
Neo4j知识图谱+LangChain:构建精准可解释的企业级RAG系统
本文介绍如何整合Neo4j知识图谱与LangChain构建混合式RAG系统。相比传统向量检索,知识图谱能提供关系推理和可解释性优势。文章详细演示了从环境配置、数据导入到构建混合检索器的完整流程,通过结合图谱遍历与语义相似性匹配,实现精准可解释的检索增强生成。该系统适用于医疗、金融等需要复杂推理的领域,支持多跳查询和路径解释等高级功能,为生产级RAG应用提供新思路。文末还提供了大模型学习资源,帮助开
本文详细介绍如何结合Neo4j知识图谱与LangChain构建Retrieval-Augmented Generation系统。文章对比传统向量检索的局限性,展示知识图谱在关系推理和可解释性方面的优势,并提供完整实现步骤:环境配置、数据导入、Cypher查询编写和混合检索器构建。通过结合图谱遍历与语义相似性匹配,打造精准可解释、适合生产环境的RAG系统,适用于医疗、金融等多个领域。
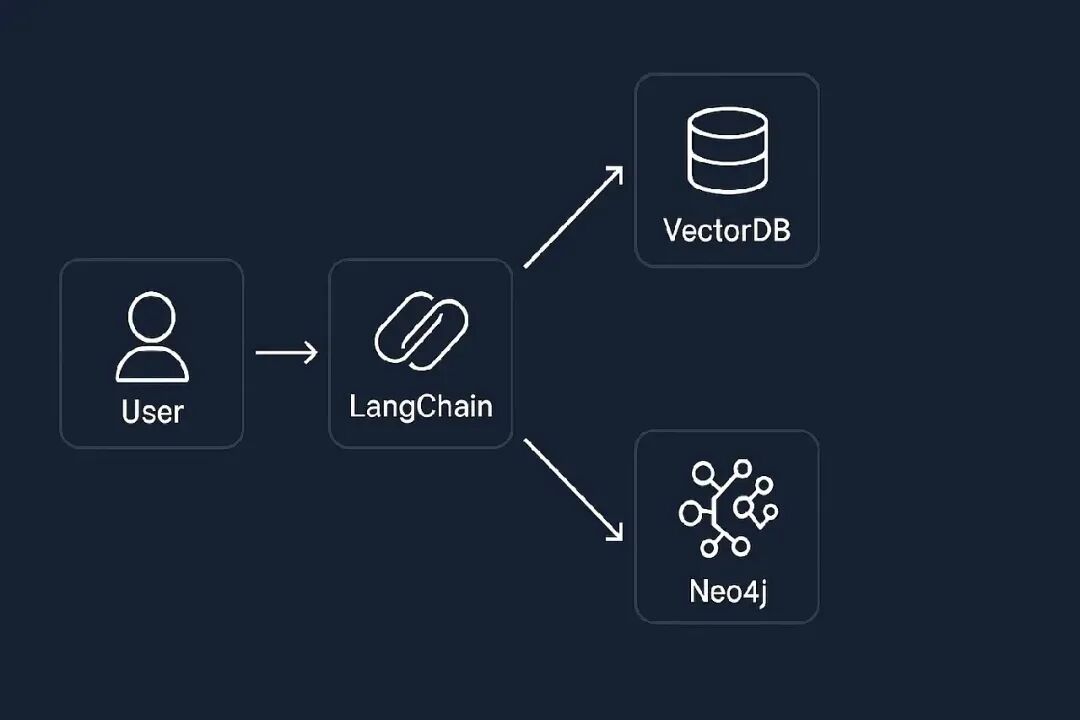
Retrieval-Augmented Generation (RAG) 已经迅速成为让 Large Language Models (LLMs) 在生产环境中真正发挥作用的首选架构。RAG 不再仅仅依赖 LLM 的内部记忆,而是将其与外部知识源连接起来。
虽然大多数教程展示的是使用 Pinecone、Weaviate 或 FAISS 等向量数据库的 RAG,但在现实世界的问题中,单靠语义相似度往往不够。你需要关系、推理和可解释性。这正是 Neo4j 驱动的知识图谱大放异彩的地方。
在这篇文章中,我们将使用 LangChain 构建一个 Neo4j 驱动的 RAG 管道,内容包括:
- • 为什么将知识图谱与 RAG 结合
- • 安装和配置 Neo4j + LangChain
- • 将数据导入 Neo4j(节点、关系、嵌入)
- • 编写 Cypher 查询 + 混合检索器
- • 使用 LangChain 的 graph chain 连接 Neo4j 和 LLM
- • 一个完整的实际示例
为什么在 RAG 中使用知识图谱?
传统的向量检索会找到与查询相似的文本片段。但在以下情况下它会失败:
- • 答案需要多跳推理(例如:“哪些供应商间接影响产品 X?”)
- • 关系是关键(药物 → 靶点 → 蛋白质 → 疾病)
- • 需要可解释性(用户想知道模型为什么这样回答)
Neo4j 允许你以图谱形式显式存储实体和关系,并使用 Cypher 进行查询。通过 LangChain,你可以结合:
- • 图谱遍历进行结构化查询
- • 嵌入进行语义相似性匹配
- • LLM 进行推理和自然语言回答
这就形成了混合检索管道:精准、可解释、适合生产环境。
设置
首先安装依赖:
pip install langchain langchain-community neo4j openai
你还需要一个运行中的 Neo4j 数据库(本地或 AuraDB Free)。
步骤 1:连接到 Neo4j
LangChain 提供内置的 Neo4j 图谱集成:
from langchain_community.graphs import Neo4jGraph
graph = Neo4jGraph(
url="bolt://localhost:7687",
username="neo4j",
password="password"
)
# 检查 schema
print(graph.schema)
这让 LangChain 能够理解你的知识图谱的实体和关系。
步骤 2:将数据导入 Neo4j
让我们插入一个小型医疗知识图谱:
CREATE (d1:Disease {name: "Diabetes"})
CREATE (d2:Disease {name: "Hypertension"})
CREATE (drug1:Drug {name: "Metformin"})
CREATE (drug2:Drug {name: "Insulin"})
CREATE (drug3:Drug {name: "Lisinopril"})
CREATE (drug1)-[:TREATS]->(d1)
CREATE (drug2)-[:TREATS]->(d1)
CREATE (drug3)-[:TREATS]->(d2)
现在我们可以直接查询类似 (:Drug)-[:TREATS]->(:Disease) 的关系。
步骤 3:使用 LangChain 的 Cypher Chain
LangChain 有一个 CypherChain,可以将自然语言问题转化为 Cypher 查询:
from langchain_openai import ChatOpenAI
from langchain.chains import GraphCypherQAChain
llm = ChatOpenAI(model="gpt-4.1")
cypher_chain = GraphCypherQAChain.from_llm(
llm=llm,
graph=graph,
verbose=True
)
response = cypher_chain.run("Which drugs treat Diabetes?")
print(response)
LLM 会将自然语言问题翻译成 Cypher 查询,在 Neo4j 上执行,然后返回人类可读的答案。
步骤 4:添加向量检索(混合 RAG)
如果用户问一些模糊的问题,比如“用来控制血糖的是什么?”单靠图谱可能不够。
这时候混合 RAG 就派上用场了:
- • 使用嵌入 + 向量数据库进行语义召回
- • 使用 Neo4j 进行关系推理
在 LangChain 中,你可以组合检索器:
from langchain.retrievers import EnsembleRetriever
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
# 示例 FAISS 检索器
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_texts(
["Metformin is first-line treatment for type 2 diabetes.",
"Insulin regulates blood glucose levels.",
"Lisinopril is used for hypertension."],
embeddings
)
faiss_retriever = vectorstore.as_retriever()
# 组合 Neo4j + FAISS 检索器
hybrid_retriever = EnsembleRetriever(
retrievers=[faiss_retriever, graph],
weights=[0.5, 0.5]
)
现在你的管道同时利用了语义和结构。
步骤 5:完整的 Neo4j RAG 链
以下是如何将它组装成完整的 LangChain RAG 流程:
from langchain.chains import RetrievalQA
rag_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=hybrid_retriever,
chain_type="stuff"
)
query = "What drugs are commonly prescribed for high blood sugar?"
answer = rag_chain.run(query)
print(answer)
检索器会从 Neo4j 和向量嵌入中拉取上下文,LLM 则生成自然语言答案。
高级扩展
- • 图谱 + LLM 代理:使用 LangChain Agents 结合工具(Neo4j 查询工具 + 向量检索工具)。
- • Schema 感知提示:将 Neo4j 的 schema 提供给 LLM,让它写出更好的 Cypher 查询。
- • 路径解释:返回答案旁边的实际图谱路径,以提高可解释性。
- • 图谱嵌入:使用 Neo4j Graph Data Science 计算实体/路径的嵌入。
使用场景
- • 医疗 RAG:检索有效的药物-疾病关系,防止幻觉。
- • 金融风险:建模机构之间的风险暴露,使用混合检索查询“间接风险”。
- • 法律搜索:将案例法引用表示为图谱,进行多跳先例推理。
- • 企业知识:基于本体论的聊天机器人,用于内部文档发现。
结论
仅依赖向量检索会限制系统处理复杂推理和多跳查询的能力。通过引入知识图谱,你不仅能获得更丰富的关联,还能提升可解释性和结构化推理能力。
使用 LangChain 的 Neo4jGraph 和 CypherQAChain,将 Neo4j 集成到 RAG 管道中变得无缝。此外,采用混合检索策略——结合嵌入和基于图谱的遍历——能提供语义灵活性和关系准确性之间的最佳平衡。
在实践中,LangChain 和 Neo4j 的结合使开发出既强大又可解释、值得信赖的生产级 RAG 系统成为可能。
读者福利大放送:如果你对大模型感兴趣,想更加深入的学习大模型**,那么这份精心整理的大模型学习资料,绝对能帮你少走弯路、快速入门**
如果你是零基础小白,别担心——大模型入门真的没那么难,你完全可以学得会!
👉 不用你懂任何算法和数学知识,公式推导、复杂原理这些都不用操心;
👉 也不挑电脑配置,普通家用电脑完全能 hold 住,不用额外花钱升级设备;
👉 更不用你提前学 Python 之类的编程语言,零基础照样能上手。
你要做的特别简单:跟着我的讲解走,照着教程里的步骤一步步操作就行。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
现在这份资料免费分享给大家,有需要的小伙伴,直接VX扫描下方二维码就能领取啦😝↓↓↓
为什么要学习大模型?
数据显示,2023 年我国大模型相关人才缺口已突破百万,这一数字直接暴露了人才培养体系的严重滞后与供给不足。而随着人工智能技术的飞速迭代,产业对专业人才的需求将呈爆发式增长,据预测,到 2025 年这一缺口将急剧扩大至 400 万!!
大模型学习路线汇总
整体的学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战,跟着学习路线一步步打卡,小白也能轻松学会!
大模型实战项目&配套源码
光学理论可不够,这套学习资料还包含了丰富的实战案例,让你在实战中检验成果巩固所学知识
大模型学习必看书籍PDF
我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
大模型超全面试题汇总
在面试过程中可能遇到的问题,我都给大家汇总好了,能让你们在面试中游刃有余
这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
👉获取方式:
😝有需要的小伙伴,可以保存图片到VX扫描下方二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最适合零基础的!!
更多推荐

 8
8 0
0- 0



 已为社区贡献58条内容
已为社区贡献58条内容

所有评论(0)