
深夜惊喜:Qwen3-Omni和Qwen3-TTS双发布,劳模的辛勤成果
Qwen系列模型迎来重大更新,发布TTS和Omni两大重磅产品。Qwen3-TTS-Flash支持17种音色和10种语言(含8种中国方言),在多语言基准测试中表现优异,首包延迟低至97ms。Qwen3-Omni作为首个开源全模态大模型,采用Thinker-Talker架构,支持19种语音输入和10种语音输出,在36项测试中32项领先,端到端音频对话延迟仅211ms。此次更新还包含开源通用音频Cap
又是熟悉的深夜,又是熟悉的差点入睡。。
Qwen 又又又又又更新了!开源权重、技术细节披露、完美博客,一样不差。
Rocky 又给你们当劳模来更新了!
此轮发布包括 TTS 和 Omni 模型,ASR 模型则在更早(本月8号时发布)
双双登顶 SoTA,就让我们一起看看看看它们特色和细节吧!
Qwen3-TTS-Flash:多语言、低延迟
01
又是一 SoTA!通义牛波一!
那就先来个 SoTA 级的 TTS 暖波场吧~
(TTS:文本转语音,即将文字内容转化为自然流畅、听起来像真人说话一样的声音或音频。)
此次发布的 TTS 支持 17 种音色选择,每一种音色均支持 10 种语言。
其中不仅包含多国语言,有:普通话、英语、法语、德语、俄语、意大利语、西班牙语、葡萄牙语、日语、韩语;
还支持了更多中国方言:闽南语、吴语、粤语、四川话、北京话、南京话、天津话和陕西话。
这对任何一款依赖于特殊语种的 TTS 服务都是福音!
此外,Qwen3-TTS-Flash 在多项评估基准上均取得了 SoTA 的表现,超越 SeedTTS、MiniMax、GPT-4o-Audio-Preview、Elevenlabs,特别是在语音稳定性和音色相似度。
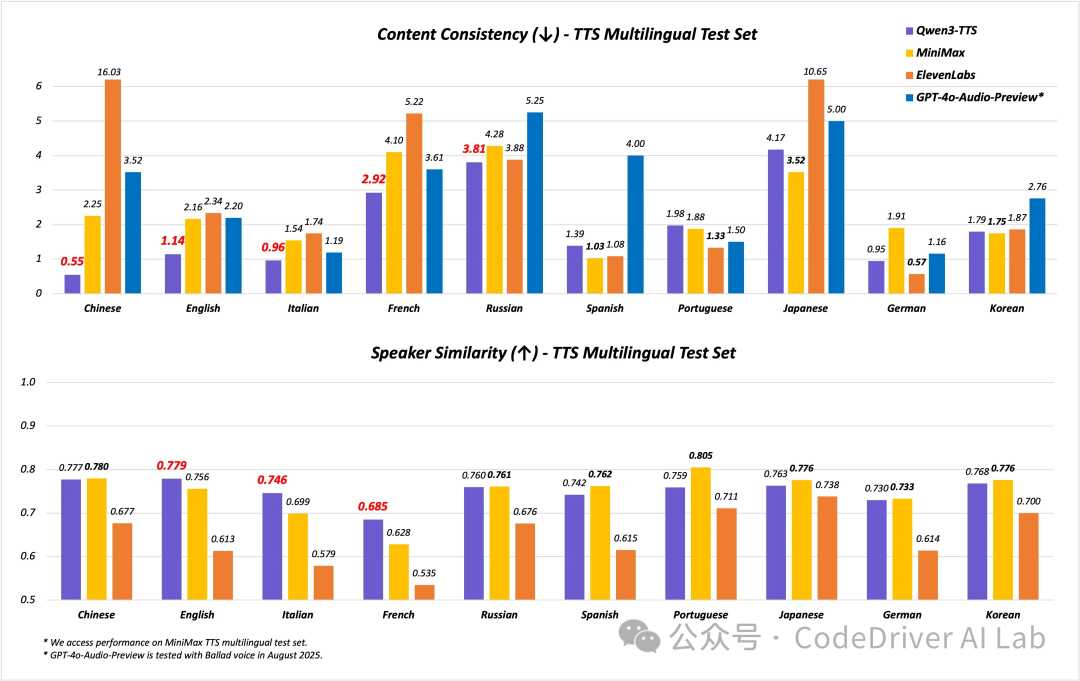
多语言基准测试集,上表越低越好,下表越高越好。
在响应延迟上,Qwen3-TTS-Flash 单并发首包模型延迟低至 97 ms。
在 Qwen Blog 上,将此次发布的 TTS 与第一代 Qwen-TTS 进行了对比:

满并发且越大越好???
总结亮点:
-
卓越的中英稳定性:在 seed-tts-eval 测试集上,超过多款主流模型,取得 SoTA;
-
出色的多语言性能:多语言稳定性和音色相似度 经过 MiniMax TTES multilingual 测试,均在多项维度取得 SoTA;
-
高表现力:具备高表现力的拟人音色,能够稳定、可靠地输出高度遵循输入文本的音频;
-
丰富的音色和语种:提供 17 种音色选择,每一种音色均支持 10 种语言;
-
多方言支持:包括普通话、闽南语、吴语、粤语、四川话、北京话、南京话、天津话和陕西话;
-
语气适应:经过海量数据训练,Qwen3-TTS-Flash 能够根据输入文本自动调节语气;
-
高鲁棒性:能够自动处理复杂文本,抽取关键信息,对复杂和多样化的文本格式具有很强的鲁棒性;
-
快速生成:具有极低的首包延迟,单并发首包模型延迟低至 97 ms。
只是该模型目前还没有开源,只支持 API 的方式调用。不过官方提供了 HF-Demo 和 MS-Demo 抢鲜体验,直达火箭:
-
DashScope(API):
-
[https://help.aliyun.com/zh/model-studio/qwen-tts]
-
-
HuggingFace(Demo):
-
[https://huggingface.co/spaces/Qwen/Qwen3-TTS-Demo]
-
-
ModelScope(Demo):
-
[https://modelscope.cn/studios/Qwen/Qwen3-TTS-Demo]
-
(小声bb,什么时候支持东南亚小语种 …
Qwen3-Omni:三个版本王炸发布、社区首个
02
Qwen3-Omni 可谓此轮发布的重磅炸弹(“王炸”
现许多应用都在陆续转向新的交互模式:实时音频交互。
而近半年的模型发布以来,一直不见 Omni 的影子。大家都在卷推理,这对许多企业来说无比痛苦,最强的模型能力得通过级联方式接入 TTS 与 ASR 模型才能够对用户提供,这会导致一定的响应延迟增加。而无法忍受该延迟的,只能默默使用更早的 Omni 模型。
而此次,Qwen3-Omni 的发布无疑解了大多数企业的心结!

不变味!此次发布的模型(Qwen3-Omni)依旧原生的、端到端的,全模态大模型!
一轮发布了三个版本:
首先最为重磅的是 Captioner 模型,首个开源发布的全模态描述模型;
(类似于我们做 VL,会先增强模型在图像描述上的能力)
其次是发布的标准版的 Instruct 版本,快速响应、强大性能;
最后,此次还发布了 Thinking 版本,保证最快响应的同时,获得更好的推理结果!
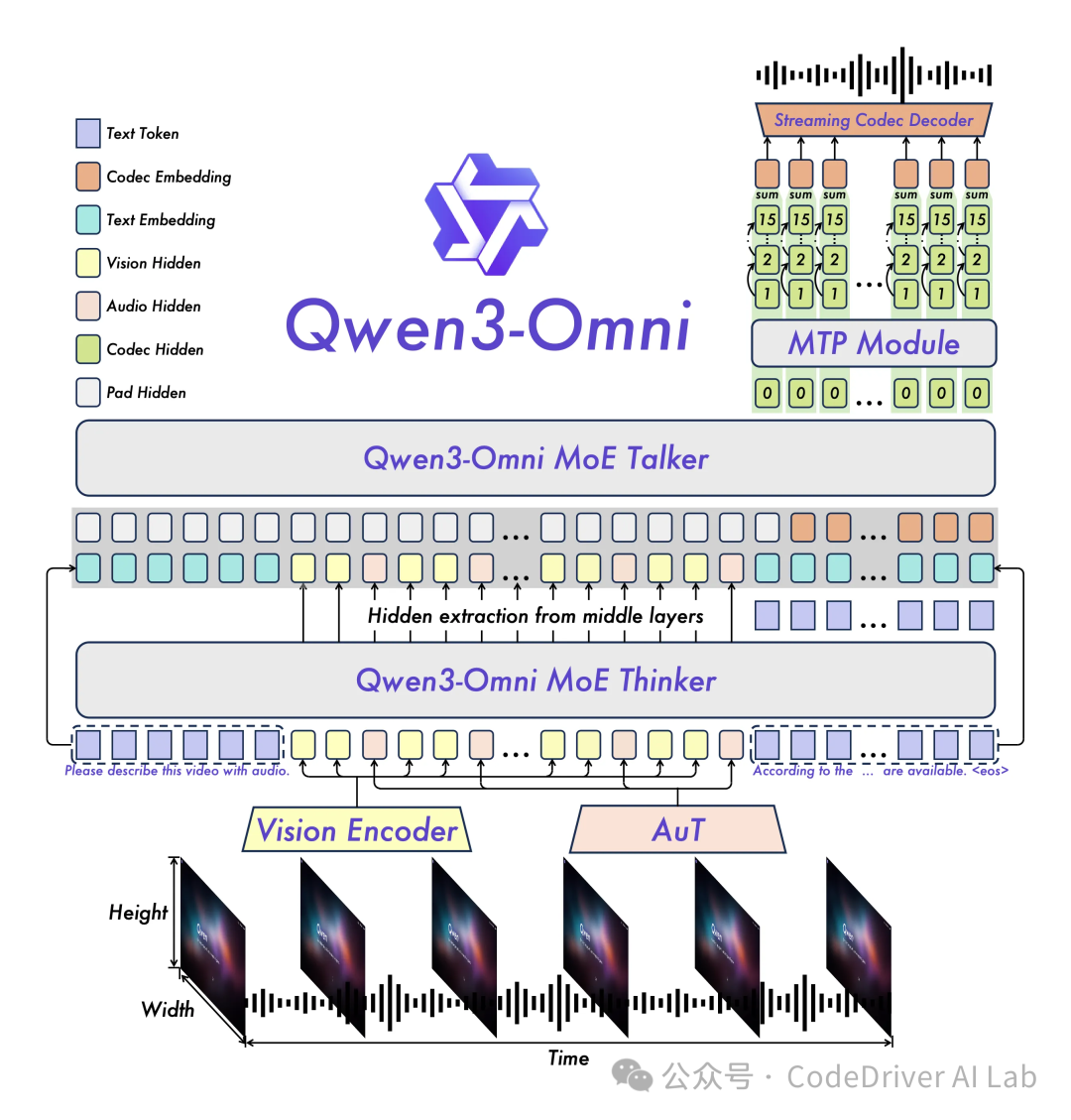
在模型架构上,还是熟悉的 Thinker-Talker 架构(参考 Qwen2.5-Omni)
Thinker 负责文本生成,Talker 直接接收来自 Thinker 的高层语义表征,专注于流式语音 Token 生成。
为了实现超低延迟流式生成,Talker 通过自回归的方式预测多码本序列:即在每一步解码中,MTP 模块输出当前帧的残差码本,随后 Code2Wav 合成对应波形,实现逐帧流式生成。
其中,音频编码器基于 2000 万个小时的音频数据训练而得 AuT 模型,具备极强的通用音频表征能力;
而基于模型发布名称我们也得知,Thinker 和 Talker 均采用 MoE 架构,支持 Qwen3 原有的高并发与快速推理!
更重要的是,通过文本预训练阶段早期混合单模态与跨模态数据,可实现各模态混训性能不下降!同时显著增强跨模态能力。
熟悉多模态模型训练过程的都知道,在对齐阶段,模型能力不下降一直是一件不容易的事情,尤其在 Omni 这种全模态模型上。
模型架构图:
再来说说我们最喜欢看的性能碾压式领先:
Qwen3-Omni 在全方位性能评估中,不但各模态任务表现与类似大小的 Qwen 系列文本模态模型持平,尤其在音频任务中展现显著优势。
该模型在 36 项音视频基准测试中,32 项取得开源领先,22项 达到 SoTA 水平!
性能一众超越了 Gemini-2.5-Pro、Seed-ASR、GPT-4o-Transcribe 等性能强大的闭源模型,
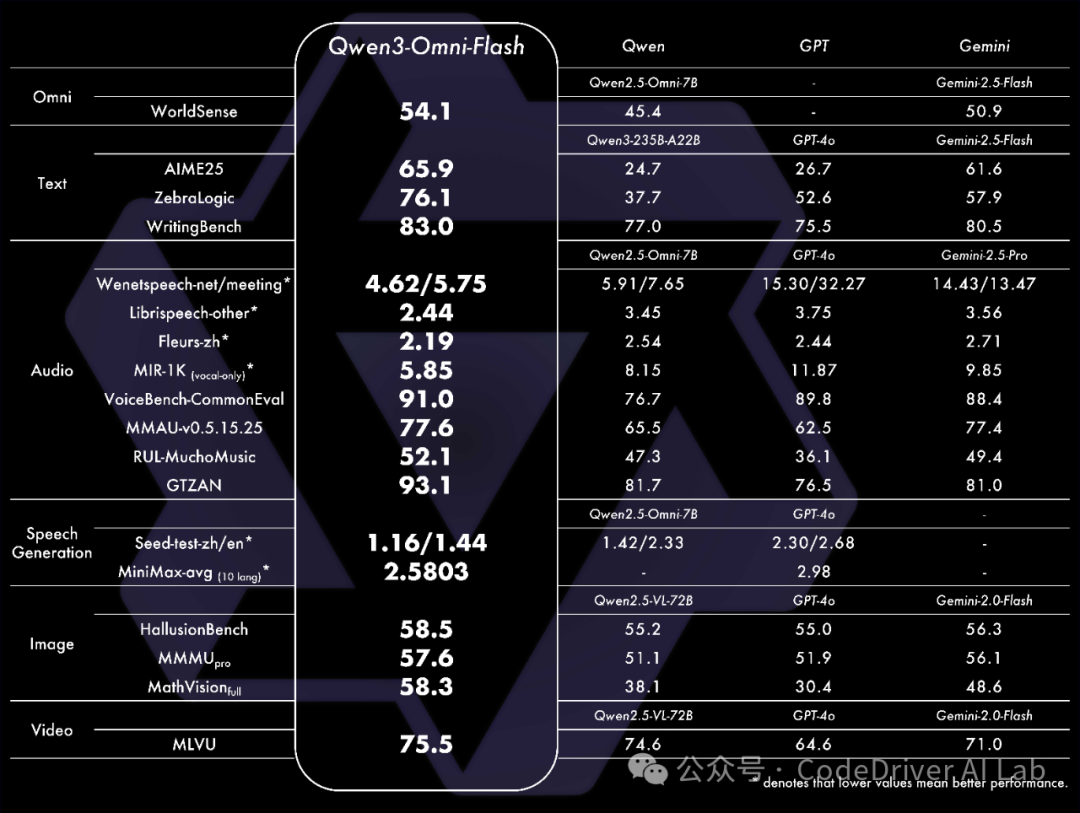
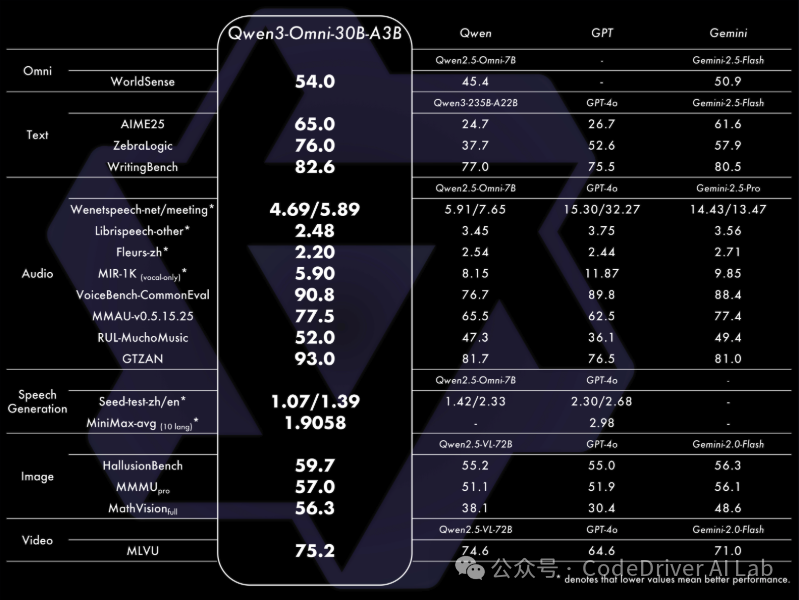
(Qwen3-Omni-Flash 为官方 API 版本,暂不开源,仅支持 API 调用)
除此之外,基于先前发布的 ASR 模型和今天一同发布的 TTS 模型,Qwen3-Omni 同样对多语言支持可怕的吓人!
-
在语音输入方面,支持 19 种语言,包括:英语、中文、韩语、日语、德语、俄语、意大利语、法语、西班牙语、葡萄牙语、马来语、荷兰语、印尼语、土耳其语、越南语、粤语、阿拉伯语、乌尔都语。
-
在语音输出方面,支持 10 种语言,包括:英语、中文、法语、德语、俄语、意大利语、西班牙语、葡萄牙语、日语、韩语。
最后,长音频、工具调用,我都很想拿出来讲讲。但是大晚上的词汇有限,一句WC走天下……
更多请看以下总结!
总结亮点:
-
原生全模态:原生全模态大模型,预训练全模态不降智。
-
强大的性能:在36项音频及音视频基准测试中斩获32项开源SOTA与22项总体SOTA,超越Gemini-2.5-Pro等闭源强模型,同时其图像和文本性能也在同尺寸模型中达到SOTA水平。
-
多语言:支持119种文本语言交互、19种语音理解语言与10种语音生成语言。
-
更快响应:模型端到端音频对话延迟低至211ms,视频对话延迟低至507ms。
-
长音频:Qwen3-Omni支持长达30分钟音频理解。
-
个性化:支持system prompt随意定制,可以修改回复风格,人设等。
-
工具调用:支持function call,实现与外部工具/服务的高效集成。
-
开源通用音频Captioner:开源Qwen3-Omni-30B-A3B-Captioner,低幻觉且非常详细的通用音频caption模型,填补开源社区空白。
如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份《LLM项目+学习笔记+电子书籍+学习视频》已经整理好,还有完整版的大模型 AI 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇


第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

更多推荐

 23
23 0
0- 0



 已为社区贡献156条内容
已为社区贡献156条内容

所有评论(0)