
一篇详解大模型:强化学习与有监督学习的区别
有监督学习:像按旅行指南走,一切明确,但缺乏灵活性。强化学习:像自由探索陌生城市,虽然起初困难,但能学到更灵活、更长远的策略。少设计规则,多给模型自由,它自己会找到更优解。
大语言模型在经过 有监督微调 后,已经能大致听懂人类指令,并完成各种任务。不过,这种方法也有明显的短板:
-
首先,需要大量的“指令—答案”数据对,而高质量的答案往往要靠人工标注,成本非常高。
-
其次,训练时常用的 交叉熵损失函数 要求模型输出必须和标准答案一字不差。但自然语言本来就有多种表达方式,这种“逐字匹配”的约束不仅限制了模型的灵活性,还让模型对输入的细微变化过于敏感。在一些需要复杂推理的任务中,这个问题尤其明显。
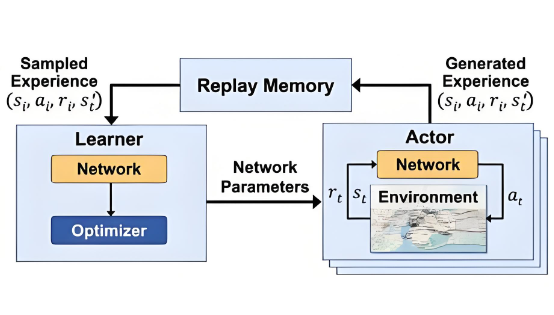
为了解决这些问题,研究者们开始在大模型里引入 强化学习,主要走了两条路:
-
基于人类反馈的强化学习(RLHF)
这里会先训练一个 奖励模型,用来判断模型输出的整体质量。这样,模型不再是死记硬背标准答案,而是学会根据人类偏好不断调整自己的策略。比如 ChatGPT 就是用这种方法,通过人类反馈和一种叫 PPO(近端策略优化) 的算法来优化,让回答更符合人类的价值观和表达习惯。 -
面向深度推理的强化学习
这类方法更像是让模型学会“逐步思考”。比如 OpenAI 的 O 系列模型、DeepSeek 的 R 系列模型,就会通过“答案校验”来引导模型进行多步推理,把复杂问题分解成一条长长的 思维链(Chain-of-Thought)。这种方式在数学证明、代码生成等需要逻辑缜密的场景里效果特别好。
相比传统的监督学习,强化学习的优势非常明显:
-
在 RLHF 的范式下,模型能通过“生成—反馈”的闭环不断进化,不再依赖唯一的标准答案。
-
在 深度推理 的场景中,模型能主动探索推理路径,用价值函数评估来避免陷入局部最优,从而找到更好的解法。
简单来说,RLHF 更强调“对齐人类价值”,而 深度推理强化学习更注重“解决复杂问题”。两者结合,正在成为推动大语言模型进化的核心动力。
1 什么是强化学习
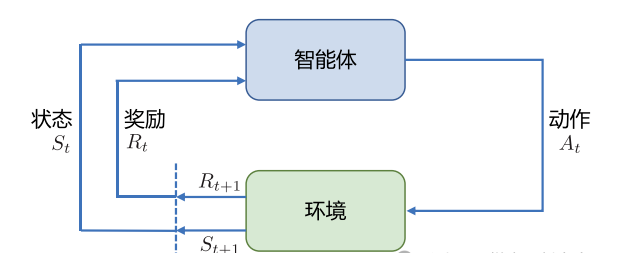
简单来说,强化学习(Reinforcement Learning,RL) 研究的就是“一个智能体在环境中如何不断尝试,最后学会做出最佳决策”的过程。目标就是:让智能体在复杂又不确定的环境中,尽可能多地获取奖励。
强化学习的框架可以理解成由两部分组成:
-
智能体(Agent):相当于学习者或决策者。
-
环境(Environment):智能体所处的世界,包含规则和反馈。
在学习过程中,智能体不断和环境互动:它先观察到一个状态(State),再基于这个状态选择一个动作(Action)。动作会影响环境,环境则会返回一个新的状态,并给予奖励(Reward)。智能体的目标就是学会一套策略(Policy),用来指导自己在不同状态下采取什么行动,才能获得更多奖励。
举个生活化的例子:你教一只宠物狗玩飞盘。
-
智能体:宠物狗就是“智能体”。
-
环境:飞盘的飞行轨迹、速度,以及周围的情况。
-
状态:飞盘此刻的位置和速度。
-
动作:狗可以选择跑、跳,或者干脆站着不动。
-
奖励:如果狗成功接住飞盘,就给它奖励(比如小零食);没接住,就没有奖励。
随着不断尝试,狗会逐渐学会一套“策略”:在不同状态下采取什么样的动作,能更大概率接住飞盘。与此同时,它还会对不同动作的“价值”形成预估,比如它知道在某些角度和速度下提前起跳更容易成功。
2 强化学习的几个概念
在强化学习中,智能体(Agent)和环境(Environment)之间会不断进行互动。
-
智能体会根据它看到的情况(观测 o)做出一个动作(a),然后环境会给它一个反馈(奖励 r)。
-
这样,随着时间推移,就会形成一条历史记录 Ht:
Ht = o1, a1, r1, o2, a2, r2, …, ot, at, rt-
这可以看作智能体的“学习日志”。
完全可观测 vs. 部分可观测
-
如果智能体能看到环境的 全部状态 St,就叫 完全可观测(Fully Observed)。
-
如果只能看到一部分信息(比如迷宫里只能看到周围一小块区域),就叫 部分可观测(Partially Observed)。
动作空间(Action Space)
动作空间就是智能体在某个环境中 可选择的动作集合。
-
离散动作空间:动作数量有限。比如下围棋,落子只能选择棋盘上的 361 个交叉点。
-
连续动作空间:动作是连续的。比如机器人在平面上走路,它可以朝任意角度移动,而不是只能选几个方向。
策略(Policy)
策略是智能体的“行动计划”,决定它在某种状态下该做什么动作。
-
随机性策略(Stochastic Policy):给每个可能动作分配一个概率。比如:
-
在状态 s 下,往左走的概率 0.3,往右走的概率 0.7。
-
智能体会根据这个概率随机选择。
-
-
确定性策略(Deterministic Policy):直接选择“最优动作”。
-
比如:在状态 s 下,智能体 100% 往右走。
-
价值函数(Value Function)
价值函数用来预测未来的奖励:
-
状态价值函数 Vπ(s):如果我现在在状态 s,并遵循策略 π,一般能获得多少未来奖励?
-
动作价值函数 Qπ(s, a):如果我在状态 s 选择动作 a,然后继续按照策略 π,会获得多少未来奖励?
这里会用到一个 折扣因子 γ(0~1 之间),它用来平衡 眼前奖励和长远奖励:
-
γ 越小,智能体更看重“眼前的好处”。
-
γ 越大,智能体更注重“长远收益”。
三类智能体
根据学习方式不同,强化学习里的智能体可以分为三类:
-
基于价值的智能体(Value-based Agent)
-
专注于学习价值函数(V 或 Q),间接地推导出策略。
-
代表算法:Q-Learning。
-
-
基于策略的智能体(Policy-based Agent)
-
直接学习策略函数 πθ(a|s),输入状态 → 输出动作概率。
-
不单独学习价值函数。
-
代表算法:REINFORCE。
-
-
演员–评论员智能体(Actor-Critic Agent)
-
演员(Actor):负责学习策略。
-
评论员(Critic):负责学习价值函数,评价动作好坏。
-
结合前两种方法:
-
两者配合,学习更高效。
-
代表算法:PPO(近端策略优化)。
-
3 强化学习与有监督学习的区别
在深度学习里,有监督学习和强化学习就像是两种不同的旅行方式。它们的目标都是“学会在环境中行动”,但走的路完全不一样。
旅行前的准备:数据来源
-
有监督学习:像是出门旅游前拿到一本详细的旅行指南,书里写清楚了所有景点、路线、餐厅,甚至还有评价。这就像模型训练时,有明确的输入和标准答案。
-
强化学习:则像走进一座陌生的城市,没有地图,也没人告诉你怎么走。你只知道目标,比如要找到一家好餐厅。要不要拐弯、去哪条街,都得靠自己摸索。
旅行中的指引:反馈机制
-
有监督学习:就像旅途中随时有人告诉你“下一步该怎么走”,每一步都有参考答案。
-
强化学习:没人告诉你怎么走,只会在你做完事后给反馈。比如走进一家餐厅,吃完才知道好不好吃。于是你要靠多次尝试,总结经验,逐渐摸索出最佳路线。
旅行的终点:学习目标
-
有监督学习:目标明确,就是按照指南把所有景点都走一遍。
-
强化学习:目标更开放,是学会在城市里自由探索,找到最优策略,无论是吃饭、住宿还是娱乐,都能做出好决策。
总结
-
有监督学习:像按旅行指南走,一切明确,但缺乏灵活性。
-
强化学习:像自由探索陌生城市,虽然起初困难,但能学到更灵活、更长远的策略。
这正印证了《苦涩的教训》里的观点:少设计规则,多给模型自由,它自己会找到更优解。
更多推荐

 11
11 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)