
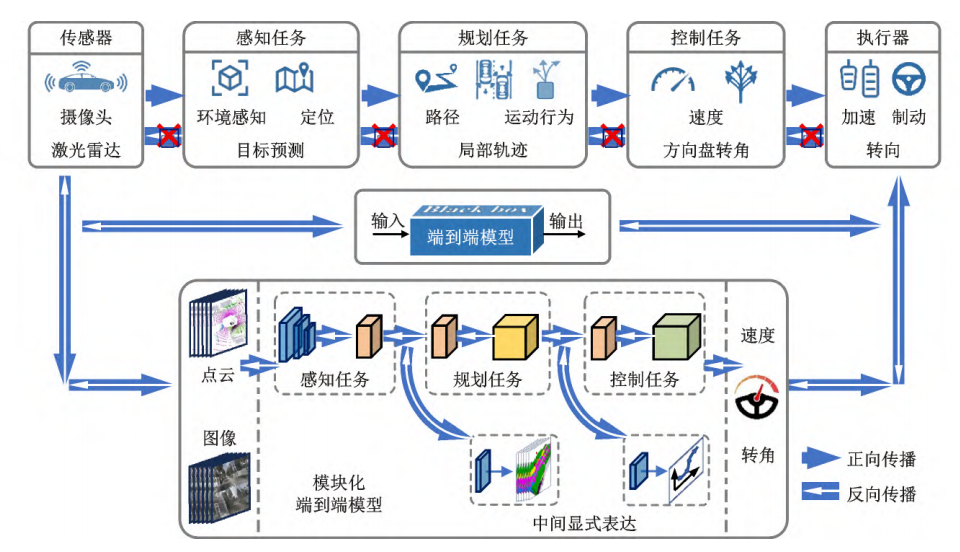
端到端自动驾驶方法介绍
随着人工智能快速发展,端到端自动驾驶方法备受关注。该方法无需人工预先定义规则与模块间显式接口,将感知、决策、控制等模块作为整体学习任务优化,直接由车载传感器信号映射出车辆控制命令。但以模仿学习、强化学习为代表的端到端方法,“黑盒式”架构使其可解释性弱、安全性难保障;且模型输出错误时,无法像模块化方法那样溯源,难以针对性优化。因此,将模块化方法的强解释性与深度学习结合,构建模块化端到端学习框架,成为
端到端自动驾驶技术通过模拟人类驾驶的反射式决策机制,利用神经网络实现传感器数据到控制指令的端到端映射。该方法虽能完成复杂驾驶任务,但存在模型可解释性不足的缺陷。为此,研究者提出模块化端到端架构,在保持整体优化性能的同时,通过中间显式表达增强系统透明度。
技术发展可追溯至1988年卡内基梅隆大学的ALVINN系统,其采用三层全连接神经网络,首次实现基于摄像头和激光数据的端到端转向控制。早期研究主要采用CNN-RNN混合架构:CNN负责图像特征提取,RNN处理时序信息。2005年Yann等人开发的六层卷积网络,通过双摄像头低分辨率图像输入实现避障控制,而英伟达团队则验证了CNN在多种场景下的转向控制能力。
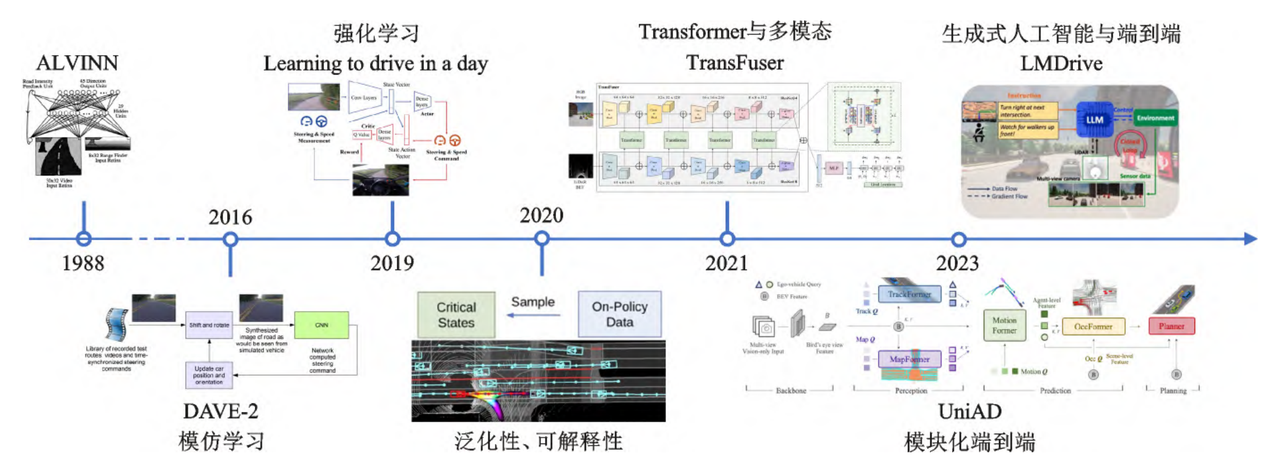
传统方法主要依赖强化学习和模仿学习,但通过辅助输出和注意力可视化技术弥补了黑盒缺陷。近年来,Transformer架构与生成式AI的结合成为突破长尾难题的关键,基础模型的预训练能力显著提升了环境理解和行为预测精度。上图展示了该领域的重要技术里程碑
一、模型输入与输出模态
端到端自动驾驶模型的输入通常包括视觉图像、激光点云、导航指令及车辆状态信息,输出则直接生成控制信号(如转向角、加速度)或轨迹点。
(1)输入模态

视觉图像:通过卷积神经网络降维编码为特征向量,常采用预训练检测网络作为编码器。
激光点云:需处理稀疏点云数据以提取三维特征,结合摄像头实现多模态融合(前/中/后融合)。
附加输入:车辆运动状态(速度、加速度)和全局路径可提升决策精度,而大语言模型虽能提供经验知识,但存在幻觉风险,且复杂环境下的安全性验证更具挑战性。
(2)输出模态
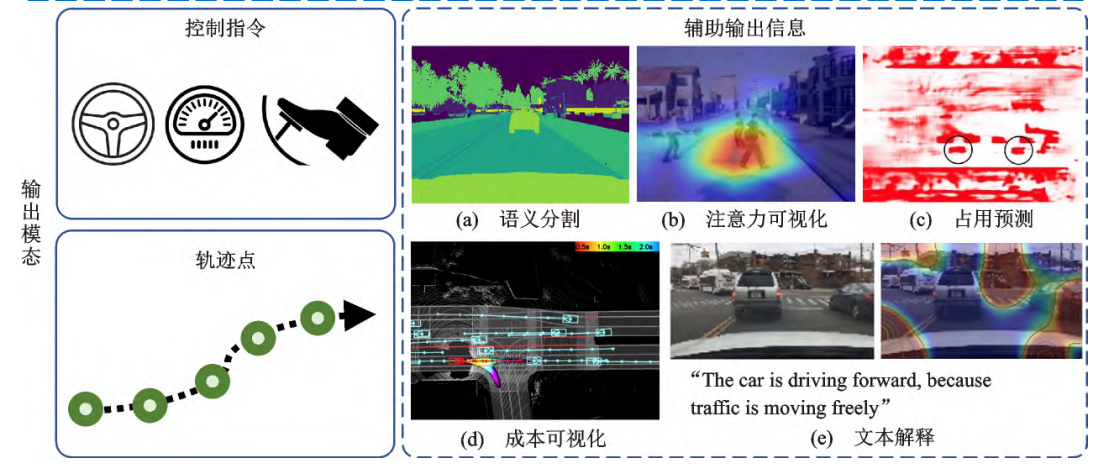
控制指令:主流方案输出转向角与加速度,部分研究通过增加转向角加速度参数提升驾驶平顺性。
轨迹规划:输出轨迹点更易分析,且不受车辆几何限制,可通过后续模块转换为控制指令。
辅助输出:注意力可视化、语义分割、占位预测等中间结果可增强模型可解释性,辅助故障排查。
二、模仿学习方法
模仿学习(Imitation Learning, IL)通过专家示范数据学习决策策略,其核心是构建状态-动作映射关系。
(1)行为克隆(BC)
基础原理:将专家数据中的状态作为输入,动作为标签,通过监督学习拟合策略π*,最小化与专家动作的差异:
π* = argmin L(πE(s), π(s))
典型应用:ALVINN模型利用3层全连接网络实现自动驾驶控制。
改进方向:
条件模仿学习(CIL)引入专家意图作为辅助输入(如Hawke等人的城市驾驶研究);
多模态输入可提升性能,但可能引发因果混淆问题。
(2)直接策略学习(DPL)
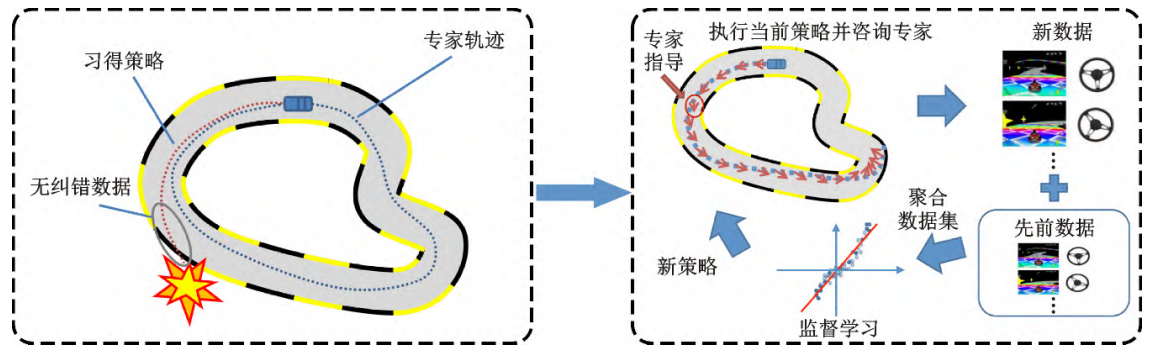
DAgger算法:通过执行初始策略生成新状态序列,由专家标注动作以修正错误,逐步聚合数据优化策略。
改进算法:SafeDAgger、HGDAGGER等减少专家问询次数,提升训练效率。
(3)逆强化学习(IRL)
通过专家数据逆向推断奖励函数,间接优化策略。
总结:模仿学习通过复制专家行为实现决策,但面临泛化能力不足与误差累积等挑战,需结合交互式学习与因果分析进一步优化。
三、模块化端到端方法
模块化端到端方法,采用数据驱动的端到端框架,对感知、决策等中间结果进行显式设计,同时确保整体可微。这一特性,使其既能借助反向传播实现整体优化,又增强了模型的可解释性 。
ST-P3、DiffStack作为该领域的早期探索成果,在端到端一体化训练模式下,联合优化感知、预测、规划等模块。这种保留模块化架构的端到端范式,通过增设辅助模块,实现了中间态信息的可视化,提升了端到端模型的可解释性与安全性。其中,ST-P3提出了首个纯视觉端到端自动驾驶的显式设计结构,利用解码器获取多种场景语义信息,极大地增强了端到端模型的可解释性。该类方法保留经典模块化架构的同时,去除了人为定义的上下游模块接口,保障了模型整体的可微性 。
Transformer与鸟瞰图(BEV)的结合,逐渐成为自动驾驶领域的重要共识。当前主流的模块化端到端范式,在联合感知预测框架基础上,融合更多下游任务,实现了以规划为导向的模块化联合端到端 。BEV感知通过将各类传感器数据映射到BEV空间,进行环境感知,实现了有效的场景特征编码与多模态数据融合。FIERY作为端到端联合感知预测范式的先驱之一,率先实现了直接从环视相机数据输入进行BEV预测的端到端模型 。由于联合感知预测的成功探索,一些学者开始研究以规划为导向的模块化联合端到端方法,即通过可微模块执行联合感知、预测、规划任务,将整个端到端模型视为一个统一体,实现模块间的协同优化,推动规划目标的达成 。为此,UniAD提出了一种规划导向的模块化端到端框架,该模型将自动驾驶的3项主要任务(感知、预测和规划)和4项子任务(目标检测与跟踪、在线建图、轨迹预测、占用栅格预测)整合到一个网络中,利用查询向量串联多个任务。同时,每个模块的Transformer架构通过注意力机制进行信息交互,并将信息传递至最终的规划模块,避免了不同任务模块间的累积误差 。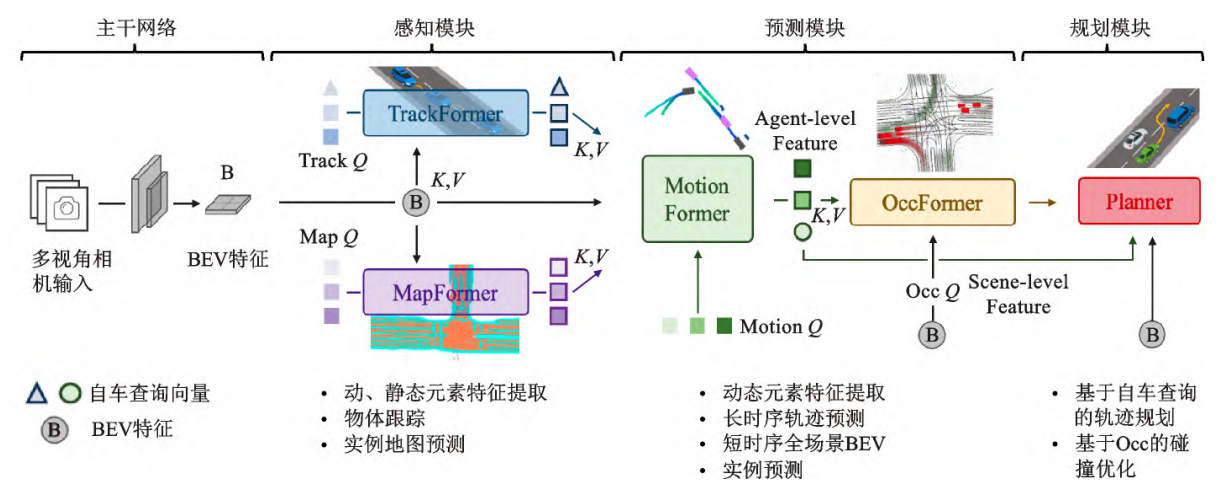
各模块围绕最终的规划控制目标进行调整和优化,其编码信息还能作为中间任务解码显式输出,便于对各个模块单独训练 。UniAD不仅提供了丰富的中间表示,还成功避免了多任务模块的累计误差问题 。随后,VAD简化了UniAD,采用矢量化场景表示法,仅运用地图、运动和规划模块进行端到端驾驶,以更高的效率实现了更优的规划性能 。然而,VAD的预测和规划串行设计,忽视了自车对环境车运动预测的影响,且缺乏对运动预测和规划不确定性的建模 。确定性范式倾向于输出主导轨迹,如数据集中出现频次最多的直行和停止等轨迹,导致规划行为保守 。为解决这些问题,VADv2提出了概率性规划,以应对规划过程中的不确定性 。该方法将多视角图像序列作为输入,利用编码器将传感器数据转换为环境Tokens嵌入,输出动作的概率分布,并对动作进行采样以控制车辆 。在CARLA Town05基准测试中,VADv2实现了先进的闭环性能,显著优于现有方法 。
四、生成式端到端方法
生成式人工智能与端到端自动驾驶融合发展,成果频出。多模态大模型凭借其强大的驾驶常识、认知及推理能力,结合 “提示-推理-微调” 策略,不仅能够完成规划任务,实现端到端自动驾驶,还能提供高透明度的解释,显著提升用户对自动驾驶的信任度。同时,生成式自监督学习与端到端自动驾驶技术的结合,成为突破“长尾”困境、保障自动驾驶安全性的重要探索方向 。部分研究尝试构建基于世界模型的自动驾驶端到端基础模型,助力自动驾驶汽车全面理解交通场景,实现类人交互 。
1.基础模型微调
基础模型通常遵循“预训练-微调”范式。先利用大规模无标注数据,通过自监督学习进行预训练;再结合有标注数据微调参数,以适配特定任务 。这一模式在自然语言处理、计算机视觉等领域广泛应用 。2017年Transformer网络的出现,开启了大语言模型(LLM)发展的新阶段 。随着数据和模型参数的规模化,GPT-3、PaLM、LLaMA和GPT-4等LLM展现出上下文学习、指令跟随和思维链推理等智能涌现能力 。此后,基础模型从自然语言处理领域拓展至计算机视觉领域 。BERT的成功引发了计算机视觉领域对生成式自监督预训练的关注,催生了BEiT、MAE等视觉大模型 。与此同时,具备多模态信息接收与推理能力的视觉-语言模型成为研究热点,常见的有CLIP、ViLBERT、VisualBERT、SimV-LM、BLIP2、Flamingo 。
通过提示工程优化现有大语言模型,或对其进行微调,可将文本化驾驶场景直接映射为规划轨迹点或控制信号,这是大语言模型实现端到端自动驾驶的早期探索 。例如,GPT-Driver将环境信息文本化,运用“提示-推理-微调”策略,使GPT3.5能应用于自动驾驶车辆的端到端规划 。当前主流做法是先编码感知信息,再输入预训练基础模型 。如DriveGPT4利用大语言模型构建了端到端可解释的自动驾驶模型,结合单目相机输入,可输出车辆控制信号及相关解释 。DriveMLM和LMDrive整合多模态传感器数据与自然语言指令作为输入,生成控制信号 。多数采用多模态大模型进行闭环端到端自动驾驶的研究,倾向于添加记忆模块存储驾驶经验 。如DiLu设计了以大语言模型为核心、包含记忆模块的端到端框架,该系统结合记忆模块经验与大语言模型常识,为当前驾驶场景制定决策 。DriveLikeaHuman通过单独的记忆模块遵循人类决策过程,收集驾驶案例获取经验,检索现有记忆协助决策,赋予大语言模型在自动驾驶领域的持续学习能力 。通过集成记忆模块,大语言模型能实时处理车辆传感器数据,还能引用历史数据优化决策,增强对复杂环境的适应与反应能力 。PlanAgent基于多模态大模型构建轨迹规划模型,输入鸟瞰图(BEV)和车道图的文本描述,通过推理引擎模块进行层次链式推理,生成规划轨迹,并引入反思模块模拟和评估规划器,降低多模态大模型的不确定性 。PlanAgent具备多模态大模型的常识推理和泛化能力,能有效应对长尾场景 。此外,大语言模型可通过上下文学习,契合驾驶人偏好与意图,实现个性化自动驾驶 。如Cui等基于大语言模型提出个性化决策,将人类语言输入解释为文本指令,发送给大语言模型推理,结合上下文信息(天气、交通状况和交通规则等)做出安全、舒适的决策 。记忆模块存储人车交互数据,确保驾驶体验能根据人类驾驶偏好和指令进行个性化决策 。Wang等将大语言模型作为“副驾驶”,以用户驾驶偏好(驾驶风格等)为输入,提供个性化决策行为 。大语言模型不仅能实现个性化端到端自动驾驶,还能对车辆决策行为提供实时、详细且易懂的解释,提升用户信任和体验 。不过,大模型存在幻觉问题,可能产生误导信息,导致错误决策 。
2.生成式模型
模仿学习需标注专家示范数据,获取真实奖励等先验知识,再结合监督学习学习专家策略,但标注成本限制了大规模未标注数据的利用 。强化学习不依赖监督数据,通过环境反馈的奖励信号或价值函数,在交互中试错学习策略,然而其缺乏对目标泛化对象的表征利用,样本效率低,泛化能力差 。生成式方法在自动驾驶场景理解、交通参与者运动状态预测、动态场景重构等任务中应用广泛 。自监督学习挖掘大规模驾驶数据潜力,拓宽了端到端自动驾驶研究路径 。
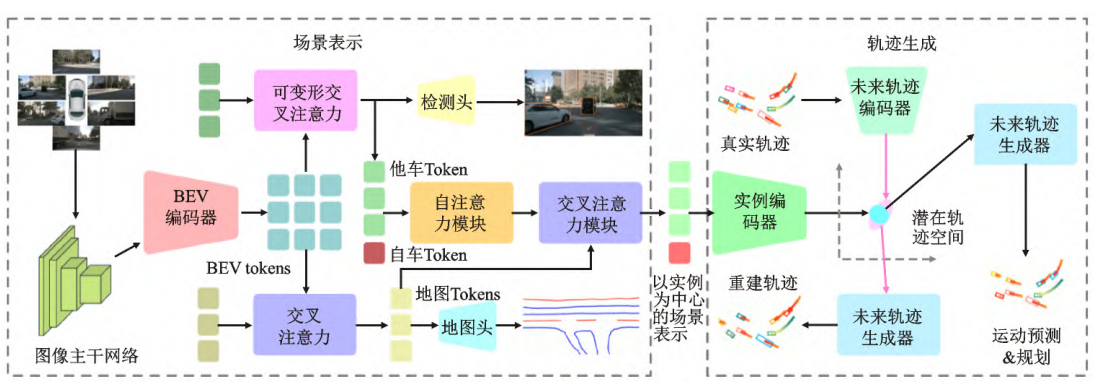
GenAD是首个生成式端到端自动驾驶模型 。它将自动驾驶建模为轨迹生成问题,采用生成式自监督方式,预测自车与他车状态的时序演变,在结构化潜在轨迹空间中同步进行运动预测和轨迹规划 。具体而言,先利用图像主干提取图像输入的多尺度特征,通过BEV编码器获取BEV Token 。接着,运用交叉注意力和可变形交叉注意力,将BEV token转换为地图Token和他车Token 。借助额外的自车Token,使用自注意力实现自车-他车交互关系建模,并通过交叉注意力整合地图信息,获取以实例为中心的场景表示 。最后,将该表示映射到结构化潜在轨迹空间,由轨迹生成器产生未来轨迹,同时完成他车运动预测和自车轨迹规划 。在nuScenes基准测试中,GenAD取得了纯视觉端到端自动驾驶的领先成绩 。
自动驾驶系统的可靠性依赖于其在未知场景的泛化能力 。世界模型作为生成式人工智能新范式,能学习理解环境动态特性表征,预测场景未来状态,具有良好泛化能力 。在自动驾驶领域,世界模型主要用于生成高保真度自动驾驶数据,丰富训练数据集,提升自动驾驶系统应对罕见和复杂驾驶场景的鲁棒性 。GAIA-1和DriveDreamer是利用世界模型生成驾驶场景的典型研究,结合视频、文本和动作输入,运用扩散模型和大语言模型实现仿真驾驶场景的泛化生成 。OccWorld采用3D语义占用作为场景表示,同时预测交通场景演变和自车未来轨迹 。DriveWorld则以BEV和历史动作作为输入,预测3D占用情况 。除视觉输入外,自动驾驶领域的世界模型研究逐渐向多模态方法发展 。
世界模型能够捕捉、学习复杂动态环境的演化机理,依据历史观测信息推测环境未来状态,有效提升行车安全性和多场景自适应能力 。因此,通过自监督或弱监督方法训练自动驾驶世界模型,实现驾驶场景理解和驾驶策略生成,成为端到端自动驾驶领域的重要研究思路 。Drive-WM通过多视图世界模型,想象不同规划路线的未来情景,依据视觉预测获取奖惩反馈,增强端到端自动驾驶规划的安全性 。Li等提出潜在世界模型(LAW),根据预测的自车动作和当前帧潜在特征,预测未来潜在特征 。利用自监督学习,即预测的潜在特征由实际观测到的未来特征监督,显著提升端到端自动驾驶性能 。
五、现有端到端方法的对比

结语
随着人工智能快速发展,端到端自动驾驶方法备受关注。该方法无需人工预先定义规则与模块间显式接口,将感知、决策、控制等模块作为整体学习任务优化,直接由车载传感器信号映射出车辆控制命令。
但以模仿学习、强化学习为代表的端到端方法,“黑盒式”架构使其可解释性弱、安全性难保障;且模型输出错误时,无法像模块化方法那样溯源,难以针对性优化。
因此,将模块化方法的强解释性与深度学习结合,构建模块化端到端学习框架,成为近年自动驾驶技术发展的新思路之一。此外,基于“预训练-微调”范式的多模态基础模型,具备复杂推理、自主决策、长期记忆与“智能涌现”能力,推动了自监督学习端到端方法的转变,为混合交通环境下的类人决策、个性化驾驶提供了可能。
更多推荐
 29
29 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)