
Cherry Studio实战使用
概述、对话框、助手、模型配置、设置、网络搜索、文档处理、CSS、分组、全局记忆、MCP、API服务器、调用链;应用:小程序、知识库、绘画、智能体、翻译、文件、代码工具。
概述
官网,开源(GitHub,33.6K Star,3K Fork)。
客户端相比官网Chat聊天的优势:
- 多供应商集成
- 对话结果本地保存,支持导出
- 功能扩展丰富
类似产品:Lobe Chat、Chatbox、Chatwise。
功能强大
- 支持主流AI模型:OpenAI、Gemini、Claude等,一个客户端全搞定;
- 内置300+专业AI助手,从写作、编程到设计;
- 可自定义AI助手,打造专属智能伙伴;
- 支持多模型同时对话,方便对比不同AI的回答;
- 强大的文件处理能力;
- 支持WebDAV文件管理,数据备份。
对话框
以Windows系统为例,从官网下载exe安装包,双击安装即可。
工具按钮比较多,默认折叠起来;点击展开,从左到右分别是:新话题、上传图片/文档、网络搜索、知识库、MCP设置、选择模型、快捷短语、清空消息、展开、清除上下文。
看一下回答内容右下角支持的操作,几个按钮功能如图:
遇到的其他问题: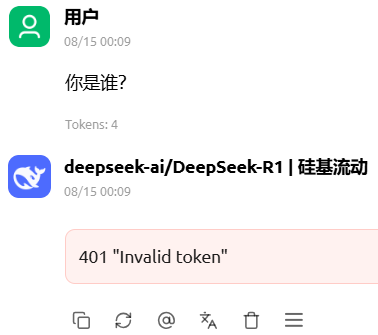
401 Invalid token:表示模型API Key配置有误。
配置连接本地部署的Ollama模型,发起Query,报错502(no body)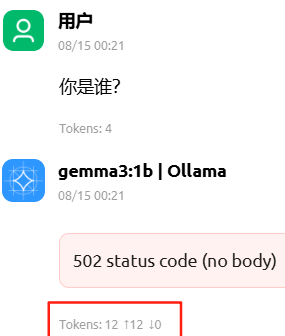
解决方法:TODO
助手

系统内置助手:默认助手、产品经理、策略产品经理、社群运营、内容运营、商家运营、产品运营、销售运营、用户运营、市场营销、商业数据分析、项目管理、SEO专家、网站运营数据分析、数据分析师、前端工程师、运维工程师、开发工程师、测试工程师、HR人力资源管理、行政、财务顾问、医生、编辑、哲学家、采购、法务、翻译成中文、英语单词背诵助手、文章总结、招聘、表情符号翻译、美文排版、会议精要、PPT精炼、爆款文案、影剧推荐、职业导航、影评达人、营销策划、面试模拟、要点精炼、推闻快写、诗意创作、期刊审稿、宣传slogan、网页生成、汉语新解卡片、Unicode字符替换、心理模型专家、概念框架开发者、认知科学研究员、分析性思维导师、供应链策略专家、数字营销助手、数字艺术创作助手、虚拟导游、个性化健康顾问、虚拟教练专家、动作捕捉分析专家、游戏社区经理、电子游戏评论员、电竞高级选手、ChatGPT SEO提示、以太坊开发人员、Linux终端、英语翻译和改进者、面试官、Excel表格、英语发音助手、英语口语教师和改进者、旅游指南、抄袭检查工具、角色扮演、广告商、故事讲述者、足球评论员、脱口秀喜剧演员、励志教练、作曲家、辩手、辩论教练、电影评论家、关系辅导员、诗人、说唱歌手、励志演讲者、哲学教师、哲学家、数学老师、AI写作导师、UX/UI开发者、网络安全专家、招聘人员、人生教练、词源学家、评论员、魔术师、职业顾问、宠物行为专家。
添加助手,支持自定义,比如新增绘图大师,提示文案有点问题:
模型配置
包括模型服务和默认模型两个配置,模型服务支持列表非常齐全,模型平台备注,支持markdown格式。支持新增提供商: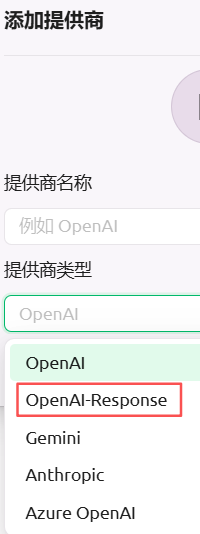
默认列表已经有OpenAI,这个应该是OpenAI兼容(compatible)提供商Server?
OpenAI-Response和OpenAI啥区别呢??
以百炼为例,填写API Key之后,默认列出5个模型,都是推理模型。需要自己新增embedding模型(如text-embedding-v4)、reranker模型(如gte-rerank-v2)。
默认模型,用于设置三种场景的默认模型: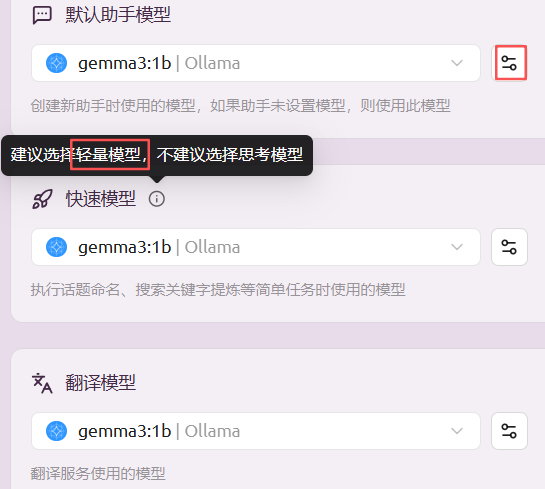
每个场景都能个性化设置。
设置
点击设置
网络搜索
其他设置-网络搜索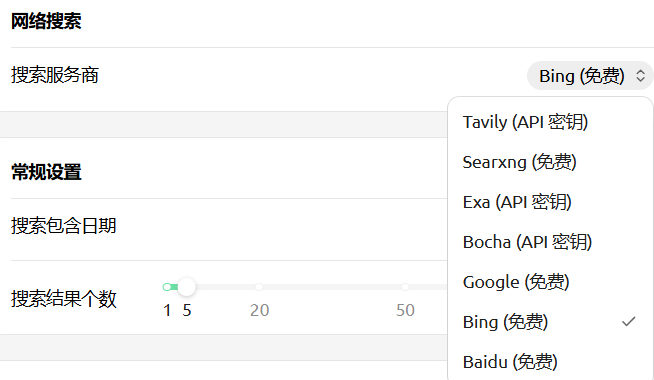
搜索结果压缩,三个选项:不压缩、截断、RAG,
黑名单,支持正则表达式形式过滤搜索结果。
黑名单订阅,可屏蔽一大堆垃圾网站的的内容,这样就不用在黑名单设置中一个个手输,将 https://git.io/ublacklist 添加到订阅源中,直接访问这个网址能看到所有订阅要屏蔽的网站地址。
联网搜索分为两类:
- 模型自带搜索功能,有些模型显示支持联网搜索,但实际上不支持;
- 使用第三方搜索服务。
使用第三方搜索服务,会经历两个阶段:
- 提取用户提问内容:将提问发送给大模型->从模型获取格式化响应->解析格式化响应提取关键词->根据关键词搜索网页->保存网页内容
- 向大模型提问:将用户提问和之前保存的网页内容一并发送给模型->模型响应
搜索结果压缩,为了解决联网搜索的结果过长超过模型上下文的问题。
配置阿里云百炼,搜索引擎使用百度,结果错误: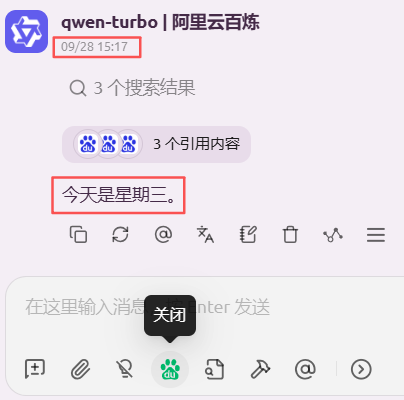
文档处理
即OCR服务。OCR服务提供商有三种:Tesseract、系统OCR(默认)、PaddleOCR。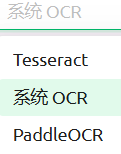
支持的语言,可多选,依赖于操作系统:
文档处理服务商也有三个:MinerU、Doc2x、Mistral。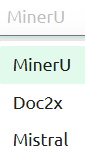
CSS
支持自定义CSS样式,设置->显示设置->自定义CSS,点击右侧https://cherrycss.com/,找到喜欢的风格,点击即复制代码,粘帖到编辑框,即时生效。
分组
全局记忆
开启全局记忆,需要提前配置好embedding模型,如text-embedding-v4
添加记忆: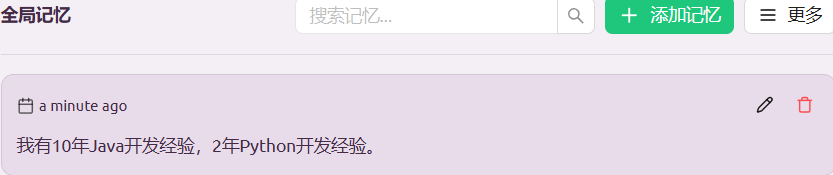
怎么使用呢??
MCP
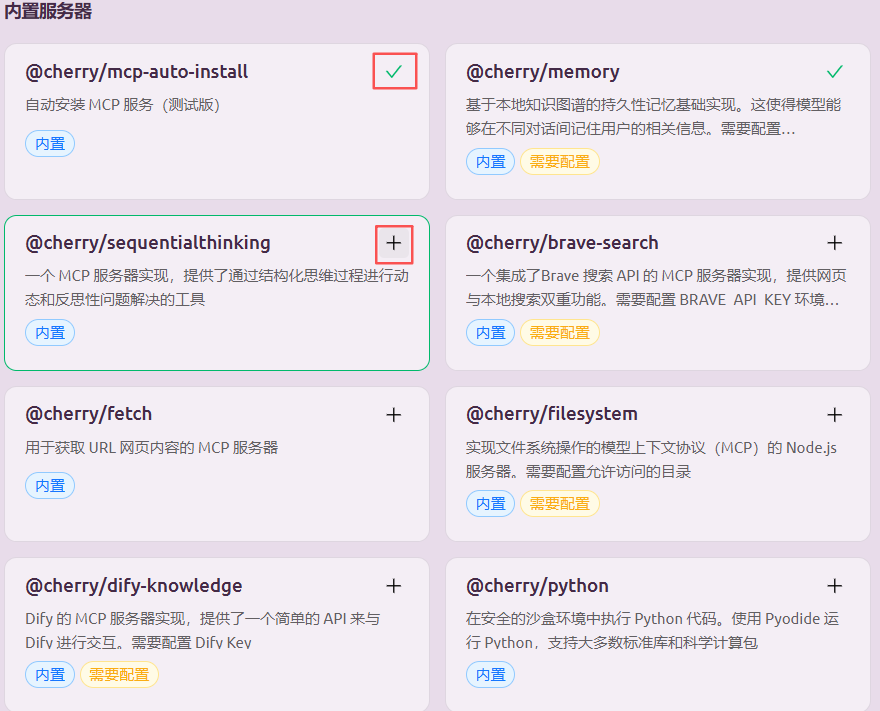
内置8个MCP Server,点击右上角的+,相当于安装:
- mcp-auto-install:自动安装MCP Server,用于测试
- memory:基于本地知识图谱的持久性记忆基础实现,使得模型能够在不同对话间记住用户的相关信息
- fetch:获取URL网页内容,即爬虫
- filesystem:操作本地文件系统
- dify-knowledge:支持与Dify进行简单交互
- python:提供安全沙盒环境,可基于Pyodide(GitHub,基于 WebAssembly的可用于浏览器和Node.js环境的Python发行版)运行Python代码,支持大多数标准库和科学计算包
此外提供10个MCP集市(Hub)超链接,方便用户找到更多有用的MCP Server,然后可集成到Cherry Studio中: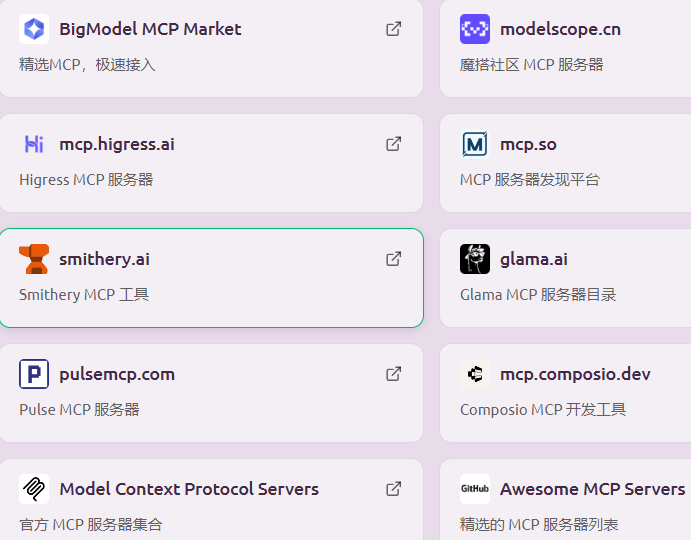
新增MCP Server,支持三种方式: - 快速创建
- 从JSON导入
- 从DXT导入

mcp.jsonJSON文件,在之前的MCP系列文章中多次提过:
{
"mcpServers": {
"playwright": {
"command": "npx",
"args": [
"@playwright/mcp@latest"
]
}
}
}
DXT,原Desktop Extensions,anthropics开源,后改名为MCPB(MCP Bundles),参考GitHub。此处Cherry Studio依旧保留旧的命名方式,但未引入新的命名方式。
编辑,实际上就是编辑上面mcp.json文件。
告警提示
同步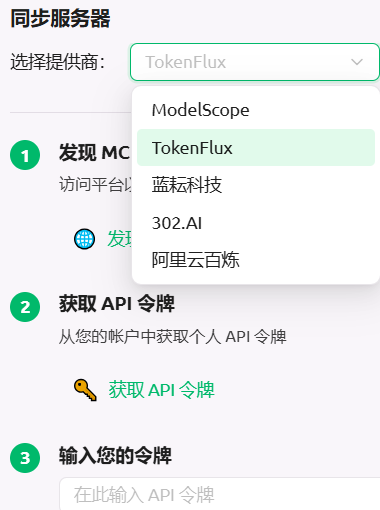
快捷创建,或编辑MCP Server时,注意到类型有三种:
- stdio:标准输入/输出
- sse:服务器发送事件
- streamableHttp:可流式传输的HTTP

通过Python代码启动一个本地MCP Server:
from fastapi import FastAPI
from fastapi_mcp import FastApiMCP
import uvicorn
app = FastAPI()
@app.get("/text", operation_id="text")
async def hello():
return "Hello"
mcp = FastApiMCP(
app, name="测试MCP",
description="测试",
)
mcp.mount(mount_path='/test-mcp')
if __name__ == '__main__':
uvicorn.run(app, host="0.0.0.0", port=8000)
python demo.py,启动日志:
选择SSE类型后开启MCP Server却报错:
原因在于URL配置为http://0.0.0.0:8000/test-mcp,改成http://localhost:8000/test-mcp,可看到连接成功,【工具】标签页下出现Hello,描述也是代码里指定的测试:
这个应该是Cherry Studio的Bug?!
API服务器
调用链
常规设置,启用开发者模式后,将可使用调用链功能查看模型调用过程的数据流。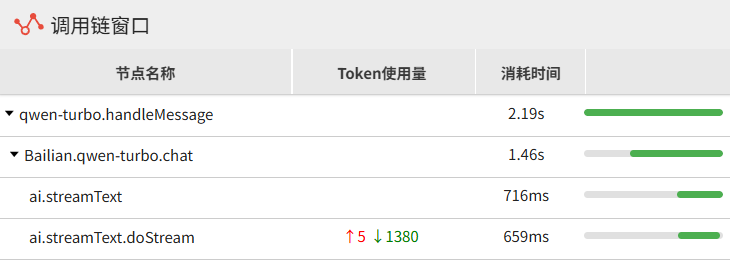
底部指出,该功能得到阿里云EDAS的加持。
应用
点击左上角加号:
小程序
小程序,其实就是通过H5的形式,把市面上最常见的聊天应用嵌入到Cherry Studio里:

新版本这个列表持续新增中,比如美团最新发布的龙猫(LongCat);部分应用需要有代理才能使用,如ChatGPT:
右上角几个按钮的解读:
- 在浏览器中打开
- 添加到启动台,也就是添加到顶部的
+按钮里,方便快速找到
- 链接:貌似没啥用
- 最小化
知识库
新增知识库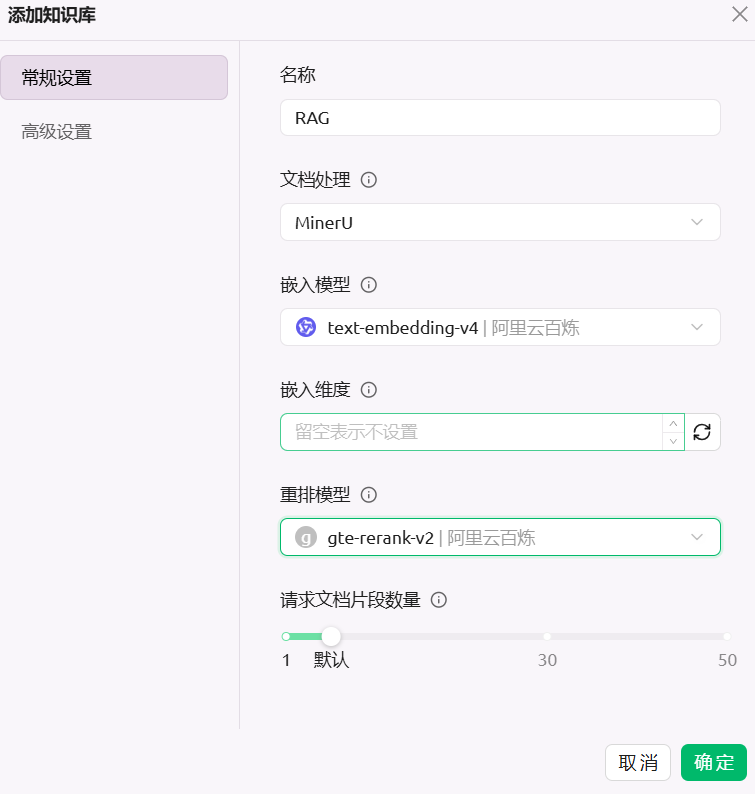
高级设置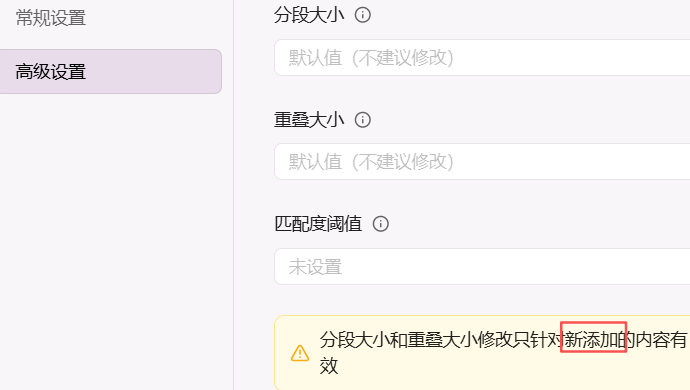
导入文件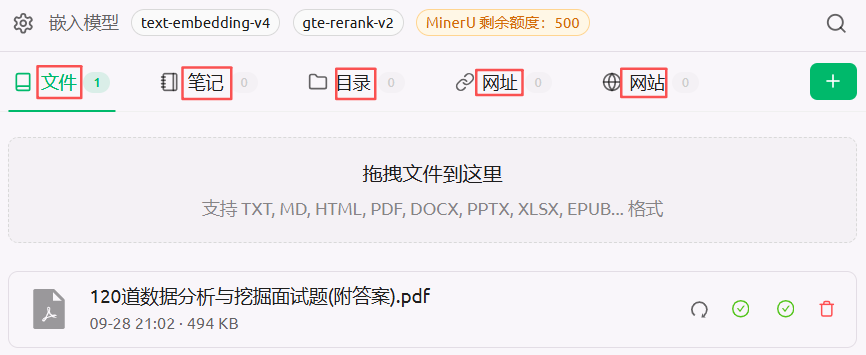
等待预处理、嵌入完成。
测试效果:
模型回答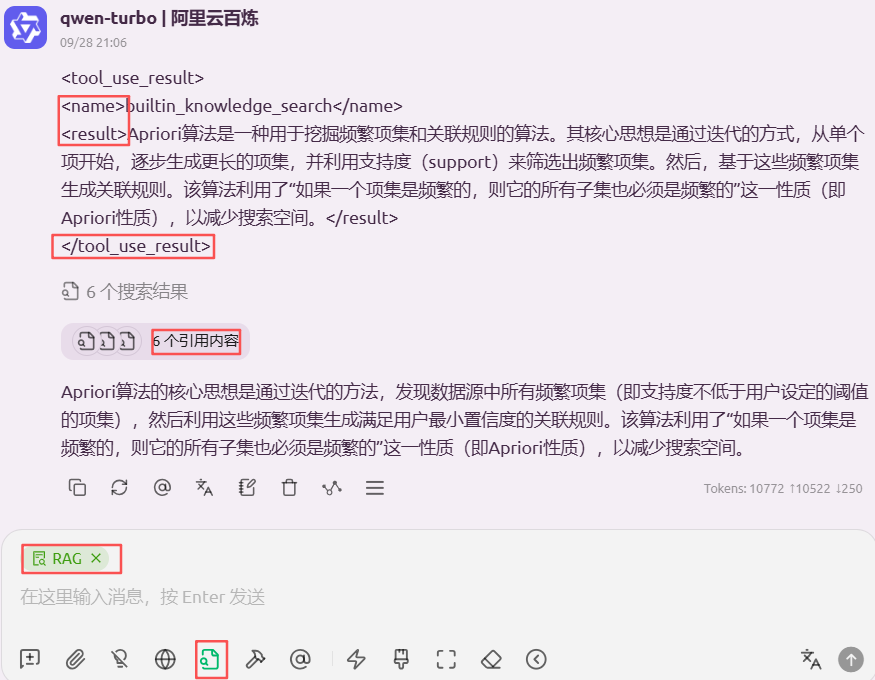
再看看原文
绘画
模型提供商
不同的模型供应商,通过的模型不同(废话),提供的能力差别很大: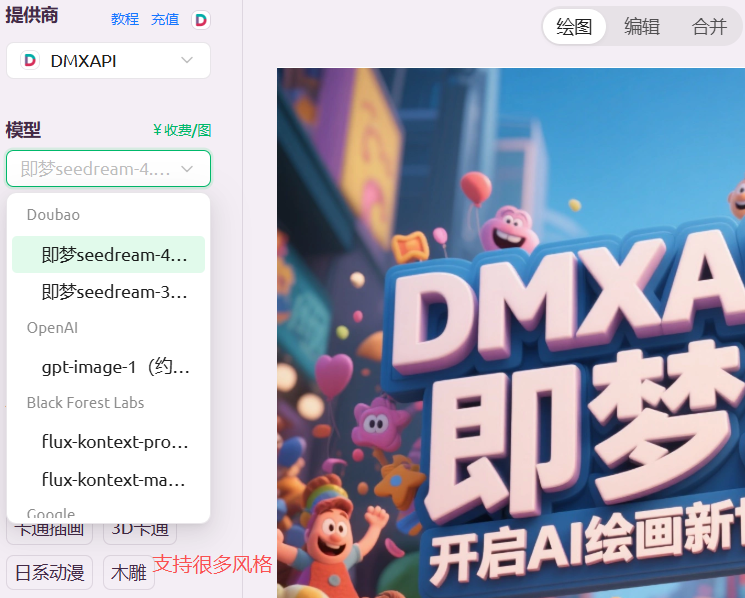
注意是付费的。
智能体
系统预置很多不同类别智能体:
包括:精选、职业、商业、工具、语言、办公、通用、写作、编程、情感、教育、创意、学术、设计、艺术、娱乐、生活、医疗、游戏、翻译、音乐、点评、文案、百科、健康、营销、科学、分析、法律、咨询、金融、旅游、管理。
支持从外部导入,有URL和JSON文件两种:
URL怎么还有JSON URL?
支持创建智能体,感觉没啥用,当然没有深入使用和调研过: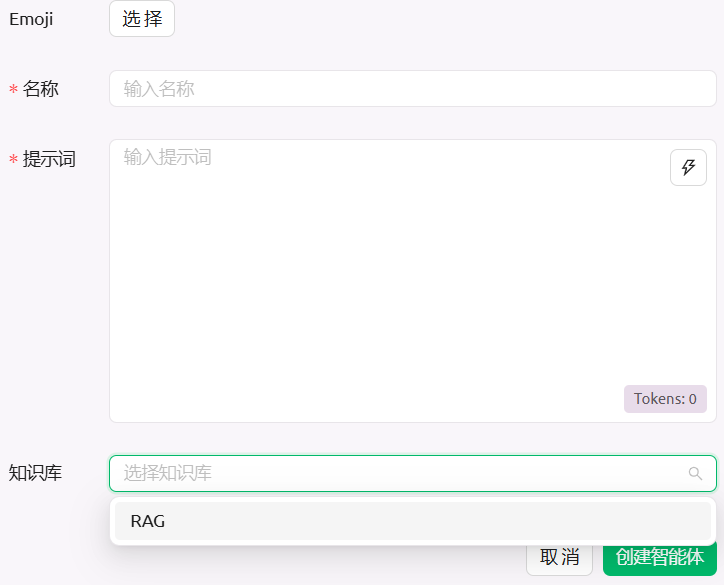
翻译
操作示意
设置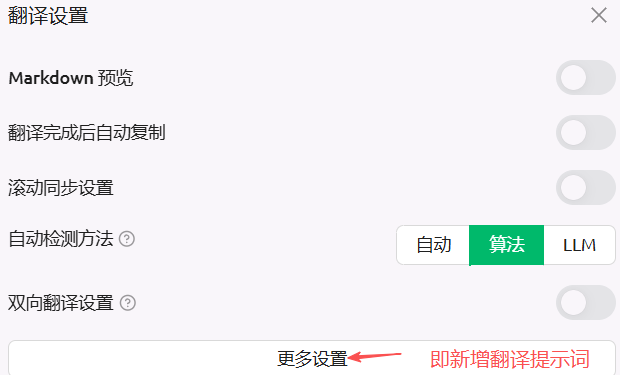
文件
知识库的文件管理,单独弄一个入口:
分为文档(PDF,Word等)、图片和文本(TXT,Markdown等)三种类型,支持单个文件编辑、删除,批量删除。
代码工具
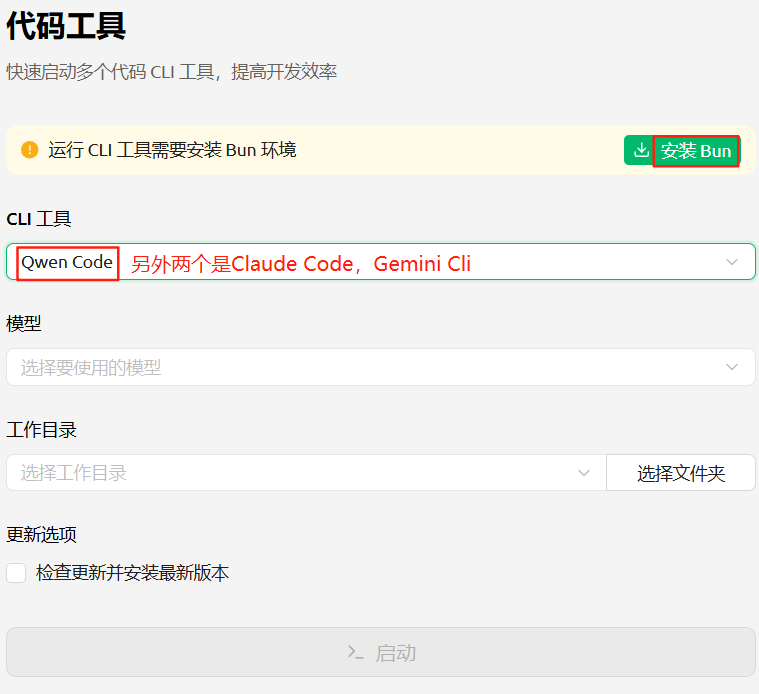
点击【安装Bun】,第一次可能失败,重试解决问题。
新版本会支持更多CLI工具:Qwen Code、Claude Code、Gemini CLI、OpenAI Codex、iFlow CLI。
选择CLI、模型,设置工作目录后,选择终端(支持Command Prompt、PowerShell、WSL),点击启动。遇到的问题,选择WSL时,会启动一个终端,一闪而过。换成PowerShell后,基于Bun自动安装qwen-code,和npm install qwen-code安装一样:
安装成功后: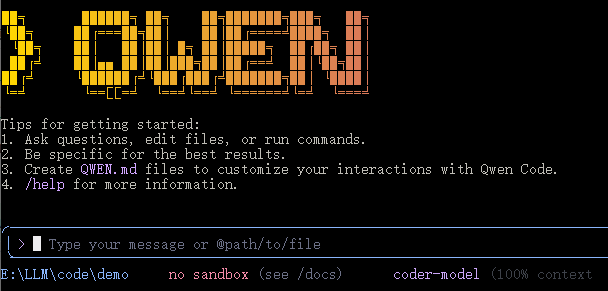
比如输入分析此目录: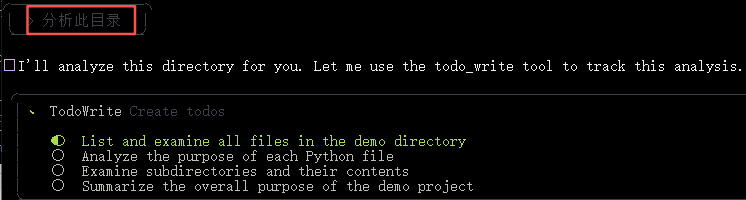
分4个步骤:
- 列举和分析当前目录(包括子目录)下所有文件
- 分析每个Python文件的作用
- 分析子目录及其内容
- 总结
给出的总结很到位,体验也很顺畅:
虽然但是!!这和我直接在终端执行命令,并没有任何区别啊;安装方式不同罢了,之前是通过npm安装,现在换成bun安装,多占用宝贵的C盘磁盘空间。
更多推荐

 12
12 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)