(如将输入转化为JSON格式、生成特定风格文本)。
- 典型应用场景:高定制化需求场景,如自动化工作流程、结构化信息提取、代码生成。
2.3 对话模型 (Chat Model):人机交互的优化
对话模型是指令微调模型的进一步演化,专门针对多轮对话场景优化与偏好对齐,核心目标是模拟人类对话交互,保持上下文连贯性,确保交流自然、流畅且符合安全规范。
- 关键设计元素:严格依赖角色机制与Prompt模板。需识别系统(system)、用户(user)和助手(assistant)三种角色消息,并通过特定Token(如Llama 3中的<|start_header_id|>和<|eot_id|>)封装消息与角色,固化对话结构。
- 与Instruct模型的本质区别:训练重点与对齐侧重不同。Instruct模型侧重任务完成度,Chat模型侧重对话流畅性与安全性;推理阶段,差异通过模型对特定Prompt模板和特殊控制Token的内化响应体现(二者功能边界非绝对,Instruct可通过指令引导对话,Chat也可完成任务)。
表 1:大模型三大核心版本对比
| 特性 | 基座模型 (Base) | 指令微调模型 (Instruct) | 对话模型 (Chat) |
|---|---|---|---|
| 训练目标 | 下一词元预测 (Next Token Prediction) | 遵循特定指令 (Instruction Following) | 模拟多轮人类对话 (Conversational Flow) |
| 主要训练步骤 | 预训练 (Pre-training) | SFT (+可选RLHF/DPO) | SFT + RLHF/DPO + 对话历史处理 |
| 核心优势 | 知识广度,RAG任务中潜在高准确率 | 任务可靠性高,格式可控性强 | 交互自然、用户体验流畅,安全性高 |
3. 版本升级的核心驱动力:模型对齐技术
对齐(Alignment)是使LLM行为与人类意图、价值观和偏好保持一致的关键工程,是基座模型向可用Instruct/Chat模型转化的核心步骤,主要包含三种技术路径。
3.1 监督式微调 (Supervised Fine-Tuning, SFT)
SFT是模型对齐的基础起点,利用高质量人工编写或筛选的“指令-响应对”数据集,对预训练模型进行有监督学习。其核心目的是教授模型“如何回应”人类指令,为模型提供基础的“指令遵循语法”与行为模式,是RLHF、DPO等复杂对齐方法的前置步骤。
3.2 基于人类反馈的强化学习 (RLHF) 深度分析
RLHF是实现高级模型对齐的主流技术,但计算密集型特点显著,核心目标是通过强化学习机制,最大化模型输出与人类偏好的匹配度。
- 核心流程:
- 数据收集:获取模型对指令的输出,以及人类对这些输出的偏好排序;
- 奖励模型(Reward Model, RM)训练:基于人类偏好数据,训练独立RM,对模型响应进行评分;
- 策略模型微调:使用近端策略优化(PPO)等强化学习算法,以RM评分为奖励信号,微调LLM策略模型。
- 优势:深度定制化潜力强,适用于理解复杂或微妙人类反馈的场景。
- 劣势:流程设置复杂,计算资源需求极高(尤其训练与维护RM的成本)。
3.3 直接偏好优化 (Direct Preference Optimization, DPO)
DPO是近年为解决RLHF复杂性与资源消耗问题发展的对齐技术,核心创新在于绕过奖励模型训练步骤。
- 核心机制:将人类偏好数据(如“响应A优于响应B”)直接编码为策略损失函数,策略模型可直接优化该函数,将人类偏好融入模型参数。
- 优势:流程简洁,计算效率高,结果更稳定;可作为SFT后的第二阶段优化手段,增强模型帮助性、减少有害输出,代表行业在“高效、可扩展性与算法稳定性”上的进步。
- 劣势:依赖二元偏好选择,处理需极度细致或多层次反馈的任务时,灵活性不如RLHF。
表 2:LLM模型对齐技术对比
| 对齐技术 | 监督式微调 (SFT) | 人类反馈强化学习 (RLHF) | 直接偏好优化 (DPO) |
|---|---|---|---|
| 基本原理 | 有监督学习(模仿行为) | 基于奖励模型的强化学习 | 直接优化偏好数据 |
| 核心组件 | 指令数据集 | RM、策略模型、PPO算法 | 偏好数据集、策略模型 |
| 资源需求 | 低(相对而言) | 极高 (需训练RM) | 中等 (流程更简洁) |
| 优势 | 快速实现基础指令能力 | 可定制化程度深,适应微妙反馈 | 简化流程,计算效率高,结果更稳定 |
4. 实际应用中的版本性能悖论与选型策略
在LLM实际部署中,尤其知识密集型任务场景,不同版本的性能表现存在“悖论”,需结合需求制定选型策略。
4.1 RAG 系统中的性能悖论与“对齐税”
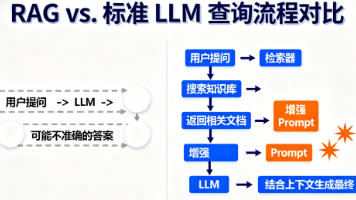
检索增强生成(RAG)系统的工作原理:先检索相关文档,再将用户查询与检索文档一同输入LLM,基于外部信息生成响应,以提升可靠性、减少幻觉。
- 性能悖论:研究发现,基座模型在部分实验设置的RAG任务中,平均准确率高于其指令微调后的版本,挑战了“指令模型在所有场景下优于基座模型”的传统认知。
- 核心原因:对齐税 (Alignment Tax):对齐后的Instruct/Chat模型被训练为高度服从指令,尤其“拒绝回答”指令(若答案未包含在检索文档中,需回答“NO-RES”),增强了可信度与上下文忠实度;而基座模型更倾向于调用预训练阶段习得的“参数化记忆 (Parametric Memory)”,即使答案不在检索上下文中,仍可能凭内部知识给出正确答案,从而获得更高原始准确率。
- 选型建议:需根据应用需求选择——追求“安全、上下文忠实的输出”选Instruct/Chat模型;追求“全面、可能包含内部知识的答案”选Base模型。
4.2 Prompt 模板的约束力与规范化
Prompt模板是对齐成果在推理阶段落地的关键接口,Instruct和Chat模型在训练中已内化对特定结构(如角色定义、特殊Token)的响应模式。
- 典型案例:Llama 3 Instruct版使用<|begin_of_text|>、<|end_of_text|>等开始/结束Token,以及<|start_header_id|>{role}<|end_header_id|>等角色封装Token,界定用户与助手消息,这些特殊Token是模型行为的“控制信号”。
- 关键注意事项:若使用非官方或错误模板,模型可能无法正确识别任务结构,导致对齐失效、性能下降。因此,部署Instruct或Chat模型时,需严格遵守模型卡规定的Prompt格式与特殊Token使用规范,确保行为可预测、可靠。
5. 关联核心概念 I:运行时学习与推理增强
除通过微调实现永久性对齐外,LLM在运行时(推理阶段)可通过Prompting技术动态提升任务表现,核心包含两种关键技术。
5.1 上下文学习 (In-Context Learning, ICL) 与 Few-Shot Prompting
上下文学习(ICL)是LLM的基础能力,允许模型通过分析Prompt中的示例与上下文,动态适应新任务的结构、风格或偏好,无需修改内部参数或权重。
ICL的具体实现方法分为三类:
- Zero-Shot Prompting:不提供任何示例,模型完全依赖预训练知识泛化,适用于简单任务。
- One-Shot Prompting:提供1个示例,用于澄清任务期望与格式,适用于中等复杂度任务。
- Few-Shot Prompting:提供2个及以上示例,帮助模型识别复杂输入-输出模式,是ICL的核心应用形式,依托模型强大的模式识别能力与注意力机制,实现“临时学习”。
5.2 思维链提示 (Chain-of-Thought, CoT) 与逻辑推理
CoT是革命性的Prompting技术,通过引导模型输出中间逻辑推理步骤,显著增强其逻辑推理能力,核心机制是将复杂任务(如数学问题、多步常识推理)分解为可管理的子步骤。
- 典型案例:解决多步骤算术问题时,CoT提示引导模型明确列出每一步加减过程,最终得出答案。
- 核心优势:
- 提升准确率:尤其在多步分析、复杂推理任务中效果显著;
- 增强透明度:输出推理过程,使模型决策路径可验证。
- 关键特性:CoT推理是模型参数量达到临界点后展现的“涌现能力 (Emergent Ability)”;其高级变体(如自动思维链 Auto-CoT)可自动生成推理步骤,进一步提升可扩展性与实用性。
表 3:主要提示工程技术对比
| 技术 | 描述 | 原理 | 典型应用场景 |
|---|---|---|---|
| Zero-Shot | 不提供任何示例 | 依赖模型的预训练知识和泛化能力 | 简单的分类、总结任务 |
| Few-Shot (ICL) | 提供多个输入/输出示例 | 利用上下文学习,识别结构和风格模式 | 复杂格式要求、风格迁移 |
| Chain-of-Thought (CoT) | 引导模型输出推理过程 | 激活模型的逻辑推理“涌现能力” | 数学问题、逻辑推理、复杂常识问答 |
6. 关联核心概念 II:模型能力、安全与未来趋势
Instruct和Chat版本的演进,不仅是技术优化,更是工程化、伦理化与合规性的综合体现,需关注能力特性、安全挑战与未来方向。
6.1 涌现能力 (Emergent Abilities) 与规模法则 (Scaling Laws)
- 涌现能力:指系统规模增加到临界点后,整体表现出“超越组成部分简单叠加”的复杂行为。对LLM而言,CoT推理等复杂技能的出现即属此类现象,证明参数规模对模型功能的非线性飞跃。
- 规模法则:为LLM预训练提供关键指导,可预测性能增益与计算资源、数据集、参数量的关系,辅助超参数选择与优化配置。但需注意:若训练涉及敏感用户数据,需引入差分隐私(DP)等保护机制,此时传统规模法则动态会改变,需重新建立法则以评估“计算资源、隐私保护强度、模型实用性”的权衡关系。
6.2 大模型的安全性与对齐挑战 (Safety Alignment)
安全性是对齐过程的最高优先级,尤其面向终端用户的Chat版本,核心目标是避免模型生成有害或不当内容(涵盖暴力言论、非法行为、未成年人危害、精神健康支持等伦理与法律领域)。
- 现存挑战:
- 安全机制非绝对可靠:即使采用RLHF/DPO等先进对齐技术,模型仍可能被“越狱”攻击(通过巧妙设计的提示欺骗模型输出有害内容);
- 内在弱点:大模型嵌入空间的线性可分性,可能成为安全机制的漏洞,增加对抗性攻击防御难度。
- 外部驱动:全球法规环境(如美国《人工智能安全披露法案》、欧盟AI法案)推动更高的安全合规性与透明度要求,使安全对齐成为“技术+法律+运营”的综合挑战。
- 核心结论:安全对齐是持续的对抗性过程,需在技术开发与模型部署中不断严格审计。
7. 结论与展望
核心结论
LLM的版本化是其从理论模型走向实用工具的关键路径:
- 基座模型(Base)是海量知识的原始载体;
- 指令微调模型(Instruct)专注于任务执行的效率与可靠性;
- 对话模型(Chat)通过严格对齐,确保人机交互的流畅性与安全性;
- 对齐技术实现了模型行为模式的重塑,但在RAG等场景中引发“性能悖论”——追求高安全性与上下文忠实度时,可能牺牲部分原始知识准确率。
未来展望
LLM的版本迭代将聚焦三大方向:
- 精细化控制机制:针对RAG等场景的性能悖论,提供更细粒度控制接口,允许用户/应用系统精确指示模型“何时依赖内部参数化知识、何时严格遵循外部上下文”。
- 对齐技术的自动化与简化:DPO等高效技术的普及,将推动对齐流程自动化、简化,降低高质量模型对齐门槛,加速模型在不同领域与语言环境的迭代。
- Prompting技术的工程化:Prompt模板与特殊控制Token将成为LLM版本化的“正式且不可或缺的组成部分”,确保这些接口的规范性、稳定性与健壮性,是未来LLM大规模、可靠部署的关键工程挑战。
更多推荐


 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)