
揭秘大模型“开卷考试”的秘密武器:一文彻底搞懂 RAG
摘要:RAG——大语言模型的“开卷考试”外挂 RAG(检索增强生成)技术通过结合实时检索与生成能力,解决了大语言模型(LLM)的三大痛点:知识过时、事实性幻觉和私有数据隔离。其核心原理分为两步: 离线构建知识库:将文档切分、向量化后存入向量数据库; 在线检索生成:用户提问时,先检索相关文档片段,再让LLM基于这些上下文生成答案。 本文通过形象比喻(闭卷vs开卷考试)解释RAG优势,并给出5分钟搭建
揭秘大模型“开卷考试”的秘密武器:一文彻底搞懂 RAG
你是否也遇到过这样的场景:
你满怀期待地问 GPT-4 关于去年某个超火的新框架,它却一脸茫然地告诉你:“我的知识截止于 2023 年初哦” 🤔;或者,你让它帮忙总结一份公司的内部技术文档,它却开始旁征博引、引经据典,最后输出一篇看似专业、实则“一本正经地胡说八道”的报告。
是不是感觉又好气又好笑?😂
别担心,这不是 AI 要叛变了,而是它遇到了所有大语言模型(LLM)共同的“天花板”。LLM 就像一个天赋异禀、博览群书但有点“不食人间烟火”的天才,它的知识停留在过去,且对你的私有世界(比如公司内网、个人笔记)一无所知。
而我们今天要聊的主角——RAG(Retrieval-Augmented Generation,检索增强生成),就是解决这个问题的终极“外挂”!它就像是给了这个天才一本可以随时查阅的、内容实时更新的“超级参考书”。
读完本文,你将彻底明白:
- 为什么我们需要 RAG?(它解决了 LLM 哪些核心痛点)
- RAG 的工作原理是什么?(从“准备参考书”到“开卷考试”的全过程)
- 如何用几行代码快速实现一个简单的 RAG 应用?
- RAG 的未来和挑战是什么?
一、为什么 LLM 需要一个“外挂”?—— RAG 的诞生背景
在 RAG 横空出世之前,我们主要面临 LLM 的三大“天坑”:
痛点 1:知识截止期 (Knowledge Cut-off)
训练一个像 GPT-4 这样的万亿参数模型,成本是天文数字。因此,它们的知识库无法做到每天更新。这就导致了,你问它任何新近发生的事,它都只能摊摊手,表示无能为力。

痛点 2:幻觉 (Hallucination)
这可能是 LLM 最让人头疼的问题。当它遇到自己知识范围外的问题时,为了“不让你失望”,它倾向于“创造”一个看似合理的答案,而不是谦虚地承认“我不知道”。对于严肃的应用场景,比如医疗咨询或法律问答,这种幻觉是致命的。
痛点 3:私有数据隔离 (Private Data Gap)
我们都希望 AI 能成为我们的专属助理,能理解我们公司的项目文档、阅读我们的个人知识库。但出于安全和隐私考虑,我们不可能把这些数据都上传给 OpenAI 进行模型训练。这就形成了一道天然的鸿沟。
你可能会说,可以用 Fine-tuning(微调) 啊!没错,微调可以让模型学习特定领域的“说话风格”,但它更像是在“授人以渔”,而不是“授人以鱼”。它无法将新知识精确地“植入”模型,而且成本高、周期长,一旦知识有变,就得重新微调。
因此,社区迫切需要一种更轻量、更灵活、更经济的方式,来为 LLM “注入”实时、准确、私有的新知识。于是,RAG 闪亮登场!✨
二、RAG 是什么?给大模型一场“开卷考试”
理解 RAG 最好的方式,就是那个我们开头提到的比喻:开卷考试。
- 没有 RAG 的情况(闭卷考试):你直接问 LLM,它只能靠自己脑子里已经记住的(也就是模型参数里固化的)知识来回答。考得好不好,全看它背得牢不牢。
- 有了 RAG 的情况(开卷考试):在回答你的问题前,系统会先进行一个预备动作——检索 (Retrieval)。它会拿着你的问题,去一个你指定的、最新的、可信的知识库(比如公司的技术文档、最新的产品手册等)里,以最快的速度找到和问题最相关的几页内容。然后,它把这些内容连同你的原始问题,一起打包交给 LLM,对它说:“嘿,参考这些材料来回答。” 这就是 增强 (Augmented)。最后,LLM 参考着这些“小抄”,胸有成竹地 生成 (Generation) 一个高质量的答案。
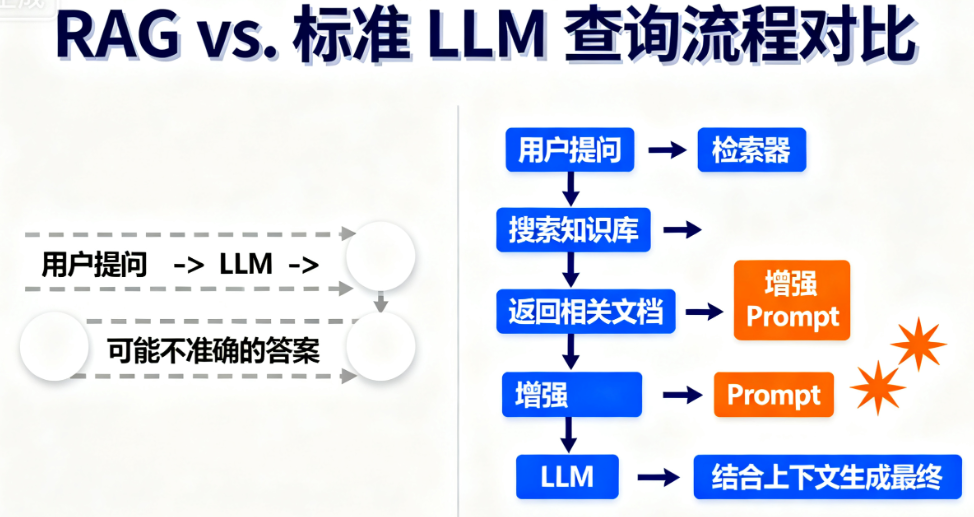
所以,RAG 的全名 Retrieval-Augmented Generation,每个词都充满了智慧:
- 检索 ( R ):快准狠地从海量信息中找到我需要的。
- 增强 ( A ):把找到的“证据”和原始问题结合,给 LLM 最充分的上下文。
- 生成 ( G ):基于可靠的“证据”进行回答,而不是凭空想象。
三、RAG 工作原理解析:两步走,让你的 LLM 变身“学霸”
RAG 的整个工作流程可以清晰地分为两个阶段:离线的“知识库构建”和在线的“检索生成”。
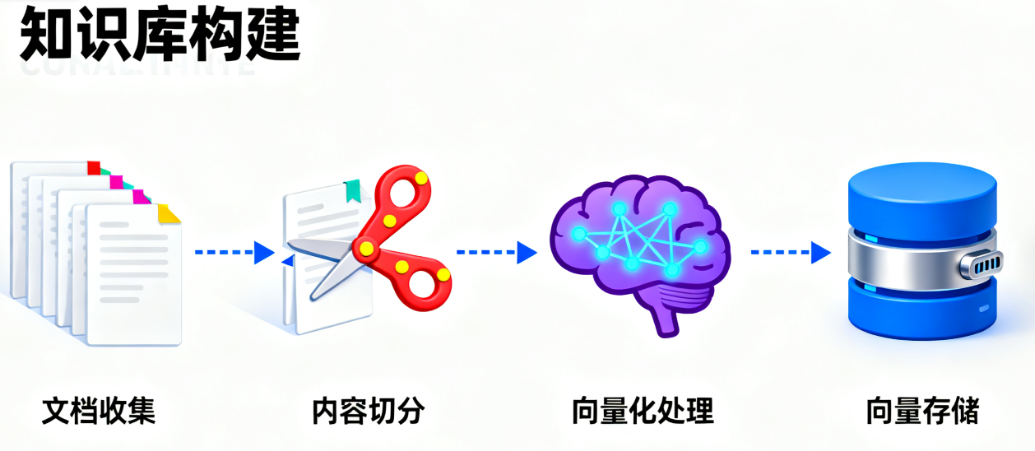
第一阶段:知识库构建(离线处理)- “制作小抄”
这个阶段就像考试前,学霸整理复习资料、制作“小抄”的过程。它是一次性的、在后台完成的。
- 加载数据 (Loading):首先,程序会读取你指定的所有文档源,无论是 PDF、TXT、Markdown 还是网页。
- 文档切分 (Chunking):一篇长达上万字的文档,直接丢给模型是不现实的。一来 LLM 的“桌子”(上下文窗口)放不下,二来信息太杂反而找不到重点。所以,我们会把文档切成一个个逻辑上独立的、几百字的小段落(Chunks)。
- 向量化 (Embedding):这是 RAG 的魔法核心!我们使用一个特殊的 AI 模型(Embedding Model),将每一个文本片段都转换成一串由几百或上千个数字组成的列表,这串数字就是“向量 (Vector)”。你可以把它想象成,我们为每一段话的“核心语义”都在一个巨大的、多维的“意义空间”里赋予了一个独一无二的坐标。意思相近的段落,它们的坐标也相近。
- 存入向量数据库 (Storing):最后,我们将这些文本片段和它们对应的“坐标”(向量),一同存入一个专门为此设计的数据库——向量数据库 (Vector Database)。这种数据库最擅长的事情就是:当你给它一个新坐标时,它能以毫秒级的速度告诉你,离这个坐标最近的邻居们都在哪里。
第二阶段:检索与生成(在线处理)- “考试答题”
当用户真正开始提问时,就进入了实时处理阶段。
- 问题向量化:同样地,用户的提问也会被同一个 Embedding 模型转换成一个“问题向量”,得到它在“意义空间”中的坐标。
- 相似度检索:系统拿着这个“问题坐标”,冲进向量数据库大喊一声:“谁离我最近?!” 数据库会迅速返回与问题坐标最接近的几个文本片段(也就是内容最相关的几份“小抄”)。
- 构建提示词 (Prompt Engineering):这是临门一脚!程序会创建一个精心设计的“模板”(Prompt Template),将上一步检索到的相关文本片段(我们称之为“上下文 Context”)和用户的原始问题(Query)组合成一个新的、信息量爆炸的提示词。
- 生成答案:最后,这个“增强版”的提示词被发送给 LLM。此刻的 LLM 如获至宝,它会严格依据你提供的上下文材料来组织语言,生成一个有理有据、忠于事实的答案。
我们来看一个典型的“增强版”Prompt 长什么样:
根据以下已知信息,简洁和专业地回答用户的问题。
如果无法从中得到答案,请说“根据已知信息,我无法回答该问题”,不允许在答案中添加编造成分。
## 已知信息:
## [这里是检索到的文档片段1,例如:RAG 技术通过检索外部知识库来增强 LLM 的能力...] [这里是检索到的文档片段2,例如:实现 RAG 的关键步骤包括文档切分、向量化和相似度搜索...] ...
用户问题: [用户的原始问题,例如:RAG 是如何工作的?]
看到这个 Prompt,LLM 就明白了它的“行动边界”:只能在“已知信息”里找答案,大大降低了胡说八道的可能性。
四、上手实战:5 分钟构建你的第一个 RAG 应用
理论说了一大堆,不如亲手敲几行代码来得实在!我们将使用 Python 和当前最火的 LLM 应用开发框架 LangChain,它把 RAG 的所有复杂步骤都封装成了简单易用的模块。
环境准备:
首先,确保你安装了必要的库,并且在你的环境变量中设置了 OPENAI_API_KEY。
pip install langchain openai faiss-cpu tiktoken
创建一个本地知识库文件 my_knowledge.txt:
RAG 的核心思想是“检索”加“生成”。
它首先从一个庞大的知识库中检索出与用户问题相关的文档片段。
然后,将这些片段与原始问题一起提供给大语言模型,让模型基于这些信息生成答案。
这项技术有效地解决了 LLM 知识过时和产生幻觉的问题。
开始写代码:
import os
from langchain.vectorstores import FAISS
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.chains import RetrievalQA
from langchain_community.chat_models import ChatOpenAI
from langchain_community.document_loaders import TextLoader
# 确保你的 OPENAI_API_KEY 已经设置在环境变量中
# os.environ["OPENAI_API_KEY"] = "sk-..."
# 1. 加载你的本地知识库文档
# TextLoader 负责读取我们的 .txt 文件
loader = TextLoader("./my_knowledge.txt")
documents = loader.load()
# 2. (隐式处理) LangChain 在背后会帮你做文本切分 (Chunking)
# 默认情况下,FAISS.from_documents 会处理切分逻辑
# 3. 向量化并构建索引 (Embedding & Storing)
# OpenAIEmbeddings() 负责将文本转换为向量
# FAISS 是一个高效的向量存储和检索引擎,这里我们用它在内存中创建一个小型的向量数据库
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(documents, embeddings)
# 4. 创建一个检索器 (Retriever)
# from_documents 已经帮我们做好了,我们可以直接从 vectorstore 创建一个检索器接口
retriever = vectorstore.as_retriever()
# 5. 创建一个问答链 (Chain)
# RetrievalQA 是 LangChain 封装好的标准 RAG 流程链
qa = RetrievalQA.from_chain_type(
llm=ChatOpenAI(model_name="gpt-3.5-turbo"),
chain_type="stuff", # "stuff" 是一种将所有检索到的文档“塞”进一个 Prompt 的简单策略
retriever=retriever
)
# 6. 开始提问!见证奇迹的时刻
query = "RAG 技术是如何解决 LLM 幻觉问题的?"
answer = qa.invoke(query) # 在新版 LangChain 中推荐使用 invoke
print(answer['result'])
# 预期输出会精准地基于 my_knowledge.txt 的内容
就是这么简单!短短十几行代码,我们就完成了一个功能完备的 RAG 应用。LangChain 帮我们处理了所有底层的复杂逻辑,让我们能专注于业务本身。
结语:RAG,不止是问答
好了,让我们来快速回顾一下。今天我们了解到:
- LLM 因为知识截止、幻觉、私有数据隔离三大痛点,急需一个“外挂”。
- RAG 通过 “检索”+“生成” 的“开卷考试”模式,完美解决了这些问题。
- 实现 RAG 的核心流程分为两步:离线构建知识库(加载、切分、向量化、存储)和在线问答(提问、检索、增强、生成)。
RAG 不仅仅是一项技术,它更代表了一种全新的 AI 应用构建范式:让强大的通用大模型(大脑)与动态、专业、可控的外部知识库(记忆)相结合,最终实现 1 + 1 > 2 的惊人效果。
如今,围绕 RAG 的探索远未停止,更高级的玩法,如优化检索结果的 Re-ranking、改善用户提问的 Query Transformation、以及将 RAG 与 Agent 结合的复杂应用,正在不断涌现,持续推动着 AI 能力的边界。
现在,轮到你了!动手用 RAG 为你的项目构建一个专属的知识问答机器人吧!在实践中你遇到了什么有趣的问题或脑洞大开的想法?欢迎在评论区留言和我一起讨论! 👇🚀
更多推荐
 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)