
RAG到ReRank:大模型检索技术的优化之路
本文探讨了RAG技术在企业应用中面临的效率和准确性问题,介绍了ReRank技术作为解决方案。ReRank采用多筛子策略,先快速检索出所有相关数据,再从中筛选出更精确的结果,应用分治思想提高检索效率。这种方法比传统遍历全部数据更高效,是对RAG技术的有效增强。
本文探讨了RAG技术在企业应用中面临的效率和准确性问题,介绍了ReRank技术作为解决方案。ReRank采用多筛子策略,先快速检索出所有相关数据,再从中筛选出更精确的结果,应用分治思想提高检索效率。这种方法比传统遍历全部数据更高效,是对RAG技术的有效增强。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
“面临日益增长的海量数据,怎么高效和准确的检索数据一直是一个值得思考的问题 ”
对大模型应用有所了解的人应该都知道RAG技术——检索增强,本公众号前前后后也写过好几次关于RAG的文章;但在实际的企业应用中,RAG还是面临着各种各样的问题,比如效率问题,准确度问题等等。
这些问题虽然在一些应用场景中并没有什么影响,但在某些场景中却是不可接受的;因此就有很多人想方设法的优化RAG技术,比如使用更加高效和准确的检索算法,更加合理的数据结构,优化提示词,关键词等。
但总的来说有些时候还是差强人意,而随着RAG技术的发展,ReRank技术被提了出来。ReRank技术可以说是对RAG技术的增强,虽然它还无法完全解决RAG存在的问题,但优中选优ReRank是比RAG更好的一种检索方式。
ReRank——重新排序
什么是ReRank技术?
ReRank 中文翻译过来就是重新排序技术,那么什么是重新排序技术,以及为什么需要重新排序技术?
在之前的检索系统中,通常是通过字符匹配的方式进行数据检索;虽然后来有了ES这种检索中间件,采用了分词以及相似度搜索的方式实现了更加高效的数据检索;但总体来说其效果也不是太好,特别是在语言分析方面。
虽然随着大模型技术的出现,基于语义的向量检索方式大行其道;但怎么从大量数据中高效与准确的检索出所需的数据,依然是一个亟待解决的问题。
同样,外部知识检索作为对大模型能力缺陷的补充,是目前企业应用中最常见的解决方案;但面临着日益复杂的应用环境,以及用户端的快速响应,RAG技术目前仍然饱受诟病,特别是RAG技术看起来入门很容易,但想深入确实很难。
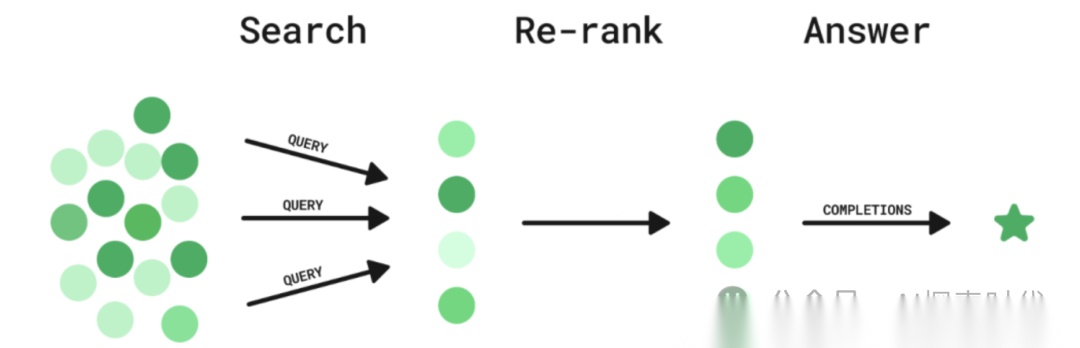
RAG技术所面临的问题是什么?
RAG技术所面临的两个主要问题就是检索的效率和准确性;为什么会出现这种问题?
不论是使用传统的检索方式,还是使用embedding向量检索的方式,面临大量数据RAG技术依然力不从心。
一旦数据达到一定规模或者用户对数据准确性要求较高,RAG技术就很难满足用户的需求。当然,这是从应用的角度得出的结论,那么从技术角度呢?
比如说,面临一个数十亿甚至上百亿数据量的知识库,基于RAG技术的检索方式是怎么实现的?
在检索方面刚开始使用的就是最传统的暴力搜索算法,什么是暴力搜索算法?
所谓的暴力搜索就是,遍历全部数据,然后通过字符匹配或相似度搜索以及向量搜索等方式查询出所需要的数据。

但有一点算法基础的人应该都知道,虽然八大排序算法在小规模数据中具有很大的优势;但在大量数据中八大排序完全没什么用。
原因是什么?
原因就是效率太低。
虽然后期通过优化,比如说通过数据治理的方式,把不同的数据根据某种规则进行分仓,或者构建索引加快检索速度;但等到索引大量增长的时候,依然会出现很多问题。
所以,现在更加高级的检索方式,ReRank就出现了。
ReRank的技术实现原理是什么?
ReRank技术就像一个筛子,通过多筛几次的方式检索到所需要的数据;第一遍通过快速检索等方式,从海量的数据中快速检索出所需要的数据;比如说全世界的知识作为一个数据库,这时你需要查询与孙悟空相关的数据。
这时ReRank技术就用最快的方式,从这个数据库中检索到所有与孙悟空有关的内容,不论是齐天大圣,还是孙猴子等等,甚至与其无关的其它三大名著的内容。
为什么要这样做?
这样做的原因就是,面对如此庞大的数据库,遍历所有数据显然是不可能的,即使技术上能实现,时间上也不允许。
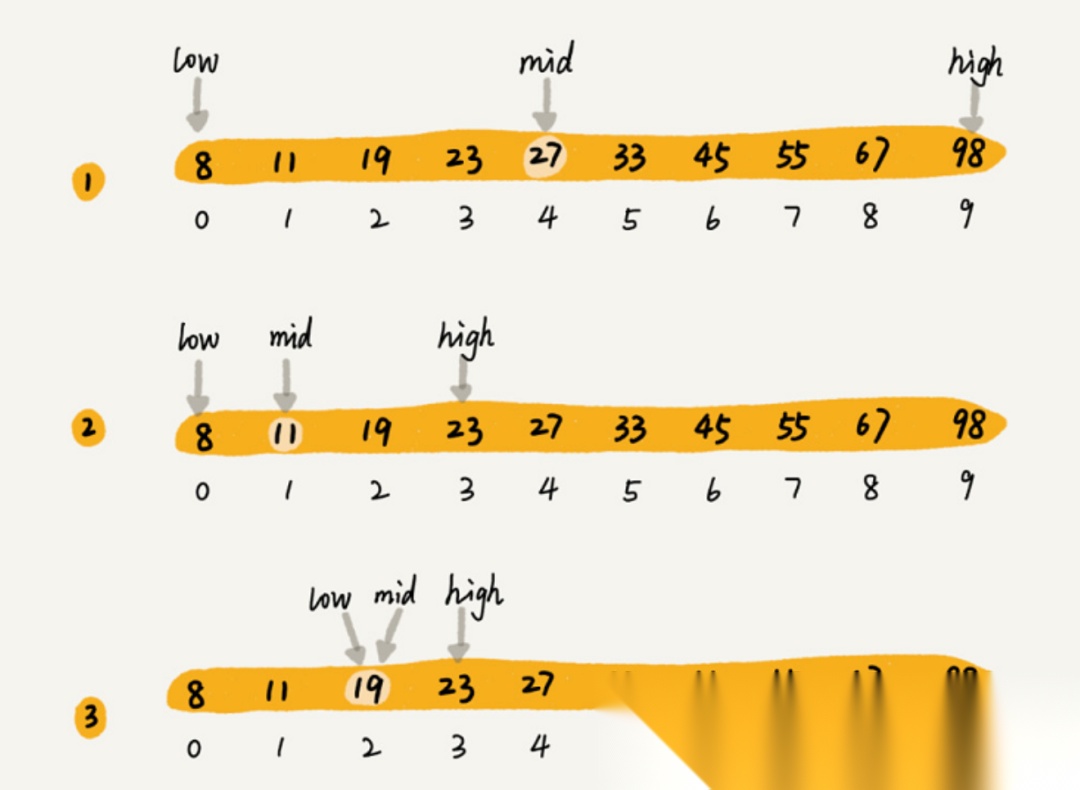
所以,第一遍就通过最快速的方式从中检索到与任何与孙悟空有关的数据;比如说检索到了一百万条数据。
然后再从这一百万条数据中再次检索,也就是再过一遍筛子;比如使用语义检索,从中匹配出相关度更高的数据。
最后通过多次筛选,通过精确匹配等方式,拿到最终的数据。
这样做有一个很明显的好处就是,虽然遍历一百万数据也很难;但至少比遍历全部数据要简单的多。
通过精确匹配等方式,拿到最终的数据。
这样做有一个很明显的好处就是,虽然遍历一百万数据也很难;但至少比遍历全部数据要简单的多。
这也是分治思想在数据检索中的一种应用;这就像我们选兵员一样;先把全国的青壮年选出来,然后再在里面优中选优,这样选出来的士兵素质肯定会更好,也会更快。
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
更多推荐
 21
21 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)