
在线教程丨百倍提速,中科院团队发布首个国产类脑脉冲大模型SpikingBrain-1.0,推理效率数量级提升
「SpikingBrain-1.0 基于内生复杂性的类脑脉冲大模型」已上线至 HyperAI超神经官网的「教程」板块,快来体验我国首个大规模类脑线性基础模型吧!
人工智能的快速发展几乎都离不开一个核心架构——Transformer。自从 2017 年被提出以来,Transformer 以其并行化的计算能力和强大的建模效果,成为大模型架构的主流标准。无论是 GPT 系列、LLaMA,还是国内的 Qwen 系列,它们都建立在 Transformer 的基础上。
然而,随着模型规模不断扩大,Transformer 逐渐暴露出一些难以忽视的问题,例如训练时开销随序列长度呈平方级增长,推理时显存占用随序列长度线性增加,造成资源消耗,导致其处理超长序列能力受限等。
与此形成鲜明对比的是,生物大脑在能效和灵活性上展现了完全不同的道路。人类大脑仅消耗约 20 瓦功率,却能处理感知、记忆、语言和复杂推理等海量任务。这种对比不禁让研究者开始深思:如果让大模型在设计和计算方式上更接近大脑,是否就能突破 Transformer 带来的瓶颈?
基于这一探索,中国科学院自动化研究所联合脑认知与类脑智能全国重点实验室等机构借鉴了大脑神经元内部复杂工作机制,提出「基于内生复杂性」大模型构架方式,并于今年 9 月发布了一款原生国产自主可控类脑脉冲大模型——「瞬悉 1.0(SpikingBrain-1.0)」。 该模型在理论上建立了脉冲神经元内生动力学与线性注意力模型之间的联系,揭示了现有线性注意力机制是树突计算的特殊简化形式,展示出一条不断提升模型复杂度和性能的新型可行路径。进一步,研发团队构建并开源了基于脉冲神经元、具有线性及混合线性复杂度的新型类脑基础模型,开发出面向国产 GPU 集群高效训练和推理框架、Triton 算子库、模型并行策略、集群通信原语。
通过实验验证,SpikingBrain-1.0 在实现极低数据量高效训练、实现推理效率数量级提升、构建国产自主可控类脑大模型生态、提出基于动态阈值脉冲化的多尺度稀疏机制 4 个性能方面均实现突破。 其中,SpikingBrain-7B 模型在 400 万个 token 序列的首个 token 时间(Time to First Token)方面实现了超过 100 倍的加速。在数百块 MetaX C550 GPU 上,SpikingBrain-7B 模型的训练可稳定运行数周,其模型 FLOP 利用率达到 23.4%。所提出的脉冲方案实现了 69.15% 的稀疏度,从而实现了低功耗运行。
值得注意的是,这是我国首次提出大规模类脑线性基础模型架构,并首次在国产 GPU 算力集群上构建类脑脉冲大模型的训练和推理框架。 其超长序列处理能力在法律与医学文档分析、复杂多智能体模拟、高能粒子物理实验、DNA 序列分析、分子动力学轨迹等超长序列任务建模场景中具有显著的潜在效率优势。
目前,「SpikingBrain-1.0 基于内生复杂性的类脑脉冲大模型」已上线至 HyperAI超神经官网的「教程」板块,点击下方链接即可体验一键部署教程 ⬇️
教程链接:
https://go.hyper.ai/T8hos
Demo 运行
- 进入 hyper.ai 首页后,选择「教程」页面,并选择「SpikingBrain-1.0 基于内生复杂性的类脑脉冲大模型」,点击「在线运行此教程」。


2.页面跳转后,点击右上角「克隆」,将该教程克隆至自己的容器中。

- 选择「NVIDIA RTX A6000 48GB」以及「PyTorch」镜像,并点击「继续执行」。OpenBayes 平台提供了 4 种计费方式,大家可以按照需求选择「按量付费」或「包日/周/月」。新用户使用下方邀请链接注册,可获得 4 小时 RTX 4090 + 5 小时 CPU 的免费时长!
HyperAI超神经专属邀请链接(直接复制到浏览器打开):
https://openbayes.com/console/signup?r=Ada0322_NR0n


4.等待分配资源,首次克隆需等待 3 分钟左右的时间。当状态变为「运行中」后,点击「API 地址」旁边的跳转箭头,即可跳转至 Demo 页面。请注意,用户需在实名认证后才能使用 API 地址访问功能。

5.在对话框输入问题即可开始进行对答。

效果演示
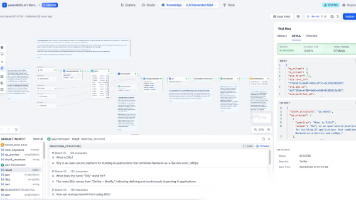
笔者以「Show me a code snippet of a website’s sticky header in CSS and JavaScript.」为例进行提问,效果如下图所示:

以上就是 HyperAI超神经本期推荐的教程,欢迎大家前来体验!
教程链接:
https://go.hyper.ai/T8hos
更多推荐
 18
18 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)