
YOLOv8【卷积创新篇·第27节】Sparse Convolution稀疏卷积优化!
🏆 本文收录于 《YOLOv8实战:从入门到深度优化》,该专栏持续复现网络上各种热门内容(全网YOLO改进最全最新的专栏,质量分97分+,全网顶流),改进内容支持(分类、检测、分割、追踪、关键点、OBB检测)。且专栏会随订阅人数上升而涨价(毕竟不断更新),当前性价比极高,有一定的参考&学习价值,部分内容会基于现有的国内外顶尖人工智能AIGC等AI大模型技术总结改进而来,嘎嘎硬核。 ✨ 特惠福利
🏆 本文收录于 《YOLOv8实战:从入门到深度优化》,该专栏持续复现网络上各种热门内容(全网YOLO改进最全最新的专栏,质量分97分+,全网顶流),改进内容支持(分类、检测、分割、追踪、关键点、OBB检测)。且专栏会随订阅人数上升而涨价(毕竟不断更新),当前性价比极高,有一定的参考&学习价值,部分内容会基于现有的国内外顶尖人工智能AIGC等AI大模型技术总结改进而来,嘎嘎硬核。
✨ 特惠福利:目前活动一折秒杀价!一次订阅,永久免费,所有后续更新内容均免费阅读!
全文目录:
⏩ 摘要
大家好,欢迎回到《YOLOv8专栏》卷积创新篇的第27节!在上一节中,我们探索了如何通过傅里叶卷积获得“全局视野”。今天,我们将转向一个截然不同的优化维度——效率。想象一下,当处理一张4K超高清航拍图,或者一帧自动驾驶的激光雷达点云时,其中真正有信息的“前景”像素或点云只占了极小一部分,而大部分是“背景”或“空白”。对这些海量的无效区域使用传统的密集卷积,无疑是巨大的计算资源浪费。稀疏卷积 (Sparse Convolution) 正是为解决这一问题而生的“节俭大师”!它独辟蹊径,只在存在有效信息的位置进行计算,跳过所有空白区域,从而在处理稀疏数据时实现数量级的性能提升。本文将带您深入理解稀疏卷积的革命性思想,从其核心的数据结构、运算原理,到如何在YOLOv8中巧妙地应用它来处理高分辨率图像,实现“看得清”与“算得快”的完美结合。准备好为你的模型装上效率引擎了吗?我们出发!🚀
⏩ 上期回顾:Fourier卷积频域特征学习
在上一节《YOLOv8【卷积创新篇·第26节】Fourier卷积频域特征学习》中,我们一同遨游了神奇的频域世界。我们了解到,借助傅里叶变换(FFT),可以将图像从空间域转换到频域,并通过 卷积定理,将复杂的空间域卷积操作,转化为高效的频域逐元素乘法。
这种方法的革命性之处在于,它仅用一层操作,就赋予了网络全局感受野,能够瞬时捕捉图像中任意两点之间的长距离依赖关系。我们不仅从零开始实现了一个FourierConv2d模块,还探讨了其在计算复杂度上相对于大核卷积的优势。更重要的是,我们学习了如何借鉴 傅里叶神经算子(FNO) 的思想,通过只学习低频模式来大幅削减参数量,并最终构思了将其集成到YOLOv8(如替换SPPF或构建C2fFourier模块)的几种实用策略。
傅里叶卷积为我们提供了从“全局”视角理解图像的强大武器。而今天,我们将从另一个极端——“局部”和“稀疏”的视角出发,看看如何通过忽略不重要的信息,来极致地压榨计算效率。让我们进入稀疏卷积的世界!🧐
⏩ 正文
⏩ 1. 稀疏性问题:为何密集卷积如此“浪费”?
在深入技术细节之前,我们必须先理解我们到底要解决什么问题。问题的核心,就在于“稀疏性”。
1.1 现实世界中的稀疏数据
“稀疏”指的是数据中大部分元素的值都是无效的(通常是零),而有效信息只占一小部分。这种现象其实非常普遍:
- 自动驾驶 (LiDAR点云): 激光雷达扫描一次环境,只会得到物体表面反射回来的点,这些点在三维空间中是极其稀疏的,点与点之间都是空的。
- 医疗影像 (病理切片): 在一张巨大的数字病理切片图像中,医生可能只关心少数几个细胞区域是否存在病变,绝大部分都是背景组织。
- 遥感与安防 (高分辨率图像): 在一张4K甚至8K的卫星图像或监控视频帧中,我们想检测的飞机、车辆或行人,可能只占了遥感与安防 (高分辨率图像) : 在一张4K甚至8K的卫星图像或监控视频帧中,我们想检测的飞机、车辆或行人,可能只占了不到1%的像素。
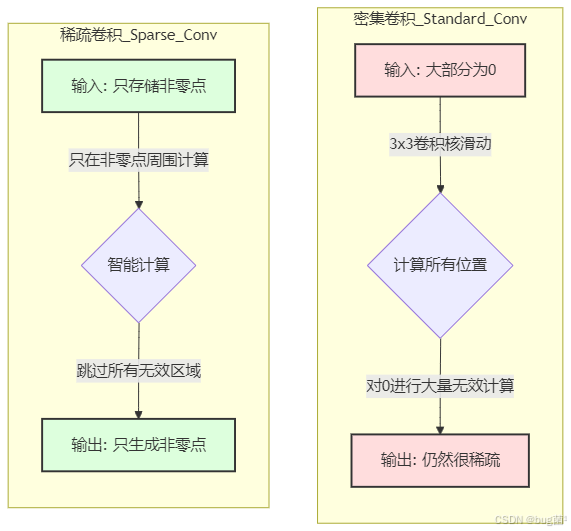
1.2 密集卷积的“空转”困境
标准的nn.Conv2d被设计用来处理 密集(Dense) 的矩阵。它会不加区分地在特征图的每一个位置上执行滑窗、乘加运算。
当输入一个大部分是0的稀疏特征图时,会发生什么?
- 无效的乘法: 卷积核的大部分计算都是与0相乘,结果还是0。
- 无效的加法: 大量的0被加在一起。
- 内存浪费: 我们需要分配一块巨大的内存来存储这些绝大多数为0的张量。
这就像让一个顶级的计算团队去数一仓库沙子里的几颗钻石,他们99.9%的时间都在处理没有价值的沙子,效率极其低下。
1.3 视化对比:密集 vs. 稀疏
我们可以用一个简单的图来展示这个困境:
⏩ 2. 稀疏卷积的核心思想:只为“有效”而计算
稀疏卷积的革命性在于,它彻底改变了数据的表示和处理方式。
2.1 数据新范式:坐标 + 特征
它不再使用一个巨大的、充满0的密集矩阵来存储数据,而是用两个更小的列表:
- 坐标列表 (Coordinates): 一个
N x D的整数矩阵,其中N是活动点的数量,D是维度(对于2D图像是2,3D点云是3,还需要加上一个batch索引,所以通常是D+1)。每一行代表一个活动点的坐标(batch_idx, zy, x)。 - 特征列表 (Features): 一个
N x C的浮点数矩阵,其中C是通道数。每一行对应坐标列表中相应点的特征向量。
这种表示方法,内存占用只与活动点的数量成正比,而与整个空间的体积无关,极大地节省了内存。
2.2 卷积新流程:只在“活动点”上操作
有了新的数据表示,卷积流程也焕然一新:
- 输入: 接收一个稀疏张量(坐标列表 + 特征列表)。
- 确定输出: 遍历所有输入的活动点,根据卷积核的形状,计算出可能产生有效输出的输出活动点的位置。
- 信息收集: 对于每一个输出活动点,找到所有能对它产生贡献的输入活动点(即卷积核能覆盖到的输入点)。
- 执行计算: 像标准卷积一样,将收集到的输入特征与对应的卷积核权重相乘,然后求和,得到该输出点的最终特征。
- 输出: 生成一个新的稀疏张量(新的坐标列表 + 新的特征列表)。
整个过程的核心在于第2步和第3步,它保证了计算只发生在“有输入信息”且“能产生输出信息”的地方。
⏩ 3. 成功的秘诀:哈希表与规则书 (Rulebook)
你可能会问:这个“确定连接关系”的过程听起来很复杂,每次都重新计算岂不是很慢?这正是稀疏卷积最巧妙的设计所在,它使用 哈希表(Hash Table) 来高效解决这个问题。
3.1 如何确定输入与输出的连接关系?
主流的稀疏卷积库(如spconv, MinkowskiEngine)会预计算一个叫做 “规则书”(Rulebook) 的东西。这个过程通常发生在第一次前向传播时,然后被缓存下来,后续迭代可以直接使用。
-
哈希化坐标: 将所有输入活动点的坐标(例如
(x, y, z))通过一个哈希函数转换成一个唯一的键(key)。 -
构建哈希表: 创建一个哈希表,将哈希键映射到该点在特征列表中的索引。这使得我们可以通过坐标快速查找到它的特征。
-
生成规则:
- 遍历每一个输入活动点
p_in。 - 遍历卷积核中的每一个偏移量
delta(例如,对于3x3核,有9个偏移量)。 - 计算出潜在的输出点坐标
p_out p_in + delta。 - 查询哈希表,看看
p_out对应的位置是否存在一个输入活动点。 - 如果存在,就在“规则书”中记录下这条连接关系:
p_out的计算需要用到p_in。
- 遍历每一个输入活动点
3.2 “规则书”生成过程图解
让我们用一个2D的例子来形象地理解这个过程。假设我们有一个3x3的卷积核,输入只有一个活动点在 (2,2)。
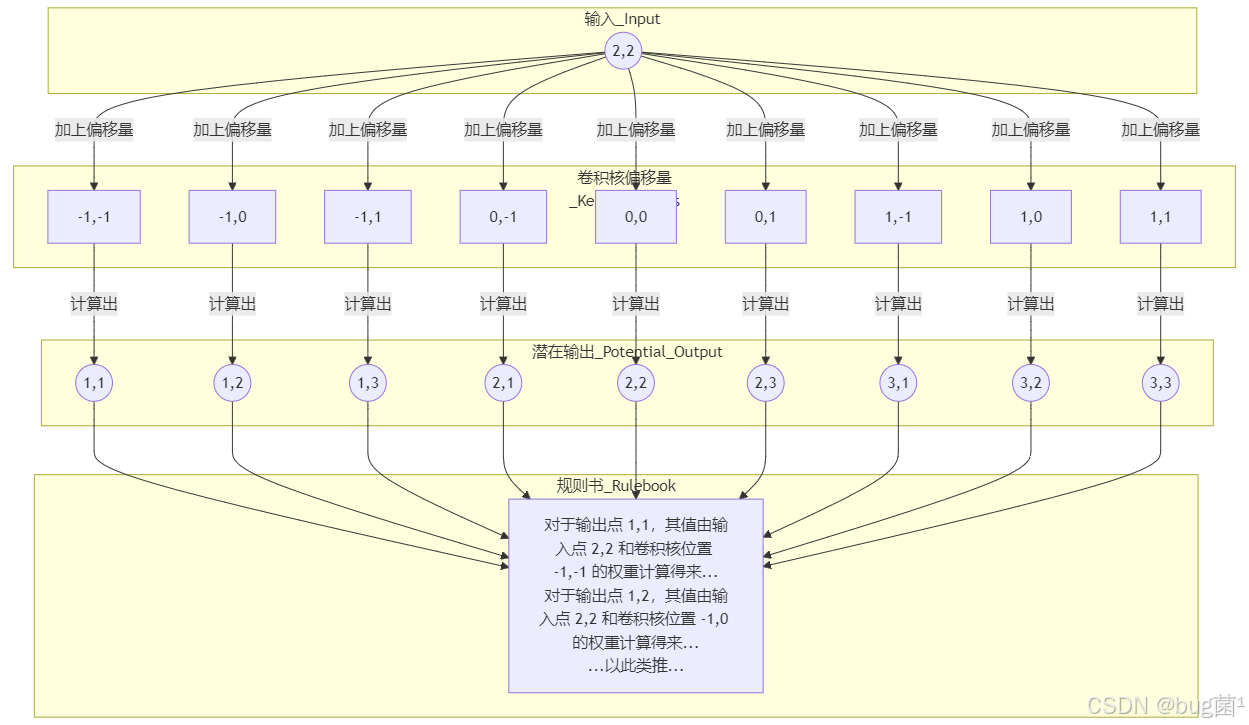
这个“规则书”一旦生成,就包含了所有输入-输出的对应关系。之后的卷积计算就变成了一个高效的查表和稀疏矩阵乘法过程,速度非常快。
3.3 子流形稀疏卷积 (Submanifold Sparse Convolution)
一个常见的稀疏卷积变体是子流形稀疏卷积 (Submanifold Sparse Convolution)。它的一个关键规则是:
只有当一个位置的中心(即卷积核中心对应的位置)有输入的活动点时,这个输出位置才会被激活并进行计算。
这意味着,输出的活动点集合与输入的活动点集合是完全相同的。它不会“创造”新的活动点,因此不会使数据变得更密集。这在网络的深层非常有用,可以防止特征图的稀疏性被破坏,保持计算的高效性。
而普通的稀疏卷积(spconv.SparseConvd)则会像标准卷积一样,在活动点的周围“膨胀”出一圈新的活动点。
⏩ 4. YOLOv8策略:赋能高分辨率检测
好了,理论讲了这么多,怎么把它用到我们的YOLOv8上呢?稀疏卷积在2D检测中的杀手级应用场景就是处理高分辨率图像。
4.1 挑战:直接下采样会丢失小目标
标准YOLOv8为了效率,通常会将输入图像(例如1920x1080)强制缩放到一个较小的尺寸(如640x640)。这个过程虽然简单粗暴有效,但代价是巨大的:
- 信息丢失: 图像中的小物体(比如远处的行人)在下采样后可能就变成了一个模糊的像素点,甚至直接消失,神仙也检测不出来。
- 形变: 强制的缩放会改变物体的长宽比,对检测精度有一定影响。
如果我们想在原始的高分辨率上进行检测,直接把640x640的模型改成处理1920x1080,计算量和显存会暴增到无法承受的程度。
4.2 “稀疏化-稀疏骨干-密集化”三部曲
这正是稀疏卷积的用武之地!我们可以设计一个混合架构:
-
稀疏化 (Sparsification):
- 不直接下采样!而是先对原始高分辨率图像进行一个快速的“前景提取”。
- 这可以是一个简单的阈值操作(如只保留颜色鲜艳的像素),也可以是一个轻量级的分割网络,或者利用图像的梯度信息找到边缘。
- 我们的目标是生成成一个稀疏的“活动像素”集合,并将其转换为稀疏张量(坐标+特征)。
-
稀疏骨干 (Sparse Backbone):
- 将YOLOv8骨干网络的前几层(这些层处理的特征图分辨率最高,计算量最大)替换为 卷积层。
- 这些稀疏卷积层只在“活动像素”上进行计算,高效地提取高分辨率特征,同时保持特征图的原始尺寸或进行稀疏的下采样。
-
密集化 (Densification):
- 当特征图经过几层稀疏卷积,分辨率降低到一定程度时(例如,下采样了8倍),数据通常会变得相对密集。
- 此时,我们将稀疏张量转换回标准的密集张量 (
sparse_tensor.dense())。 - 将这个密集的、但分辨率已经降低的特征图,送入YOLOv8 剩下的标准骨干网络、Neck和Head中进行后续处理。
这个策略的精髓在于:算最昂贵的高分辨率阶段使用稀疏卷积,在特征更抽象、分辨率更低的阶段切换回高度优化的密集卷积。
4.3 架构图:Sparse-YOLOv8

⏩ 5. 代码实践:构建一个混合稀疏-密集模块
让我们用代码来勾勒出这个想法。我们将使用spconv-cu18库作为示例,你需要先安装它(pip install spconv-cu118,请根据你的CUDA版本选择)。
5.1 关键库:spconv
spconv是目前在3D检测领域广泛使用的高性能稀疏卷积库。它的API与PyTorch的nn.Module非常相似,易于上手。
5.2 稀疏-密集转换
首先,我们需要两个工具函数:
import torch
import spconv.pytorch as spconv
def dense_to_sparse(x: torch.Tensor):
"""
将密集张量转换为稀疏张量
:param x: 稠密张量, 形状 (B, C, H, W)
:return: spconv.SparseConvTensor
"""
# 找到所有非零元素的索引
# 我们假设背景是0,非背景是有效信息
# non_zero_mask: (B, C, H, W) -> bool
non_zero_mask = x.abs().sum(dim=1) > 0
# coords: (N, 3) -> (batch_idx, y, x)
# N是所有批次中非零点的总数
coords = torch.nonzero(non_zero_mask).int()
# 调整坐标顺序以匹配spconv的要求: (batch_idx, z, y, x)
# 对于2D,我们没有z轴,所以用0填充
coords_spconv = torch.zeros((coords.shape[0], 4), dtype=torch.int32, device=x.device)
coords_spconv[:, 0] = coords[:, 0] # batch_idx
coords_spconv[:, 2] = coords[:, 1] # y
coords_spconv[:, 3] = coords[:, 2] # x
# 获取非零位置的特征
features = x[non_zero_mask]
# 获取空间尺寸和批次大小
spatial_shape = [x.shape[2], x.shape[3]] # [H, W]
batch_size = x.shape[0]
# 创建稀疏张量
sparse_tensor = spconv.SparseConvTensor(features, coords_spconv, spatial_shape, batch_size)
return sparse_tensor
# 密集化操作很简单,spconv直接提供了方法
# sparse_tensor.dense()
代码解析:
dense_to_sparse的核心是torch.nonzero,它能找到所有非零值的索引。- 我们将找到的索引整理成
spconv要求的格式(batch_idx, z, y, x)。对于2D图像,z轴坐标为0。 - 然后,我们根据这些索引,从原始张量中提取出对应的特征。
- 最后,用特征、坐标、空间尺寸和批大小,创建一个
spconv.SparseConvTensor对象。
5.3 C2fSparse 模块概念代码与解析
现在,我们可以仿照YOLOv8的C2f模块,设计一个C2fSparse模块,作为我们稀疏骨干的一部分。
import torch.nn as nn
# 假设已经定义了上面的 dense_to_sparse 函数
# 并已安装 spconv
class SparseBottleneck(nn.Module)::
"""一个使用稀疏卷积的Bottleneck"""
def __init__(self, c1, c2, shortcut=True, g=1 e=0.5):
super().__init__()
c_ = int(c2 * e) # hidden channels
# 使用SubmanifoldSparseConvolution保持稀疏性
self.cv1 = spconv.SubMConv2d(c1, c_, kernel_size=3, padding=1, bias=False, indice_key="subm0")
self.bn1 = nn.BatchNorm1d(c_) # 稀疏卷积的BN是一维的
self.act = nn.ReLU()
self.cv2 = spconv.SubMConv2d(c_, c2, kernel_size=3, padding=1, bias=False, indice_key="subm0")
self.bn2 = nn.BatchNorm1d(c2)
self.add = shortcut and c1 == c2
def forward(self, x: spconv.SparseConvTensor):
y = x
x_features = self.act(self.bn1(self.cv1(x).features))
x = x.replace_feature(x_features) # 更新特征
x_features = self.bn2(self.cv2(x).features)
if self.add:
x_features += y.features
return x.replace_feature(self.act(x_features))
class InitialSparseBlock(nn.Module):
"""
模型最开始的混合块:密集输入->稀疏处理->密集输出
"""
def __init__(self, in_channels, out_channels, n=3):
super().__init__()
# 第一个卷积是带步长的稀疏卷积,用于下采样
self.sparse_conv_downsample = spconv.SparseConv2d(
in_channels, out_channels, kernel_size=3, stride=2, padding=1, bias=False
)
self.bn_down = nn.BatchNorm1d(out_channels)
self.act = nn.ReLU()
# 后面接n个子流形稀疏卷积瓶颈层
self.sparse_bottlenecks = nn.Sequential(
*[SparseBottleneck(out_channels, out_channels, shortcut=True) for _ in range(n)]
)
def forward(self, x):
# 1. 密集 -> 稀疏
sparse_x = dense_to_sparse(x)
print(f"稀疏化后,活动点数量: {sparse_x.features.shape[0]}")
# 2. 稀疏处理
sparse_x = self.sparse_conv_downsample(sparse_x)
sparse_x = sparse_x.replace_feature(self.act(self.bn_down(sparse_x.features)))
sparse_x = self.sparse_bottlenecks(sparse_x)
# 3. 稀疏 -> 密集
dense_out = sparse_x.dense()
return dense_out
# --- 使用示例 ---
# 模拟一个高分辨率、但很稀疏的输入
high_res_input = torch.zeros(1, 3, 256, 256)
high_res_input[:, :, 100:150, 100:150] = torch.randn(1, 3, 50, 50) # 中间有一块非零区域
print(f"输入尺寸: {high_res_input.shape}")
print(f"输入非零元素比例: {high_res_input.count_nonzero() / high_res_input.numel():.4f}")
# 创建混合模块
sparse_block = InitialSparseBlock(in_channels=3, out_channels=64, n=2)
# 执行前向传播
output_tensor = sparse_block(high_res_input)
print(f"输出尺寸: {output_tensor.shape}")
代码解析:
-
SparseBottleneck: 我们定义了一个使用稀疏卷积的瓶颈层。注意,我们用了spconv.SubMConv2d,这是一种子流形稀疏卷积,它不会改变活动点的数量,非常适合在残差结构中使用。另外,稀疏卷积的BN层是nnBatchNorm1d,因为它作用在N x C的特征列表上。 -
InitialSparseBlock: 这是我们设计的混合模块。- 它的
forward函数完美地展示了“三部曲”:dense_to_sparse-> 稀疏卷积处理 ->sparse_tensor.dense()。 - 下采样由第一个
spconv.SparseConv2d(注意不是SubMConv)通过设置stride=2来完成。
- 它的
-
使用示例: 我们创建了一个256x256的模拟输入,但其中只有一小块区域有值,很好地模拟了稀疏性。你可以看到,通过这个模块后,输出的特征图尺寸减半(因为stride=2),并且变回了我们可以送入标准YOLOv8的密集张量。
⏩ 6. 总结与展望
今天,我们深入探讨了稀疏卷积这一强大的优化技术,它为处理现实世界中普遍存在的稀疏数据提供了优雅而高效的解决方案。
核心知识点回顾:
- 稀疏性: 许多数据(如点云、高分辨率图像)的有效信息只占一小部分,用密集卷积处理是巨大的浪费。
- 核心思想: 稀疏卷积通过“坐标+特征”的数据表示,并借助哈希表和“规则书”机制,实现了只在活动点上进行计算,从而大大节省了计算和内存。
- 子流疏卷积: 一种特殊的稀疏卷积,保持输入和输出的活动点集不变,非常适合构建深层稀疏网络。
- YOLOv8应用: 通过“稀疏化-稀疏骨干-密集化”的混合架构,稀疏卷积可以赋能YOLOv8高效处理高分辨率图像,在不牺牲小目标信息的前提下,避免了计算爆炸。
稀疏卷积的思想不仅是一种模型优化技巧,更是一种高效计算的哲学。它告诉我们,计算资源应该被用在“刀刃上”。虽然在YOLOv8这样的2D检测器中,它的应用不像在3D领域那样成为标配,但随着图像分辨率的不断提升和边缘设备算力的限制,这种为效率而生的技术必将展现出越来越大的价值。
希望今天的学习能启发你,在面对特定场景的性能瓶颈时,能够跳出传统密集计算的思维框架,从数据本身的特性中寻找优化的钥匙!🔑
⏩ 下期预告:Binary Neural Network二积
今天我们通过“跳过”无效计算来追求效率。然而,还有一群更极致的探索者,他们在思考一个更疯狂的问题:我们能否让每一次计算本身变得极其廉价?
如果模型的权重不再是32位的浮点数,而是只有+1和-1这两个值呢?如果连特征图的激活值也只有+1和-1呢?那么,昂贵的浮点乘法运算,将直接退化为简单的 异或(XNOR) 位运算!这将带来数十倍的理论加速和模型压缩比!
下一节,《YOLOv8【卷积创新篇·第28节】Binary Neural Network二值卷积》,我们将踏入这个极致轻量化的世界,探索如何在几乎不使用乘法的情况下构建一个神经网络。我们将学习权重和激活的二值化方法、梯度如何在离散的参数上传播,以及如何弥补二值化带来的巨大精度损失。准备好迎接一场对神经网络计算方式的终极颠覆吧!🤯✨✨
希望本文所提供的YOLOv8内容能够帮助到你,特别是在模型精度提升和推理速度优化方面。
PS:如果你在按照本文提供的方法进行YOLOv8优化后,依然遇到问题,请不要急躁或抱怨!YOLOv8作为一个高度复杂的目标检测框架,其优化过程涉及硬件、数据集、训练参数等多方面因素。如果你在应用过程中遇到新的Bug或未解决的问题,欢迎将其粘贴到评论区,我们可以一起分析、探讨解决方案。如果你有新的优化思路,也欢迎分享给大家,互相学习,共同进步!
🧧🧧 文末福利,等你来拿!🧧🧧
文中讨论的技术问题大部分来源于我在YOLOv8项目开发中的亲身经历,也有部分来自网络及读者提供的案例。如果文中内容涉及版权问题,请及时告知,我会立即修改或删除。同时,部分解答思路和步骤来自全网社区及人工智能问答平台,若未能帮助到你,还请谅解!YOLOv8模型的优化过程复杂多变,遇到不同的环境、数据集或任务时,解决方案也各不相同。如果你有更优的解决方案,欢迎在评论区分享,撰写教程与方案,帮助更多开发者提升YOLOv8应用的精度与效率!
OK,以上就是我这期关于YOLOv8优化的解决方案,如果你还想深入了解更多YOLOv8相关的优化策略与技巧,欢迎查看我专门收集YOLOv8及其他目标检测技术的专栏《YOLOv8实战:从入门到深度优化》。希望我的分享能帮你解决在YOLOv8应用中的难题,提升你的技术水平。下期再见!
码字不易,如果这篇文章对你有所帮助,帮忙给我来个一键三连(关注、点赞、收藏),你的支持是我持续创作的最大动力。
同时也推荐大家关注我的公众号:「猿圈奇妙屋」,第一时间获取更多YOLOv8优化内容及技术资源,包括目标检测相关的最新优化方案、BAT大厂面试题、技术书籍、工具等,期待与你一起学习,共同进步!
🫵 Who am I?
我是bug菌,CSDN | 掘金 | InfoQ | 51CTO | 华为云 | 阿里云 | 腾讯云 等社区博客专家,C站博客之星Top30,华为云多年度十佳博主,掘金多年度人气作者Top40,掘金等各大社区平台签约作者,51CTO年度博主Top12,掘金/InfoQ/51CTO等社区优质创作者;全网粉丝合计 30w+;更多精彩福利点击这里;硬核微信公众号「猿圈奇妙屋」,欢迎你的加入!免费白嫖最新BAT互联网公司面试真题、4000G PDF电子书籍、简历模板等海量资料,你想要的我都有,关键是你不来拿。

-End-
更多推荐


 17
17 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)